【入門】自然言語処理でできることをいくつかPythonで実装してみる!


こんにちは!
消費財メーカーでデジタルマーケター・データサイエンティストを経験後、現在は独立して働いているウマたん(@statistics1012)です!
自然言語処理は、機械に人間の言葉を理解させる上で非常に重要な領域。
しかーし、あんまり自然言語処理の中身についてはブラックボックスでよく分かっていないという人が多いのではないでしょうか?

ということで、この記事では自然言語処理についてまとめていきたいと思います。
様々な自然言語処理領域に対してPython実装をおこなっていくので、気になるところからつまみ食い的にチェックしてみてください!
ちなみに当メディアが運営する学習プラットフォーム「スタアカ」の自然言語処理コースで自然言語処理について詳しく学べますので興味のある方はチェックしてみてください!

目次
自然言語処理とは
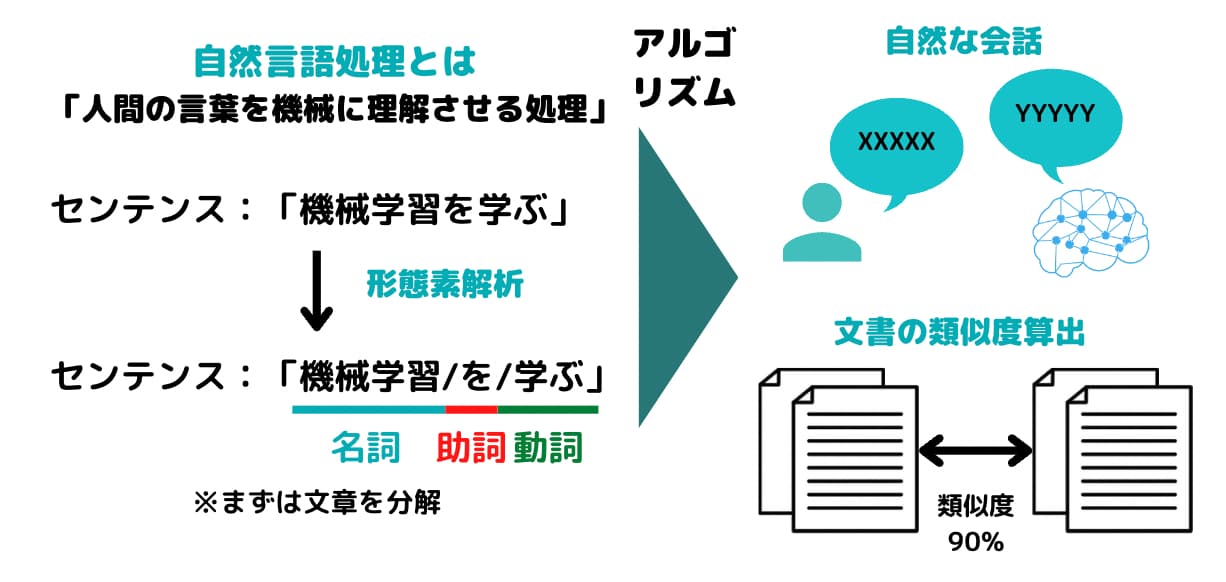
まず、自然言語処理とは何でしょうか?
自然言語処理とは、端的に言うと「人間の言葉を機械が理解するルール作り」です。
言葉は、人類が生み出した虚構であり文化によって全く違う構造を持ちます。
そんな言葉を機械が理解できるようにする領域が自然言語処理なのです。
機械が人間の言葉をしっかり理解するためには、文脈理解と単語理解が必要。
単語理解は、どのような言葉がどのような意味で使われているかをまとめた辞書(コーパスと呼ばれる)が必要になってきます。
そんな辞書と大量の文章をインプットさせて機会が文意を読み取ることができるようになるのです。
そのため、実は自然言語処理の分野では教師データがどれだけリッチかが非常に重要なんです。
その点では中国など個人情報の法規制に緩い国が有利。
なぜなら昨今のデジタル上でのコミュニケーションを仮にテキスト情報としてインプットすることが出来れば、各段に自然言語処理精度が上がるからです。
今のところ、コミュニケーションのテキスト情報をインプット情報として使える企業は少ないです。
日本でも、LINE社は日々の大量のコミュニケーション情報をテキストとして保持していながら個人情報保護の観点から解析に使えない状態になっています。
個人情報の取り扱いに関しては国によって全く方針が違うんですよねー。
以下の動画で自然言語処理について詳しく解説しているのであわせてチェックしてみてください!
Pythonで自然言語処理で出来ることを実装

続いて、いくつかのトピックを紹介しながらPythonで実装をおこなっていきます。
MeCabで形態素解析をしてみよう!

