
【Pythonで実装】BERTの使い方を解説!日本語モデルを使って予測をしてみようー!


こんにちは!
デジタルマーケターやらデータサイエンティストみたいなことを事業会社でやったのち、独立して事業展開しているウマたん(@statistics1012)です!
データサイエンティストとしてもブロガーとしても気になるBERT!

より文脈をAIが理解できるようになったBERTというロジックにデータサイエンス的な観点とSEO的な観点で踏み込んでいきたいと思います。
AIとSEOについてあまり分からないなーという方は以下の記事を参考にしながら読み進めてください。


より詳しくデータサイエンスやSEOついて知りたい方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の講座をチェックしてみてください。
目次
BERTとは?

BERTとは「Bidirectional Encoder Representations from Transformers」の略であり、Googleが新たに開発した自然言語処理のロジックになります。
Googleは2018年10月11日に論文を公開し、Google検索のアルゴリズムに2019年10月25日に適応しました。
そして日本語のGoogleへのアップデート適応は2019年12月となっています。
BERTの登場によりGoogleはより長く複雑な文章を理解できるようになり、文脈を読み取ることができるようになりました。
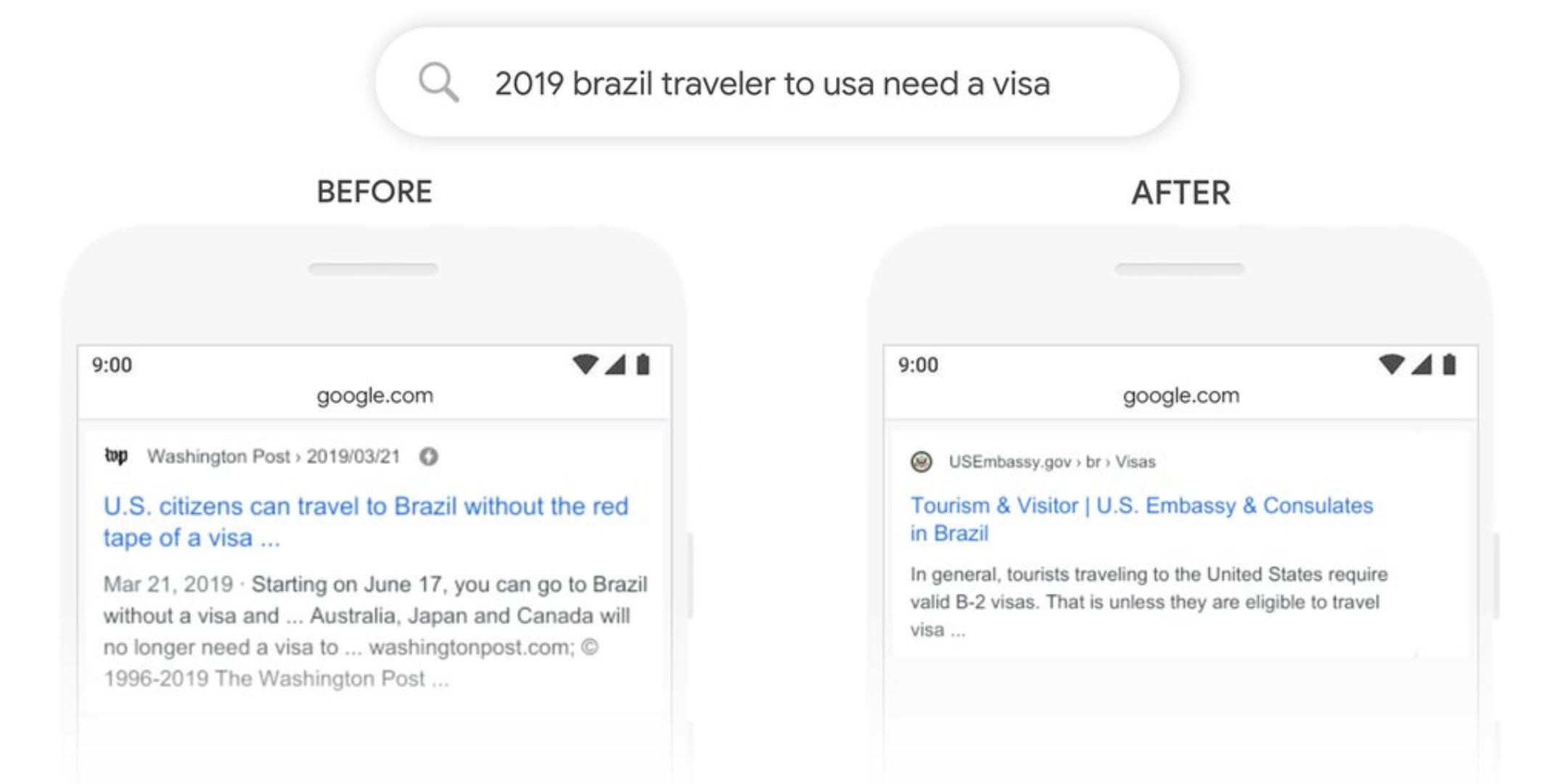
実際にGoogleのリリースにBERT導入前と導入後のGoogle検索の違いが記載されています。
 (引用元:Google-”Understanding searches better than ever before”)
(引用元:Google-”Understanding searches better than ever before”)
ブラジル人が米国へ渡航する際のビザの有無を知りたいのですが、BERT実装前は英文における“to”の意味を明確に捉えることができずアメリカ人がブラジルへ旅行する場合の結果を返していました(左側)。
BERT実装後は、しっかりアメリカ渡航の際の結果を返すことができています。
このように検索結果が、より検索者の検索意図を読み取れるように進化してきているのです。
BERTのアルゴリズム

