Catboostとは?XgboostやLightGBMとの違いとPythonでの使い方を見ていこうー!!


こんにちは!
消費財メーカーでデジタルマーケター・データサイエンティストをやっているウマたん(@statistics1012)です!
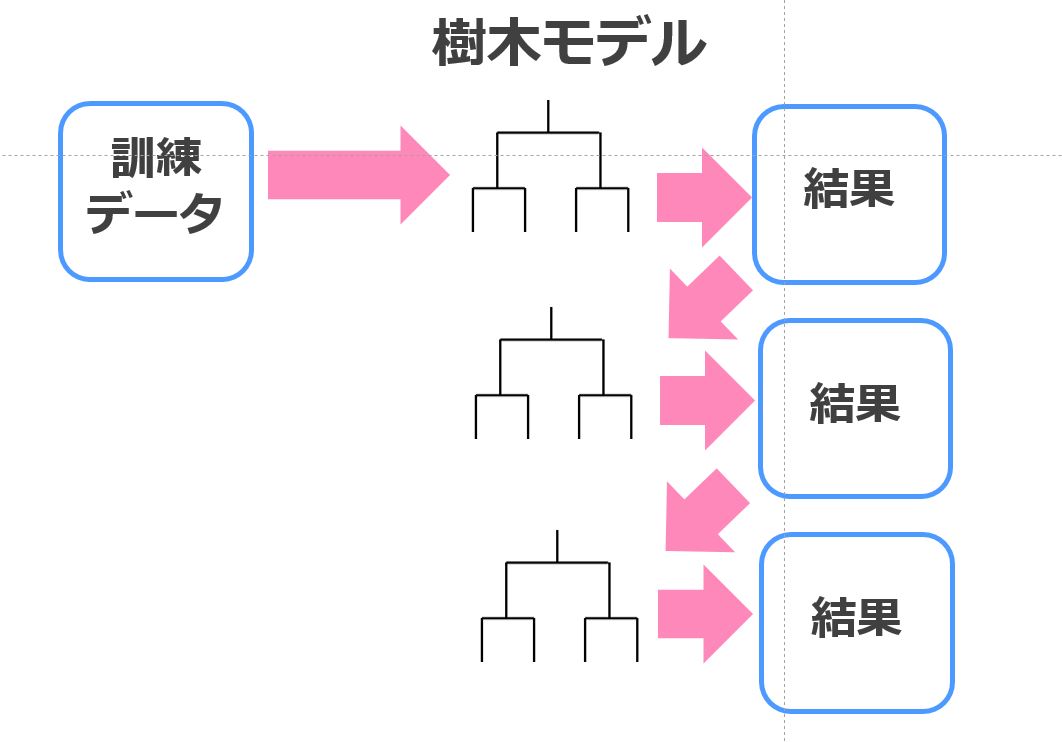
Xgboostに代わる手法としてLightGBMが登場し、さらにCatboostという手法が2017年に登場いたしました。
これらは弱学習器である決定木を勾配ブースティングによりアンサンブル学習した非常に強力な機械学習手法群。
計算負荷もそれほど重くなく非常に高い精度が期待できるため、Kaggleなどのデータ分析コンペや実務シーンなど様々な場面で頻繁に使用されているのです。

この記事では、そんなCatboostの概要について見ていき、PythonでMnistの画像データを分類するモデルを作っていきます。
LightGBMとディープラーニングとの精度比較も行いますよー!
機械学習・ディープラーニングをまず勉強したい方は当メディアが運営する「スタアカ(スタビジアカデミー)」の以下のコースをチェックしてみて下さい!