まずは、形態素解析。
形態素解析とは、文章を単語単位で区切りそれぞれの単語に情報を付与する手法です。
形態素解析エンジンにはいくつかの種類がありますが、ここではMeCabを使用していきます。
Mecabは古くから有名で最も良く使われている形態素解析エンジン。
PythonだけでなくRやRubyなど他のプログラミング言語も使用することが可能です。
まずは、MeCabを使う環境を整えていきましょう!
MeCabを使う場合はGoogle colaboratoryを使うのがオススメです。
Google colaboratoryであれば、以下のように記述してあげることでMecabを利用することができます。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7Google ColaboratoryとはGoogleが無料で提供してくれているクラウド実行型のJupyter notebook実行環境です。
Googleのアカウントを持ってさえいれば誰でも使用することができ、開発環境を整える必要もなくPythonによる機械学習実装が可能です。
ローカル環境でMecabを使う場合は以下のURLから「mecab-0.996-64.exe」をダウンロードしてセットアップする必要があります。
https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
早速MeCabを利用して文章を単語区切りに分解していきます。
import MeCab
text = "テキストを入れる"
m=MeCab.Tagger()
m1=m.parse (text)たったこれだけで、textを単語区切りにしてくれるんです。
試しにこのtext部分に
”統計ラボはデータサイエンスとWebマーケティングをまとめたサイトです”
と入れてみます。
※スタビジの旧サイト名は統計ラボでした
すると・・・
以下のような結果が返ってきます。素晴らしい!
統計 名詞,サ変接続,*,*,*,*,統計,トウケイ,トーケイ ラボ 名詞,一般,*,*,*,*,ラボ,ラボ,ラボ は 助詞,係助詞,*,*,*,*,は,ハ,ワ データ 名詞,一般,*,*,*,*,データ,データ,データ サイエンス 名詞,一般,*,*,*,*,サイエンス,サイエンス,サイエンス と 助詞,並立助詞,*,*,*,*,と,ト,ト Web 名詞,固有名詞,組織,*,*,*,* マーケティング 名詞,一般,*,*,*,*,マーケティング,マーケティング,マーケティング を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ まとめ 動詞,自立,*,*,一段,連用形,まとめる,マトメ,マトメ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ サイト 名詞,一般,*,*,*,*,サイト,サイト,サイト です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス EOS
返ってきた結果に対して名詞だけ取り出したいケースが多いため、.splitを使い2つ目の要素が名詞だったら配列に格納するような処理を行ってみましょう!
以下のようになります!
word_list = []
for row in m1.split("\n"):
word =row.split("\t")[0]#タブ区切りになっている1つ目を取り出す。ここには形態素が格納されている
if word == "EOS":
break
else:
pos = row.split("\t")[1]#タブ区切りになっている2つ目を取り出す。ここには品詞が格納されている
slice = pos[:2]
if slice == "名詞":
word_list.append(word)
print(word_list)これによりテキスト情報を単語に分解し、名詞だけ格納した配列が出来上がりました。
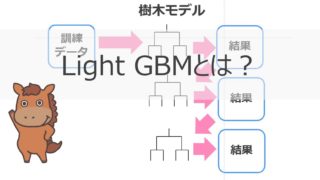
形態素解析×Light gbmで文章の著者を予測してみる

続いて、形態素解析したデータに対してLight gbmという強力な機械学習手法を使って文章の著者なのかを予測してみたいと思います。
データは、![]() Nishikaというデータコンペの「AIは芥川龍之介を見分けられるのか?」というコンペのデータを使います。
Nishikaというデータコンペの「AIは芥川龍之介を見分けられるのか?」というコンペのデータを使います。
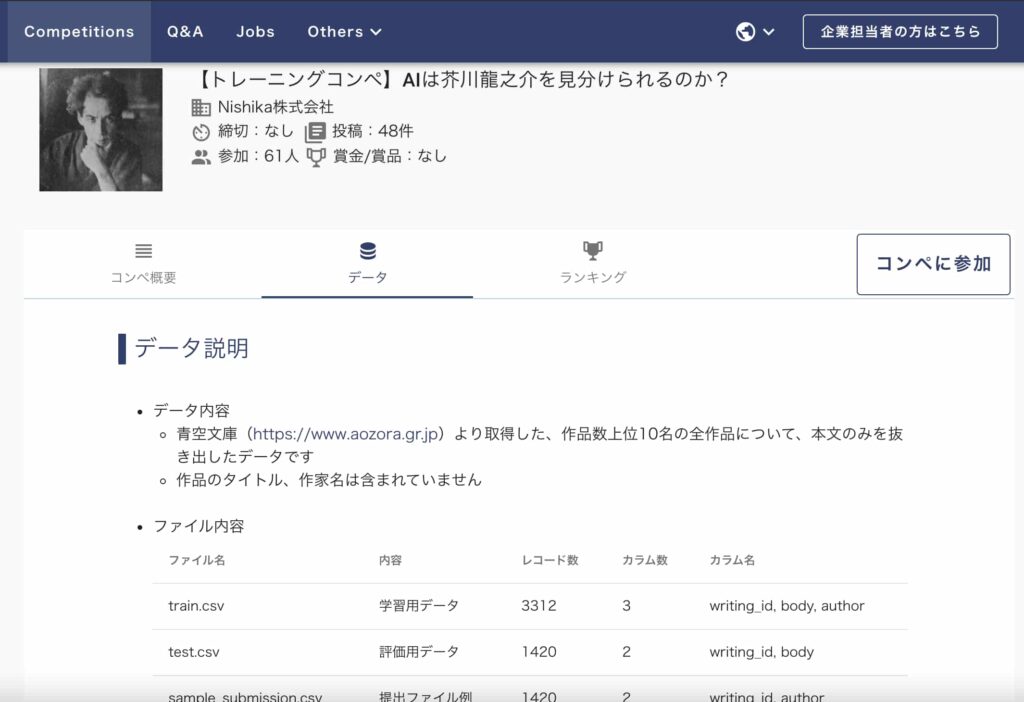
![]() Nishikaに会員登録をしてtrainデータをローカル環境にダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
Nishikaに会員登録をしてtrainデータをローカル環境にダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
データは、3,312個の文章とそれぞれに対して芥川龍之介が否かがラベルで付いているデータになっています。
こちらもMeCabを利用するのでGoogle colaboratory上で実装していきます。
以下のように記述してあげることでMecabが使えるようになります。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7まずは必要なライブラリをインストールします。
import pandas as pd
import numpy as np
import collections
import MeCab
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score続いて必要なデータをデータフレームとして読み込みます。
df = pd.read_csv("/content/drive/MyDrive/Stabiz/python/data-science/nishika_text_data/train.csv")
続いてMeCabにより形態素解析を行い各文章ごとの単語を集計していきます。
m = MeCab.Tagger("")
text_list = []
length_list = []
# それぞれの文書を取り出して形態素解析
for sentence in df["body"]:
ma = m.parse(sentence)
word_list = []
# 形態解析後の単語だけ抽出
for text in ma.split("\n"):
word_list.append(text.split("\t")[0])
# 単語の数を集計
length_list.append(len(word_list))
# 単語の頻度を集計
data = collections.Counter(word_list)
text_data = pd.DataFrame.from_dict(data, orient='index')
text_list.append(text_data)そして3312個の全文章の中で登場する単語の上位100個の頻出単語だけ特徴量とします。
feature = pd.concat(text_list, axis=1)
#Nanを0に置換
feature = feature.fillna(0)
#Arrayに変換
feature_temp = feature.values.sum(axis=1)
#上位k件
K = 100
#上位k件のインデックス
indices = np.argpartition(-feature_temp, K)[:K]
文章ごとに長さが違うので、長さのバイアスを取り除くために各特徴量を各文章の全単語数で割返して特徴量とします。
## 各文書に対して全体で頻出の上位k個の単語の出現数をその文書の単語出現数で割ったものを変数とする ##
modi_feature = []
for index, row in feature.iloc[indices].T.reset_index(drop=True).iterrows():
modi_feature_temp = row/length_list[index]
modi_feature.append(modi_feature_temp)
modi_feature = pd.concat(modi_feature, axis=1).T
# 各文書と作成した特徴量を結合
df = pd.concat([df, modi_feature], axis=1)その上でやっとLight gbmの実装をしていきます!
## Light gbmと実装
df = df.drop(["writing_id", "body"], axis=1)
df_train, df_val = train_test_split(df, test_size=0.2)
col = "author"
train_y = df_train[col]
train_x = df_train.drop(col, axis=1)
val_y = df_val[col]
val_x = df_val.drop(col, axis=1)
trains = lgb.Dataset(train_x.values, train_y)
valids = lgb.Dataset(val_x.values, val_y)
params = {
"objective": "binary",
"metrics": "binary_logloss"
}
model = lgb.train(params, trains, valid_sets=valids, num_boost_round=1000, early_stopping_rounds=100)
最後に得られたモデルから予測値を算出し、その値に対してF-measureを算出しています。
## 予測:量的変数で返ってきているので0.5を閾値にして0,1に振り分ける
predict_list = []
for i in model.predict(val_x):
if i > 0.5:
predict = 1
else:
predict = 0
predict_list.append(predict)
f1_score(val_y, predict_list)
この時予測値は連続値で返ってくるので、0.5を閾値にして0,1に振り分けています。
F-measureは分類問題でよく使われる指標で適合率と再現率の調和平均を取っています。

