
【5分で分かる】コード付きで解説!Pythonのglobの使い方まとめ!


こんにちは!スタビジ編集部です!
この記事では、Pythonでディレクトリに格納されたファイル名を抽出するのに便利なライブラリ”glob“の使い方についてまとめていきたいと思います!

そんな時に役立つのが”glob”なんだ!
ぜひglobの基本についてしっかりおさえて扱えるようになっておきましょう!
globとは?

“glob“はPython標準のライブラリの一つでディレクトリに格納されたファイル名を抽出するのに使われます!
globモジュールにはglob()やigrob()、escape()といった関数があります!
その中で、よく使われるのがglob()なのでぜひ使い方を覚えておきましょう!
glob()はファイルの抽出条件を引数として与えることで、その条件にマッチしたファイルやフォルダの一覧をリストとして返してくれます!
ただ、この抽出条件の書き方が少し難しいので実戦で見ていきましょう!
似たような名前のファイルから一つ一つデータを取り出すときとかに便利!
globを使ってファイルを抽出してみよう!
実際にglobを使ってみましょう!
学習用のデータがある「trainフォルダ」とサンプルデータが「sample_dataフォルダ」のあるディレクトリを想定します!
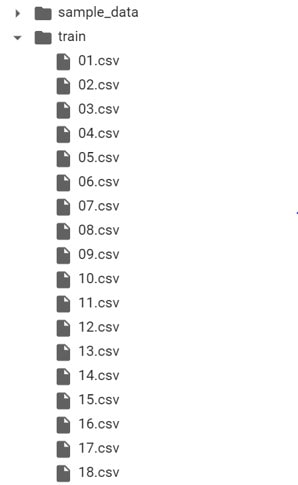
trainフォルダの中には分析の元になるデータがcsvファイルとして01~47まで格納されています!
では、globを使ってこのcsvファイルのファイル名を取得していきましょう!
file = glob.glob("train/01.csv")glob()の中に習得したいファイルの条件(pathname)を記述します!
今回はtrainフォルダの中の”01.csv”を指定しました!
“file”の中身を見てみるとでファイル名が確認できます!
print(file)
>>['train/01.csv'][‘train/01.csv’]
複数のファイルを抽出する
続いて、複数のファイルを抽出してみましょう!
方法は先ほどと同じで、glob()の中に条件を記述します!
files = glob.glob("train/*.csv")ここの「*」はワイルドカードと呼ばれるもので特殊な意味を持ち、条件の指定に役立ちます!
globでよく使われる特殊文字を見ていきましょう!
| * | 0文字以上の任意の文字列 |
|---|---|
| ? | 1文字の任意の文字 |
| [文字列] | []の中に含まれている文字の中の1文字 |
| [!文字列] | []の中に含まれない1文字 |
上の例の”train/*.csv“は「trainフォルダの中にあるcsvファイルすべてを抽出する」という意味になります!
filesの中を見てみるとデータのcsvファイルがリスト形式で格納されています!
print(files)
>>['train/43.csv', 'train/16.csv', 'train/20.csv', 'train/47.csv', 'train/31.csv', 'train/01.csv', 'train/10.csv', 'train/39.csv', 'train/09.csv', 'train/36.csv', 'train/25.csv', 'train/44.csv', 'train/11.csv', 'train/23.csv', 'train/14.csv', 'train/17.csv', 'train/04.csv', 'train/38.csv', 'train/26.csv', 'train/06.csv', 'train/21.csv', 'train/07.csv', 'train/29.csv', 'train/13.csv', 'train/27.csv', 'train/28.csv', 'train/02.csv', 'train/19.csv', 'train/22.csv', 'train/46.csv', 'train/34.csv', 'train/18.csv', 'train/35.csv', 'train/32.csv', 'train/37.csv', 'train/08.csv', 'train/24.csv', 'train/42.csv', 'train/05.csv', 'train/12.csv', 'train/30.csv', 'train/45.csv', 'train/03.csv', 'train/15.csv', 'train/40.csv', 'train/33.csv', 'train/41.csv']
次は、「01~09の数字がついたcsvファイル」だけを抽出してみましょう!
file1 = glob.glob("train/[0][1-9].csv")いろんなやり方があると思いますが、今回は[]を使って条件を指定しています!
2桁目は0で固定なので[0]、1桁目は1~9の文字のどれかなので[1-9]と指定します!
“文字-文字”を使うと文字から文字までとなります!他に[a-z]と書いてa~zまでと意味で使うことが多いです!
file1の中を見てみると意図したファイル名が格納されていますね!
print(file1)
>>['train/01.csv', 'train/09.csv', 'train/04.csv', 'train/06.csv', 'train/07.csv', 'train/02.csv', 'train/08.csv', 'train/05.csv', 'train/03.csv']
別ディレクトリのファイルも抽出する
先ほど「glob()の中に習得したいファイルの条件(pathname)を記述します」と記載しましたが、ファイルの条件は具体的にパスを指定しているため、そのディレクトリ内を対象にしています、、、
なので、このままだと別のディレクトリにあるファイルと抽出できなくなります!
例えば、「trainフォルダ」と「testフォルダ」それぞれに目当てデータのファイルがある場合を想定します!「trainフォルダ」の中には「train2フォルダ」があり、そこにもデータがあります!
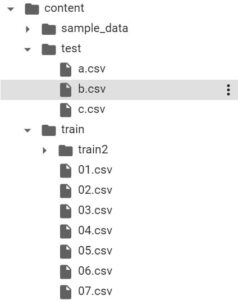

