【図解で解説】LightGBMの仕組みとPythonでの実装を見ていこう!

こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
様々なデータ分析コンペティションで上位入賞しているのが勾配ブースティングを使ったモデル!
決定木とブースティングを用いたXgboostが2014年に考案され、今でも最前線を戦う最強の手法ではあるのですが・・・
そんなXgboostの絶対的地位を脅かす存在がLightGBM!!
LightGBMの構造はXgboostと非常に近いものがありますが、計算負荷が少なくXgboostから置き換わりつつある手法です。

この記事では、そんなLightGBMについて徹底的に見ていきます!
LightGBMの特徴と理論、Pythonでの実装方法について見ていきましょう!
Nishikaというデータ分析コンペの不動産データを使って実践していきつつ、最終的には有名なMnistという画像認識データセットを使ってディープラーニングとの比較をしていきます!
気になるところへ読み飛ばす
目次
LightGBMとは

まずはLightGBMの概要について見ていきましょう!
以下の動画でも解説していますのであわせてご覧ください!
LightGBMは2016年にリリースされ、Xgboostを改良した手法になっています。
XgboostのgboostはGradient boost(勾配ブースティング)を示しており、LightGBMのGBMも同じくGradient boosting machine(勾配ブースティング)を示しています。
すなわち両手法とも基本的な考え方は同じ。
どちらも弱学習器である決定木を勾配ブースティングによりアンサンブル学習した手法になります。
LightGBM speeds up the training process of conventional GBDT by up to over 20 times while achieving almost the same accuracy.
(引用:”Google-LightGBM: A Highly Efficient Gradient Boosting
Decision Tree“)
論文にある通り、LightGBMは通常の決定木を用いた勾配ブースティングよりも高速で解を求めることができるとあります。
それゆえにLightという名前が用いられているのですね。
