
【わかりやすく解説】XGboostとは?理論とPythonとRでの実践方法!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
Kaggleや![]() Nishikaなどのデータ分析コンペでも頻繁に用いられているXGboost。
Nishikaなどのデータ分析コンペでも頻繁に用いられているXGboost。
最近では、LightGBMに王座の場を奪われつつありますが、まだまだ現役で使われている名実ともに最強の教師あり学習手法です。
この記事では、そんなXGboostに関して解説していきたいと思います!
目次
XGboostとは

XGBoostについて簡単に見ていきましょう!動画でも解説していますよー!
XGboostは「eXtreme Gradient Boosting」の略で2014年に発表された手法です。
勾配ブースティングと呼ばれるアンサンブル学習と決定木を組み合わせた手法で非常に高い汎化能力を誇ります。
アンサンブル学習とは、弱学習器(それほど性能の高くない手法)を複数用いて総合的に結果を出力する方法で、バギングとブースティングというタイプがあります。
バギングは弱学習器を並列に使うイメージ。決定木とバギングを組み合わせたのがランダムフォレストです。
ランダムフォレストの簡単なイメージが以下!
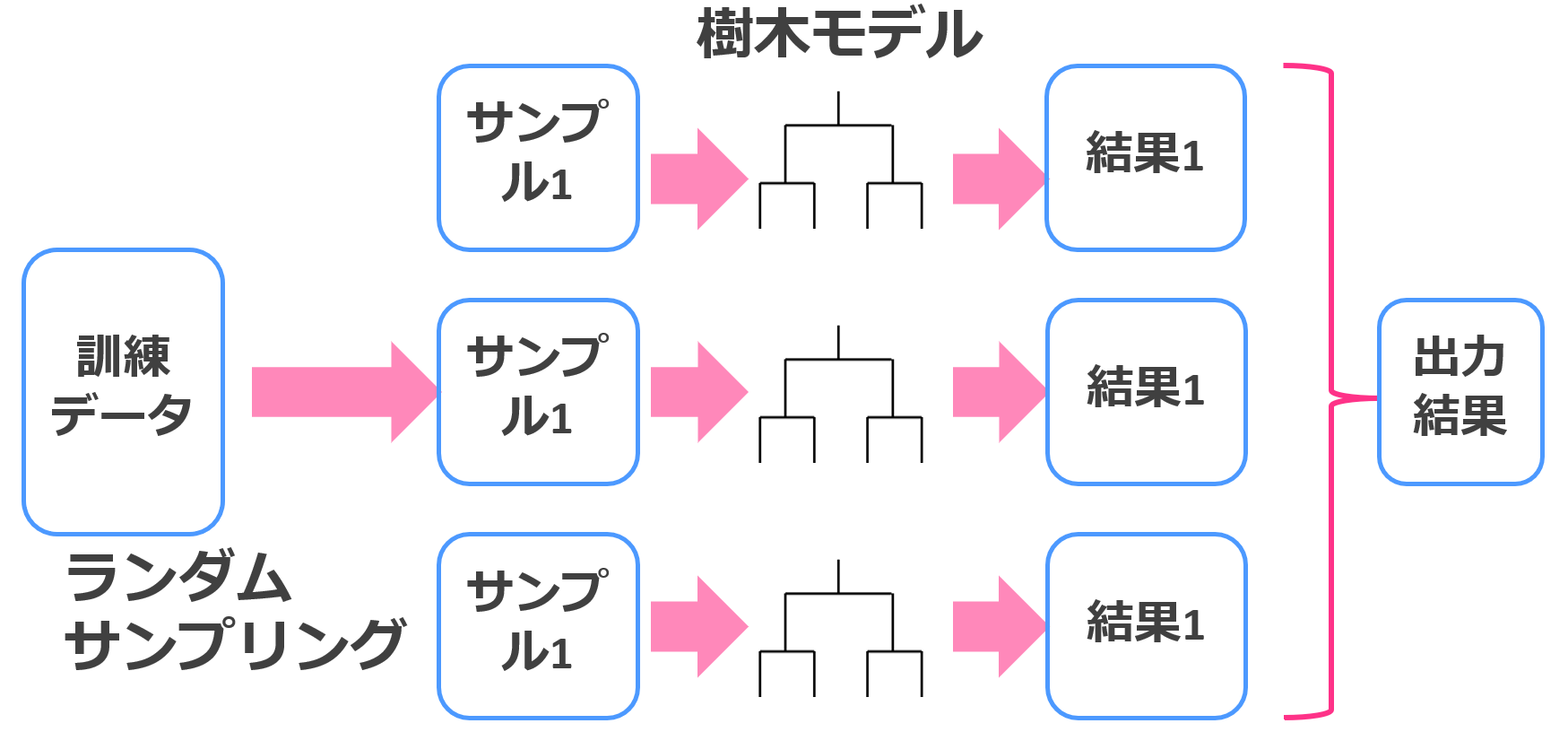
並列に決定木モデルを扱ってそれぞれのモデルの結果を総合的に判断します。
一方でブースティングは弱学習器を直列に使います。
ブースティングと決定木を組み合わせたのがXGboostなのです。
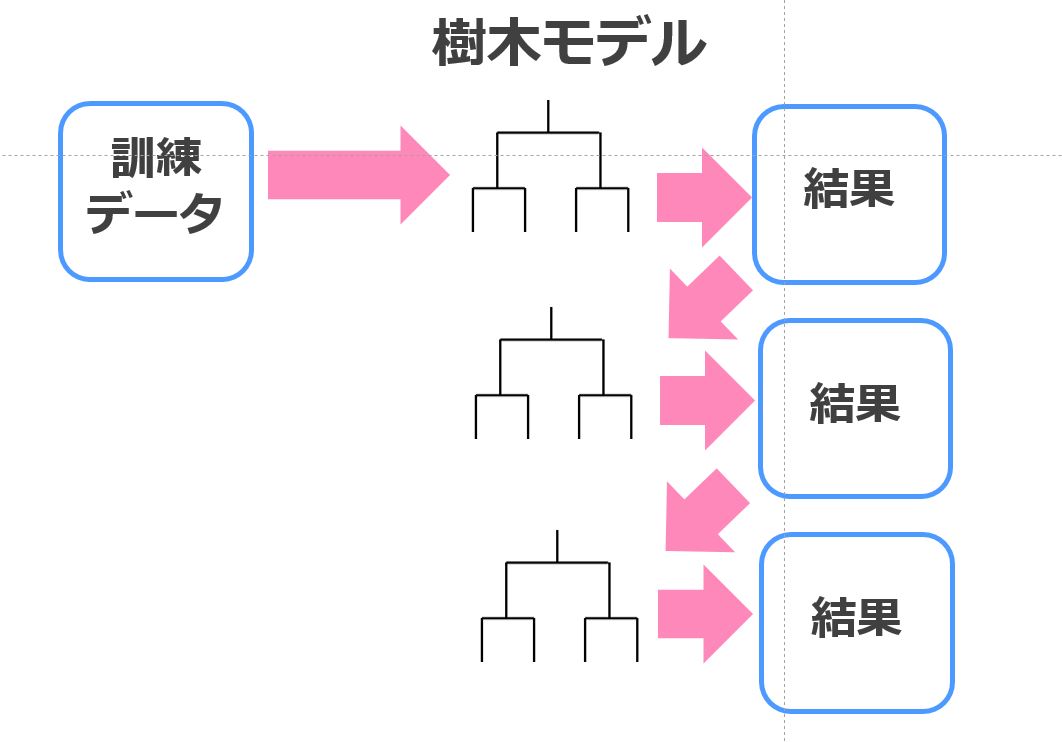
最初の学習器で上手く分類・推定できなかった部分に対して重みを付けて次の弱学習器で学習を行います。
そうすることで、上手く推定できない部分もできるようになってきます。
最終的には、それぞれのモデルに対して精度の高さを基に重みを付けて集約し、モデルを作成します。
3人寄れば文殊の知恵的な感じですね!
