
データエンジニアリングに重要なdbtの使い方を徹底解説!


こんにちは!スタビジ編集部です!
近年、企業が扱うデータ量は爆発的に増え続けています。
ただ大量のデータを蓄積するだけでは、ビジネスに活かせる”価値あるデータ“にはならないため、データサイエンティストがその大量のデータを変換・加工・分析し、新たな知見を導き出しています。
そんなデータの変換・整形のプロセスを効率的かつ再現性高く行うために、多くのデータサイエンティストが採用しているのが 「dbt(data build tool)」です。


本記事では、「dbt(data build tool)」の概要から導入方法、活用事例まで、実際の操作を交えながら徹底的に解説します。
・dbtの概要
・dbtの使い方
・dbtの活用方法
ちなみに、dbtの使い方についてガッツリ学びたい方は以下のUdemy講座で解説していますのでチェックしてみてください!
【実践】dbt完全入門!dbt × SQL × DuckDB超速習コースで最先端ETLとデータモデリングを学ぼう!
| 【時間】 | 3.5時間 |
|---|---|
| 【レベル】 | 初級 |
dbtを学んでデータエンジニアリングをしっかりマスターしたいならこのコース!
今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
目次
dbt(data build tool)の概要
「dbt(data build tool)」の概要について見ていきましょう。
ただ、その前にまずデータ分析の流れ「データパイプライン」について見ていきます。
データパイプラインとは
「データパイプライン」とは、データを収集して活用できる形に加工し、最終的に分析やアプリケーションで利用できるようにする一連のプロセスのことです。
データを効率的にかつ信頼性高く処理するために設計された仕組みになります。
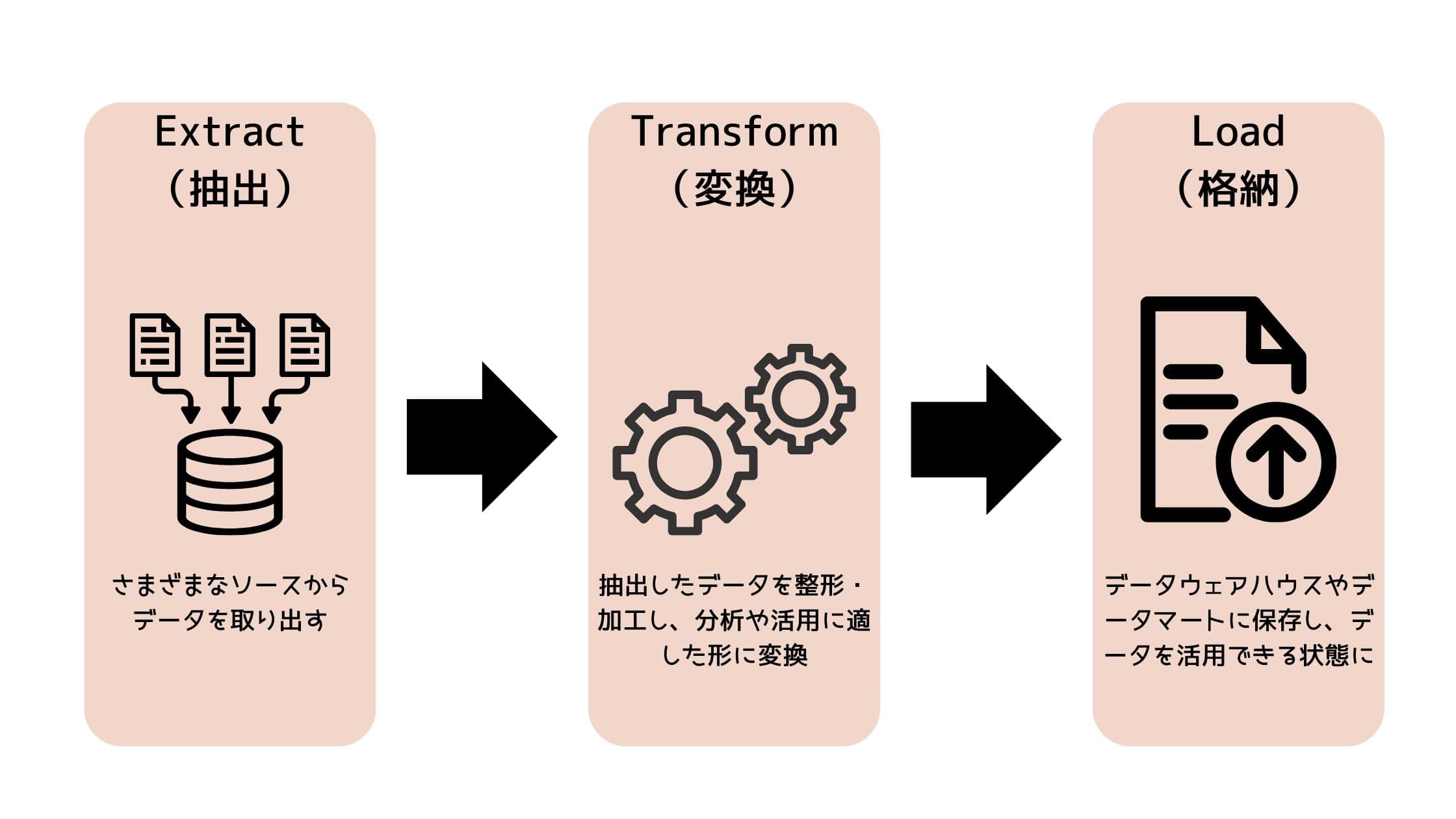
そんなデータパイプラインの中心的な仕組みのひとつが「ETLプロセス」です。
- Extract(抽出):各種システム(アプリDB、ログ、外部API など)から必要なデータを取り出すフェーズ
- Transform(変換):データの形式を整えたり、不要な値を削除したり、複数ソースを結合したりするフェーズ、分析や活用に適した状態にするための重要なプロセス
- Load(格納):変換後のデータをデータウェアハウス(BigQuery、Snowflake、Redshiftなど)やストレージに保存し、BIツールや機械学習で使える状態にするフェーズ
図にすると以下のようなイメージです。
dbt(data build tool)とは
「dbt(data build tool)」とは、SQLをベースにしたシンプルな記法でデータの変換処理を「モデル」として管理できるツールです。
dbtは先ほどのデータパイプラインの中では「Transform(変換)」のフェーズで利用されます。
従来データの変換ではその場でSQLを書いて実行するのが一般的でした。