ただ必ずしも精度が良くなるとは結論付けられておりません。
精度を上げるためには手法の優劣よりも特徴量によって決まるコトが多いです。
その特徴量の精査にかける時間を取るためにはモデル構築の時間が早い手法を使う方が有利なのです。
そのため、時間の限られたコンペティションではLightGBMを使うユーザーが非常に多くなってきています。
LightGBMも含めた機械学習の手法について体系的に学びたい方は当メディアが運営するスタアカがオススメ!
機械学習の他にもディープラーニングや生成AIのコースも用意しているので是非チェックしてみて下さい。
LightGBMの特徴
さてLightGBMの概念について見てきましたが、ここで簡単にLightGBMの特徴と理論について確認しておきましょう!
決定木と勾配ブースティングを組み合わせた手法
LightGBMは決定木と勾配ブースティングを組み合わせた手法です。
決定木とは、ある変数の値によって集団をグループ分けしていく手法です。
例えば、2変数であれば以下のように分けることができます。
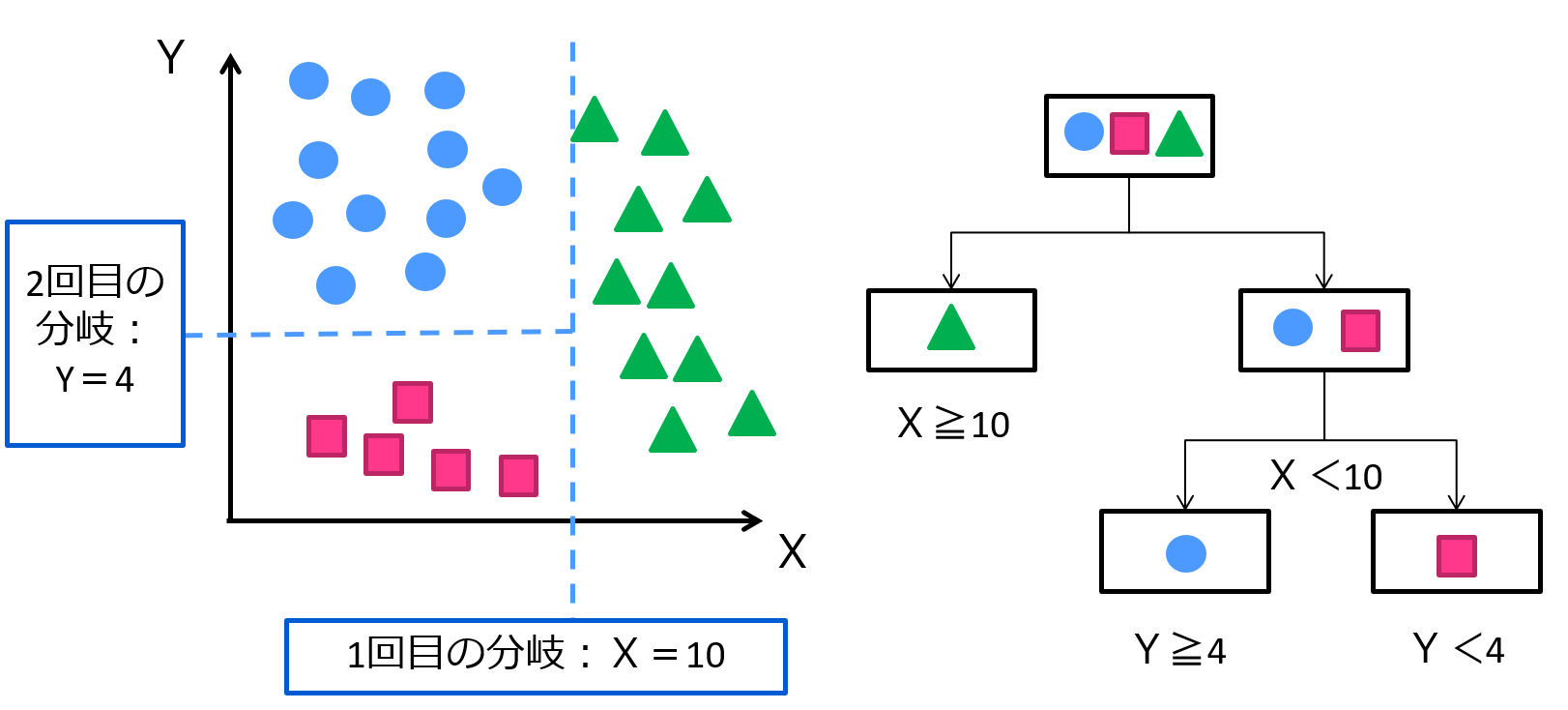
タイタニック号のデータセットを決定木で分類していく例などが有名でしょう。