この時、「trainフォルダ」と「testフォルダ」にあるcsvファイルを抽出したい場合”再帰的な処理“を行います!
再帰的な処理とは同じ処理を繰り返すという意味です!
今回の場合、globではディレクトリの中で条件に合うファイルを抽出してリストに格納するという処理をしています!
その処理を今のディレクトリの下のディレクトリでも繰り返し実施し、最も深い階層にあるファイルやディレクトリまで検索することが再帰的処理になります!
説明だけだと難しいので、実際にやってみましょう!
まずはtrainフォルダの中にあるcsvファイルをすべて抽出します!
file_recursive = glob.glob("train/**/*.csv", recursive=True)「**」を使うことで、条件のpathを起点(今回はtrain)に下の階層まで条件のファイルがないか検索してくれます!
その時、「recursive=True」として再帰的な検索を有効にすることを忘れずに!
print(file_recursive)
>>['train/43.csv', 'train/16.csv', 'train/20.csv', 'train/47.csv', 'train/31.csv', 'train/01.csv', 'train/10.csv', 'train/39.csv', 'train/09.csv', 'train/36.csv', 'train/25.csv', 'train/44.csv', 'train/11.csv', 'train/23.csv', 'train/14.csv', 'train/17.csv', 'train/04.csv', 'train/38.csv', 'train/26.csv', 'train/06.csv', 'train/21.csv', 'train/07.csv', 'train/29.csv', 'train/13.csv', 'train/27.csv', 'train/28.csv', 'train/02.csv', 'train/19.csv', 'train/22.csv', 'train/46.csv', 'train/34.csv', 'train/18.csv', 'train/35.csv', 'train/32.csv', 'train/37.csv', 'train/08.csv', 'train/24.csv', 'train/42.csv', 'train/05.csv', 'train/12.csv', 'train/30.csv', 'train/45.csv', 'train/03.csv', 'train/15.csv', 'train/40.csv', 'train/33.csv', 'train/41.csv', 'train/train2/98.csv', 'train/train2/99.csv', 'train/train2/97.csv']file_recursiveを見てみると、すべてのファイルがリスト形式で格納されていますね!
最後に「trainフォルダ」と「testファイル」の中から「a.csvファイル」と「1の位が9のファイル」を抽出してみます!
files_ex = glob.glob("**/*[a,9].csv", recursive=True)
print(files_ex)
>>['train/39.csv', 'train/09.csv', 'train/29.csv', 'train/19.csv', 'train/train2/99.csv', 'test/a.csv']別のフォルダのデータもしっかり抽出できますね!
glob使い方まとめ
ここまでで、globとはから使い方まで解説していきました!
globを使い、ワイルドカードや再帰的な処理を利用することで複数のファイルを抽出できました!
「globの使い方はわかったけど、これをどう場面で使うの?」と思った方はぜひ以下の講座を受講してみてください!
実際のデータ分析の流れを解説していて、実戦でglobがどのように使われているのか参考になります!
また、Pythonを使ってデータ分析や機械学習を学びたい!という方には当メディアが運営するAIデータサイエンス特化スクールの「スタアカ(スタビジアカデミー)」がオススメです!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
また、Pythonで出来ることを知りたい場合は以下の記事でまとめていますので是非チェックしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