例えば月ごとの売上を集計したい場合、下記のようなSQLを実行します。
SELECT
DATE_TRUNC('month', order_date) AS month,
SUM(amount) AS total_sales
FROM orders
GROUP BY 1;ただこの場合、下記のような課題があります。
- 共有や再利用が難しい:分析担当者がローカルやBIツールで一時的に実行していることが多い、共有や再利用が難しい(同じSQL文を探し出さないといけない)
- 変更に弱い:データのスキーマが変わったり、計算ルールが変わった場合各自が個別にSQLを修正しないといけない
dbtの場合は、下記のように処理します。
-- models/monthly_sales.sql
SELECT
DATE_TRUNC('month', order_date) AS month,
SUM(amount) AS total_sales
FROM {{ ref('orders') }}
GROUP BY 1;“models/monthly_sales.sql”の部分でSQLを”モデル”として定義します。
これにより、SQLを再利用可能な変換処理として利用できます。
このように、変換ロジックをコードとして管理できるため、スクリプトが散在する従来型のETL開発に比べて透明性が高く、チームでの開発や運用を効率的に進められる点が大きな特徴です。
dbtの特徴
「dbtの特徴」をより深く見ていきましょう。
dbtの特徴は以下です。
- SQLベースの変換管理:データ変換をSQLで記述し、ファイル(モデル)として管理
- モデル化と依存関係の可視化:テーブルやビューを「モデル」として扱い、ref() 関数で依存関係を明示
- テスト機能:”not_null”や”unique”など簡単に記述できるテストを提供
- ドキュメント自動生成:モデルやカラムの説明を含むドキュメントをHTML化して閲覧可能
dbtでは、SQLをモデル化して再利用可能にできることが大きな特徴です。
また、依存関係を理解し、処理の実行順序を自動的に決定してくれます。
またテスト機能やドキュメント自動生成機能もあるので、開発の効率化と品質の向上できる点も特徴です。
dbtの使い方
実際に、dbtの使い方について見ていきましょう
下記の流れで見ていきます。
- 事前準備
- プロジェクト作成
- サンプルデータ実行
- 結果確認
事前準備
まずは、ローカル環境でdbtを動かすための準備を行っていきます。
今回は「DuckDB」に対してdbtの処理を行っていきます。
「DuckDB」はデータを分析・集計するのに便利な軽量のDBで、ローカル環境でも大量のデータを高速に処理することができます。
必要なツールをインストールします。
$pip install duckdb
$pip install dbt-core dbt-duckdbDuckDBとdbtと、dbtとDuckDBを繋ぐアダプタを自身の環境にインストールします。
$dbt --version
Core:
- installed: 1.10.11
- latest: 1.10.11 - Up to date!