結果的にF-measureの値は・・・0.851となりました!
以下が全コードになっています。
関数化していないので少し処理がわかりにくいですがご容赦を・・・
Mecabに関してより詳しくは以下の記事でまとめています。

URLからスクレイピングでテキストを引っ張ってきて、それらをMecabで形態素解析し、テキスト類似度を測るプログラムを以下で公開していますのでぜひチェックしてみてください!
また今回利用したLight gbm については以下の記事で詳しく解説しています!
RNNを使ってみる
続いて、ディープラーニングの領域に足を踏み入れてみましょう!
RNNはリカレントニューラルネットワークの略で、ディープラーニングの層構造に再帰性を取り入れたもの。
通常のディープラーニングでは、時系列要素のあるデータを上手く扱えないという欠点があるんです。

そんなディープラーニングの構造に対して、時系列要素を加えて順番を考慮しようよというのがRNNの考え方。
時系列処理はテキストの文脈を読み取る上で非常に重要です。
例えば英語で、he said “I’m () ” という文章があった時、()の中身を当てるのは相当難しい。
しかし、その後ろにこんな文脈があったらどうでしょう?
Tom came home, and he said “I’m () “.
()の中にどのような文章が入るかほとんどの人が分かると思います。
おそらくTom came home, and he said “I’m home “でしょう。
このようにテキストの文脈からワードを推論するのは周りの文脈が非常に重要なんです。
それを実現できるのがRNNと考えてください。
今までのディープラーニングでは、それぞれのインプットがそれぞれの中間層に与えられていましたが、RNNでは同一の中間層を用いて再帰的にインプットが行われます。
再帰的という部分がReccurentと言われるゆえんです。
こんなイメージ
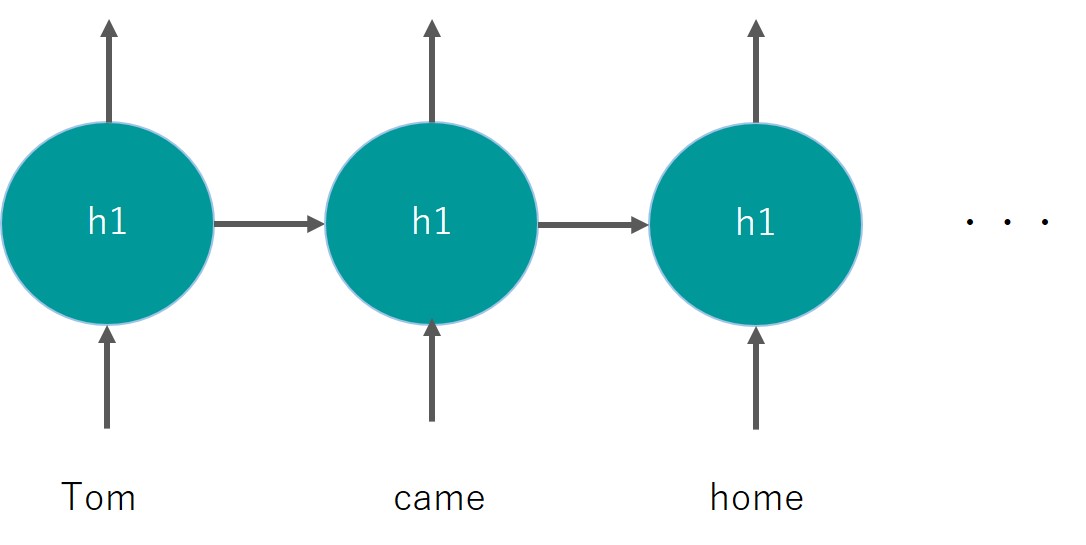
同じレイヤーh1を用いているのがミソです。
これにより前のワードの情報をレイヤに記憶させ後続へとつなぐことができます。
自然言語処理ではないですが、RNNを使って時系列問題を解くことができるというところを見ていきましょう!
使うデータセットはKaggleのホームページが落とせる航空会社の乗客数データ!
1949年から1960年までの月別乗客数がデータとして入っています。
149行2列のシンプルなデータセット。
1変数の時系列データを基に過去のデータから未来の値を予測します。
この時、tflearnというライブラリを使ってRNN(正確にはLSTM)を実装していきます。tflearnはkerasと似たようなライブラリでディープラーニングの実装が感覚的に容易にできます。
実際にモデルを構築していきましょう!
最終的な評価はRMSE(Root Mean Square Error)で算出しています。
RMSEは0.10079201となりました。それなりに良い予測ができてる!
RNNについて詳しくは以下の記事でまとめています。