XGBoostの論文はこちら!この後述べる特徴なども詳しく書かれています!
In this paper, we described a scalable end-to-end tree boosting system called XGBoost, which is used widely by data scientists to acheve state-of-the-art results on many machine learning challenges.
XGboostの特徴
XGboostの特徴を見ていきましょう!
精度が比較的高い
冒頭でも書きましたが、Kaggleでもまだまだ用いられている精度の高い手法です。
一般的にバギングを用いたランダムフォレストよりも精度は高くなります。

学習に時間がかかる
ブースティングは直列に学習を行うため、バギングよりも学習に時間がかかります。
大規模データを解析するとなると、それなりの学習時間がかかるので注意が必要です。
実は、そんなXGboostの弱点を克服するためにリリースされたのがLightGBM(軽いXGboost的なイメージ)なのです。
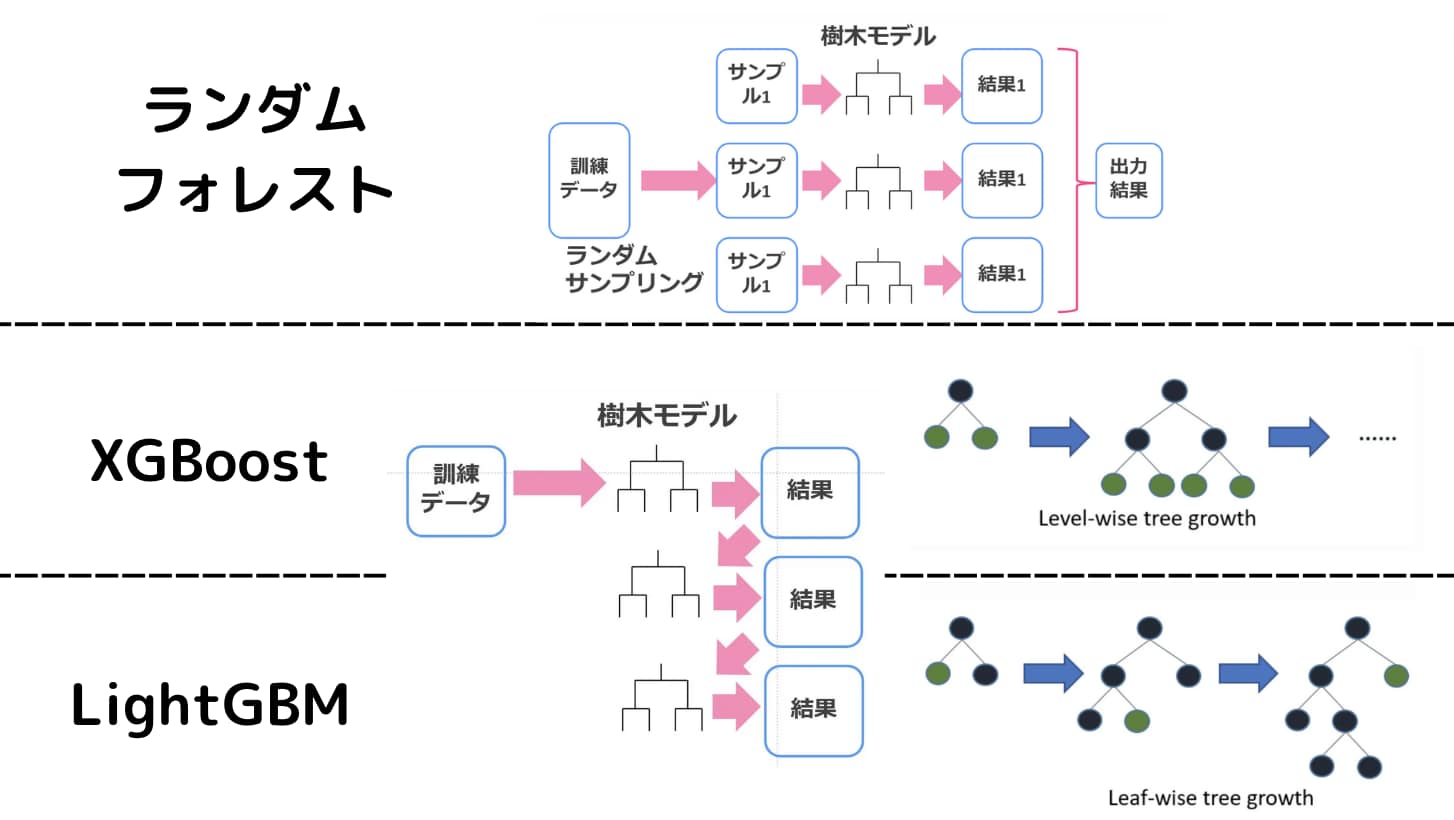
