
Pythonで文書類似度算出!MeCabで形態素解析後にTf-idfとCos類似度を使ってみよう


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!

一見難しそうなこれらの実装ですが、Pythonを使って比較的簡単に実装できちゃうんです!
MeCabという形態素解析エンジンを用いて形態素解析を行い、その後Tf-idfという指標を使って単語をベクトル化し、Cos類似度を使って単語ベクトルの類似度を測ります!
是非この記事の内容を理解して簡単な自然言語処理についてマスターしましょうー!
以下のYoutube動画でも解説していますのでチェックしてみてください!
目次
形態素解析エンジンMeCabとは

自然言語処理とは、端的に言うと「人間の言葉を機械が理解するルール作り」です。
機械が人間の言葉をしっかり理解するためには、まずは単語理解が必要。
そして単語理解には、文章がどのような単語そしてどのような品詞で成り立っているかを分解する必要があります。
そんな時に使われるのが形態素解析エンジンなのです。
形態素解析とは、文章を単語単位で区切りそれぞれの単語に情報を付与する手法です。
形態素解析エンジンにはいくつかの種類がありますが、最も有名なものがMecab。
Mecabは古くから有名で、最も良く使われている形態素解析エンジンです。
PythonでもRでもMeCabを動かすことが可能ですが、今回はPythonで実装していきますよー!