Googleが公表したBERTを使ってみる
最後にGoogleが2018年に公表し、2019年に検索アルゴリズム適応させたBERTについて見ていきましょう!
BERTとは「Bidirectional Encoder Representations from Transformers」の略であり、Googleが新たに開発した自然言語処理のロジックになります。
BERTの登場によりGoogleはより長く複雑な文章を理解できるようになり、文脈を読み取ることができるようになりました。
実際にGoogleのリリースにBERT導入前と導入後のGoogle検索の違いが記載されています。
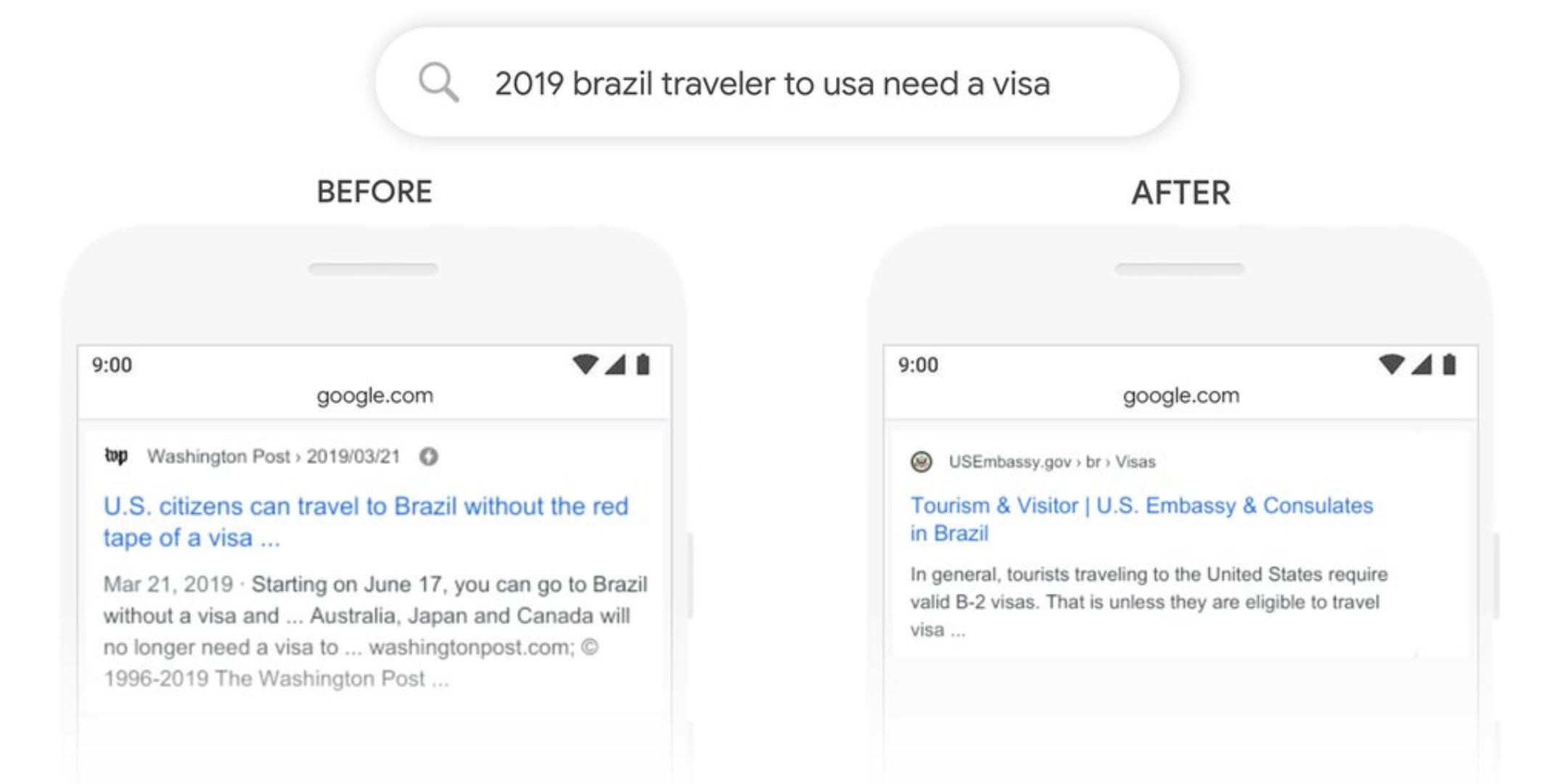 (引用元:Google-”Understanding searches better than ever before”)
(引用元:Google-”Understanding searches better than ever before”)
ブラジル人が米国へ渡航する際のビザの有無を知りたいのですが、BERT実装前は英文における”to”の意味を明確に捉えることができずアメリカ人がブラジルへ旅行する場合の結果を返していました(左側)。
BERT実装後は、しっかりアメリカ渡航の際の結果を返すことができています。
このように検索結果が、より検索者の検索意図を読み取れるように進化してきているのです。
それでは、そんなBERTを実際に実装してみましょう!
BERTを使って以下の日本語文章の空白を予測してみます。
※当サイト【スタビジ】は昔統計ラボというサイトでした
[‘統計’, ‘ラボ’, ‘は’, ‘*’, ‘を’, ‘発信’, ‘する’, ‘サイト’, ‘です’]
京都大学の黒橋・河原・村脇研究室の作成した強力な形態素解析器JUMAN++をインストールしていきます。
こちらは、先ほどのMeCabよりも口語に対応している形態素解析です。
BERTを実装するためには日本語における相当な量の事前学習が必要なのですが京都大学の黒橋・河原・村脇研究室が公開してくれています。
非常にありがたいですね!
import urllib.request
kyoto_u_bert_url = "http://nlp.ist.i.kyoto-u.ac.jp/nl-resource/JapaneseBertPretrainedModel/Japanese_L-12_H-768_A-12_E-30_BPE.zip"
urllib.request.urlretrieve(kyoto_u_bert_url, "Japanese_L-12_H-768_A-12_E-30_BPE.zip")続いてZIPファイルを解凍していきます。
!unzip Japanese_L-12_H-768_A-12_E-30_BPE.zipこれで、日本語モデルの準備は完了です。
config = BertConfig.from_json_file('/content/drive/My Drive/bert/japan_test/Japanese_L-12_H-768_A-12_E-30_BPE/bert_config.json')
model = BertForMaskedLM.from_pretrained('/content/drive/My Drive/bert/japan_test/Japanese_L-12_H-768_A-12_E-30_BPE/pytorch_model.bin', config=config)
bert_tokenizer = BertTokenizer('/content/drive/My Drive/bert/japan_test/Japanese_L-12_H-768_A-12_E-30_BPE/vocab.txt',
do_lower_case=False, do_basic_tokenize=False)必要なパラメータやモデル、BERTが扱いやすい形に加工するための変換処理などを先ほどダウンロードした日本語Pretrainedモデルから取得します。
text = "スタビジは*を発信するサイトです"
result = jumanpp.analysis(text)
tokenized_text = [mrph.midasi for mrph in result.mrph_list()]
print(tokenized_text)続いて、JUMAN++によって品詞分解を行います。
[‘統計’, ‘ラボ’, ‘は’, ‘*’, ‘を’, ‘発信’, ‘する’, ‘サイト’, ‘です’]
tokenized_text.insert(0, '[CLS]')
tokenized_text.append('[SEP]')
masked_index = 4
tokenized_text[masked_index] = '[MASK]'
print(tokenized_text)文章の区切れやマスクする部分をBERTに明示的に知らせるために、SEPやMASKを挿入していきます。
CLSは文章の頭に、SEPは文章の区切れに、MASKは隠したい部分に適用します。
[‘[CLS]’, ‘統計’, ‘ラボ’, ‘は’, ‘[MASK]’, ‘を’, ‘発信’, ‘する’, ‘サイト’, ‘です’, ‘[SEP]’]
tokens = bert_tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([tokens])そして、得られたテキストをBERT用に変換します。
model.eval()
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
_,predicted_indexes = torch.topk(predictions[0, masked_index], k=10)
predicted_tokens = bert_tokenizer.convert_ids_to_tokens(predicted_indexes.tolist())
print(predicted_tokens)そして、マスクされた部分の予測を行います。
結果は・・・
[‘統計’, ‘情報’, ‘データ’, ‘ニュース’, ‘それ’, ‘調査’, ‘分析’, ‘レポート’, ‘トレンド’, ‘ランキング’]
上手く予測できていることが分かります!
ところどころ省略しているので詳しくは以下の記事をチェックしてみてください!

