
【入門者向け】PythonのPandasの使い方・基本操作について簡単にまとめておく!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です。
データサイエンスにおいて非常に重要なのがデータの前処理加工や可視化の段階。
そんなデータ加工や可視化に非常に有用なのがPythonのPandasというライブラリです。
この記事では、そんなPandasについてまとめていきつつ頻繁に使う記法について自分への備忘録も兼ねてまとめておきたいと思います。
より詳細は、Pandasの公式ドキュメントもしくはQiitaの記事を参考にしてみてください。
ここではサクッとピックアップしてまとめていきます。

目次
Pandasの基本情報

Pandasは誰でも無料で使えるオープンソースであり、データ分析を行う上で必須なライブラリです。
最も使う機会が多いライブラリの1つでもあるので必ずおさえておきましょう!
データ分析ではモデル構築に焦点が当てられガチな節もありますが、正直最も時間を費やすのはデータの加工・集計・可視化です。
その役割を担うのがPandasであり、Pandasを使えば簡易的な記法かつ高速で処理することができるのです。
数多くの処理がありますが、ここではメイン処理として以下のようなタイプに分けてまとめていきます。
・データの読み込み
・データの構造やカラムを確認
・行/列のデータを確認・抽出したい
・データの結合
・データ集計・加工
・データの可視化
それでは、細かく見ていきましょう!
以下の動画でも解説していますので、動画を見ながら学習を進めていただくと理解が深まると思います!
Pandasでデータの読み込み
まずは、データの読み込みが大事ですね!
当たり前ですが、Pandasはインポートしないと使えません。
import pandas as pdほぼpdで定義されることがほとんどなので以下pdと定義してpdで呼びます。
pd.read_csv()
データの読み込みにはread_csv()を使います。
df = pd.read_csv('○○.csv')データを読み込む時は、慣例でdf(データフレーム)と定義することが多いですが何でも問題ないです。
分かりやすい名前を付けておきましょう。
pd.read_exel()
基本CSV形式で読み込みますが、xlsx形式のデータも読み込むことが可能です。
pip install xlrdxlrdをインストールしておいてください。
基本的にcsv形式と同様の記法になりますが、
df = pd.read_excel('○○.xlsx')シートを指定して読み込むこともできます。
df = pd.read_excel('○○.xlsx, sheet_name=○○')シート名を指定しない場合は、最初のシートだけが読み込まれることになります。
データ構造やカラムを確認

続いてデータ構造やカラムを確認していきましょう!
ここでは実際にデータがあった方が分かりやすいので、Kaggleで有名なタイタニックのデータセットを使用します。
ちなみにpandasには既存のサンプルデータセットは入っていないのですが、seabornというライブラリを使えばサンプルデータセットを読み込むことが可能です。
タイタニックのデータであれば以下のように記述することで読み込みが可能。
import seaborn as sns
df = sns.load_dataset('titanic')これで準備万端!実際にデータを確認してみましょう!
df.head()
ざっとデータ構造を確認する時に使います。
df.head()デフォルトだと最初の5行を表示するようになっています。