Plugins:
- duckdb: 1.9.4 - Up to date!上記のコマンドでバージョンが表示されれば正常にインストールされています。
プロジェクト作成
dbtでは、変換処理(モデル)や設定ファイルを「プロジェクト」という単位でまとめて管理します。
新しくdbtを使う場合、最初にプロジェクトを作ることで、設定ファイルや各種フォルダが自動生成されます。
$dbt init dbt_duck_sample上記コマンドでプロジェクトを作成できます。
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2025/09/07 23:21 analyses
d----- 2025/09/07 23:21 macros
d----- 2025/09/07 23:21 models
d----- 2025/09/07 23:21 seeds
d----- 2025/09/07 23:21 snapshots
d----- 2025/09/07 23:21 tests
-a---- 2025/09/07 23:21 29 .gitignore
-a---- 2025/09/08 7:42 1295 dbt_project.yml
-a---- 2025/09/07 23:21 571 README.md“dbt_duck_sample”配下を見ると上記のように設定ファイル(dbt_project.yml)やフォルダが作成されています。
また、ホームディレクトリ(Linux/Mac では ~/.dbt/profiles.yml、Windowsでは C:\Users\<ユーザー名>\.dbt\profiles.yml)に設定ファイル(profiles.yml)が作成されています。
dbt_duck_sample: # ← dbt_project.yml の profile: と一致
outputs:
dev:
type: duckdb # ← DuckDBアダプタを使用
path: dev.duckdb # DuckDBファイルの保存先(相対 or 絶対パス)
threads: 1
prod:
type: duckdb
path: prod.duckdb
threads: 4
target: devここではdbtが“どのデータベースにどんな設定で”接続するかを定義しています。
ここではデフォルトの設定で進めていきます。
$dbt debug上記コマンドで「All checks passed!」と表示されれば、接続できています。
サンプルデータ実行
ではサンプルデータを使ってdbtを実行してみましょう。
まずはプロジェクト直下の”seeds”フォルダに”order.csv”ファイルを作成します。
## order.csv
order_id,order_date,customer_id,amount
1,2024-01-03,101,120.5
2,2024-01-15,102,99.0
3,2024-02-02,101,250.0
4,2024-02-28,103,80.0
5,2024-03-03,101,300.0
6,2024-03-20,104,70.0dbtでは”seed“という仕組みがあり、csvファイルをデータベースに取り込んでテーブル化できます。
デフォルトではプロジェクト直下の”seeds”フォルダ内のcsvファイルをseedとして認識します。
$dbt seed
11:13:09 Running with dbt=1.10.11
11:13:09 Registered adapter: duckdb=1.9.4
11:13:10 Found 2 models, 4 data tests, 1 seed, 429 macros
11:13:10
11:13:10 Concurrency: 1 threads (target='dev')
11:13:10
11:13:10 1 of 1 START seed file main.order .............................................. [RUN]
11:13:11 1 of 1 OK loaded seed file main.order ...............................11:13:09 Running with dbt=1.10.11
11:13:09 Registered adapter: duckdb=1.9.4
11:13:10 Found 2 models, 4 data tests, 1 seed, 429 macros
11:13:10
11:13:10 Concurrency: 1 threads (target='dev')
11:13:10
11:13:10 1 of 1 START seed file main.order .............................................. [RUN]
11:13:11 1 of 1 OK loaded seed file main.order ...............................11:13:10 Found 2 models, 4 data tests, 1 seed, 429 macros
11:13:10
11:13:10 Concurrency: 1 threads (target='dev')
11:13:10
11:13:10 1 of 1 START seed file main.order .............................................. [RUN]
11:13:11 1 of 1 OK loaded seed file main.order ...............................11:13:10
11:13:10 1 of 1 START seed file main.order .............................................. [RUN]
11:13:11 1 of 1 OK loaded seed file main.order .......................................... [INSERT 6 in 0.17s]
........... [RUN]
11:13:11 1 of 1 OK loaded seed file main.order .......................................... [INSERT 6 in 0.17s]
........... [INSERT 6 in 0.17s]
11:13:11
11:13:11 Finished running 1 seed in 0 hours 0 minutes and 0.49 seconds (0.49s).
