
ハイパーパラメータのチューニングについて解説!PythonでのLightGBM実装と一緒に見ていこう!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です。
機械学習モデル構築において精度を上げる方法は多くありますが、その中でも最後の手段として利用されるのがハイパーパラメータのチューニング!

Kaggleなどのデータ分析コンペでは最後の最後まで微小な精度改善が求められるためパラメータチューニングは必須のスキルです。
ハイパーパラメータのチューニングについて解説したあと、その中の一部を利用して実際にハイパーパラメータチューニングを行っていきましょう!
パラメータチューニングについては以下の動画でも解説していますので是非参考にしてみてください!
また、以下のUdemy講座でパラメータチューニングについて詳しく解説しているので、さらに深く知りたいという方はチェックしてみてください!
【初心者向け】パラメータチューニング入門!Pythonで機械学習モデルを構築しパラメータチューニングで精度向上させよう!
| 【時間】 | 4.5時間 |
|---|---|
| 【レベル】 | 初級 |
パラメータチューニングについて学びたいならこのコース!
今なら購入時に「B3PS3TPL8ZWG」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
目次
ハイパーパラメータチューニングとは

まず、ハイパーパラメータチューニングとはなんでしょうか?
非常に簡単な例で考えてみましょう!
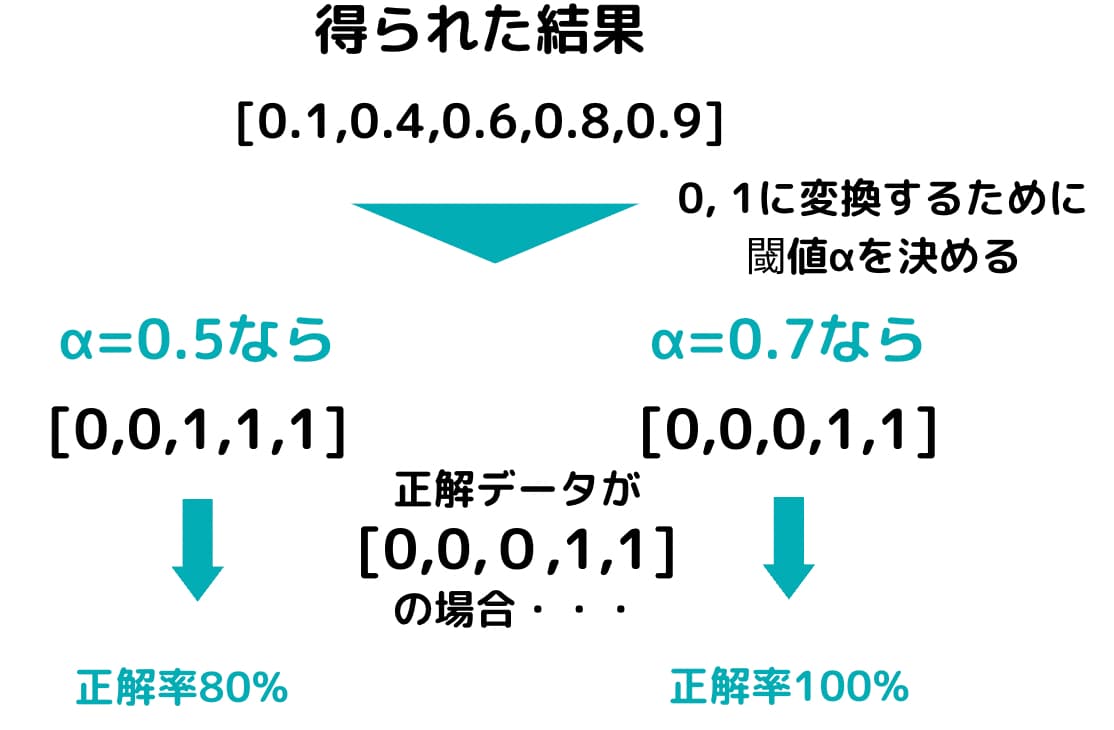
0~1で出力される結果に対して0か1に振り分けたいとします。
この時[0.1,0.4,0.6,0.8,0.9]という結果が得られたとします。
この時、振り分ける閾値を0.5に設定すれば、それぞれの出力結果は[0,0,1,1,1]となります。
しかし閾値を0.7に設定すれば[0,0,0,1,1]になります。
この閾値は可変する値でありそれによって出力結果が変わるため、ある種のパラメータと考えることが出来ます。
このような可変値が機械学習の各手法のアルゴリズムには存在し、それらをハイパーパラメータと呼ぶのです。
先ほどの例で正解データは[0,0,0,1,1]だったとします。
その場合、閾値パラメータを0.5に設定した場合は[0,0,1,1,1]となり正答率が80%になります。
しかし閾値パラメータを0.7に設定した場合は[0,0,0,1,1]となるので正答率は100%となります。
このようにパラメータを調整することで精度を向上させることができるのです。
このようなパラメータを調整して精度の最適化をはかっていくことをパラメータチューニングと呼びます。
ただ、機械学習手法のハイパーパラメータはこんなに単純ではありません。
複数のハイパーパラメータが複合的に組み合わさっているのです。
次の章ではそんなハイパーパラメータの種類について見ていきましょう!
各機械学習手法のハイパーパラメータの種類
ハイパーパラメータについて学んできましたが、実際にハイパーパラメータにはどんな種類があるのでしょうか?
例えば、この記事で実装していくLightGBMという勾配ブースティング木の手法のパラメータ種類について見ていきましょう!
LightGBMとは、決定木とアンサンブル学習であるブースティングを組合わあせた手法でありKaggleなどのデータ分析コンペで非常によくつかわれる強力な機械学習手法です。
イメージ的には複数の決定木を直列につなぎ精度を改善していくイメージです。
詳しくは以下の記事で解説しているので見てみてください!
そんなLightGBMですが、実は大量のパラメータが存在します。
これでもかというくらい大量のパラメータが存在するのですが、有名どころをピックアップしていきましょう!