数値を入れることでその行分を表示してくれますよー!
df.head(3)df.tail()
逆に下から表示したい時はこっち。
df.tail()
df.shape
データフレームの行×列数を知りたい時にこちらを使います。
df.shape(891, 15)
df.columns
カラム名を確認したい時はこれ!
df.columnsIndex([‘survived’, ‘pclass’, ‘sex’, ‘age’, ‘sibsp’, ‘parch’, ‘fare’,
‘embarked’, ‘class’, ‘who’, ‘adult_male’, ‘deck’, ‘embark_town’,
‘alive’, ‘alone’],
dtype=’object’)
df.unique()
ある項目のユニークな値の種類を確認することができます。
df['pclass'].unique()以下のように出力されます。
array([3, 1, 2], dtype=int64)
パッセンジャーズクラス(pclass)は1~3の3つあるということが分かりました。
行・列のデータを確認・抽出したい
続いて行・列のデータを確認・抽出してみましょう!
df.loc[]
df.locは任意の名称を指定して行・列から好きなようにデータを抽出することができます。
df.loc[:3,:'pclass']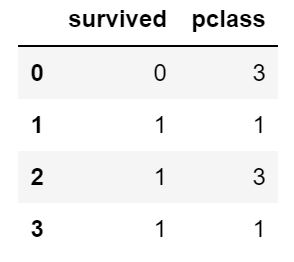
df.iloc[]
一方でdf.iloc[]では、インデックス番号で指定して抽出することができます。
iloc(index-location)です。
df.iloc[:3,:2]複数データを結合したい
複数のテーブルデータを結合したい場合。
SQLだとJOIN句で行うこの処理はPythonだとmergeを使って実行できます。
pd.merge()
ぐう、タイタニックのデータはMerge用には作られていないのでイメージで紹介しますね。
df_aとdf_bというPandasデータフレームがあった時、それらは以下のようにマージすることができます。
pd.merge(df_a, df_b)この時、あるカラムをキーにして結合したい場合は以下のように記述することで可能です。
pd.merge(df_a, df_b, on='○○')特に指定がないときは、共通項目すべてがキーになります。
Inner join、Left join, right joinなどはパラメータhowで指定できます。
pd.concat()
concatでも同様にデータフレームの結合が可能です。
pd.concat([df_a,df_b])Mergeでは横結合であったのに対してconcatは縦結合も可能です。
mergeとconcatの違いはイマイチ分かりにくいのですが、concatは縦方向の結合もすることができ、mergeはキーを指定して柔軟に結合することができます。
以下の記事が詳しいです。
データ集計・加工
続いてデータの集計・加工について見ていきましょう!
集計・加工の延長線上にはデータ分析において非常に重要な特徴量エンジニアリングがあります。