そんなBERTはどのようなアルゴリズムなのでしょうか?
2018年10月にGoogleからリリースされた論文にはこのように記載されています。
BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks
(引用元:Google-“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”)
BERTはシンプルでありながら非常に強力で一般的な11つの言語処理指標において優位な結果を収めたと・・
実はBERTは事前学習モデルであり他の既存モデルと組み合わせることで効果を発揮するものなんです。
BERTとは「Bidirectional Encoder Representations from Transformers」。
以下のように一般的に文脈から予測する場合、それより前の文字列から予測する一方向的な学習しかできませんでした。
$$ p(x_n|x_1,x_2,…,x_{n-1}) $$
しかしこのBERTは、双方向から文脈を学習できるようになったのです。
BERTがSEOに与える影響

先ほどの検索結果の例でも挙げましたが、BERT導入によりGoogleは検索意図を明確に読み取れるように進化しました。
これは、Googleが「Rank Brain」を導入した2015年以来の大きな進化と言えるでしょう!
別の例を見てみましょう!
 (引用元:Google-”Understanding searches better than ever before”)
(引用元:Google-”Understanding searches better than ever before”)
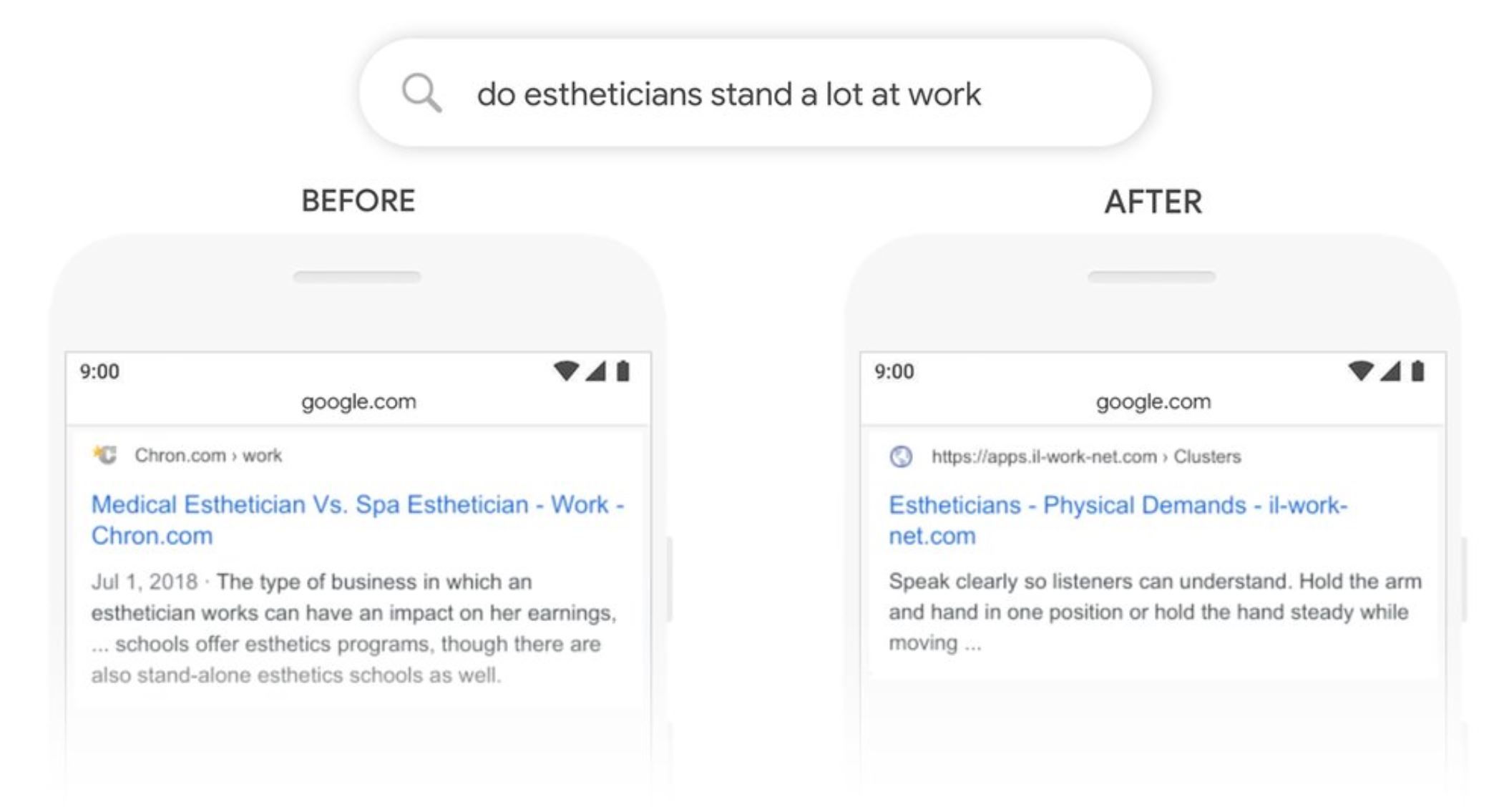
こちらの例では、”Stand”という単語の意味が焦点になっています。
BERT実装前は、エステティシャンという職業の立ち位置的な受け取り方をGoogleはしており、結果的に医療エステティシャンとスパエステティシャンはどっちが良いか的な記事を返しています。
しかし、検索者が知りたいのはエステティシャンの物理的な立ちについて。立ち時間や労働環境について知りたいんです。
BERT後はしっかりエステティシャンの物理的な労働環境について返しています。
英語でもそうですが、日本語においても同じ単語が別の文脈では別の意味で使われることは多いです。
そのような状況でもBERTは文脈から適切に検索意図を読み取ることができるようになっているのです。
日本語BERTをPythonで実装してみる