以下のリファレンスで細かいハイパーパラメータについて確認することが可能です。
Objective:機械学習タスクがどんなタスクなのかを決定するハイパーパラメータ。回帰なのか2値分類なのか多値分類なのか。デフォルトはregression。
metrics:モデルの評価指標を示すハイパーパラメータ。maeやrmseなど。デフォルトはObjectiveと紐づく評価指標が設定されます。
num_iterations:ブースティングの繰り返し数を示すハイパーパラメータ。デフォルトは100。
learning_rate:学習率を表すハイパーパラメータ。勾配ブースティングの際に勾配降下法という最適化手法を用いるがその時の勾配学習の進度。デフォルトは0.1。num_iterationsが小さい時はある程度大きいlearning_rateを取らないと最適解を得られない。
num_leaves:決定木にある最大ノードの数を示すハイパーパラメータ。デフォルトは31。
max_depth:木の最大の深さを示すハイパーパラメータ。デフォルトは-1。0以下の場合は制限なしになる。データ数が少なくmax_depthが制限なしだと過学習に陥る可能性がある。
early_stopping_round:イテレーションの強制終了するハイパーパラメータ。num_iterationsにおいてearly_stopping_roundで設定した回数分Validationデータの精度が向上しなければ強制終了する。デフォルトは0
verbosity:学習の経過の表示を制御するハイパーパラメータ。デフォルトは1で1回のイテレーションごとに経過が表示される。10に設定すると10回ごとに表示される。−1に設定すると表示されなくなる。
これ以外にも非常に多くのハイパーパラメータがあるのでぜひチェックしてみてください!
ハイパーパラメータチューニングの種類

ここまでで、ハイパーパラメータについて見てきましたがこんなに大量のパラメータの中から最適な組み合わせをどのように見つけていけばよいのでしょうか?
実はパラメータチューニングにはたくさんの種類があるんです。
グリッドサーチ
グリッドサーチとは、最適化をはかりたいハイパーパラメータ全ての組み合わせを調べる手法です。
ハイパーパラメータの組み合わせの交点であるグリッドを全てサーチするイメージからグリッドサーチを呼ばれています。
無難な手法ですが、ハイパーパラメータの多い手法に対しては組み合わせ数が膨大になってしまい現実的ではありません。
またグリッドとして調べる範囲は自分で設定しないといけなく網羅的に調べることができるわけではありません。
例えば、先ほどのLightGBMの例であれば、
num_leavesは[20,30,40,50]
learning_rateは[0.1,0.01,0.001,0.0001]
というように設定してそれぞれの組み合わせの最適解を調べます。
ランダムサーチ
グリッドサーチはハイパーパラメータの勘所がつかめている場合は有効ですが、非常に膨大なパラメータの組み合わせを人が設定しなくてはいけないため時間がかかる上に勘所がつかめていない場合は筋の悪いパラメータを選んでしまう可能性もあります。
そこで有効なのがランダムサーチ。
ランダムサーチではハイパーパラメータの組み合わせをランダムに探索的に抽出し、指定した回数分繰り返して最適な組み合わせを探ります。
ただ、試行回数が少ないと最適なハイパーパラメータが見つかりづらい弱点もあります。
ベイズ最適化
ベイズ最適化は、ベイズ理論を用いたパラメータ最適化手法で、過去のハイパーパラメータの組み合わせの解に基づいて、筋の良さそうな組み合わせの周りを探索していく手法です。
一般的にランダムサーチよりも効率的に解を探し出すことができます。
ハイパーパラメータチューニングをPythonで実装!