データを上手く集計・加工してモデル構築時の精度を上げましょう!
df.describe()
簡単に要約統計量を確認したい時はこれ!
df.describe()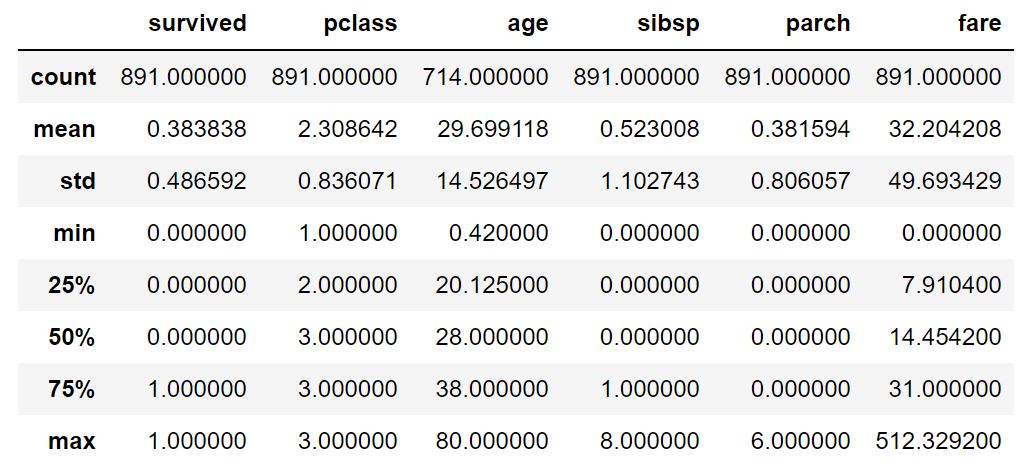
df.value_counts()
出現の回数を測ることができます。
例えばタイタニックのデータに対して以下のように記述すると、
df['survived'].value_counts()このように出力されます。
0 549
1 342
生死ラベルの出現回数が分かります。
df.groupby()
ある項目をキーにして集計することができます。
例えば以下のように記述すると生死でグルーピングした際の年齢の平均が集計できます。
df.groupby('survived')['age'].mean()0 30.626179
1 28.343690
df.sort_values()
ある値をキーにしてデータフレームをソートすることができます。
df.sort_values('age')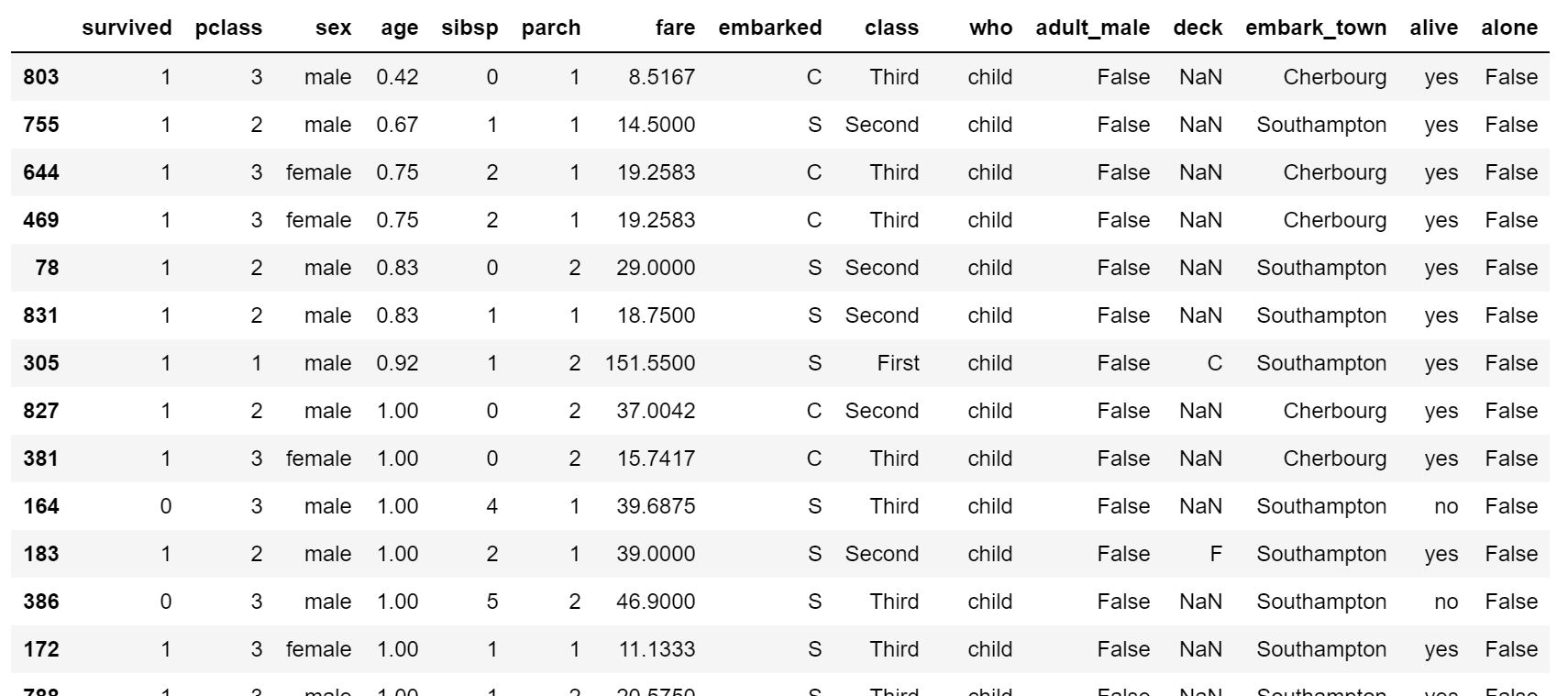
年齢で昇順にソートできているのが分かると思います。
降順にしたい場合は、以下のようにすれば大丈夫です。
df.sort_values('age',ascending=False)df.isnull()
欠損値処理はデータ分析において非常に重要な部分。
欠損値をどのように処理するのかによって明暗が分かれることも多々あります。
まずは、欠損値を確認しましょう!
df.isnull().sum()によって各カラムの欠損値の数を集計することができます。
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
df.dropna()
続いて欠損値を処理する方法について見ていきましょう!
df.dropna()dropnaを使うことで欠損値が1つでも入っている行を削除することができます。
処理後の行数を確認してみると、
df.dropna().shape(182, 15)
182行に減っていることが分かります。
df.fillna()
fillna()を使うことで欠損値を埋めることができます。
df['age'].head(10)0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
5 NaN
6 54.0
7 2.0
8 27.0
9 14.0
Name: age, dtype: float64
年齢の欠損値を埋めてみましょう!
df['age'].fillna(0).head(10)0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
5 0.0
6 54.0
7 2.0
8 27.0
9 14.0
Name: age, dtype: float64
pd.get_dummies()
ダミー変数化とは多クラスのカテゴリーを01ラベルで表す特徴量として展開すること。
例えば以下のようなケースだと、
| カテゴリ |
| A |
| B |
| A |
| C |
| ・・・ |
| A |
| B |
ダミー変数化をすることにより以下のようなデータ構造に変換されます。
| A | B |
| 1 | 0 |
| 0 | 1 |
| 1 | 0 |
| 0 | 0 |
| 1 | 0 |
| 0 | 1 |
この時、Aが0でBが0であればCということが明示的に分かるのでCのカラムは必要ありません。
逆にCのカラムを追加してしまうと変数同士の重複が起き「多重共線性」という問題が生じ推定精度が不安定になります。
pd.get_dummies()を用いることで簡単にダミー変数を生成することができます。
pd.get_dummies(df)
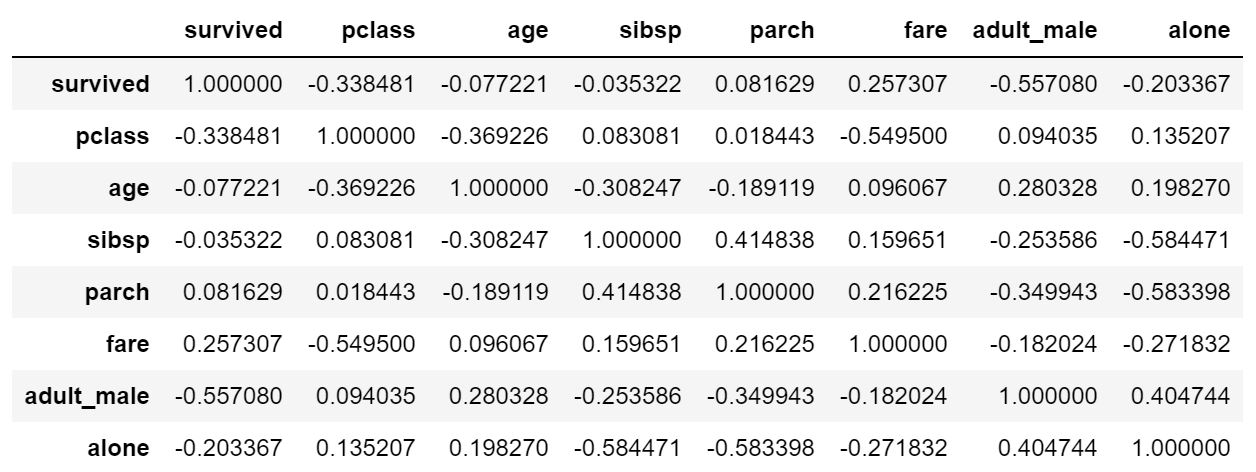
df.corr()
corr()で相関関係を簡単に確認することが可能です。
df.corr()
Pandas勉強方法

