
手書き文字のMnistデータセットをPythonで分類して使い方を理解していこう!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です。
データサイエンスの世界では最終的には実データを使っていくことになりますが、手法を簡易的に実装してみたり手法の精度を比較する上で既存のデータセットが存在します。
そんな既存のデータセットの中でもディープラーニングの画像分類精度を測る上で非常によく使われるデータセットがMnist。

データセットは色んなタイプがありますが、Mnistの扱い方を知っておくことは非常に重要です。
ということで、この記事ではMnistというデータセットについて見ていきたいと思います。
Mnistデータとは?

(イラストはイメージです)
まずは、Mnistデータとは何か見ていきましょう!
MnistはMixed National Institute of Standards and Technology databaseの略で、手書き数字画像60,000枚とテスト画像10,000枚を集めた、画像データセット。
0~9の手書き数字が教師ラベルとして各画像に与えられています。
つまりデータセットの構造は以下のようになっています。
・学習用画像データ
・学習用教師ラベルデータ
・予測用画像データ
・予測用教師ラベルデータ
1つ1つの画像は、文字画像をタテヨコ28×28のピクセルに分け、1つのピクセルあたり0~255の数値で白黒のスケールを表します。
非常に扱いやすくて、データセットとしての完成度が高いので多くの論文やカリキュラムで取り上げられるデータセットです。
画像分類問題に取り組むのであればまずはMnistを使ってディープラーニングを実装してみるのが良いと思います。
画像認識に関しては以下の記事で詳しく取り上げているのであわせてチェックしてみてください。

PythonでMnistデータを使って分類精度を比較
そんなMnistデータを使ってPythonで分類を行っていきましょう!
比較する手法は以下の4つ!
・CNN(畳み込みニューラルネットワーク)
・Xgboost
・LightGBM
・Catboost
CNN(畳み込みニューラルネットワーク)
ディープラーニングに畳み込み層を組みあわせた画像分類には定番の手法です。
まずは、必要なライブラリをインストールしていきます!
import numpy as np
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow import keras
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categoricaltensorflowなどのライブラリはあらかじめpip installしておいてくださいね!
続いてMnistのデータを学習データとテストデータに分けます。そしてさらに学習データからパラメータチューニングのための検証データを取り出します。
# Kerasに付属の手書き数字画像データをダウンロード
np.random.seed(0)
(X_train_base, labels_train_base), (X_test, labels_test) = mnist.load_data()
# Training set を学習データ(X_train, labels_train)と検証データ(X_validation, labels_validation)に8:2で分割する
X_train,X_validation,labels_train,labels_validation = train_test_split(X_train_base,labels_train_base,test_size = 0.2)この時画像データは、描画がしやすいように28×28の行列になっているのですが、学習するために1×784に直しましょう!さらに0~255のスケールを正規化しましょう!
# 各画像は行列なので1次元に変換→X_train,X_validation,X_testを上書き
X_train = X_train.reshape(-1,784)
X_validation = X_validation.reshape(-1,784)
X_test = X_test.reshape(-1,784)
#正規化
X_train = X_train.astype('float32')
X_validation = X_validation.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_validation /= 255
X_test /= 255続いてラベルをダミー変数化します。
# labels_train, labels_validation, labels_test をダミー変数化して y_train, y_validation, y_test に格納する
y_train = to_categorical(labels_train)
y_validation = to_categorical(labels_validation)
y_test = to_categorical(labels_test)ここでデータの成型が終了したので、ディープラーニングのネットワーク構築に入ります。
隠れ層では、RELU(ランプ)関数を用いて出力層ではソフトマックス関数を用いています。
Model.addを使うことで隠れ層をいくつも積み重ねることが可能です。
# パラメータの設定
n_features = 784
n_hidden = 100
bias_init = 0.1
# 学習率
rate = 0.01
# Sequentialクラスを使ってモデルを準備する
model = Sequential()
# 隠れ層を追加
model.add(Dense(n_hidden,activation='relu',input_shape=(n_features,)))
model.add(Dense(n_hidden,activation='relu'))
model.add(Dense(n_hidden,activation='relu'))
# 出力層を追加
model.add(Dense(10,activation='softmax'))
ネットワークの構築が終了した後は、最適な重みを見つけていきます。AdamOptimizerは最近よく使われている最適化手法です。
Early stoppingとはもう精度が改善しないようなら学習を止めてしまう条件です。これによってムダな学習を省くことが可能です。最後のvalidation_dataで過学習が起こらないように検証を行っています。
# TensorFlowのモデルを構築
model.compile(optimizer=tf.train.AdamOptimizer(rate),
loss='categorical_crossentropy', metrics=['mae', 'accuracy'])
# Early stoppingを適用してフィッティング
log = model.fit(X_train, y_train, epochs=3000, batch_size=100, verbose=True,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0, patience=10,
verbose=1)],
validation_data=(X_validation, y_validation))最後にテストデータで予測を実行して実測値と予測値の正解率を求めます!
# Test dataで予測を実行。
pred_test = model.predict_classes(X_test)
validation = (pred_test == labels_test)
size = validation.size
size
correct = np.count_nonzero(validation)
print(f"{correct}/{size} correct ({correct*100/size:.3f}%)")最終的な結果は・・・・96.96%!!
そこそこな精度をたたき出すことができました。パラメータをいじることで精度を99%まで伸ばしてみてください!
最後にまとめてコードを載せておきます。
CNNに関しては以下の記事で詳しくまとめていますのでチェックしてみてください!

