
【徹底比較】【Python】データ分析コンペそれぞれの特徴とトレーニング実装


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
データ分析をある程度できるようになるとぜひ挑戦してほしいのがデータ分析コンペ!
データ分析コンペを開催するサービスといえばKaggleが有名ですが、それ以外にもデータ分析コンペはNishikaやSignateなどたくさんあるんです。

そこでこの記事では、データ分析コンペの特徴についてまとめていきたいと思います!
また、いくつかのコンペのトレーニングデータのテスト実装もしていきます。
目次
各データ分析コンペの特徴

さてまずは、各データ分析コンペの特徴について比較していきましょう!
ここで紹介するのは以下の3つです。
やっぱりKaggleが圧倒的な知名度を誇るのですが、NishikaやSignateといった国産のデータ分析コンペもあるので是非チェックしてみてください!
Kaggle
| 【オススメ度】 | |
|---|---|
| 【入賞のしやすさ】 | |
| 【レベル】 | 中級者〜上級者 |
Kaggleとはデータサイエンティスト40万人を超える世界中のデータサイエンティストがひしめき合うコミュニティ。
そんなKaggleの基本構造は、企業が与えた課題に対して腕に自信のあるデータサイエンティストたちが挑む。
数か月の期間、与えられたデータを基に試行錯誤して最適なモデルを構築したチームにはあらかじめ決められていた賞金が付与されるというもの。
Kaggleにはランクがあり、10以位内に入賞するとゴールドメダルがもらえるのですがゴールドメダルを5回手に入れるとグランドマスターという最高位の称号を得ることができます。
Kaggleを生業にしているKagglerと呼ばれる人たちもいるくらい、Kaggleは非常に盛り上がりを見せています。
企業は賞金というインセンティブを用意することで、自社のデータ活用を世界的な水準まで押し上げることが可能です。
そして、活躍の場が制限されていたデータサイエンティストがKaggleによって日の目を浴びることになりました。
企業にとっても個人にとってもWin-Winな場になっているんです!
ただ年々レベルが上がっていて、上位に入賞するのは厳しくなりつつあります。
そしてデータセットも非常に膨大なものが多く初心者が扱うにはあまりにも時間がかかってしまうケースが多いです。
もちろんKaggleはオススメのデータ分析コンペサービスですが、なかなか取り組み続けるのには気概がいるのも事実。
ぜひ他のデータ分析コンペサービスも覗いてみるとよいでしょう!
以下の記事でKaggleの説明とKaggleへサブミットする準備などについてまとめていますので是非チェックしてみてください!
Nishika
| 【オススメ度】 | |
|---|---|
| 【入賞のしやすさ】 | |
| 【レベル】 | 初級者〜 |
Nishikaは国産のデータ分析コンペサービスで比較的新しいです。
海外ではKaggleなどのデータ分析コンペが有名ですが、国産のデータ分析コンペもいくつかあります。
「データ分析コンペを、日本の当たり前に」をコンセプトにデータ分析コンペの開催を中心にデータサイエンスで様々な課題を解決するための事業を展開しています。
画像認識・自然言語処理・需要予測・時系列分析など分野も網羅的に用意してくれているので最初に力試しとして取り組んでみることをオススメします!
世界的に有名なKaggleというデータ分析コンペももちろん有用ですが、データセットが煩雑でデータ量も爆発的に多くそもそもデータ分析のプロセスを1回まわすのにものすごく時間がかかってしまうコンペが多いです。
Kaggleで有名なタイタニックのデータは逆にサンプルが少なすぎて実践には不向きです・・・
その点、Nishikaは比較的扱いやすくかつ実践的なデータを基にデータ分析コンペが開催されているので初心者の人でも取り組みやすくオススメです。
以下のトレーニングコンペがちょうどよくオススメです。
・テーブルデータ: 【トレーニングコンペ】中古マンション価格予測
・画像データ:![]() 【トレーニングコンペ】絵巻物・絵本の画像分類
【トレーニングコンペ】絵巻物・絵本の画像分類
・テキストデータ:![]() 【トレーニングコンペ】文学:芥川龍之介
【トレーニングコンペ】文学:芥川龍之介
またKaggleは海外のプラットフォームなのでほとんど英語なのに対して国産のプラットフォームは日本語なのもよいところですね。
のちほど、このNishikaが提供しているトレーニングのデータ分析コンペのデータを題材に機械学習の実装をしていきます。
Signate

