
【入門】PySparkとは?使い方を分かりやすく解説!


こんにちは!スタビジ編集部です!
AIやデータ分析、自動化などを実現するため、”Python“を使ってWebアプリやサービスを開発する人が増えています。
特にビッグデータの分析や機械学習といった分野で、Pythonを利用する方は多いと思います。
一方でこんな悩みもあると思います。


これらの悩みを解決するのがPythonで分散処理が出来るフレームワーク”PySpark“!
今回はそんな”PySpark“について解説していきます。
Pythonについて基礎から体系的に学びたい人は当メディアが運営する「スタアカ」の以下のコースをチェックしてみて下さい。

PySparkについて
まずは”PySpark“について概要をおさえていきましょう
PySparkとは
“PySpark“とは、Apache SparkをPythonで実行できるライブラリで、分散環境でリアルタイムの大規模データ処理が出来ます。
ここで出てくる”Apache Spark“とは「大規模なデータを高速に処理できる分散処理フレームワーク」の一つです。
Apache Sparkの概要図は以下のようになります。
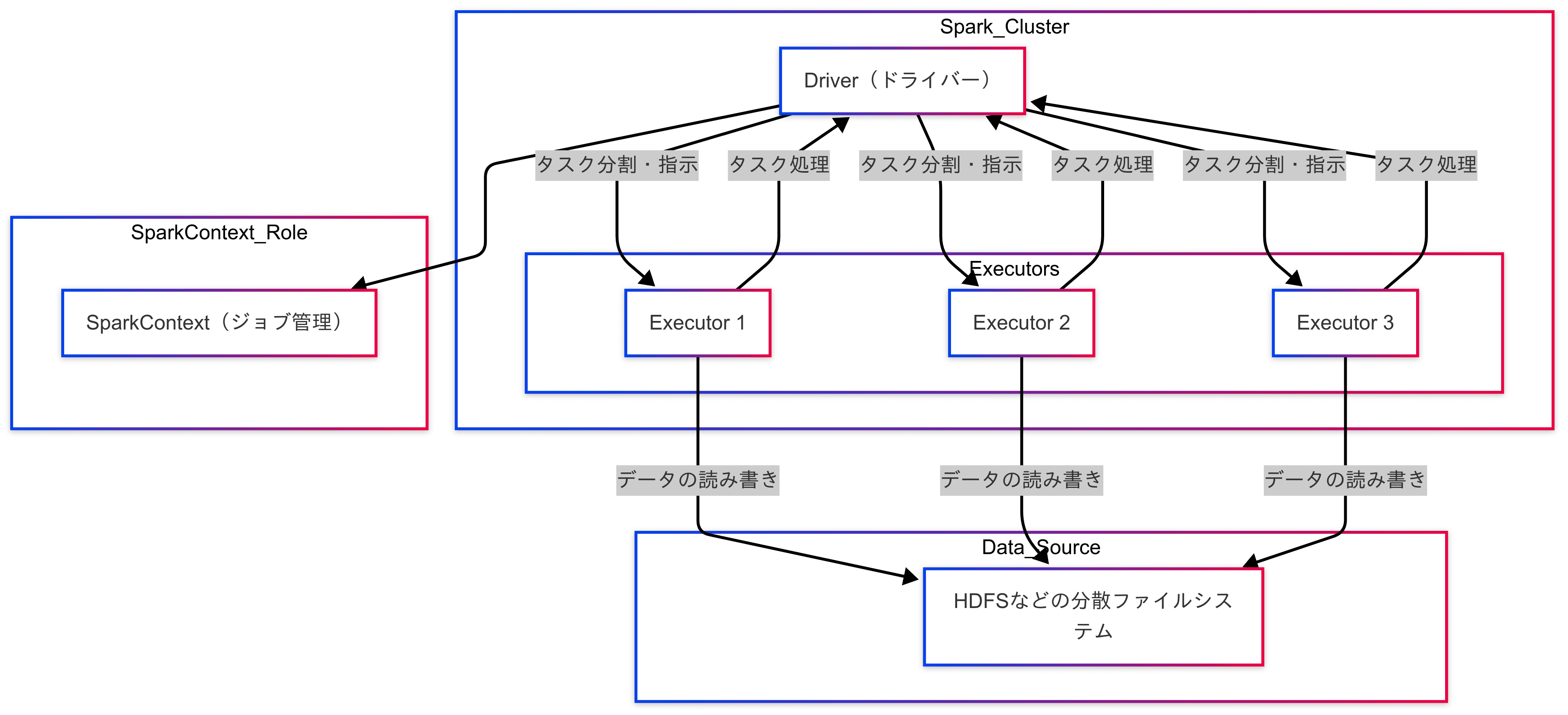
Apache Sparkでは上記のように処理したい大量のデータを分割して、それぞれのノードで並行して処理することで、高速化を実現しています。
このような実行方法を”Spark処理“と呼ばれます。
Pythonの高速化テクニックについては以下の記事でまとめているので、参考にしてみて下さい。

PySparkの特徴
「PySpark(Spark処理)の特徴」は以下です。
- データを複数のコンピュータ(クラスター)に分散させて処理する
- データをメモリ上に一時的に保管しながら処理を行うため高速
- 数百万〜数億行などの大規模データでも処理可能
- さまざまなデータフォーマット(テキスト、CSV、JSONなど)に対応
Sparkの持つ強力な並列分散処理機能をPythonのシンプルな記述で利用できるため、ビッグデータ分析や機械学習など、データ処理が必要な様々なシーンで広く利用されています
PySparkでデータ集計をやってみよう!
ここからは実際にPySparkを使った処理を実装していきます。
今回はPySparkで以下の操作を確認していきます。
・データの読み込み・表示
・データの操作
・SQLクエリの実行
本記事でのPythonの作業は「Jupyter Notebook」で行っています。
Jupyter NotebookはWebブラウザ上でPythonプログラムを書いて・実行出来る環境です。
プログラムの実行結果を毎回確認できるので初心者におすすめのツールになります。
Jupyter Notebookについて以下の記事で解説しているので、参考にしてみて下さい。