ただ決定木は、単体ではそれほど精度が高くなく、過学習もしやすいです。
そのような性能の低い手法を弱学習器と呼びます。
そして弱学習器を最強の手法に生まれ変わらせるのがアンサンブル学習という学習方法。
アンサンブル学習では複数の弱学習器を用いて学習をおこなっていきます。
アンサンブル学習の中でもバギングは並列的に、ブースティングは直列的に学習していきます。
バギングは並列に学習を進めて多数決を取るイメージ。
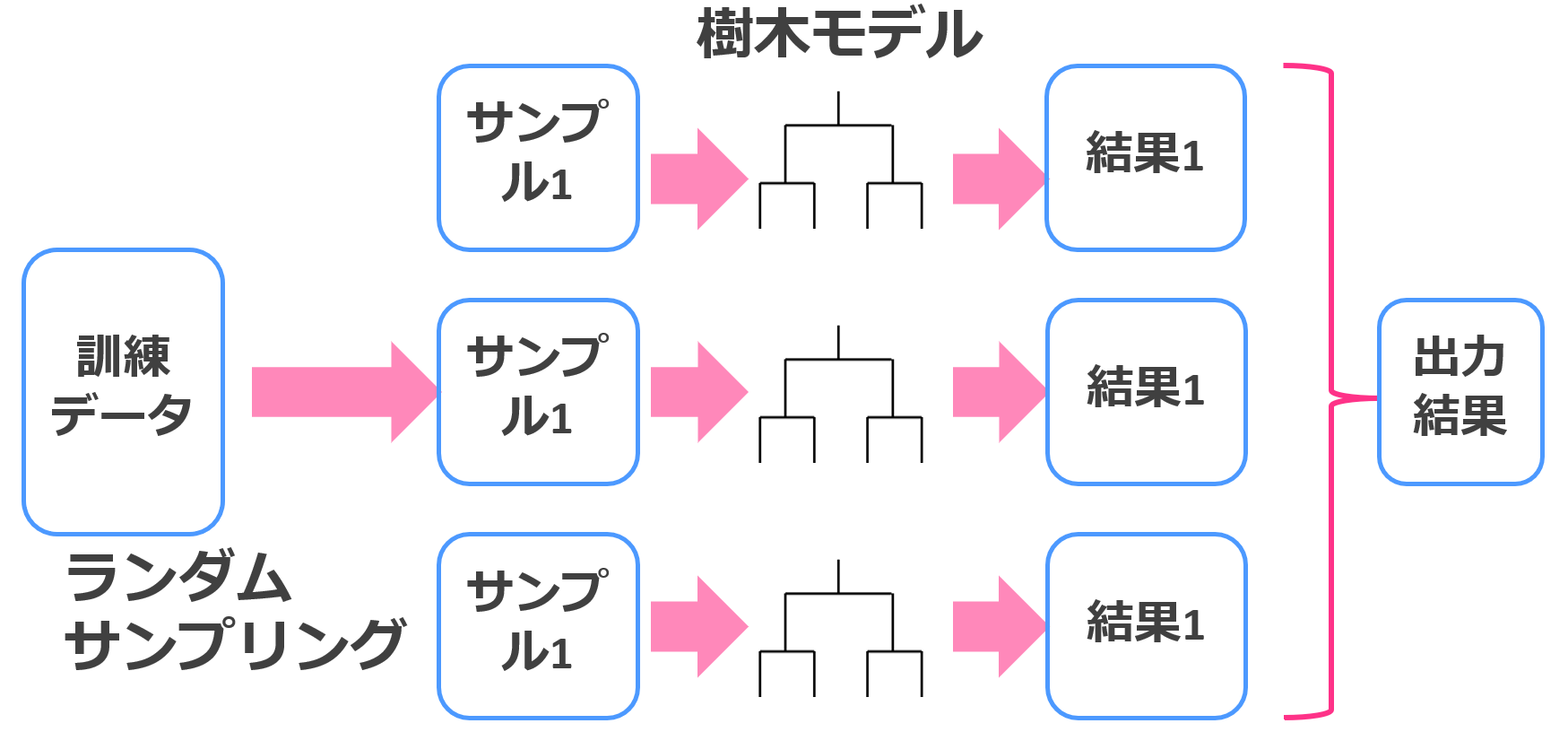
決定木×バギングはランダムフォレストと呼ばれ、これも強力な機械学習手法です。
一方、勾配ブースティングでは直列に学習を進めていきます。
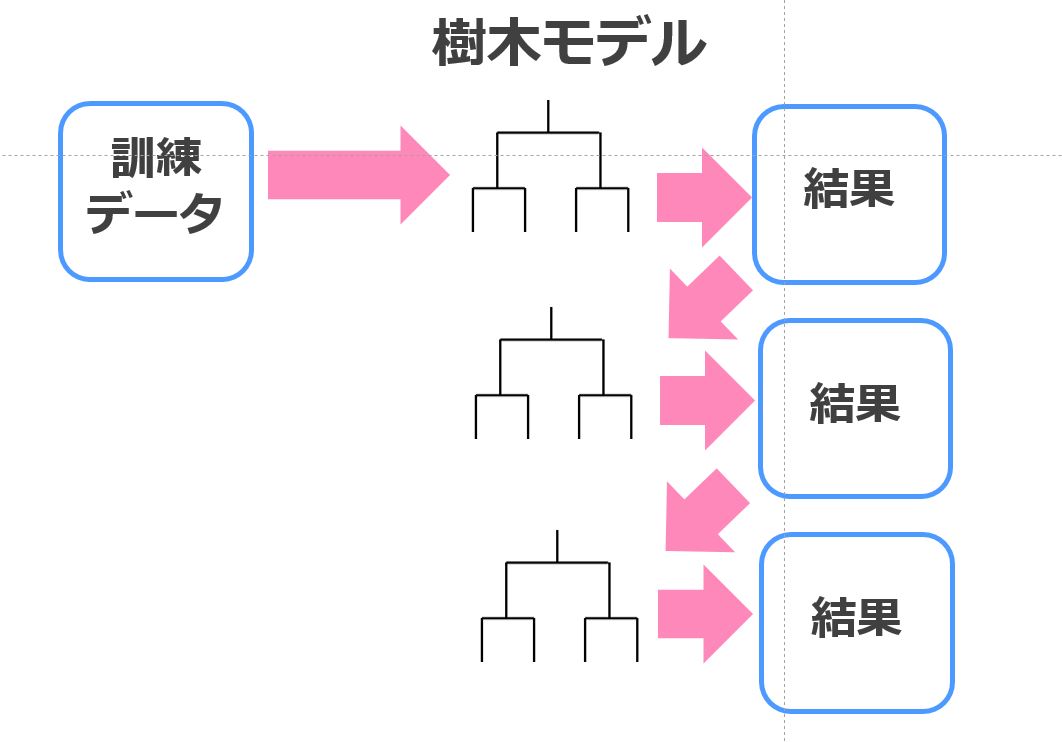
この学習のプロセスにおけるミソは、前回のモデルで生じた誤差を訓練データとして次の学習が行われるということ。
これにより、より誤差が少ないモデルが構築されるようになるというわけです。
そして、この決定木×ブースティングの手法こそLightGBMの根幹です。
決定木の学習方法が違う
決定木×勾配ブースティングだけではXgboostもLightGBMも変わりません。