公式HP:https://signate.jp/
| 【オススメ度】 | |
|---|---|
| 【入賞のしやすさ】 | |
| 【レベル】 | 中級者〜 |
Signateという国産のデータ分析コンペもあります。
知名度はNishikaよりもSignateの方が圧倒的に高く、データコンペの開催数や参加人数もまだまだ多いです。
レベルはKaggleとNishikaの中間くらいのイメージです。
データ分析コンペのトレーニングデータを使って実装していく
ここまでで、データ分析コンペを比較してきましたが、実際にどんなものなのか Nishikaの「中古マンション価格予測」というトレーニングコンペのデータに対してLight gbmを実装してみたいと思います。
まず Nishikaに会員登録し中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
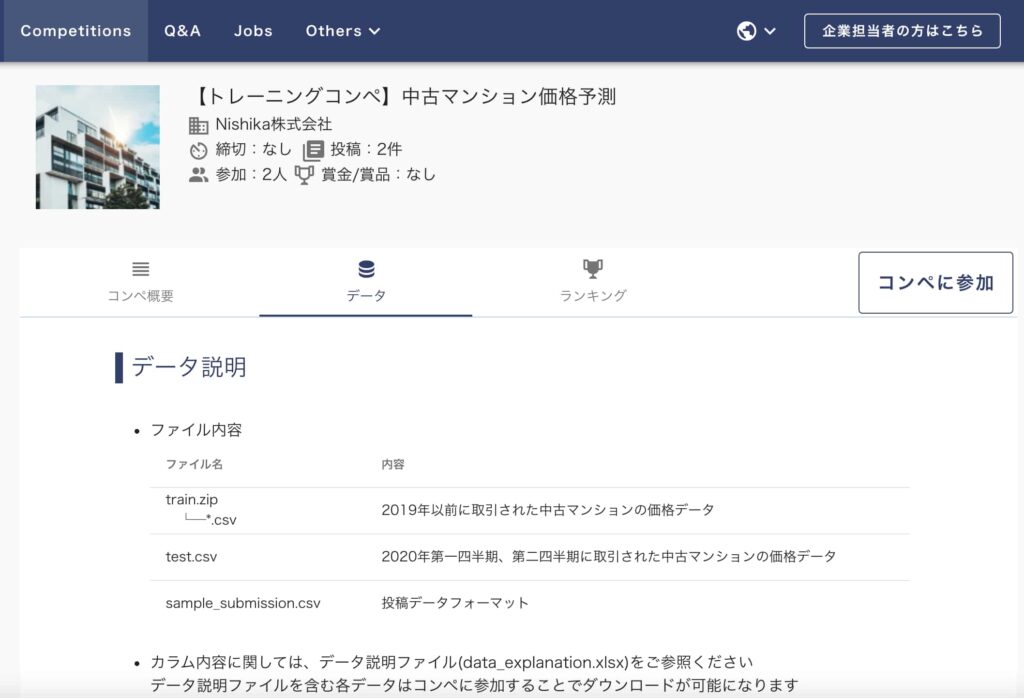
コンペティションのデータの箇所からダウンロードできます。
学習データには複数CSVが入っているので、それらをglobで結合させてデータフレーム化していきます。
globは、ディレクトリに格納されたファイル名を抽出するのに便利なライブラリです。

import glob
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as mae
files = glob.glob("train/*.csv")
data_list = []
for file in files:
data_list.append(pd.read_csv(file, index_col=0))
df = pd.concat(data_list)カラムを見てみると・・・