Xgboost
アンサンブル学習と決定木を組み合わせた手法で非常に高い汎化能力を誇ります。
Xgboostでは、アンサンブル学習の中でもブースティングを用いています。
バギングは並列学習なのですが、ブースティングは直列で学習していくイメージです。
前期に上手く学習できなかったら誤差を目的変数にして次の学習を行います。
コードをみていきましょう!
精度・・0.976!!非常に高い!
以下の記事で詳しくまとめています!

LightGBM
続いてXgboostを改良した手法として発表されたLightGBM。
データコンペでもよく使われる手法です。
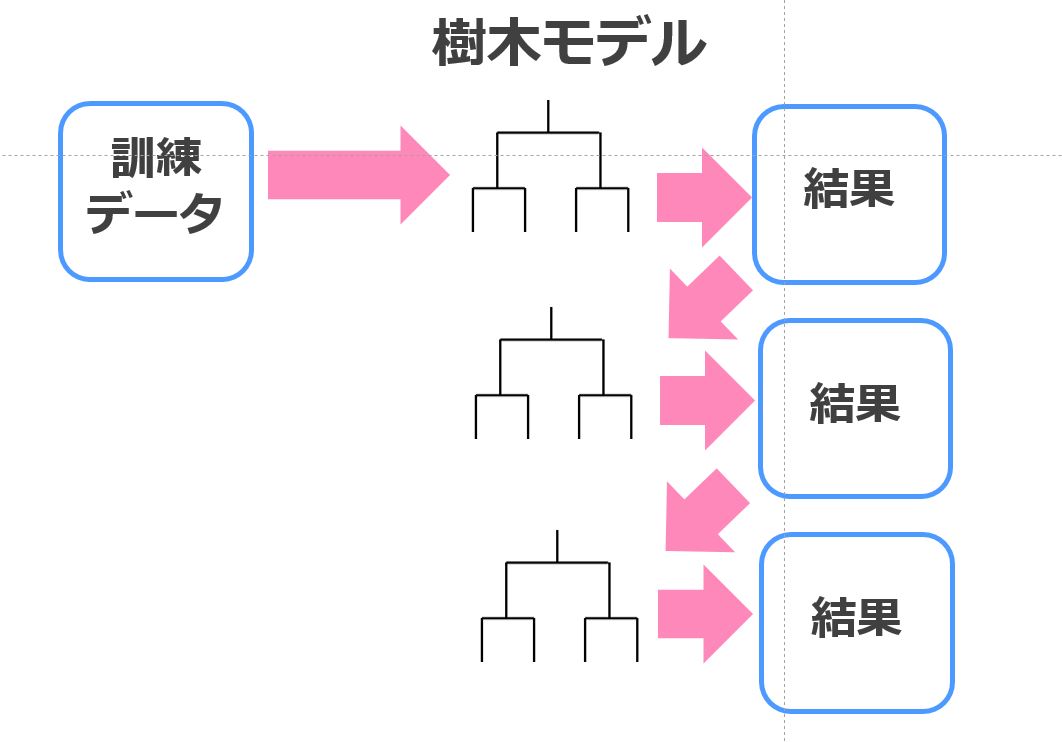
Xgboostを含む通常の決定木モデルは以下のように階層をあわせて学習していきます。
それをLevel-wiseと呼びます。
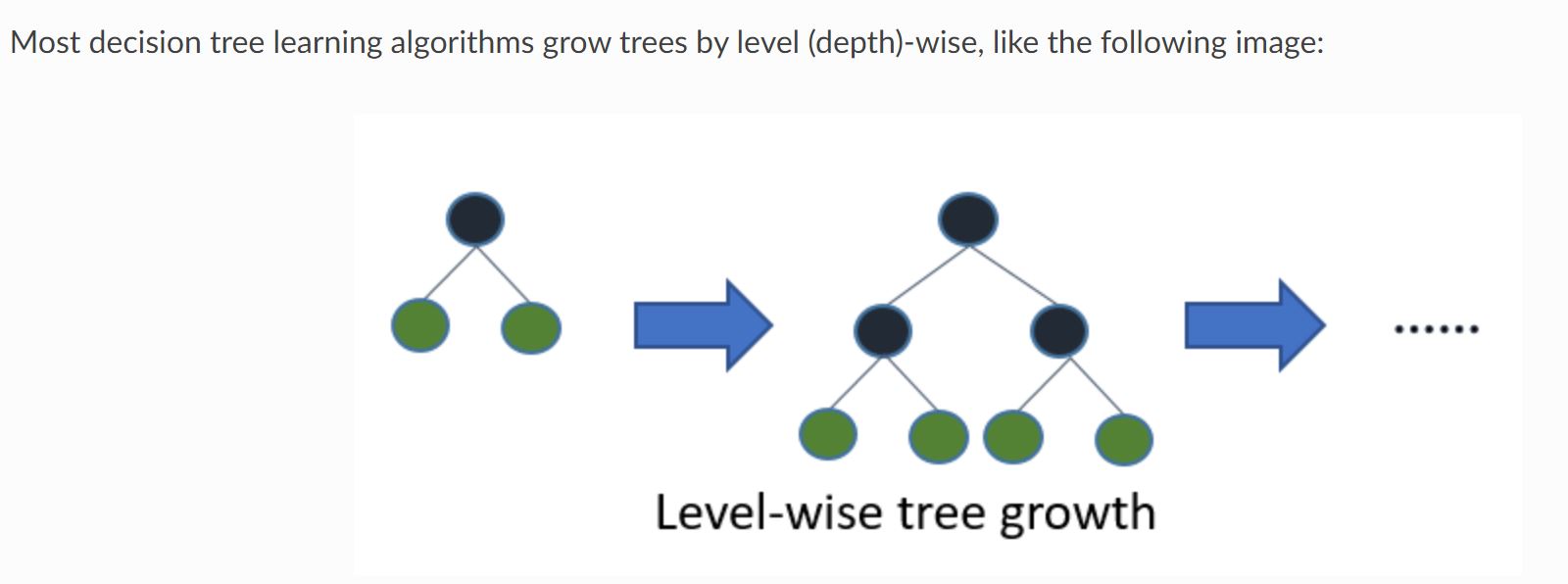
(引用元:Light GBM公式リファレンス)
一方Light GBMは以下のように葉ごとの学習を行います。これをleaf-wise法と呼びます。
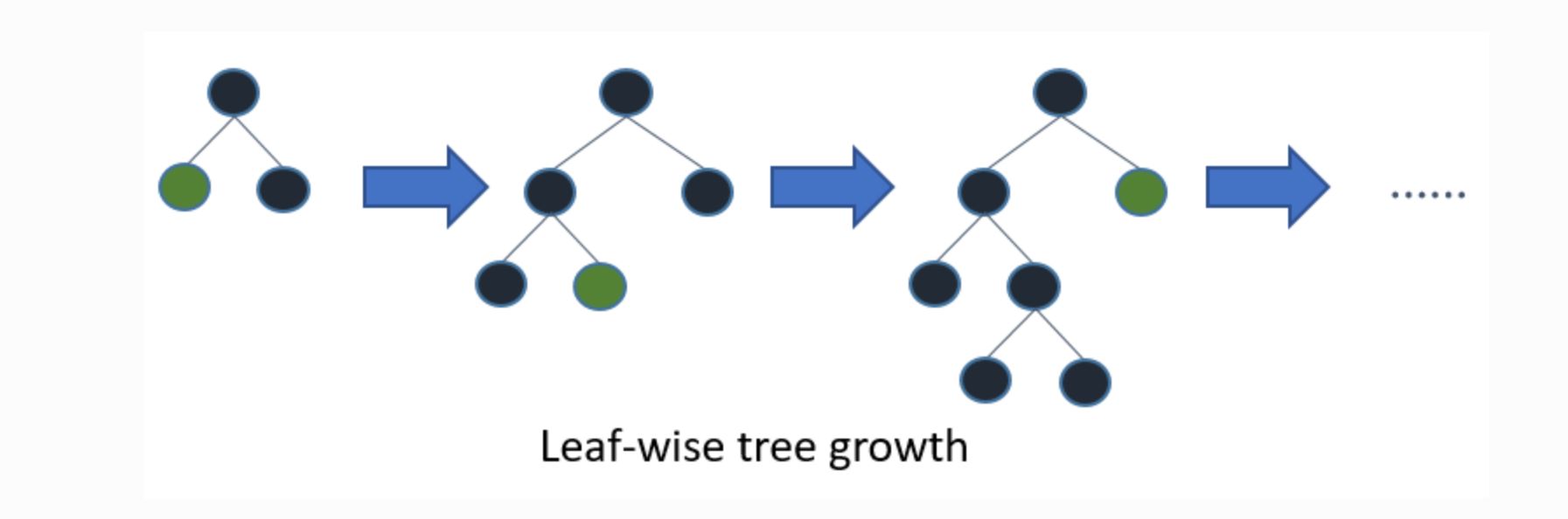
(引用元:Light GBM公式リファレンス)