LightGBMの特徴は、その学習方法にあります。
Xgboostを含む通常の決定木モデルは以下のように階層をあわせて学習していきます。
それをLevel-wiseと呼びます。
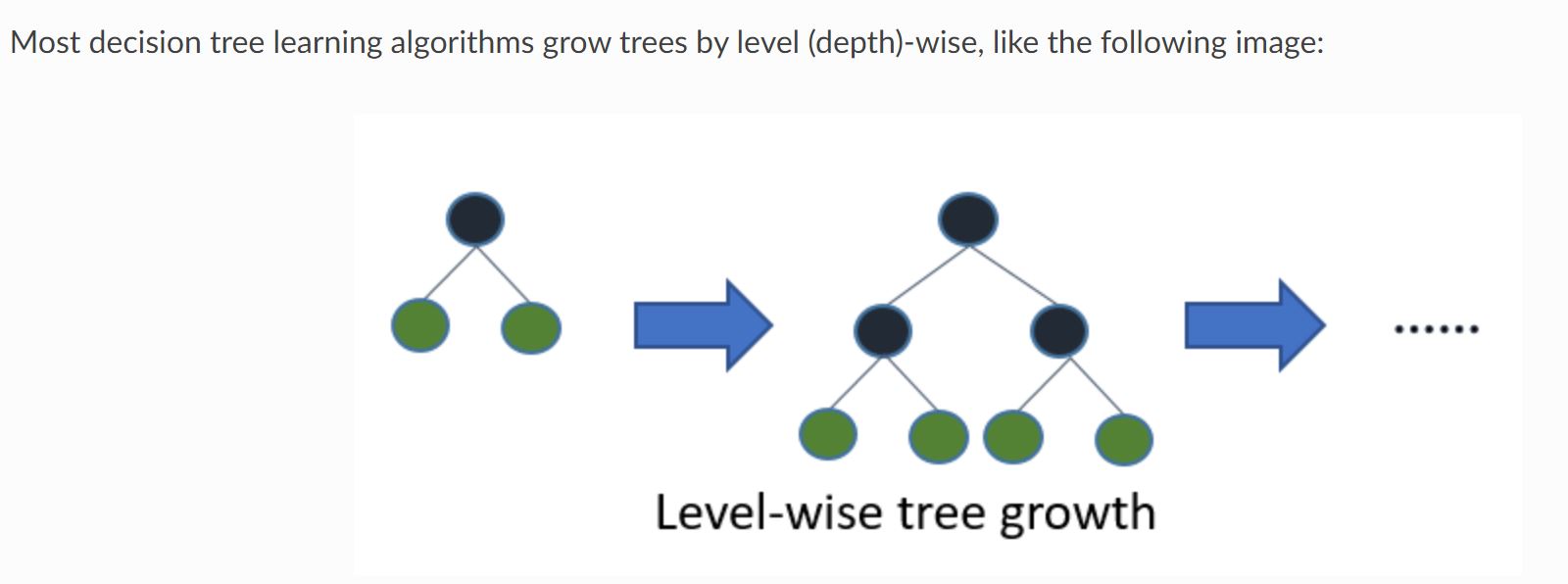
(引用元:LightGBM公式リファレンス)
一方LightGBMは以下のように葉ごとの学習を行います。これをleaf-wise法と呼びます。
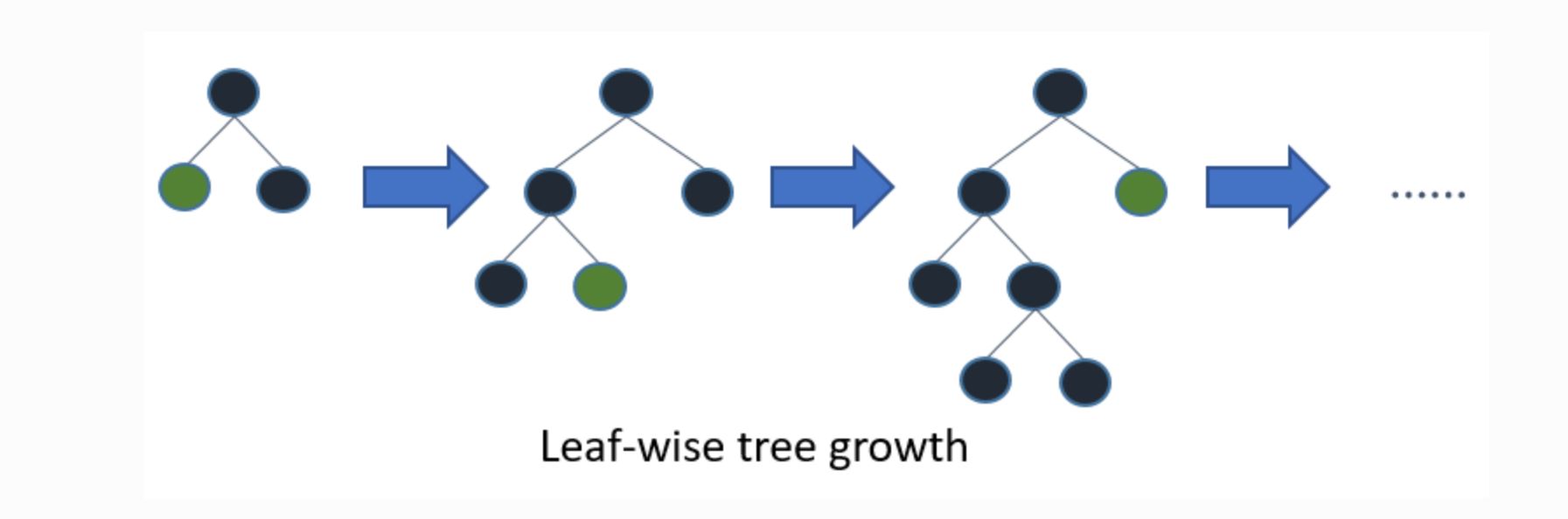
(引用元:LightGBM公式リファレンス)
これにより、ムダな学習をしなくても済むためより効率的に学習を進めることができます。
LightGBMの解到達スピードが速いゆえんはここにあるのです。
過学習しやすい
ただ、先ほどのleaf-wise法は学習の構造的に過学習に陥りやすいという特徴があります。
過学習とは訓練データにフィッティングし過ぎて未知データに対する予測精度が下がってしまう現象のことを言います。

特にデータセットのサンプル数が少ない時は過学習のおそれがあるため注意が必要です。
学習する層の深さを一定以下に抑えるなど学習過程に制御を加えて過学習をしないようにしましょう!