欠損値があったり、数値型で欲しいデータが文字列型になっていたりするので前処理を施していきます!
def data_pre(df):
nonnull_list = []
for col in df.columns:
nonnull = df[col].count()
if nonnull == 0:
nonnull_list.append(col)
df = df.drop(nonnull_list, axis=1)
df = df.drop("市区町村名", axis=1)
df = df.drop("種類", axis=1)
dis = {
"30分?60分":45,
"1H?1H30":75,
"2H?":120,
"1H30?2H":105
}
df["最寄駅:距離(分)"] = df["最寄駅:距離(分)"].replace(dis).astype(float)
df["面積(㎡)"] = df["面積(㎡)"].replace("2000㎡以上", 2000).astype(float)
y_list = {}
for i in df["建築年"].value_counts().keys():
if "平成" in i:
num = float(i.split("平成")[1].split("年")[0])
year = 33 - num
if "令和" in i:
num = float(i.split("令和")[1].split("年")[0])
year = 3 - num
if "昭和" in i:
num = float(i.split("昭和")[1].split("年")[0])
year = 96 - num
y_list[i] = year
y_list["戦前"] = 76
df["建築年"] = df["建築年"].replace(y_list)
year = {
"年第1四半期": ".25",
"年第2四半期": ".50",
"年第3四半期": ".75",
"年第4四半期": ".99"
}
year_list = {}
for i in df["取引時点"].value_counts().keys():
for k, j in year.items():
if k in i:
year_rep = i.replace(k, j)
year_list[i] = year_rep
df["取引時点"] = df["取引時点"].replace(year_list).astype(float)
for col in ["都道府県名", "地区名", "最寄駅:名称", "間取り", "建物の構造", "用途", "今後の利用目的", "都市計画", "改装", "取引の事情等"]:
df[col] = df[col].astype("category")
return df
df = data_pre(df)
この前処理に関してここでは詳細は省きますが、全てが欠損値になっているカラムを削除して、「最寄り駅・面積・建築年・取引時点」に関して変換をおこなっています。
そして前処理をおこなったデータに対してLight gbm を実装!
df_train, df_val =train_test_split(df, test_size=0.2)
col = "取引価格(総額)_log"
train_y = df_train[col]
train_x = df_train.drop(col, axis=1)
val_y = df_val[col]
val_x = df_val.drop(col, axis=1)
trains = lgb.Dataset(train_x, train_y)
valids = lgb.Dataset(val_x, val_y)
params = {
"objective": "regression",
"metrics": "mae"
}
model = lgb.train(params, trains, valid_sets=valids, num_boost_round=1000, early_stopping_rounds=100)簡単ですね!
このタスクでは評価指標がMAE(平均絶対誤差)であり、Validationデータでの結果は
0.0764となりました!
データコンペですのでテストデータで予測値を算出し提出するところまでやってみましょう!
df_test = pd.read_csv("test.csv", index_col=0)
df_test = data_pre(df_test)
predict = model.predict(df_test)
df_test["取引価格(総額)_log"] = predict
df_test[["取引価格(総額)_log"]].to_csv("submit_test.csv")これでサブミット用のファイルを作成することができましたー!
簡単に実装できましたねー!
作成したファイルはサブミットしていきましょうー!
コンペティションの結果を投稿のボタンからサブミットすることが出来ます。
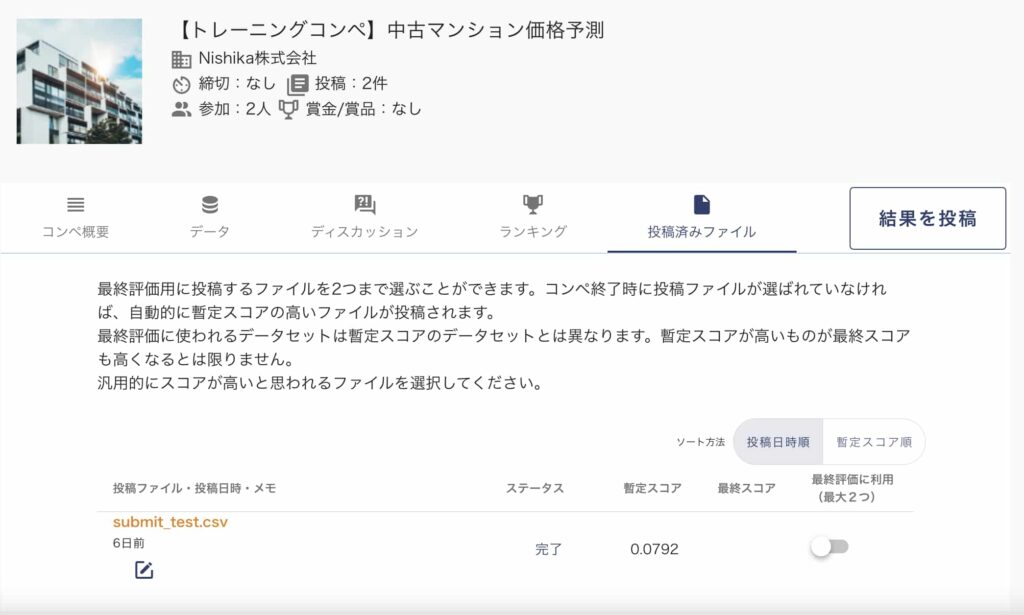
テストデータでの結果は0.0792となりましたー!
全コードは以下になります!
パラメータチューニングや特徴量エンジニアリングによってさらに精度が上がりますので是非色々と手を動かしてみてください!
今回扱ったデータは中古マンションの価格データということで比較的扱いやすいデータセットになっています。
他にも画像認識や自然言語処理のデータなどがあるので是非挑戦してみてください!
データ分析コンペに臨む上での勉強法

トレーニングコンペでの実装をおこなってきましたが、完全に初心者の方にとってはなかなか難しいと思います。
そこでここではデータ分析コンペに臨む上でおすすめの勉強法や勉強教材についてまとめていきます。
大きく分けてやってほしいことは以下の2つです。
・データ分析の全体像を把握する
・機械学習の基礎知識を身に付ける
・Pythonでの実装
データ分析の全体像を把握する
データ分析の全体像を把握するためには、以下の「俺たちひよっこデータサイエンティストが世界を変える」という書籍がオススメです!