事前準備
PySparkを使うための事前準備について見ていきましょう。
PySparkではJava環境(JDK)が必要になります。
PySparkの元のApache Sparkが動くJavaのバージョンは、2025年4月時点では”8″、”11″、”17″が対象になります。
詳細は”Apache Spark“のページで対象のJavaのバージョンを確認しましょう。
続いて、PySparkをインストールします。
!pip install pyspark無事インストールされたら以下のコードを実行してみてください
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataLoadExample").getOrCreate()ここではPySparkライブラリの読み込みと”SparkSession“の作成を行っています。
“SparkSession“とはPySparkを使ってデータを処理するときに必要な機能にアクセスできるエントリーポイントになります。
先ほどの概要図の”Driver(ドライバー)”に所属するオブジェクトにあたり、SparkSessionを作成することでPython上でSpark機能が利用できるようになります。
データの読み込み・表示
まずはPySparkを使った「データの読み込み・表示」をやってみましょう。
下記コードを実行します。
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataLoadExample").getOrCreate()
# CSVを読み込み
df = spark.read.csv("sample.csv", header=True, inferSchema=True)
# 読み込んだデータを表示
df.show(5)
spark.stop()csvファイルを読み込んでSparkのDataFrame型として扱います。
パラメータは下記の意味になります。
- spark.read.csv():CSVファイルを読み込む
- header=True:1行目をカラム名として扱う
- inferShema=True:自動的にカラムのデータ型(文字列、整数、など)を推測
上記のコードを見るとPandasの”read_csv()”に似ていますが、Sparkの方は複数コアに処理を分けて(分散処理)いるのが特徴です。
sample.csvファイルの中身と実行結果はこちらになります。
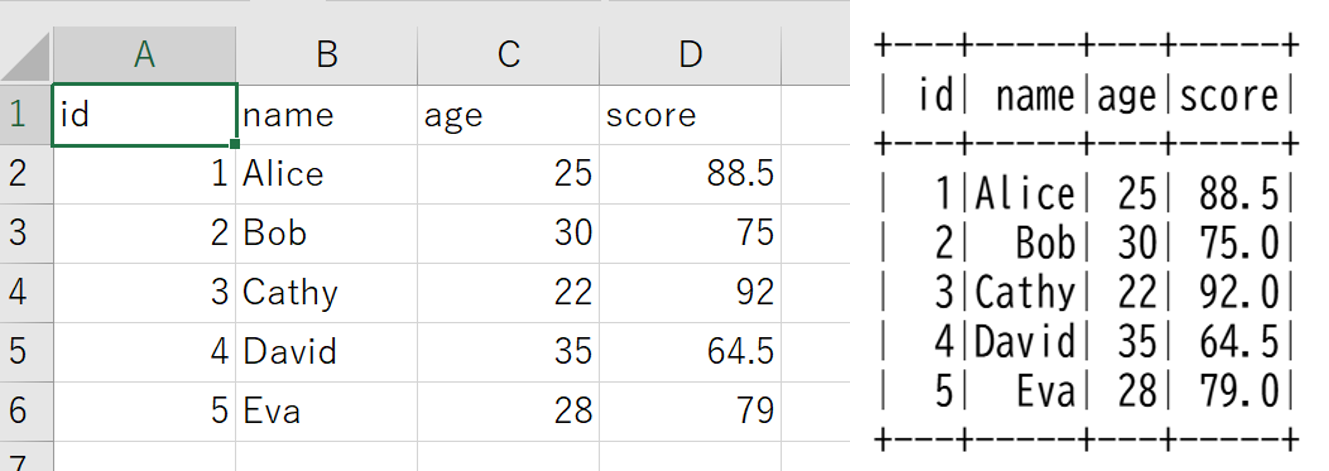
csvファイルの中身のデータを読み込めていますね
また、コードの最後”spark.stop()”でSparkSessionを停止していますが、こちらをコメントアウトして実行してみます。
その後ブラウザで「http://localhost:4040/」を入力して実行すると、”Spark UI“にアクセスできます。