特徴量ヒストグラム化
LightGBMでは、特徴量をヒストグラム化して学習を行います。
ツリーの枝分かれポイントを全網羅的に調べる必要がありましたが、ヒストグラム化することで計算負荷がだいぶおさえることができます。
これにより、学習がスピードアップし、メモリ使用量が削減されるのです。
データコンペの回帰タスクに対してLightGBMをPython実装

それではいざ実践!
まずは、国産データコンペ Nishikaの「中古マンション価格予測」というトレーニングコンペのデータに対してLightGBMを実装してみたいと思います。
Pythonであればいとも簡単に実装することができるんです!
まず![]() Nishikaに会員登録をして中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
Nishikaに会員登録をして中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
学習データには複数CSVが入っているので、それらをglobで結合させてデータフレーム化していきます。
globは、ディレクトリに格納されたファイル名を抽出するのに便利なライブラリです。

import glob
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as mae
files = glob.glob("train/*.csv")
data_list = []
for file in files:
data_list.append(pd.read_csv(file, index_col=0))
df = pd.concat(data_list)カラムを見てみると・・・

欠損値があったり、数値型で欲しいデータが文字列型になっていたりするので前処理を施していきます!
def data_pre(df):
nonnull_list = []
for col in df.columns:
nonnull = df[col].count()
if nonnull == 0:
nonnull_list.append(col)
df = df.drop(nonnull_list, axis=1)
df = df.drop("市区町村名", axis=1)
df = df.drop("種類", axis=1)
dis = {
"30分?60分":45,
"1H?1H30":75,
"2H?":120,
"1H30?2H":105
}
df["最寄駅:距離(分)"] = df["最寄駅:距離(分)"].replace(dis).astype(float)
df["面積(㎡)"] = df["面積(㎡)"].replace("2000㎡以上", 2000).astype(float)
y_list = {}
for i in df["建築年"].value_counts().keys():
if "平成" in i:
num = float(i.split("平成")[1].split("年")[0])
year = 33 - num
if "令和" in i:
num = float(i.split("令和")[1].split("年")[0])
year = 3 - num
if "昭和" in i:
num = float(i.split("昭和")[1].split("年")[0])
year = 96 - num
y_list[i] = year
y_list["戦前"] = 76
df["建築年"] = df["建築年"].replace(y_list)
year = {
"年第1四半期": ".25",
"年第2四半期": ".50",
"年第3四半期": ".75",
"年第4四半期": ".99"
}
year_list = {}
for i in df["取引時点"].value_counts().keys():
for k, j in year.items():
if k in i:
year_rep = i.replace(k, j)
year_list[i] = year_rep
df["取引時点"] = df["取引時点"].replace(year_list).astype(float)
for col in ["都道府県名", "地区名", "最寄駅:名称", "間取り", "建物の構造", "用途", "今後の利用目的", "都市計画", "改装", "取引の事情等"]:
df[col] = df[col].astype("category")
return df
df = data_pre(df)
この前処理に関してここでは詳細は省きますが、全てが欠損値になっているカラムを削除して、「最寄り駅・面積・建築年・取引時点」に関して変換をおこなっています。
そして前処理をおこなったデータに対してLightGBM を実装!
df_train, df_val =train_test_split(df, test_size=0.2)
col = "取引価格(総額)_log"
train_y = df_train[col]
train_x = df_train.drop(col, axis=1)
val_y = df_val[col]
val_x = df_val.drop(col, axis=1)
trains = lgb.Dataset(train_x, train_y)
valids = lgb.Dataset(val_x, val_y)
params = {
"objective": "regression",
"metrics": "mae"
}
model = lgb.train(params, trains, valid_sets=valids, num_boost_round=1000, early_stopping_rounds=100)簡単ですね!
このタスクでは評価指標がMAE(平均絶対誤差)であり、結果は
0.0764となりました!