Tf-idfとCos類似度とは
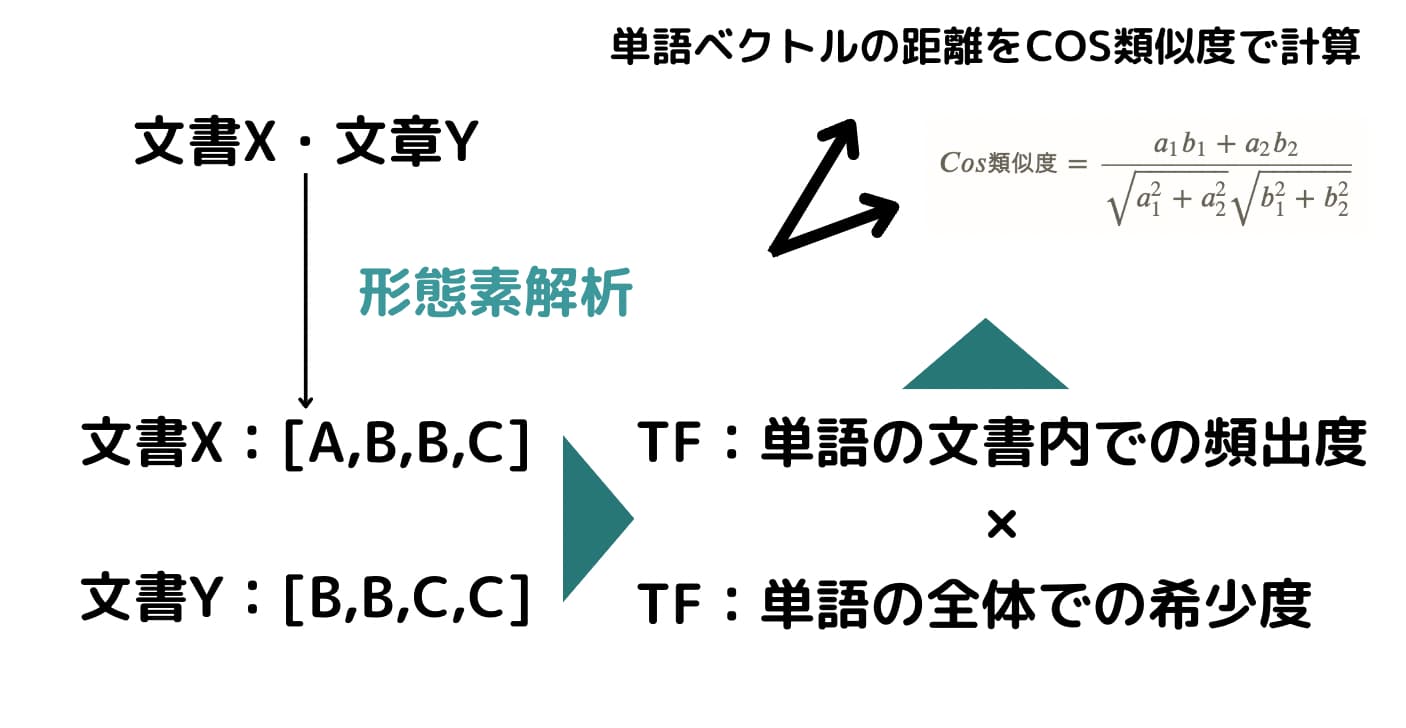
続いて、形態素解析後のデータを扱う上で重要なTf-idfとCos類似度について見ていきます!
tf-idfは(Term Frequency Inverse Document Frequency)の略であり、端的に言うとある文書における単語の特徴を表した指標です。
TF
TFはその文書内での単語の頻出度を表しており、IDFはその単語が全ての文書の中でどれくらいの文書で登場するか、すなわち単語の希少度を表しています。
簡単な例でTf-idfを見ていきましょう!
例えば、以下のような状況では、
[A,B,B,C]
[B,B,C,C]
TFはこのようになります。
[A,B,B,C]→[A:1/4=0.25, B:2/4=0.5, C:1/4=0.25]
[B,B,C,C]→[B:2/4=0.5, C:2/4=0.5]
ただTFだけではそのテキスト内の特徴的な単語を抽出できているとは限りません。
そのテキストの中で頻出だったとしても他のテキストにも同じように多く頻出している単語は特徴的な単語とは言えませんよね?
例えば、「私」という1人称はどんな文章にも等しく多く頻出する可能性が高いですが、それはその文章の特徴を表しているとは言えません。
このようなどんな文章にも頻出する単語の特徴度を落とすためにIDFを計算する必要があります。
IDF
IDFはこのような式で表されます。
$$ IDF = log(全文書数/その単語が登場する文書数) $$
()の中身が大きいすなわちその単語が他の文書であまり使われていない時にIDFの値が大きくなることが分かると思います。
ちなみにlogを取っているので()の中身が1になるすなわち全ての文書に登場する単語のIDFは0になります。
ここではIDFを仮の値として設定しましょう!
AのIDFが4, BのIDFが1、CのIDFが2だとしましょう。
すると先程の例でTf-idfを計算すると・・・
[A,B,B,C]→[A:0.25×4=1, B:0.5×1=0.5, C:0.25×2=0.5]
[B,B,C,C]→[B:0.5×1=0.5, C:0.5×2=1]
となります。
他の文書にはなかなか登場しないけどその文書には多く登場する単語ほどTf-idf値が高くなり、その文書を特徴づける単語であるとなるわけですねー!
Cos類似度
さて、続いてこれらのデータを基にCos類似度を算出してみましょう!
Cos類似度は簡単に言うと、それぞれのベクトルがどれくらい同じ方向を向いているかを表したもの。
単語ベクトルにCos類似度を当てはめることで文書の類似度を算出することが出来るのです!
\(A=[a_1, a_2]\)、\(B=[b_1, b_2]\)の時、Cos類似度は以下のような式で求めます!
$$ Cos類似度 = \frac{a_1b_1+a_2b_2}{\sqrt{a_1^2+a_2^2}\sqrt{b_1^2+b_2^2}} $$
これは、高校数学で習うCosとベクトルの関係式そのままです。
先ほどの単語ベクトル
[A,B,B,C]→[A:1, B:0.5, C:0.5]
[B,B,C,C]→[B:0.5, C:1]
を当てはめて見ると計算してみると、0.5477となりました。
Pythonであれば以下のように計算できますし、
import math
0.75/(math.sqrt(1.5)*math.sqrt(1.25))
25.5/(math.sqrt(26.5)*math.sqrt(26))
関数を作って以下のように計算してもよしです。
import numpy as np
def cos_sim(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
v1 = [1, 0.5, 0.5]
v2 = [0, 0.5, 1]
cos_sim(v1, v2)さて、それではidfが変わるとどうなるのでしょうか?
ここでBが希少度の高い単語だと仮定してidfを10にしてみましょう!
そうすると単語ベクトルはこのようになり・・・
「A,B,B,C」→「A:0.25×4=1, B:0.5×10=5, C:0.25×2=0.5」
「B,B,C,C」→「B:0.5×10=5, C:0.5×2=1」
Cos類似度は0.976になりました!
v1 = [1, 5, 0.5]
v2 = [0, 5, 1]
cos_sim(v1, v2)Tf-idfの値によってCos類似度すなわち文書の類似度が変化することが確認することができましたねー!
tf-idfとCos類似度は非常に重要な考え方なので是非理解しておいてください!
PythonとMeCabとTf-idf/Cos類似度を使ってテキストの文書類似度を算出!

MeCabやTf-idfやCos類似度の概要について理解したところで、実際に手を動かして実装していきましょう!
Step1:URLからテキスト情報をスクレイピング
Step2:それらをMeCabで形態素解析。名詞だけ抽出
Step3:名詞の出現頻度からTF-IDF/COS類似度を算出。テキスト情報のマッチ度を測る
テキスト情報はベタ打ちでもいいのですが、せっかくだからネット上のテキストデータをスクレイピングによって抽出できるように設定します。
Pythonでスクレイピングを行う方法に関しては以下の記事をご覧ください!