トピック分析を行ってみる
トピックモデルの主な目的は、大量の文書から隠れたトピックを抽出し、それらのトピックが文書にどのように分布しているかを理解することです。
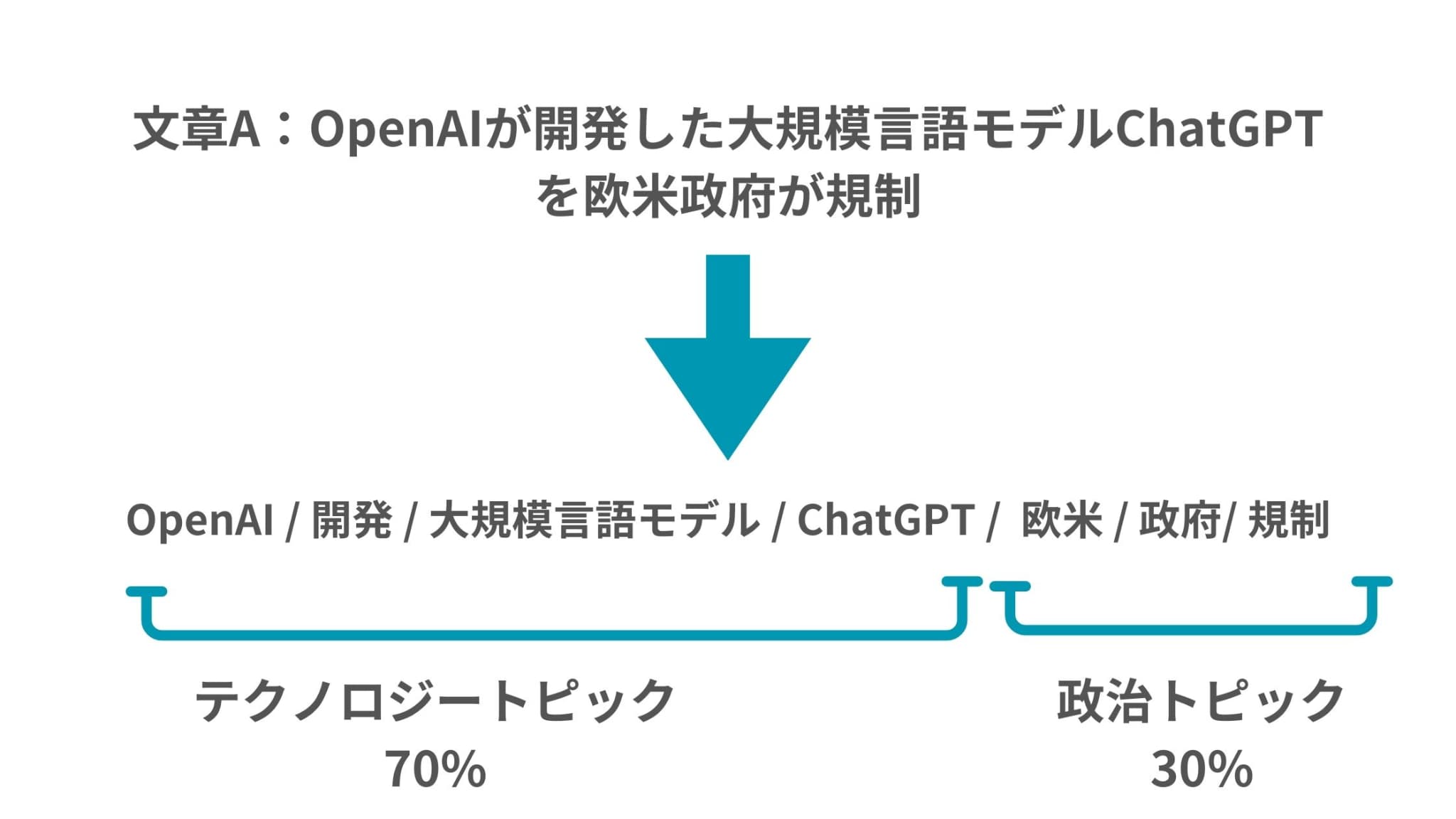
例えば、「OpenAIが開発した大規模言語モデルChatGPTを欧米政府が規制」
みたいな記事があればAI関連のトピックとも考えられますが、政治関連のトピックとも考えられます。
そのためこの文書にはAI関連のトピックと政治関連のトピックが潜在的に存在していることになるのです。
それではここでは、そんなトピックモデルの1つのアプローチであるLDA(潜在的ディリクレ配分法)をPythonで実装していきたいと思います。
トピックモデルのベースとなる文章を手に入れる必要があるので、NEWS_APIと使ってニュースを取得します。
処理の流れは以下の通りです。
1.NEWS_APIからニュース情報を取得
2.ニュース情報からタイトルだけ抽出
3.ニュースタイトルの文章からストップワードを削除して名詞だけに絞る
4.単語出現回数をカウント
5.LDAを適用させて結果を表示
それでは実際にコードを見てみましょう!
from newsapi import NewsApiClient
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import pandas as pd
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
# NLTKのリソースをダウンロード
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('stopwords')
# NEWS_APIのキーを設定
api_key = '<NEWS_APIのキー>'
newsapi = NewsApiClient(api_key=api_key)
# ニュース記事を取得
articles = newsapi.get_everything(q='latest', language='en', page_size=100)
titles = [article['title'] for article in articles['articles']]
# ストップワードの削除と名詞だけに絞る処理
stop_words = set(stopwords.words('english'))
filtered_titles = []
for title in titles:
words = word_tokenize(title)
words = [word for word in words if word.lower() not in stop_words]
nouns = [word for word, pos in pos_tag(words) if pos in ['NN', 'NNS']]
filtered_titles.append(" ".join(nouns))
# タイトルから単語の出現回数をカウント
vectorizer = CountVectorizer()
title_counts = vectorizer.fit_transform(filtered_titles)
# LDAモデルを適用
topic_num = 5
lda = LatentDirichletAllocation(n_components=topic_num, random_state=42)
lda.fit(title_counts)
# トピックごとの単語を表示
words = vectorizer.get_feature_names_out()
for topic_idx, topic in enumerate(lda.components_):
print(f"Topic #{topic_idx}:")
print(" ".join([words[i] for i in topic.argsort()[:-10 - 1:-1]]))
# 各記事のトピックをデータフレームに保存
doc_topic = lda.transform(title_counts)
df = pd.DataFrame(doc_topic, columns=[f'Topic {i}' for i in range(topic_num)])
df['Title'] = titles
print(df.head())
結果は以下のようになりました!