パラメータチューニングや特徴量エンジニアリングによってさらに精度が上がりますので是非色々と手を動かしてみてください!
データコンペですのでテストデータで予測値を算出し提出するところまでやってみましょう!
df_test = pd.read_csv("test.csv", index_col=0)
df_test = data_pre(df_test)
predict = model.predict(df_test)
df_test["取引価格(総額)_log"] = predict
df_test[["取引価格(総額)_log"]].to_csv("submit_test.csv")簡単に実装できましたねー!
全コードは以下になります!
画像認識タスクに対してLightGBMをPython実装!

続いて画像認識タスクに対してLightGBMを適用させていきます!
import lightgbm as lgb
import pandas as pd
import numpy as np
from tensorflow.keras.datasets import mnist
from sklearn.model_selection import train_test_split
今回は、Mnistというよく画像認識に使われるデータセットを用いていきます。
このデータセットには0~9の文字が様々なカタチで書かれたサンプルが入っています。
# Kerasに付属の手書き数字画像データをダウンロード
np.random.seed(0)
(X_train, labels_train), (X_test, labels_test) = mnist.load_data()
これにより学習データ60000個とテストデータ10000個に分けられます。
# Training set を学習データ(X_train, labels_train)と検証データ(X_validation, labels_validation)に8:2で分割する
X_train,X_validation,labels_train,labels_validation = train_test_split(X_train_base,labels_train_base,test_size = 0.2)
# 各画像は行列なので1次元に変換→X_train,X_validation,X_testを上書き
X_train = X_train.reshape(-1,784)
X_validation = X_validation.reshape(-1,784)
X_test = X_test.reshape(-1,784)
#正規化
X_train = X_train.astype('float32')
X_validation = X_validation.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_validation /= 255
X_test /= 255
さらにこの部分で、データセットの変数を行列から1次元に変換し正規化しています。
# 訓練・検証データの設定
train_data = lgb.Dataset(X_train, label=labels_train)
eval_data = lgb.Dataset(X_validation, label=labels_validation, reference= train_data)
#経過時間計測
import time
start = time.time()
#light gbm モデル構築
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'multiclass',
'num_class': 10,
}
gbm = lgb.train(
params,
train_data,
valid_sets=eval_data,
num_boost_round=100,
early_stopping_rounds=10,
)パラメータを決定しLightGBMを回すのはこの部分。
実際にLightGBMで推定してみると・・・
preds = gbm.predict(X_test)
preds
y_pred = []
for x in preds:
y_pred.append(np.argmax(x))
from sklearn.metrics import accuracy_score
print('accuracy_score:{}'.format(accuracy_score(labels_test, y_pred)))
#経過時間
print('elapsed_timetime:{}'.format(time.time()-start))0.972という推定精度が得られました!
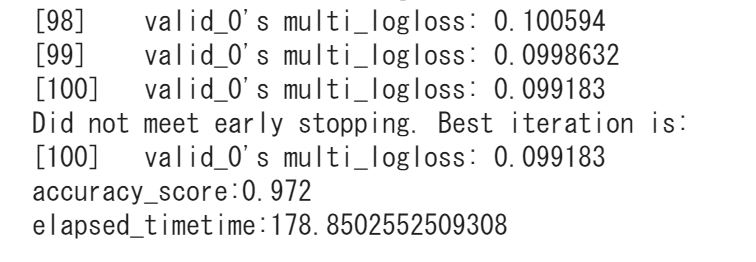
だいぶ高い正答率!