目次
Catboostとは?XgboostやLightGBMとの違い
Catboostは、「Category Boosting」の略であり2017年にYandex社から発表された機械学習ライブラリ。
発表時期としてはLightGBMよりも若干後になっています。
Yandex社はロシアのGoogle。
ロシアの検索エンジン市場の過半数を占有しており、自動車産業にも事業展開している大手IT企業なんです。
さて、そんなYandex社が発表した「Category Boosting」ですが他の勾配ブースティング手法と比較してどのような特徴があるのでしょうか?
「Category Boosting」を発表した論文を見てみると以下のように書いてあります。
In this paper we present a new gradient boosting algorithm that successfully handles categorical features and takes advantage of dealing with them during training as opposed to preprocessing time.
Another advantage of the algorithm is that it uses a new schema for calculating leaf values when selecting the tree structure, which helps to reduce overfitting.
(引用元:”CatBoost: gradient boosting with categorical features
support”)
ここで言っているのは2つ。
・カテゴリカル変数(質的変数)の扱い方が上手いよ
・決定木のツリー構造を最適にして過学習を防ぐよ
まあ、要はデータセットによるけどXgboostやLightGBMよりも精度が高くなる可能性があるよってことですね。
実際に論文の中でもいくつかのデータセットに各手法を適用させてLogloss値で比較をしています。
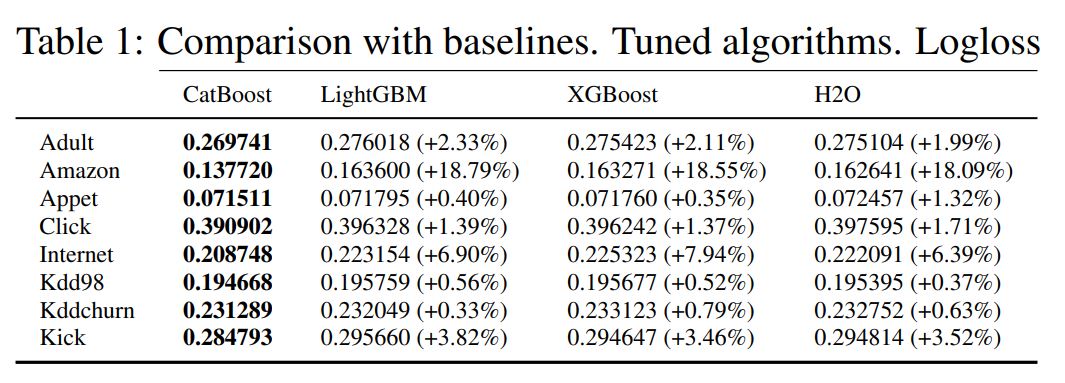
(引用元:”CatBoost: gradient boosting with categorical features support”)
実際にCatboostが最も良い精度をたたき出しているのが分かると思います。
ちなみにCatboostの公式HPに色々とまとめてありますが、大規模データセットのモデル構築も予測も比較的早い速度で出来るよ、とも書いてあります。
CatboostをPythonで実装してみよう!
実際にそんなCatboostをPythonで実装していきましょう!
今回は、Mnistというよく画像認識に使われるデータセットを用いていきます。
このデータセットには0~9の文字が様々なカタチで書かれたサンプルが入っています。
LightGBMとディープラーニング(CNN)と比較していきますよー!
ちなみに機械学習モデルを個人で構築するならGoogle colaboratoryがオススメです!
永久無料でGPUが使えるので!
CatboostについてもGoogle colaboratoryを使ってモデル構築していきます!
CatboostでMnistを分類
Catboostは、その名の通りcatboostという名前のライブラリから使用することが可能なんです。
前準備として必要なライブラリを読み込んでいきましょう!
import pandas as pd
import numpy as np
from tensorflow.keras.datasets import mnist
from sklearn.model_selection import train_test_split続いて、今回分類を行うMnistデータを加工。
# Kerasに付属の手書き数字画像データをダウンロード
np.random.seed(0)
(X_train_base, labels_train_base), (X_test, labels_test) = mnist.load_data()
# Training set を学習データ(X_train, labels_train)と検証データ(X_validation, labels_validation)に8:2で分割する
X_train,X_validation,labels_train,labels_validation = train_test_split(X_train_base,labels_train_base,test_size = 0.2)