5つのトピックを表現する特徴的な単語が列挙されていて、それぞれのニュース記事がどのトピックに分類されそうか確率値が並んでますね!
以下の記事で詳しく解説していますのでチェックしてみてください!

OpenAIのEmbeddingベクトル化
OpenAIのEmbedding APIを使うと文章をベクトルに変換することができます。
Embeddingは以下のようなイメージ
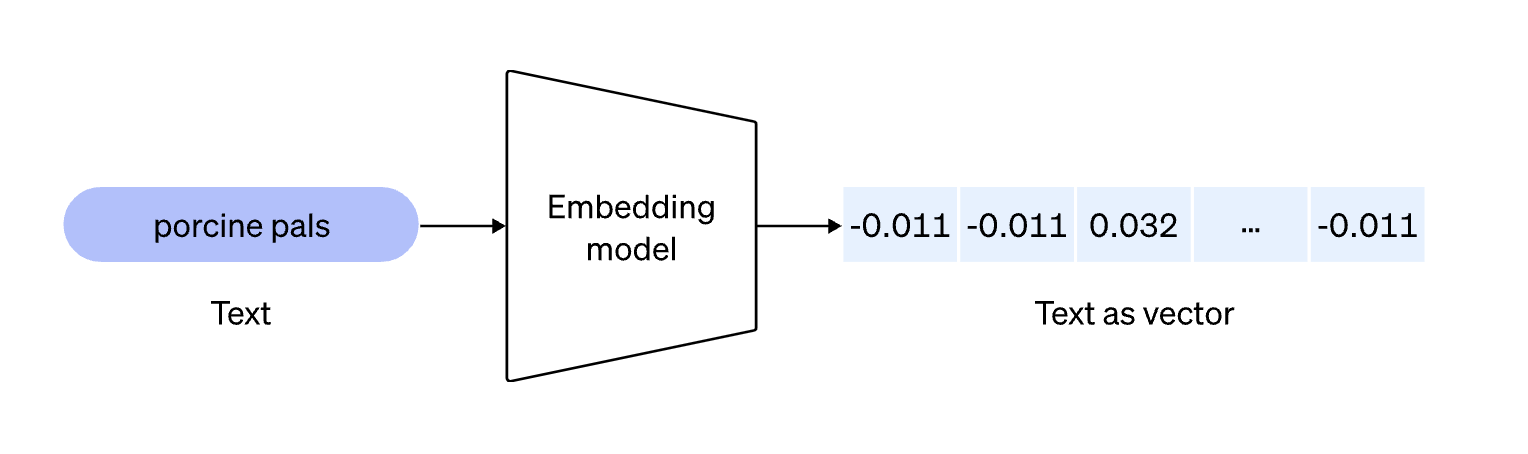
単語のベクトル化は非常に様々な領域で利用します。
まず、必要なライブラリをインポートしてOpenAIのAPIキーを記述していきます。
OpenAIのAPIキーを取得していない人は公式サイトから取得しましょう。
import openai
from openai.embeddings_utils import cosine_similarity
import json
openai.api_key = "<OpenAIのAPIキー>"
続いて文章をベクトル化していきます!
以下のように記述してください。
def text_to_embedding(text):
response = openai.Embedding.create(
model= "text-embedding-ada-002",
input=[text]
)
return response["data"][0]["embedding"]ここでは、”text-embedding-ada-002″というモデルを指定して文章をベクトル化し返してくれる関数を定義しています。
それでは、文章をベクトル化していきましょう!
texts = ["吾輩は猫である", "私は猫です", "データサイエンスが好きです"]
embeddings = []
for text in texts:
embeddings.append(text_to_embedding(text))
これらの文章は何でも問題ありません。
まずは、1つ目と2つ目を比較してみましょう!
cosine_similarity(embeddings[0], embeddings[ 1 ])0.9514619587040718
結果は約0.95となりました。
続いて、2つ目と3つ目を比較してみましょう!
cosine_similarity(embeddings[ 1 ], embeddings[ 2 ])0.8207195033580368
結果は約0.82となりました。
想定どおり、1つ目と2つ目の類似度が非常に高い2つ目と3つ目の類似度はそれよりだいぶ低い結果になりました。
以下の記事で解説しています!