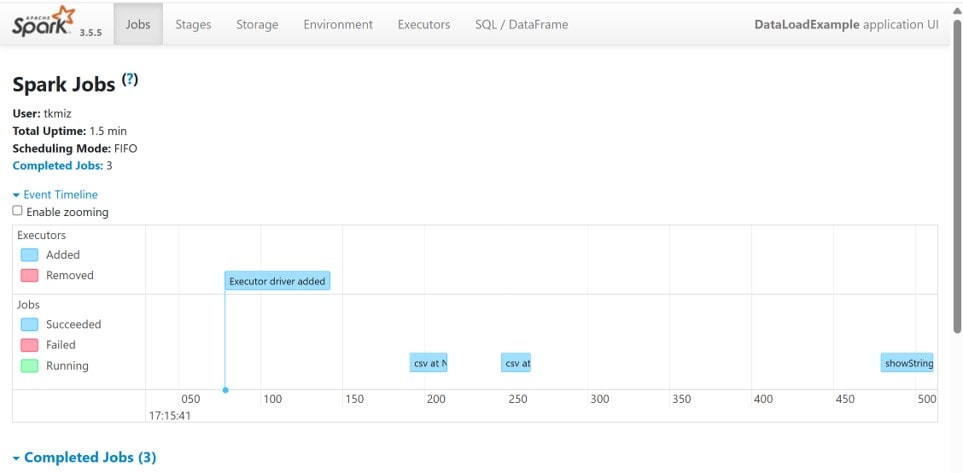
“Spark UI”では以下のことを確認できます。
・”Jobs”タブで処理単位ごとの概要
・”Stages”タブで分割タスクがどう分割・実行されたかを表示
・”Executors”タブで各ノード(Executors)の処理内容やメモリ使用量
ここで実際の処理状況を確認できます。
デフォルトでは1スレッドで実行されますが、下記のように”.master()“で実行するスレッド数を指定することも出来ます。
spark = SparkSession.builder.appName("DataLoadExample").master("local[8]").getOrCreate()
上記は8スレッドを指定した例になります。
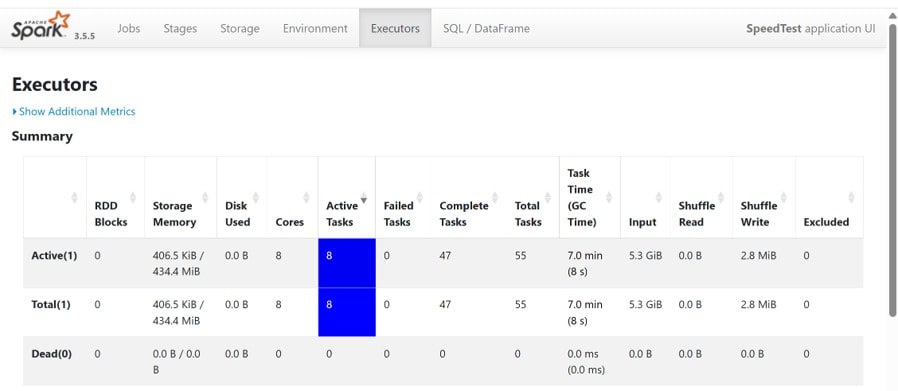
“Executors”を見てみると1つのノードで8タスクが並行して処理されているのがわかります。
他にも「.master(“local[*]”)」とすべてのコアで実行するように指定できるので、PCのスペックに応じて並行処理を試してみて下さい。
確認が終わったら”spark.stop()”でSparkSessionを停止すると良いです。
Pandasについては以下の記事で詳しく解説しているので参考にしてみて下さい。

データの操作
PySparkでは収集した「データの操作」も実行できます。
まずは年齢が30歳以上の人をフィルタリングして表示してみます。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when
# SparkSessionの作成
spark = SparkSession.builder.appName("AllBasicOperations").getOrCreate()
# CSVファイルの読み込み
df = spark.read.csv("sample.csv", header=True, inferSchema=True)
# ① 年齢が30歳以上の人だけを抽出(フィルタリング)
df_filtered = df.filter(col("age") >= 30)
print("▼ 年齢30歳以上の人:")
df_filtered.show()“pyspark.sql.functions“はPySparkで使える関数を集めたモジュールになり、必要な関数はあらかじめインポートします。
よく使われる関数は以下です。
- col():列(カラム)を指定
- when():条件分岐
- avg():平均
- count():カウント
- concat():複数列を連結
- isnull():欠損値の判定
PySparkのDataFrameでは独自のメソッドを使ってデータを操作します。