全コードを以下にまとめておきます。
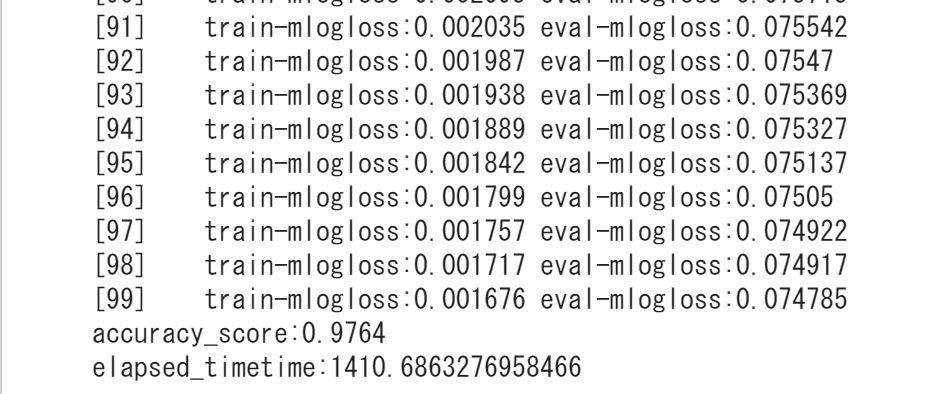
そして目を見張るべきはこの処理時間!LightGBMでは、178秒で処理が終了しているんです。
Xgboostでも同じデータセットを分類していますが、なんと1400秒もかかっています。

LightGBMとXgboostとCatboostの3大勾配ブースティング手法を比較した記事を以下にまとめていますのでこちらもチェックしてみてください!

ちなみにディープラーニングで回した時の推定精度は、0.9696!
以下がディープラーニングのコードになります。
詳しくは以下の記事でまとめています!

LightGBMの強力さが分かっていただけたと思います。
LightGBM まとめ

ここまでご覧いただきありがとうございました!
本記事では。LightGBMについて見てきました!
LightGBMは強力な手法ですがPythonで比較的簡単に実装できます。
最後にLightGBMの特徴についてまとめておきましょう!
・決定木と勾配ブースティングを組み合わせた手法
・決定木の学習方法が違う
・過学習しやすい
データセットによっては、ディープラーニングを作り込むよりも勾配ブースティングの方が強力なコトは多いです。
LightGBMについてもっと勉強したい方は、当メディアでLightGBMを含めた様々な機械学習手法やデータサイエンスの知識を体系的に学べるスタアカ(スタビジアカデミー)というスクールを展開していますので是非チェックしてみてください!
スタアカ(スタビジアカデミー)
 公式サイト:https://toukei-lab.com/achademy/
公式サイト:https://toukei-lab.com/achademy/
| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
また、LightGBMを使ったデータ分析については以下のUdemy講座でより詳しく解説していますので是非チェックしてみてください!
【初学者向け】データ分析コンペで楽しみながら学べるPython×データ分析講座
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 4時間 |
| 【レベル】 | 初級~中級 |
僕自身がUdemyの色んなコースを受けてみた中で、他のコースにはないこんなコースあったらいいなみたいなコースを作ってみました。
このコースは、なかなか勉強する時間がないという方に向けてコンパクトに分かりやすく必要最低限の時間で重要なエッセンスを学び取れるように作成しています。
アニメーションを使った概要編とハンズオン形式で進む実践編に分かれており、概要編ではYoutubeの内容をより体系的にデータ分析・機械学習導入の文脈でまとめています。
データサイエンスの基礎について基本のキから学びつつ、なるべく堅苦しい説明は抜きにしてイメージを掴んでいきます。
統計学・機械学習の基本的な内容を学び各手法の詳細についてもなるべく概念的に分かりやすく理解できるように学んでいきます。
そしてデータ分析の流れについては実務に即したCRISP-DMというフレームワークに沿って体系的に学んでいきます!
データ分析というと機械学習でモデル構築する部分にスポットがあたりがちですが、それ以外の工程についてもしっかりおさえておきましょう!
続いて実践編ではデータコンペの中古マンションのデータを題材にして、実際に手を動かしながら機械学習手法を実装していきます。
ここでは、探索的にデータを見ていきながらデータを加工し、その上でLight gbm を使ってモデル構築までおこなっていきます。
是非興味のある方は受講してみてください!
Twitterアカウント(@statistics1012)にメンションいただければ2000円以下になる講師クーポンを発行いたします!
他の勾配ブースティング手法やディープラーニングについては以下の記事でまとめています。
また、機械学習全般の手法を以下にまとめていますのでこちらもあわせて見てみてください!

機械学習やデータサイエンス、Pythonの勉強ロードマップは以下です!



 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!