それでは、ここまでの内容をふまえた上でハイパーパラメータのチューニングをおこなっていきましょう!
LightGBMという強力な機械学習手法を使ってパラメータチューニングをおこなっていきます。
国産データコンペ Nishikaの「中古マンション価格予測」というトレーニングコンペのデータに対してLightGBMを実装し、パラメータチューニングをおこなっていきます。
まず Nishikaに会員登録し中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
学習データには複数CSVが入っているので、それらをglobで結合させてデータフレーム化していきます。
globは、ディレクトリに格納されたファイル名を抽出するのに便利なライブラリです。

import glob
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as mae
files = glob.glob("train/*.csv")
data_list = []
for file in files:
data_list.append(pd.read_csv(file, index_col=0))
df = pd.concat(data_list)カラムを見てみると・・・

欠損値があったり、数値型で欲しいデータが文字列型になっていたりするので前処理を施していきます!
def data_pre(df):
nonnull_list = []
for col in df.columns:
nonnull = df[col].count()
if nonnull == 0:
nonnull_list.append(col)
df = df.drop(nonnull_list, axis=1)
df = df.drop("市区町村名", axis=1)
df = df.drop("種類", axis=1)
dis = {
"30分?60分":45,
"1H?1H30":75,
"2H?":120,
"1H30?2H":105
}
df["最寄駅:距離(分)"] = df["最寄駅:距離(分)"].replace(dis).astype(float)
df["面積(㎡)"] = df["面積(㎡)"].replace("2000㎡以上", 2000).astype(float)
y_list = {}
for i in df["建築年"].value_counts().keys():
if "平成" in i:
num = float(i.split("平成")[1].split("年")[0])
year = 33 - num
if "令和" in i:
num = float(i.split("令和")[1].split("年")[0])
year = 3 - num
if "昭和" in i:
num = float(i.split("昭和")[1].split("年")[0])
year = 96 - num
y_list[i] = year
y_list["戦前"] = 76
df["建築年"] = df["建築年"].replace(y_list)
year = {
"年第1四半期": ".25",
"年第2四半期": ".50",
"年第3四半期": ".75",
"年第4四半期": ".99"
}
year_list = {}
for i in df["取引時点"].value_counts().keys():
for k, j in year.items():
if k in i:
year_rep = i.replace(k, j)
year_list[i] = year_rep
df["取引時点"] = df["取引時点"].replace(year_list).astype(float)
for col in ["都道府県名", "地区名", "最寄駅:名称", "間取り", "建物の構造", "用途", "今後の利用目的", "都市計画", "改装", "取引の事情等"]:
df[col] = df[col].astype("category")
return df
df = data_pre(df)
この前処理に関してここでは詳細は省きますが、全てが欠損値になっているカラムを削除して、「最寄り駅・面積・建築年・取引時点」に関して変換をおこなっています。
そして前処理をおこなったデータに対してLightGBM を実装!
df_train, df_val =train_test_split(df, test_size=0.2)
col = "取引価格(総額)_log"
train_y = df_train[col]
train_x = df_train.drop(col, axis=1)
val_y = df_val[col]
val_x = df_val.drop(col, axis=1)
trains = lgb.Dataset(train_x, train_y)
valids = lgb.Dataset(val_x, val_y)
params = {
"objective": "regression",
"metrics": "mae"
}
model = lgb.train(params, trains, valid_sets=valids, num_boost_round=1000, early_stopping_rounds=100)簡単ですね!
ここからパラメータチューニングをおこなっていきます。
Optunaというライブラリを使ってパラメータ最適化をおこなっていきます!
Optunaはあの東大発のAIベンチャー「Preferred Networks」が開発したオープンソースソフトウェアです。
Optunaは先ほどご紹介したパラメータ最適化の手法の中でもベイズ最適化をベースに作られています。
そしてそのOptunaの拡張機能としてLightGBM用に開発されたのが、「LightGBM Tuner」!
LightGBMのハイパーパラメータチューニングには非常に便利な手法で、簡単に使えるので使い勝手バツグンです!
それでは、LightGBM Tuner使って精度を改善してみましょう!
先ほどのモデル構築の部分をまずはLightGBM Tunerでパラメータチューニングしていきます。
import optuna.integration.lightgbm as lgb_tune
df_train, df_val =train_test_split(df, test_size=0.2)
col = "取引価格(総額)_log"
train_y = df_train[col]
train_x = df_train.drop(col, axis=1)
val_y = df_val[col]
val_x = df_val.drop(col, axis=1)
trains = lgb.Dataset(train_x, train_y)
valids = lgb.Dataset(val_x, val_y)
params = {
"objective": "regression",
"metrics": "mae"
}
model_tune = lgb_tune.train(
params, trains, valid_sets=valids,
verbose_eval=100,
early_stopping_rounds=100,
)これで、LightGBMの最適なハイパーパラメータが算出されます。
パラメータに関しては以下のように記述することで確認することができます。
model_tune.paramsこのパラメータを用いてモデル構築をおこなっていきましょう!
model = lgb.train(model_tune.params, trains, valid_sets=valids, num_boost_round=1000, early_stopping_rounds=100)このデータを基にテストデータにおいてモデル構築をしてサブミットしてみましょう!
サブミットは別途ダウンロードしたtestデータを基に予測を行いファイルを作成し、 Nishikaのコンペ画面からサブミットしていきます。
df_test = pd.read_csv("test.csv", index_col=0)
df_test = data_pre(df_test)
predict = model.predict(df_test)
df_test["取引価格(総額)_log"] = predict
df_test[["取引価格(総額)_log"]].to_csv("submit_test.csv")ハイパーパラメータチューニングの注意点