あまり具体的なデータサイエンティストの仕事について分かりやすく書いている本が見当たらなかったので自分で執筆しました!
勾配ブースティング木のXGBoostを使ったビジネスシーンでの実装についてストーリー形式で簡単にまとめていますのでイメージをふくらませてもらうのにちょうど良いかと思います!
価格は300円ちょっとですし、Kindle unlimitedであれば無料で読めるのでぜひチェックしてみてくださいね!
他にも以下の書籍がデータ分析の全体像を理解する上でオススメなので適宜目を通してみてください!


機械学習の基礎知識を身に付ける
続いて機械学習の基礎知識を身に付けていきます。
このフェーズでは、以下のUdemyコースがオススメです!
【初学者向け】データ分析コンペで楽しみながら学べるPython×データ分析講座
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 4時間 |
| 【レベル】 | 初級~中級 |
このコースは、なかなか勉強する時間がないという方に向けてコンパクトに分かりやすく必要最低限の時間で重要なエッセンスを学び取れるように作成しています。
アニメーションを使った概要編とハンズオン形式で進む実践編に分かれており、概要編ではYoutubeの内容をより体系的にデータ分析・機械学習導入の文脈でまとめています。
データサイエンスの基礎について基本のキから学びつつ、なるべく堅苦しい説明は抜きにしてイメージを掴んでいきます。
統計学・機械学習の基本的な内容を学び各手法の詳細についてもなるべく概念的に分かりやすく理解できるように学んでいきます。
そしてデータ分析の流れについては実務に即したCRISP-DMというフレームワークに沿って体系的に学んでいきます!
データ分析というと機械学習でモデル構築する部分にスポットがあたりがちですが、それ以外の工程についてもしっかりおさえておきましょう!
続いて実践編ではデータコンペの中古マンションのデータを題材にして、実際に手を動かしながら機械学習手法を実装していきます。
ここでは、探索的にデータを見ていきながらデータを加工し、その上でLight gbm という機械学習手法を使ってモデル構築までおこなっていきます。
是非興味のある方は受講してみてください!
Twitterアカウント(@statistics1012)にメンションいただければ1500円になる講師クーポンを発行いたします!
ちなみにもっと理論に踏み込みたい!という方は以下を参考にしてみてください!
AI・機械学習を学ぶ前手の数学勉強法については以下の記事で詳しくまとめています!

Pythonでの実装
ここからガッツリPythonでの実装に入っていきます。
先ほどの「【初学者向け】データ分析コンペで楽しみながら学べるPython×データ分析講座」でもPython実装部分はあるのでそちらで学んでいただいても問題ないですが、ガッツリ学ぶのであれば当メディアが運営するスタアカ(スタビジアカデミー)が非常にオススメです!
スタアカ(スタビジアカデミー)

公式サイト:https://toukei-lab.com/achademy/
| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる1週間に1回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
また、さらに深い特徴量エンジニアリングなどについて学びたい方は以下の書籍は非常に勉強になります!

ぜひチェックしてみてください!
またデータ加工集計可視化100本ノックというUdemyコースも私が講師で作っていますのでこちらも力試しに使ってみてください!!
【実践】Python✕データサイエンス加工・集計・可視化処理100本ノック!実務でよく使う100個の問題にチャレンジ!
| 【時間】 | 4.5時間 |
|---|---|
| 【レベル】 | 初級〜中級 |
Python✕データサイエンス関連の100問に挑戦して腕試ししたいならこれ!
今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
また、PythonでオススメのUdemyコースについて以下でまとめています!
Pythonの勉強に関しては以下の記事で詳しく解説していますので是非チェックしてみてください!

結局どのデータ分析コンペを選べばよい?

さて、結局いくつかのデータ分析コンペがあることは分かりましたが、どのコンペを選べばよいのでしょう?
結論から言うと、サービスで選ぶのではなくコンペで選ぶことをオススメします。
コンペの内容は色んなものがあるので、自分が得意な領域だったり自分が取り組んでみたい領域のコンペティションを探して挑戦してみることをオススメします。
そのためには、KaggleもNishikaもSignateもとりあえず全て登録しておいて、定期的にコンペティションをチェックすることをオススメします。
初心者におすすめなのはNishikaですが、ぜひ自分の取り組みたいコンペを色々と探してみてください!
データ分析コンペ まとめ
ここまでご覧いただきありがとうございました!
本記事では、データ分析コンペについて見てきました。
データ分析コンペといってもKaggleだけではなく、いくつかのコンペティションがあることがご理解いただけたでしょうか?
データ分析コンペティションは実践力を積むのに非常にオススメな場で、ぜひぜひ取り組んで欲しいです。
Kaggle・Nishika・Signateの中から自分に合ったコンペを探して挑戦してみましょう!
データサイエンティストへの勉強法や機械学習・Pythonの勉強法については以下の記事で解説しています。


またデータ分析手法については以下の記事で詳しくまとめています!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