これにより、ムダな学習をしなくても済むためより効率的に学習を進めることができます。
Light GBMの解到達スピードが速いゆえんはここにあるのです。
では実装していきましょう!
結果的に0.972という推定精度が得られました!
結果はXgboostに負けていますが、処理時間ではXgboostの8分の1ほどで終了しています。
LightGBMに関しては以下の記事で詳しくまとめています!
Catboost
Catboostは、「Category Boosting」の略であり2017年にYandex社から発表された機械学習ライブラリ。
発表時期としてはLightGBMよりも若干後になっています。
ポイントは2つ。
・カテゴリカル変数(質的変数)の扱い方が上手いよ
・決定木のツリー構造を最適にして過学習を防ぐよ
まあ、要はデータセットによるけどXgboostやLightGBMよりも精度が高くなる可能性があるよってことですね。
では、実装していきましょう!
推定精度は0.9565!
Catboostについては以下の記事でまとめています!

結果は・・・以下のようになりました!
| CNN | Xgboost | LightGBM | Catboost |
| 96.96% | 97.60% | 97.20% | 95.65% |
絶妙な差ですが、Xgboostが最も高くCatboostが最も低いという結果に!
ぜひ色んな手法でMnistを分類して精度比較してみてください!
Mnistデータまとめ
ここまでご覧いただきありがとうございました!
本記事では、Mnistデータの特徴とPythonでの分類実装を見てきました。
Mnistの特徴をもう一度まとめておきましょう!
・0~9の手書き数字がまとめられたデータセット
・6万枚の訓練データ用(画像とラベル)
・1万枚のテストデータ用(画像とラベル)
・白「0」~黒「255」の256段階
・幅28×高さ28フィールド
Mnist以外のデータも分析してみたい!という方はデータ分析コンペティションに挑戦してみることをオススメします!
データ分析コンペを開催するサービスといえばKaggleが有名ですが、それ以外にもデータ分析コンペはNishikaやSignateなどたくさんあります。
今回精度比較に用いたディープラーニングをはじめとする機械学習手法やPythonやデータサイエンス全般についての勉強は以下の記事でまとめています。




 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