それでは、そんなBERTを実際に実装してみましょう!
BERTを使って以下の日本語文章の空白を予測してみます。
※昔はスタビジは統計ラボというサイト名でした
[‘統計’, ‘ラボ’, ‘は’, ‘*’, ‘を’, ‘発信’, ‘する’, ‘サイト’, ‘です’]
また、実装にはGoogle colaboratoryを使います。
Google colaboratoryはGPUを使用できる強力なクラウドサービス!以下の記事で詳しくまとめているので参考にしてみてください!
また、今回のBERTをGoogle colaboratoryで実装する上で以下の2つの記事を参考にさせていただきました。非常に有用ですのであわせて読んでみてください。
さて、BERTを本格的に日本語に適応して実装するには、そこそこ事前準備が必要なので整理しておきましょう!
・形態素解析のためのJUMAN++インストール
・BERT日本語Pretrainedモデルのダウンロード
・各種必要なライブラリをインストール
JUMAN++とBERT日本語Pretrainedモデルは京都大学の黒橋・河原・村脇研究室からインストールしていきます!
自然言語処理に有用な様々なフレームワークを展開してくれています。
ありがたい!順に見ていきましょう!
形態素解析のためのJUMAN++インストール
京都大学の黒橋・河原・村脇研究室の作成した強力な形態素解析器JUMAN++をインストールしていきます。
こちらは、定番のMeCabよりも口語に対応している形態素解析です。
Google colaboratory上で以下のように記述しインストールを進めます。
!wget https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc2/jumanpp-2.0.0-rc2.tar.xz &&
tar xJvf jumanpp-2.0.0-rc2.tar.xz &&
rm jumanpp-2.0.0-rc2.tar.xz &&
cd jumanpp-2.0.0-rc2/ &&
mkdir bld &&
cd bld &&
cmake ..
-DCMAKE_BUILD_TYPE=Release
-DCMAKE_INSTALL_PREFIX=/usr/local &&
make &&
sudo make install※10分ほど時間がかかります。
BERT日本語Pretrainedモデルのダウンロード
まず、BERTを実装するためには日本語における相当な量の事前学習が必要なのですが京都大学の黒橋・河原・村脇研究室が公開してくれています。
非常にありがたいですね!
まずは、Google colaboratory上でGoogle driveをマウントしていきます。
from google.colab import drive
drive.mount('/content/drive')これによりGoogle drive上と同期をとるコトが可能です。
結果のURLからパスを入手してGoogle colaboratory上で記述しましょう!
続いて、Google drive上に日本語モデルを格納するフォルダを作成します。
!mkdir -p /content/drive/'My Drive'/bert/japan_test作成したディレクトリに移動します。
cd /content/drive/'My Drive'/bert/japan_test移動したら、早速黒橋・河原・村脇研究室で公開しているモデルをダウンロードしていきましょう!