XGboostでは決定木の階層が同時に深くなっていきますが、LightGBMでは階層は一定ではありません。片方のノードだけ深くなることもあります。
これをLeaf-wiseと呼びます。
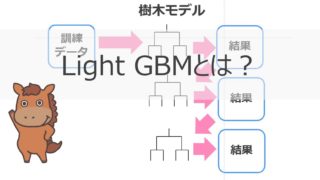
パラメータの数が多くチューニングが必要
XGboostには数々のパラメータが存在します。
精度を上げるためにはパラメータのチューニングが必要になってきます。
パラメータのチューニングの方法にはグリッドサーチやベイズ最適化などがあります。

決定木と比較すると解釈容易性が低い
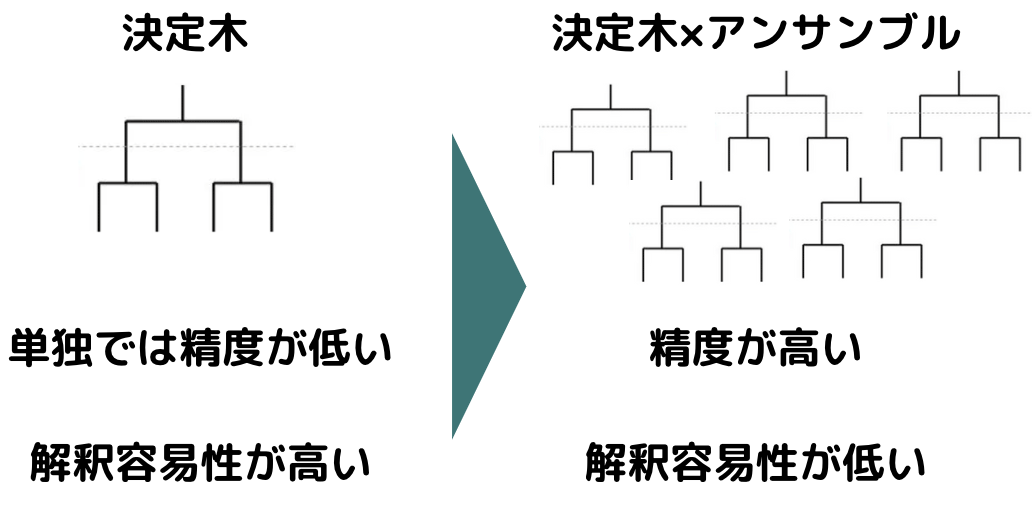
決定木は結果がツリー構造で可視化されるので解釈容易性が高く、他人に説明する際や現状を紐解く際には便利です。
一方でXGboostは、複数の決定木をアンサンブルしてしまうので解釈容易性が低くなってしまいます。
ただ、どの特徴量が効いているかなどの特徴量重要度は算出することが可能です。
回帰タスクに対してXGboostをPythonで実装してみよう!

XGboostはRやPythonで簡単に実装することができます。
まずは、実際にPythonを用いてXGboostを実装してみましょう!