11:13:11
11:13:11 Completed successfully
11:13:11
11:13:11 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 NO-OP=0 TOTAL=1上記のように”dbt seed”とコマンドを実行することで、対象のcsvファイルを接続しているデータベースにテーブルとして作成・更新できます。
次にsqlファイルを準備します。
“models/example”というフォルダの中に”monthly_sales.sql”というファイルを作成し、月ごとの売上を集計するSQLを書きます。
## monthly_sales.sql
{{ config(materialized='table') }}
select
date_trunc('month', order_date) as month,
sum(amount) as total_sales
from {{ ref('order') }}
group by 1
order by 1“ref(‘order’)“を使うと、”order”テーブルと”monthly_sales”モデルの依存関係がdbtに自動登録されます。
dbt側では依存関係を記録し、実行順序を自動で決定してくれます。
ではモデルを実行してみましょう。
$dbt run -s monthly_sales
11:47:38 Running with dbt=1.10.11
11:47:39 Registered adapter: duckdb=1.9.4
11:47:40 Found 3 models, 4 data tests, 1 seed, 429 macros
11:47:40
11:47:40 Concurrency: 1 threads (target='dev')
11:47:40
11:47:47 1 of 1 START sql table model main.monthly_sales ................................ [RUN]
11:47:47 1 of 1 OK created sql table model main.monthly_sales ........................... [OK in 0.19s]
11:47:47
11:47:47 Finished running 1 table model in 0 hours 0 minutes and 7.20 seconds (7.20s).
11:47:47
11:47:47 Completed successfully
11:47:47
11:47:47 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 NO-OP=0 TOTAL=1“dbt run“でモデルが実行され、DuckDBファイル内に”monthly_sales”テーブルが作成されます。
モデルがあるから何回も実行可能!
結果確認
実行した結果を見ていきましょう。
DuckDBのCLIやPythonからDuckDBの中身を確認できます。今回はCLIで確認してみます。
DuckDBのCLIがない場合は公式サイトからインストールしましょう。