# 各画像は行列なので1次元に変換→X_train,X_validation,X_testを上書き
X_train = X_train.reshape(-1,784)
X_validation = X_validation.reshape(-1,784)
X_test = X_test.reshape(-1,784)
#正規化
X_train = X_train.astype('float32')
X_validation = X_validation.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_validation /= 255
X_test /= 255Catboostにインプットするためのデータを用意します。
# 訓練・テストデータの設定
from catboost import Pool
train_pool = Pool(X_train, labels_train)
validate_pool = Pool(X_validation, labels_validation)パラメータを設定して・・
#経過時間計測
import time
start = time.time()
from catboost import CatBoostClassifier
params = {
'early_stopping_rounds' : 10,
'iterations' : 100,
'custom_loss' :['Accuracy'],
'random_seed' :42
}モデル構築と予測を行っていきます。
この時処理速度も同時に測っていきます。
# パラメータを指定した場合は、以下のようにインスタンスに適用させる
model = CatBoostClassifier(**params)
cab = model.fit(train_pool, eval_set=validate_pool)
preds = cab.predict(X_test)
from sklearn.metrics import accuracy_score
print('accuracy_score:{}'.format(accuracy_score(labels_test, preds)))
#経過時間
print('elapsed_timetime:{}'.format(time.time()-start))推定精度は・・・
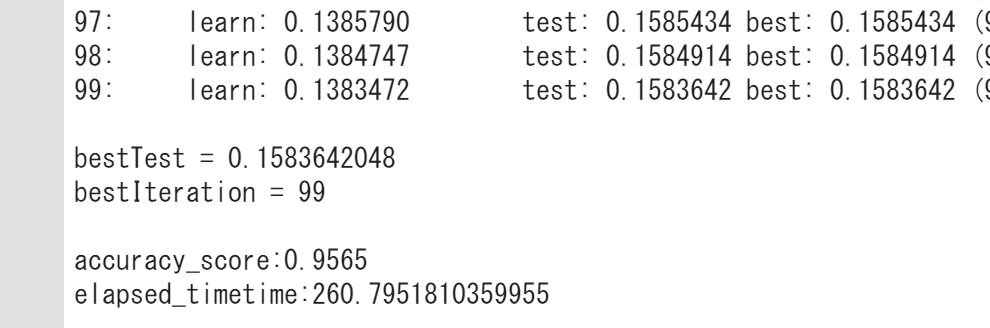
推定精度は0.9565!
非常に高い精度を得ることができました。
最新の勾配ブースティング手法「Catboost」がこんなにもカンタンに実装できちゃうんです!
全コードをまとめておきましょう!
LightGBMとディープラーニング(CNN)でMnistを分類
同様にLightGBMを使用してMnistを分類した結果は・・・0.972!
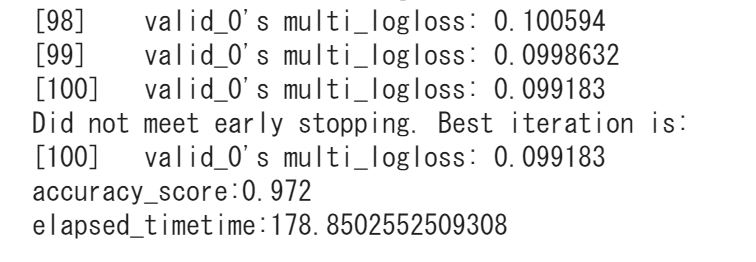
結果はLight gbmに軍配があがりました。
処理速度もCatboostが負けている・・・
やはりLight gbmつよし!ですねー
LightGBMの全コードは以下です。
詳しくは以下の記事でまとめています!
ちなみにディープラーニング(CNN)で回した時の推定精度は、0.9696!
以下がディープラーニングのコードになります。
詳しくは以下の記事でまとめています!

もう少し真面目にパラメータチューニングを行えば順序が逆転することは多いにあります。
ぜひ色々と試してみてください!
Catboost まとめ

ここまでご覧いただきありがとうございました!
本記事ではCatboostについて見てきましたー!
最後にカンタンにCatboostの特徴をまとめておきましょう!
・カテゴリカル変数(質的変数)の扱い方が上手いよ
・決定木のツリー構造を最適にして過学習を防ぐよ
・計算負荷が低いよ
Pythonで容易に実装できるので、ぜひ使ってみてください。
XgboostやLightGBMより高い精度を得られるかもしれませんよー!
ちなみにPythonの学習方法については以下の記事でまとめていますのでよければチェックしてみてください!
よりさらに深く統計学や機械学習を学びたい人のために勉強法を以下にまとめていますのでぜひチェックしてみてください!


また、当メディアではデータサイエンティストになるための分野を体系的に学ぶスクール「スタアカ(スタビジアカデミー)」を運営しておりますので、データサイエンス全般に興味のある方は是非チェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!