Pandas含めPythonの勉強は、実際にデータ分析を行う上で非常に重要です。
ただ目的のないPandas勉強は正直意味がないしモチベーションは続きません。
ここでは、pandas含めPythonの基礎文法の勉強法についてまとめておきます!
自分で進められる自信がある人
自分で進められる自信のある人はUdemyの教材を視聴もしくはPyQを自力で進めた後Kaggleに挑戦してみることをオススメします。
Pandasを使ったデータ分析についてはUdemyの中でも以下の僕の講座がオススメなので是非チェックしてみてください!
【初学者向け】データ分析コンペで楽しみながら学べるPython×データ分析講座
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 4時間 |
| 【レベル】 | 初級~中級 |
僕自身がUdemyの色んなコースを受けてみた中で、他のコースにはないこんなコースあったらいいなみたいなコースを作ってみました。
このコースは、なかなか勉強する時間がないという方に向けてコンパクトに分かりやすく必要最低限の時間で重要なエッセンスを学び取れるように作成しています。
アニメーションを使った概要編とハンズオン形式で進む実践編に分かれており、概要編では体系的にデータ分析・機械学習導入をまとめています。
データサイエンスの基礎について基本のキから学びつつ、なるべく堅苦しい説明は抜きにしてイメージを掴んでいきます。
統計学・機械学習の基本的な内容を学び各手法の詳細についてもなるべく概念的に分かりやすく理解できるように学んでいきます。
そしてデータ分析の流れについては実務に即したCRISP-DMというフレームワークに沿って体系的に学んでいきます!
データ分析というと機械学習でモデル構築する部分にスポットがあたりがちですが、それ以外の工程についてもしっかりおさえておきましょう!
続いて実践編ではデータコンペの中古マンションのデータを題材にして、実際に手を動かしながら機械学習手法を実装していきます。
ここでは、探索的にデータを見ていきながらデータを加工し、その上でLight gbm という機械学習手法を使ってモデル構築までおこなっていきます。
是非興味のある方は受講してみてください!
Twitterアカウント(@statistics1012)にメンションいただければ2000円以下になる講師クーポンを発行いたします!
PyQはPython特化のオンライン学習サービスで、ひたすらPythonコーディングを行うのにオススメです。
データサイエンスの理論まわりはあまり深く扱っていません。
そしてある程度Pythonの素地が出来上がった後は、データ分析コンペティションのKaggleやNishikaなどに挑戦してみることをオススメします!
企業から提供されるデータなどを基にお題に沿って精度の高いモデルを構築していきます。