Word2Vec
Word2Vecという有名な単語ベクトル化のアプローチについてもとりあげておきましょう!
Word2Vecの論文内では2つのアプローチが提案されています。
・CBOW
・Skip-gram
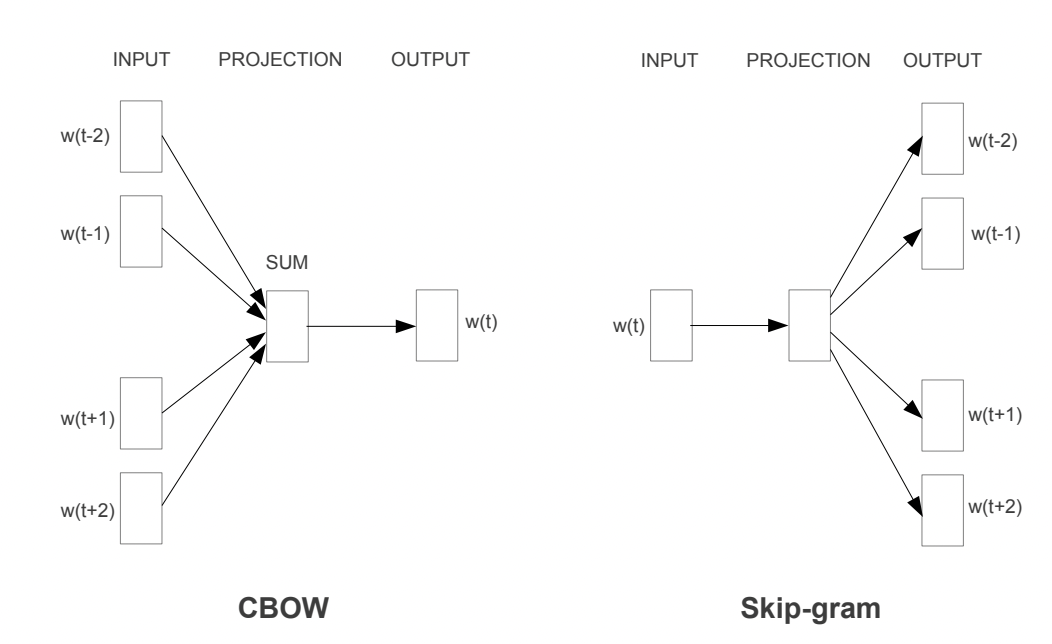
それぞれについて見ていきましょう!
CBOW
CBOWは、前後の文脈から対象となる単語を推論するアプローチです。
例えば、
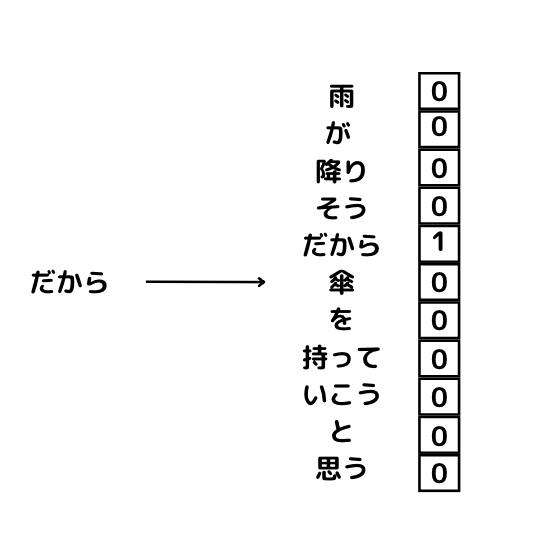
「雨が降りそうだから傘を持っていこうと思う」という文章があった時にその文章は以下のように分解することができます。
雨 / が / 降り / そう / だから / 傘 / を / 持って / いこう / と / 思う
この単語のかたまりのうち傘の部分をマスクしてみましょう!
雨 / が / 降り / そう / だから / ? / を / 持って / いこう / と / 思う
この状態で前後関係からマスクした「?」の部分を推測するのがCBOWです。
前後複数個の単語からマスクした単語を予測するわけです。
まずそれぞれの単語をOne-hot ベクトル化します。
これらのOne-hotベクトル化したものそれぞれに対して重み行列によって次元圧縮して平均を取ったものを最終的に重み行列で元の次元に戻して予測するモデルを構築します。
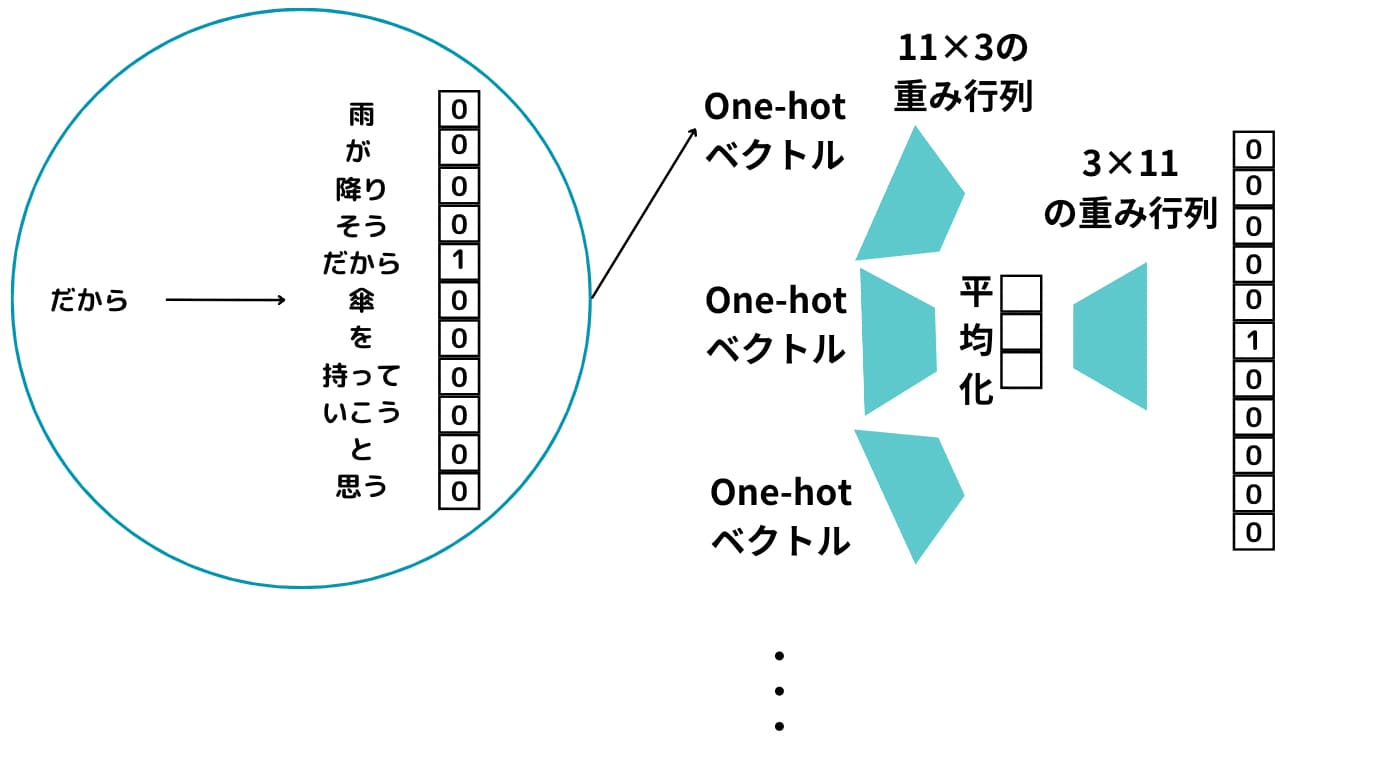
シンプルな2層構造のニューラルネットワークになることが分かりますね!
この時上手く出力結果が、「雨」になるようにニューラルネットワークの重みを調整します。
この過程で出力される重み行列の各行がWord2Vecで求められる単語ベクトルになるんです!
つまり、特定単語の前後から特定単語を予測する問題を解いている過程で生成されるベクトルがまさにWord2Vecで手に入れたい単語ベクトルになるんです。
Skip-gram
Skip-gramはCBOWの逆です。
? / ? / ? / ? / ? / 傘 / ? / ? / ? / ? / ?
特定の単語から前後の単語を予測するモデルを構築します。
Skip-gramの方が精度が高いですが、計算負荷が高く処理に時間がかかります。
以下の記事でWord2Vecについて解説しています!