“filter“メソッドでは条件に一致する行を抽出できます。
PySparkでよく利用されるDataFrameメソッドは以下になります。
| カテゴリ | メソッド | 説明 |
|---|---|---|
| 基本操作・表示 | show(n) | データの先頭n行を表示 |
| printSchema() | スキーマ(列の型情報)を表示 | |
| columns | 列名一覧を取得 | |
| dtypes | 各列のデータ型を確認 | |
| count() | 行数を取得 | |
| フィルタリング | filter() | 条件に一致する行を抽出 |
| distinct() | 重複行を削除 | |
| 列操作 | select() | 特定の列だけを選択 |
| withColumn() | 新しい列を追加/既存列を更新 | |
| drop() | 列を削除 | |
| 集計・グループ化 | groupBy() | 指定列でグループ化 |
| .agg() | 集計処理 | |
| avg() | 平均 |
また、filterメソッドの中にある”col“関数を使ってで特定の列を指定しています。
これらの記法を活用して、今回は「年齢が30歳以上」を指定してフィルタリングしてみました。

次にデータを追加する操作として、合否の列を追加しスコアが80以上の人を合格、80未満を不合格に分類してみます。
# ② スコアに応じて「合格/不合格」列を追加
df_with_result = df.withColumn(
"result",
when(col("score") >= 80, "合格").otherwise("不合格")
)
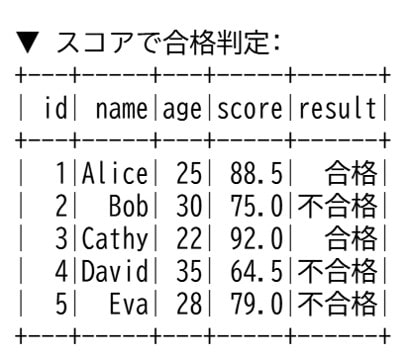
print("▼ スコアで合格判定:")
df_with_result.show()“when“関数を使うと条件分岐をして”withColumn“メソッドで列を追加します。
実行結果を見ると合格判定の結果が列に追加されているのが確認できます。
SQLクエリの実行
PySparkでは「SQLクエリの実行」してデータをSQL的に扱うことも出来ます。
SQLに慣れている人にはSQLクエリの方が直感的で、複雑な集計や条件処理が簡単に書けるのが魅力があります。
SQLについては下記記事で解説しているので参考にしてみて下さい。

実際にコードを書いて結果を見てみましょう。
from pyspark.sql import SparkSession
# SparkSessionの作成
spark = SparkSession.builder.appName("SQLWithSampleData").getOrCreate()
# データの読み込み
df = spark.read.csv("sample.csv", header=True, inferSchema=True)