import urllib.request
kyoto_u_bert_url = "http://nlp.ist.i.kyoto-u.ac.jp/nl-resource/JapaneseBertPretrainedModel/Japanese_L-12_H-768_A-12_E-30_BPE.zip"
urllib.request.urlretrieve(kyoto_u_bert_url, "Japanese_L-12_H-768_A-12_E-30_BPE.zip")続いてZIPファイルを解凍していきます。
!unzip Japanese_L-12_H-768_A-12_E-30_BPE.zipこれで、日本語モデルの準備は完了です。
各種必要なライブラリをインストール
最後に必要なライブラリをpipインストールしていきます。
!pip install transformers
!pip install pyknpPython上のインポートを行います。
import torch
from transformers import BertTokenizer, BertForMaskedLM, BertConfig
import numpy as np
from pyknp import Juman
jumanpp = Juman()pyknpは黒橋・河原・村脇研究室が提供する、JumanとKNPのバインディングフレームワークです。
transformersは色々と使用用途があるみたいですが、今回はBERTのモデルやパラメータ取得、インプットデータの加工などに使います。
これで準備が整いました。本実装していきます。
BERT本実装
config = BertConfig.from_json_file('/content/drive/My Drive/bert/japan_test/Japanese_L-12_H-768_A-12_E-30_BPE/bert_config.json')
model = BertForMaskedLM.from_pretrained('/content/drive/My Drive/bert/japan_test/Japanese_L-12_H-768_A-12_E-30_BPE/pytorch_model.bin', config=config)
bert_tokenizer = BertTokenizer('/content/drive/My Drive/bert/japan_test/Japanese_L-12_H-768_A-12_E-30_BPE/vocab.txt',
do_lower_case=False, do_basic_tokenize=False)必要なパラメータやモデル、BERTが扱いやすい形に加工するための変換処理などを先ほどダウンロードした日本語Pretrainedモデルから取得します。
text = "スタビジは*を発信するサイトです"
result = jumanpp.analysis(text)
tokenized_text = [mrph.midasi for mrph in result.mrph_list()]
print(tokenized_text)続いて、JUMAN++によって品詞分解を行います。
[‘統計’, ‘ラボ’, ‘は’, ‘*’, ‘を’, ‘発信’, ‘する’, ‘サイト’, ‘です’]