n-gram
自然言語処理の領域で検索システムを作る際によく使われる分解方法としてn-gramというものがあります。
n-gramは文章を特定のまとまりごとにまとめてグループ化するアプローチです。
nには数字が入るようになっており、1-gram(ユニグラム)、2-gram(バイグラム)、3-gram(トリグラム)の3つのパターンがあります。
スタビジは面白いサイトだ
という文章があった時にそれを文字単位で分割すると
・1-gramの場合
ス/タ/ビ/ジ/は/面/白/い/サ/イ/ト/だ
となります。これはシンプルですね。
・2-gramの場合
スタ / タビ / ビジ / ジは / は面 / 面白 / 白い / いサ / サイ / イト / トだ
となります。2個ずつの文字が1つの塊になり、それぞれが1個ずつズレていることが分かります。
・3-gramの場合
では3-gramはどうなるでしょう?
スタビ / タビジ / ビジは / ジは面 / は面白 / 面白い / 白いサ / いサイ / サイト / イトだ
3文字ごとの塊になり1文字ずつズレていることが分かります。
非常にシンプルですね!
3-gramをPythonで実装すると以下のようになります。
text = "スタビジは面白いサイトだ"
n_grams = [text[i:i+3] for i in range(len(text)-2)]
n_grams
非常にシンプルなコードになっているのが分かりますね!
テキストの文字数を最大値として最大値に達するまでfor文で取り出してtextをスライスで塊に分けています。
これで
3-gramの
スタビ / タビジ / ビジは / ジは面 / は面白 / 面白い / 白いサ / いサイ / サイト / イトだ
というリストが取得できます。
n-gramのロジックはシンプルなのですが、実際に検索システムを構築する際は考慮することがたくさんあります。
具体的にどうやってn-gramを使って検索システムを作っていくかについては以下の記事でまとめてますので詳しく知りたい方はチェックしてみてください!

自然言語処理でできることをPythonで実装してみよう まとめ
本記事では、自然言語処理についてまとめました!
自然言語処理は、機械が自然な会話を実現できるようになるために非常に重要な分野。
これからの研究が期待される領域なんですねー!
例えば、複数人で会話をする時に人間であれば複数人の音声が重なっていても切り分けて処理することができますが、現状の機械ではそれは厳しいです。
音声分離の技術はまだまだこれからの研究課題になっています。
もしディープラーニングや機械学習、Pythonに興味があれば以下の記事で勉強法をまとめていますのでぜひチェックしてみてください!




自然言語処理を使ったアプリについて興味がある方は、以下の記事でチャットボットの作り方を解説しているので、チェックしてみて下さい。

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!