# 一時テーブルとして登録
df.createOrReplaceTempView("students")「createOrReplaceTempView」メソッドで、取得したデータを仮想的な「SQLのテーブル」として登録することが出来ます。
これにより今回のDataFrameを”students”テーブルとしてSQL的に扱えるようにしています。
では実際にSQLクエリを実行してみます。
# ① 年齢が30歳以上の人だけを抽出
result = spark.sql("""
SELECT id, name, age, score
FROM students
WHERE age >= 30
""")
result.show()
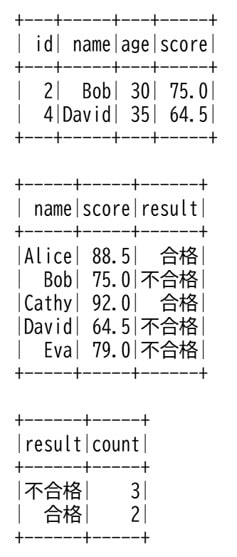
# ② スコアによって「合格/不合格」を表示
result = spark.sql("""
SELECT name, score,
CASE
WHEN score >= 80 THEN '合格'
ELSE '不合格'
END AS result
FROM students
""")
result.show()
# ③ 合格・不合格ごとの人数を集計
result = spark.sql("""
SELECT result, COUNT(*) AS count
FROM (
SELECT CASE
WHEN score >= 80 THEN '合格'
ELSE '不合格'
END AS result
FROM students
)
GROUP BY result
""")
result.show()PySparkでは”spark.sql()“というメソッドでSQLクエリをそのまま実行することが出来ます。
実行結果は下記になります、SQLクエリで意図したデータを抽出出来ていることが確認出来ました。
PySpark まとめ
今回は「PySpark」について見ていきました。
最後にPySparkの特徴をおさらいします。
- データを複数のコンピュータ(クラスター)に分散させて処理する
- データをメモリ上に一時的に保管しながら処理を行うため高速
- 数百万〜数億行などの大規模データでも処理可能
- さまざまなデータフォーマット(テキスト、CSV、JSONなど)に対応
また、Pythonを使ってデータ分析をもっと学びたい方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」を以下の講座チェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムですので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