自分で進められるモチベが保てない人
自分で進められるモチベが保てない人には半ば強制的に勉強を行うプログラミングスクールをオススメします!
僕自身、あまりモチベーションをコントロールするのが上手くない方なのでプログラミングスクールを受講した過去があります。
Pythonを学ぶならAI特化のAidemy Premium Planがオススメです。
複雑なアプリケーション作成までは出来ませんがPythonの基本文法からディープラーニング実装までは非常に手厚くサポートされています。
ただプログラミングスクールはどこも正直価格が非常に高い・・・
そこで当サイトが展開するスタアカ(スタビジアカデミー)!

手前味噌ですが、今までの経験を詰め込んでかつ価格をどこよりもリーズナブルに抑えているコスパ最強のスクールだと自負しています!
ご受講お待ちしております!
他のデータサイエンス系のプログラミングスクールとあわせて以下で比較していますので客観的な観点で選んでみてください!

PythonのPandas使い方 まとめ
本記事では、Pandasについて見てきました!
Pandasはよく使われるライブラリでPythonを使う上では、必ずおさえておきたい内容ですね!
ぜひPandasを使ってみましょう!
ちなみにPandasと同じようにデータ過去集計処理に使えるPolarsというライブラリも便利で処理速度が速くオススメです。興味のある方はチェックしてみてください!

また、Pythonの勉強方法については以下の記事でまとめています!

また、データ分析によく使われるExcelの勉強法やpandasを使ったExcel操作について学びたい方は以下の記事をチェックしてみてください!
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