最初に回帰タスクに対してXGBoostを実装してみます。
国産データコンペ Nishikaの「中古マンション価格予測」というトレーニングコンペのデータを題材にしていきます。
まず![]() Nishikaに会員登録をして中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
Nishikaに会員登録をして中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
globは、ディレクトリに格納されたファイル名を抽出するのに便利なライブラリです。

import glob
import pandas as pd
import numpy as np
import xgboost as xgb
import category_encoders as ce
from sklearn.model_selection import train_test_split
files = glob.glob("train/*.csv")
data_list = []
for file in files:
data_list.append(pd.read_csv(file, index_col=0))
df = pd.concat(data_list)category_encodersは変数をカテゴリ変数化するためのライブラリです。
学習データには複数CSVが入っているので、それらをglobで結合させてデータフレーム化していきます。
続いてデータが少し汚いのでカラムを削除したり型の変換などをおこなっていきます。
def data_pre(df):
nonnull_list = []
for col in df.columns:
nonnull = df[col].count()
if nonnull == 0:
nonnull_list.append(col)
df = df.drop(nonnull_list, axis=1)
df = df.drop("市区町村名", axis=1)
df = df.drop("種類", axis=1)
dis = {
"30分?60分":45,
"1H?1H30":75,
"2H?":120,
"1H30?2H":105
}
df["最寄駅:距離(分)"] = df["最寄駅:距離(分)"].replace(dis).astype(float)
df["面積(㎡)"] = df["面積(㎡)"].replace("2000㎡以上", 2000).astype(float)
y_list = {}
for i in df["建築年"].value_counts().keys():
if "平成" in i:
num = float(i.split("平成")[1].split("年")[0])
year = 33 - num
if "令和" in i:
num = float(i.split("令和")[1].split("年")[0])
year = 3 - num
if "昭和" in i:
num = float(i.split("昭和")[1].split("年")[0])
year = 96 - num
y_list[i] = year
y_list["戦前"] = 76
df["建築年"] = df["建築年"].replace(y_list)
year = {
"年第1四半期": ".25",
"年第2四半期": ".50",
"年第3四半期": ".75",
"年第4四半期": ".99"
}
year_list = {}
for i in df["取引時点"].value_counts().keys():
for k, j in year.items():
if k in i:
year_rep = i.replace(k, j)
year_list[i] = year_rep
df["取引時点"] = df["取引時点"].replace(year_list).astype(float)
cols = ["都道府県名", "地区名", "最寄駅:名称", "間取り", "建物の構造", "用途", "今後の利用目的", "都市計画", "改装", "取引の事情等"]
ce_df = ce.OrdinalEncoder(cols=cols, handle_unknown='impute')
df = ce_df.fit_transform(df)
return df
df = data_pre(df)
以下の箇所では質的変数に関してカテゴリーエンコーディングをおこなっていきます。
cols = ["都道府県名", "地区名", "最寄駅:名称", "間取り", "建物の構造", "用途", "今後の利用目的", "都市計画", "改装", "取引の事情等"]
ce_df = ce.OrdinalEncoder(cols=cols, handle_unknown='impute')
df = ce_df.fit_transform(df)そして最終的にXGBoostを実装していきます。
df_train, df_val =train_test_split(df, test_size=0.2)
col = "取引価格(総額)_log"
train_y = df_train[col]
train_x = df_train.drop(col, axis=1)
val_y = df_val[col]
val_x = df_val.drop(col, axis=1)
train_data = xgb.DMatrix(train_x, label=train_y)
eval_data = xgb.DMatrix(val_x, label=val_y)
xgb_params = {
"objective": "reg:squarederror",
'eval_metric': "mae"
}
evals = [(train_data, 'train'), (eval_data, 'eval')]
gbm = xgb.train(
xgb_params,
train_data,
num_boost_round=100,
early_stopping_rounds=10,
evals=evals,
)学習用のデータと検証用のデータに分けています。
学習をする際は、xgb.DMatrixというXGBoost用のデータ型に変換するのが特徴です。
その後はパラメータをかんたんにセットしモデル構築をおこなっていきます。
今回eval_metricをMAE(平均絶対誤差)に設定しているので、MAEで算出されます。
[99] train-mae:0.08941 eval-mae:0.09110
パラメータチューニングをしたり特徴量エンジニアリングをすることで精度は上がります。
以下に全コードを載せておきます。
分類タスクに対してXGboostをPythonで実装してみよう!