$duckdb ./dev.duckdb上記コマンドで作成したDuckDBの中に入ります。
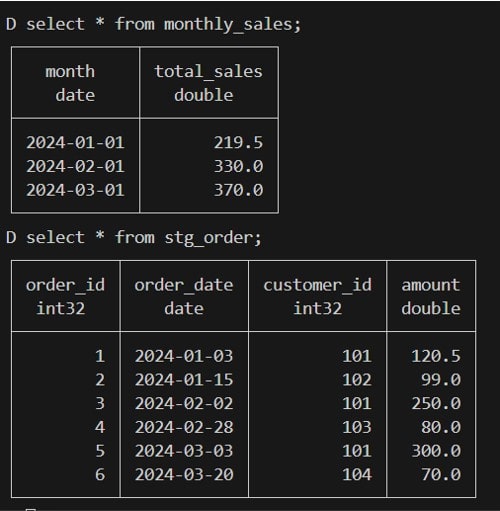
select * from monthly_sales;SQLクエリでテーブルを確認します。
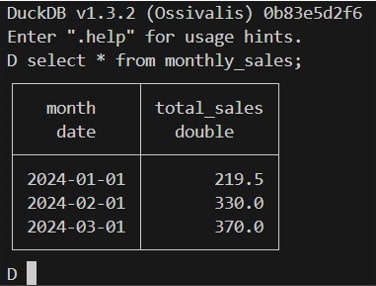
csvファイルのデータが計算され、テーブルとして格納されていることを確認できました。
dbtの活用方法
ここではdbtの機能をもう少し踏み込んで見ていきます。
ドキュメント作成
dbtの機能であるドキュメント作成機能を見ていきます。
$dbt docs generate上記コマンドを実行すると、プロジェクトのモデル(SQLファイル)やYAMLファイルのメタ情報を解析してくれます。
そして、依存関係(DAG)、モデルの説明文、カラム定義をまとめた静的HTMLドキュメントを作成してくれます。
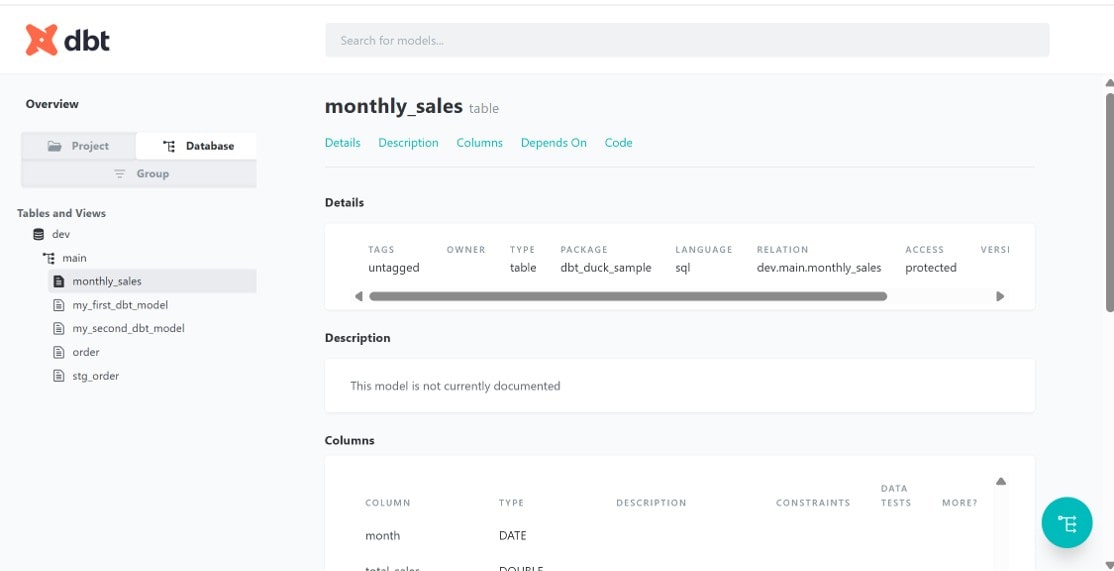
$dbt docs serve続いて、上記コマンドを実行すると生成されたドキュメントを簡易Webサーバーで公開してくれます。
ブラウザ(localhost:8080)から閲覧できて、モデル説明やカラム定義といった情報を確認できます。
依存関係(ref)の確認
dbtの依存関係の機能を見ていきましょう。
“models”フォルダに”staging/stg_order.sql”を作成します。
## stg_order.sql
{{ config(materialized='view') }}
select
cast(order_id as int) as order_id,
cast(order_date as date) as order_date,
customer_id,
amount
from {{ ref('order') }}
次に”monthly_sales.sql”を修正します。
## monthly_sales.sql
{{ config(materialized='table') }}
select
date_trunc('month', order_date) as month,
sum(amount) as total_sales
from {{ ref('stg_order') }}
group by 1この状態で再度”dbt run”を実行します。
dbt側で依存関係を確認して実行してくれるため、正常にデータが入っていることを確認できます。
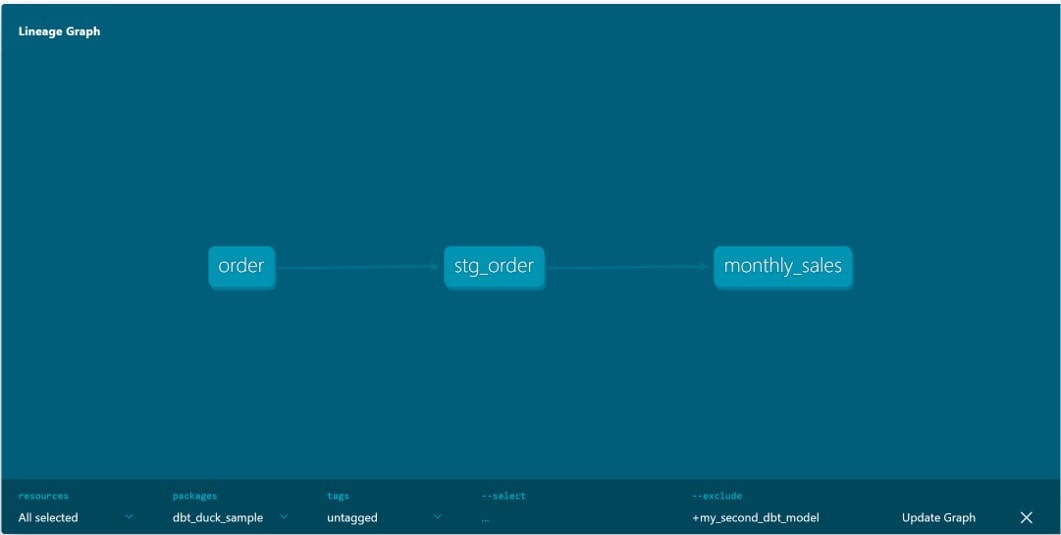
ブラウザでドキュメントを確認すると、依存関係が図示化されています。
 テストの実施
テストの実施
dbtの特徴の一つは「SQLで作ったモデルに対して、品質テストを簡単に実行できる」ことです。
“models/example”というフォルダの中に”marts.yml”というファイルを作成します。
## marts.yml
version: 2
models:
- name: monthly_sales
description: "月次売上集計モデル"
columns:
- name: month
tests:
- not_null
- name: total_sales