最適なハイパーパラメータは、もちろんデータや特徴量によって変わってきます。
そのため、せっかくパラメータチューニングをおこなったとしてもその後にデータ量が増減したり特徴量が増えたりすると最適なハイパーパラメータは変わってきてしまうのです。
そのため、いきなりパラメータチューニングを行うのではなく、最初は特徴量エンジニアリングなどの観点で精度向上ができないか模索をしましょう。
その中でもうこれ以上精度向上の見込みがないとなった場合、最終的にモデル構築する前にハイパーパラメータのチューニングをおこなって最適化を行うのがおすすめです。
ハイパーパラメータのチューニングは非常に時間がかかりますので、何度も行うのは時間のムダです。
注意しましょう!
ハイパーパラメータチューニング まとめ
本記事では、ハイパーパラメータのチューニングについて見てきました。
ハイパーパラメータは機械学習のモデル精度を決定する非常に重要な要素であり、ハイパーパラメータをチューニングすることで精度を向上できることが分かりました。
どんなハイパーパラメータが存在するのかを知った上で、最適なパラメータチューニング方法を選んで実装してみましょう!
また冒頭にもお伝えしましたが、以下のUdemy講座でパラメータチューニングについて詳しく解説しているので、さらに深く知りたいという方はチェックしてみてください!
【初心者向け】パラメータチューニング入門!Pythonで機械学習モデルを構築しパラメータチューニングで精度向上させよう!
| 【時間】 | 4.5時間 |
|---|---|
| 【レベル】 | 初級 |
パラメータチューニングについて学びたいならこのコース!
今なら購入時に「B3PS3TPL8ZWG」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
機械学習やデータサイエンティスト・Pythonの勉強法については以下の記事でまとめていますのであわせてチェックしてみてください!



これらを包括的により深く学びたい方は、当メディアが運営している「スタアカ(スタビジアカデミー)」を是非チェックしてみてください!
格安でデータサイエンスが一通り学べます!ご受講お待ちしております!
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