先ほどは![]() Nishikaというデータコンペの中古マンション価格データを題材に回帰タスクに対してXGBoostを実装しました。
Nishikaというデータコンペの中古マンション価格データを題材に回帰タスクに対してXGBoostを実装しました。
続いてはMnistという文字の識別分類データを題材に分類タスクに対してXGBoostを実装していきます。
また、今回は他の手法と精度比較をおこなっていきます。
その手法とは、Xgboostと同じ勾配ブースティング手法であるLight gbmとCatboostの2つです!
XGBoostよりも後に開発された2つの強力な手法と精度を比較してみましょう!
今回扱うMnistデータセットの特徴は以下です。
・0~9の手書き数字がまとめられたデータセット
・6万枚の訓練データ用(画像とラベル)
・1万枚のテストデータ用(画像とラベル)
・白「0」~黒「255」の256段階
・幅28×高さ28フィールド
それでは、コードをみていきましょう!
まずは、Mnistのデータをインポートして分類するために加工していきます!
続いて、Xgboost用のデータ構造に変換します。
最後にパラメータをセットしてXgboostで学習を行っていきます!
結果は・・・
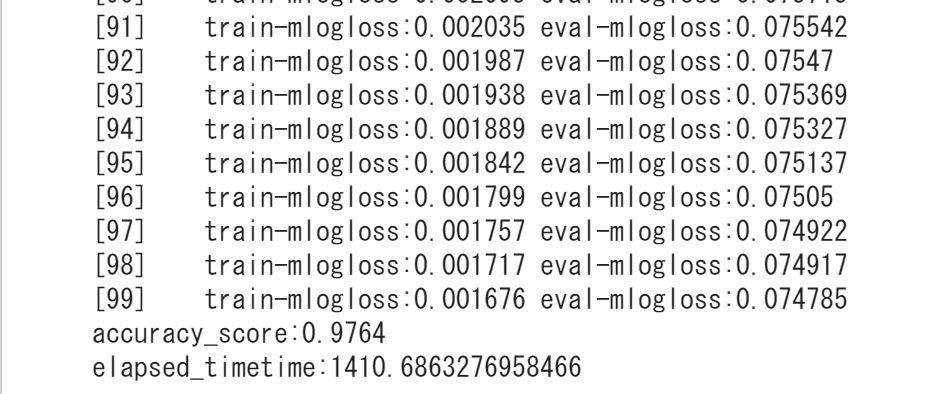
精度・・0.976!!非常に高い!
実はLight gbmやCatboostよりも高くなっています。
Light gbmは0.972、Catboostは0.9567!
ただ処理時間が他の手法よりも圧倒的に遅いんです。
以下の記事で比較しているので詳しくはチェックしてみてください!

XGboostをRで実装してみよう!

Pythonでの実装を見てきましたが、続いてはRを用いて実装していきます。
今回は、Kaggleの公式サイトで提供されているTitanicのデータを使います。
データのクレンジングを行い、欠損値は削除、不要と考えられる項目は削除します。
生死(Survive)を目的変数としそれ以外を説明変数とします。
サンプル数714のうちランダムに400個のデータを取り出し学習データとし、残りの314を予測データとします。
学習データで予測モデルを作り、予測データにあてはめ真値と予測値の判別率を精度として比較します。
シミュレーション回数は10回とし、上記の手順を10回繰り返し、結果を平均したものを最終アウトプットとします。シミュレーション回数をもっと増やせば精度の信頼性は上がります。
先程は、Light gbmとCatboostの2つと比較しましたが、RではXGboostをランダムフォレスト、サポートベクターマシン、ナイーブベイズ、ニューラルネットワーク、k近傍法の5手法と比較します!