tokenized_text.insert(0, '[CLS]')
tokenized_text.append('[SEP]')
masked_index = 4
tokenized_text[masked_index] = '[MASK]'
print(tokenized_text)文章の区切れやマスクする部分をBERTに明示的に知らせるために、SEPやMASKを挿入していきます。
CLSは文章の頭に、SEPは文章の区切れに、MASKは隠したい部分に適用します。
[‘[CLS]’, ‘統計’, ‘ラボ’, ‘は’, ‘[MASK]’, ‘を’, ‘発信’, ‘する’, ‘サイト’, ‘です’, ‘[SEP]’]
tokens = bert_tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([tokens])そして、得られたテキストをBERT用に変換します。
model.eval()
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
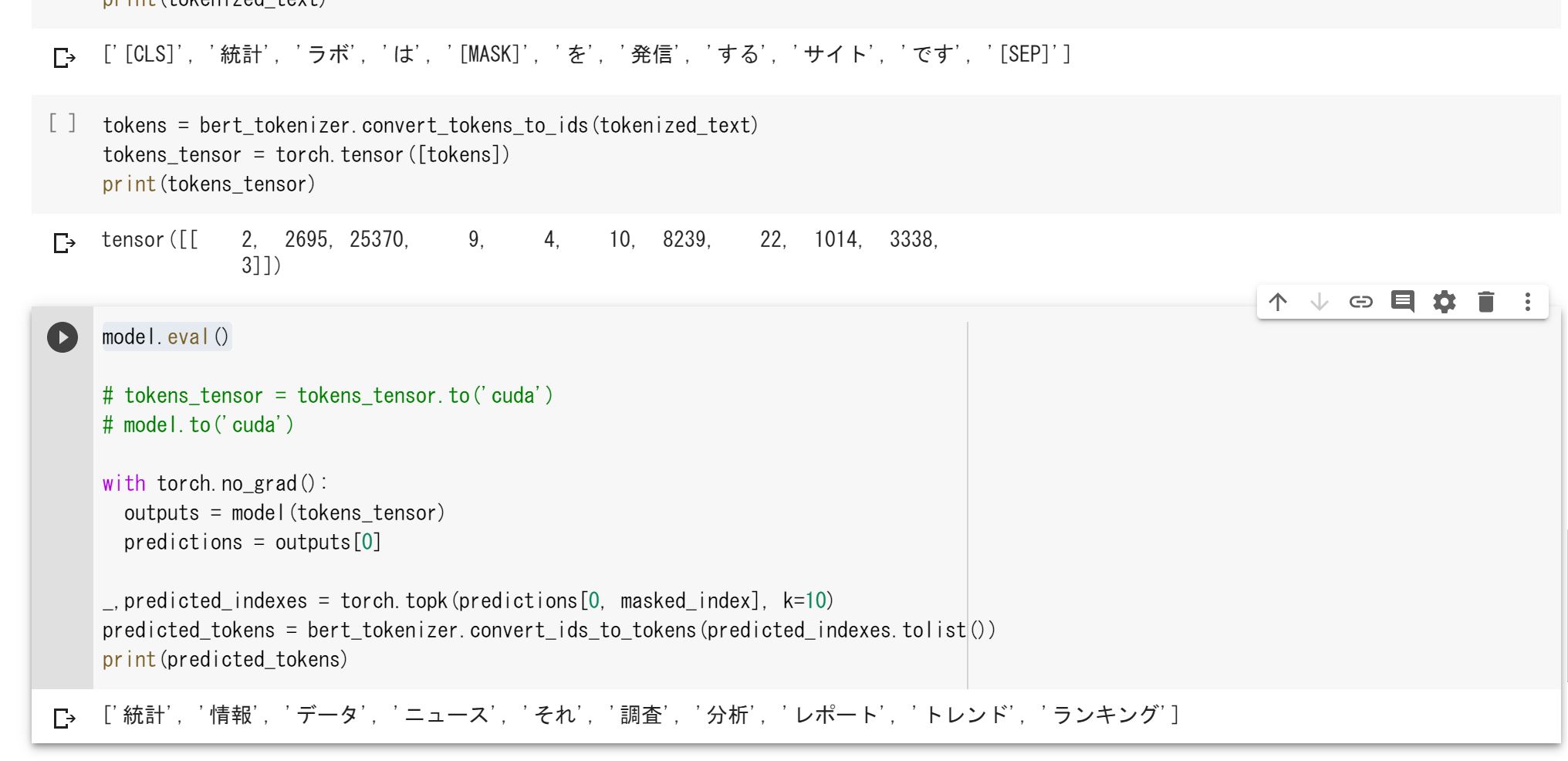
_,predicted_indexes = torch.topk(predictions[0, masked_index], k=10)
predicted_tokens = bert_tokenizer.convert_ids_to_tokens(predicted_indexes.tolist())
print(predicted_tokens)そして、マスクされた部分の予測を行います。
結果は・・・
[‘統計’, ‘情報’, ‘データ’, ‘ニュース’, ‘それ’, ‘調査’, ‘分析’, ‘レポート’, ‘トレンド’, ‘ランキング’]
上手く予測できていることが分かります!
マスク部分を前に持ってきても上手く予測できました!
[‘*’, ‘を’, ‘発信’, ‘する’, ‘サイト’, ‘が’, ‘統計’, ‘ラボ’, ‘です’]
[‘統計’, ‘データ’, ‘情報’, ‘それ’, ‘これ’, ‘結果’, ‘ニュース’, ‘調査’, ‘ランキング’, ‘トレンド’]
BERT まとめ

ここまでご覧いただきありがとうございました!
本記事では、BERTについてSEO観点と機械学習観点から見てきました!
それぞれの観点からBERTについて簡単にまとめてみましょう!
今後GoogleはBERTにとどまらず、さらなる精度のアップデートを行うでしょう!
日々めまぐるしい進化が起こる業界ではありますが、自分のペースで徐々にキャッチアップしていきましょう!
ディープラーニング系、その他のAI用語を一挙にまとめた以下の記事も合わせて要チェックです!

ちなみに自然言語処理については以下の記事でまとめているのであわせてチェックしてみてください!

データサイエンスやPythonやAI全般については以下の記事を参考にしてみてください。


当メディアではデータサイエンティストになるための分野を体系的に学ぶスクール「スタアカ」を運営しております!
データサイエンスについて幅広く知りたい方は是非チェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解などもあわせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