tests:
- not_null
データにnull値がないかチェックするテストになります。
$dbt test -s monthly_sales
15:27:48 Running with dbt=1.10.11
15:27:48 Registered adapter: duckdb=1.9.4
15:27:49 Found 4 models, 1 seed, 6 data tests, 545 macros
15:27:49
15:27:49 Concurrency: 1 threads (target='dev')
15:27:49
15:27:49 1 of 2 START test not_null_monthly_sales_month ................................. [RUN]
15:27:49 1 of 2 PASS not_null_monthly_sales_month ....................................... [PASS in 0.05s]
15:27:49 2 of 2 START test not_null_monthly_sales_total_sales ........................... [RUN]
15:27:49 2 of 2 PASS not_null_monthly_sales_total_sales ................................. [PASS in 0.02s]
15:27:49
15:27:49 Finished running 2 data tests in 0 hours 0 minutes and 0.20 seconds (0.20s).
15:27:49
15:27:49 Completed successfully
15:27:49
15:27:49 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 NO-OP=0 TOTAL=2上記のコマンドでテストを実行して、結果を確認できます。
dbt まとめ
dbtについて見ていきました。
最後にdbtの特徴についておさらいします。
dbtの特徴は以下です。
- SQLベースの変換管理:データ変換をSQLで記述し、ファイル(モデル)として管理
- モデル化と依存関係の可視化:テーブルやビューを「モデル」として扱い、ref() 関数で依存関係を明示
- テスト機能:”not_null”や”unique”など簡単に記述できるテストを提供
- ドキュメント自動生成:モデルやカラムの説明を含むドキュメントをHTML化して閲覧可能
dbtについてもっと深く学びたい方は以下のUdemy講座で解説していますのでチェックしてみてください!
【実践】dbt完全入門!dbt × SQL × DuckDB超速習コースで最先端ETLとデータモデリングを学ぼう!
| 【時間】 | 3.5時間 |
|---|---|
| 【レベル】 | 初級 |
dbtを学んでデータエンジニアリングをしっかりマスターしたいならこのコース!
今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