基本的に引数は全部デフォルトで!果たして結果はどうなるでしょうか!
xgboostというパッケージに入っている関数を用いて解析を行っていきます。
XGboost以外は基本的にパッケージを読み込み関数を記述すれば問題ないのですが、XGboostだけ特別な型にするためにデータ加工をしています。
xgb.data<-xgb.DMatrix(data.matrix(train.data.xg),label=label.data.train)
他の機械学習手法は普通のデータフレーム型で扱えるんですが、XGboostは特殊な型にしなくてはいけないのが少し面倒なんですよねー!
結果は以下のようになりました!
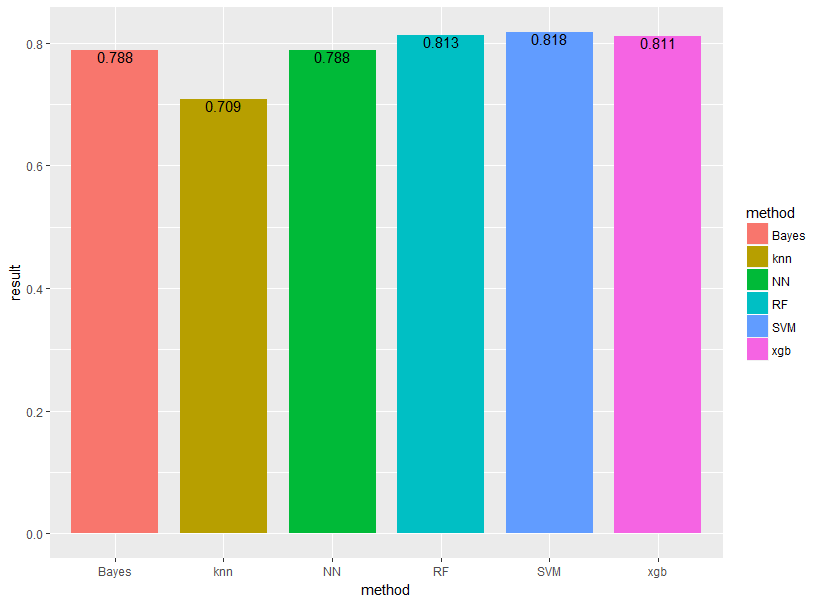
それぞれBayes(ナイーブベイズ)、knn(k近傍法)、NN(ニューラルネットワーク)、RF(ランダムフォレスト)、SVM(サポートベクターマシン)、xgb(XGboost)と表示しています。
k近傍法(黄色)が一番パフォーマンスが悪く、SVM(青色)が最もパフォーマンスが良いという結果になりました!
XGboostにはパラメータが非常にたくさんあるので注意が必要です。
今回は、二値の質的変数が目的変数なので
“objective“ = “binary:logistic“
を使用しています。
分類なのか回帰なのか、マルチクラスなのかによってobjectiveを変えるようにしましょう!
他にもたくさんのパラメータがあります。
パラメータをチューニングすることで精度がだいぶ変わるので、是非試してみてください!
XGboost まとめ
本記事では、XGboostについて様々な観点から見てきました。
XGboostは非常に精度の高い手法であり簡易的に実装してみてもその効果を確かめることができました。
最後にXGboostについてまとめておきましょう!
・精度が非常に高い
・学習に時間がかかる
・パラメータの数が多くチューニングが大変
是非XGboostを試してみてください!
以下の記事で他の機械学習手法やデータサイエンス全般については以下でまとめていますので興味があればご覧ください!


機械学習手法の実装にはPythonが最適です。
Pythonの習得方法に関しては以下の記事でまとめています!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