Step0: MeCabを使う前準備
それでは、早速MeCabを使う環境を整えていきましょう!
MeCabを使う場合はGoogle colaboratoryを使うのがオススメです。
Google colaboratoryであれば、以下のように記述してあげることでMecabを利用することができます。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7Google ColaboratoryとはGoogleが無料で提供してくれているクラウド実行型のJupyter notebook実行環境です。
Googleのアカウントを持ってさえいれば誰でも使用することができ、開発環境を整える必要もなくPythonによる機械学習実装が可能です。
ローカルの開発環境でMeCabを動かす場合は少々面倒です。
以下のURLから「mecab-0.996-64.exe」をダウンロードしてください。
https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
ダウンロードした後は、PythonでMeCabが使えるようにバインディングしていきます。
以下の記事で詳しくまとめられているので参考にしてみてください。
MeCabを使う準備が整いました。
実装していきましょう!
Step1:URLからテキスト情報をスクレイピング
関数のgeturlを定義することで、Pythonの「BeautifulSoup」「requests」というライブラリからpタグに囲まれたテキスト情報を抽出します。
def geturl(urls):
all_text=[]
for url in urls:
r=requests.get(url)
c=r.content
soup=BeautifulSoup(c,"html.parser")
article1_content=soup.find_all("p")
temp=[]
for con in article1_content:
out=con.text
temp.append(out)
text=''.join(temp)
all_text.append(text)
sleep(1)
return all_text先ほども紹介しましたが、詳しくは以下の記事にまとめているのでご覧ください!
Step2:それらをMeCabで形態素解析。名詞だけ抽出
以下の部分でMeCabが文章を形態素分解してくれます。
import MeCab
text = "テキストを入れる"
m=MeCab.Tagger()
m1=m.parse (text)試しにこのtext部分に
”統計ラボはデータサイエンスとWebマーケティングをまとめたサイトです”
と入れてみます。
※スタビジの旧サイト名は統計ラボでした
そうすると以下のような結果が返ってきます。素晴らしい!
統計 名詞,サ変接続,*,*,*,*,統計,トウケイ,トーケイ ラボ 名詞,一般,*,*,*,*,ラボ,ラボ,ラボ は 助詞,係助詞,*,*,*,*,は,ハ,ワ データ 名詞,一般,*,*,*,*,データ,データ,データ サイエンス 名詞,一般,*,*,*,*,サイエンス,サイエンス,サイエンス と 助詞,並立助詞,*,*,*,*,と,ト,ト Web 名詞,固有名詞,組織,*,*,*,* マーケティング 名詞,一般,*,*,*,*,マーケティング,マーケティング,マーケティング を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ まとめ 動詞,自立,*,*,一段,連用形,まとめる,マトメ,マトメ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ サイト 名詞,一般,*,*,*,*,サイト,サイト,サイト です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス EOS
返ってきた結果に対して名詞だけ取り出したいため、.splitを使い2つ目の要素が名詞だったら配列に格納するような処理を行っています。
word_list = []
for row in m1.split("\n"):
word =row.split("\t")[0]#タブ区切りになっている1つ目を取り出す。ここには形態素が格納されている
if word == "EOS":
break
else:
pos = row.split("\t")[1]#タブ区切りになっている2つ目を取り出す。ここには品詞が格納されている
slice = pos[:2]
if slice == "名詞":
word_list.append(word)
print(word_list)これによりテキスト情報を単語に分解し、名詞だけ格納した配列が出来上がりました。
Step3:名詞の出現頻度からTF-IDF/COS類似度を算出。テキスト情報のマッチ度を測る
続いてTF-IDFとCOS類似度を用いて、文書の類似度を算出していきます。
TfidfVectorizerを用いて文書における単語のスコアを数値化していきます。
def tfidf(word_list):
docs = np.array(word_list)#Numpyの配列に変換する
#単語を配列ベクトル化して、TF-IDFを計算する
vecs = TfidfVectorizer(
token_pattern=u'(?u)bw+b'#文字列長が 1 の単語を処理対象に含めることを意味します。
).fit_transform(docs)
vecs = vecs.toarray()
return vecs
TF-IDFは文書における単語の特徴を他の文書と比較して算出する指標であり、特徴的な単語の数値が高くなります。
token_pattern=u'(?u)bw+b’では、1文字の単語も単語として処理するように設定しています。
COS類似度では、2つのベクトルの内積をそれぞれのL2ノルムで割る計算を行っています。
def cossim(v1,v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))これで完了です!
以下が全コードになります。
MeCab×Light gbmで文章の著者を予測してみる
続いて、Pythonを使ってMeCabで形態素解析したデータに対してLight gbmという強力な機械学習手法を使って文章の著者なのかを予測してみたいと思います。
先程は文章類似度を算出しましたが、続いては文章の著者の予測です!!
データは、![]() Nishikaというデータコンペの「AIは芥川龍之介を見分けられるのか?」というコンペのデータを使います。
Nishikaというデータコンペの「AIは芥川龍之介を見分けられるのか?」というコンペのデータを使います。
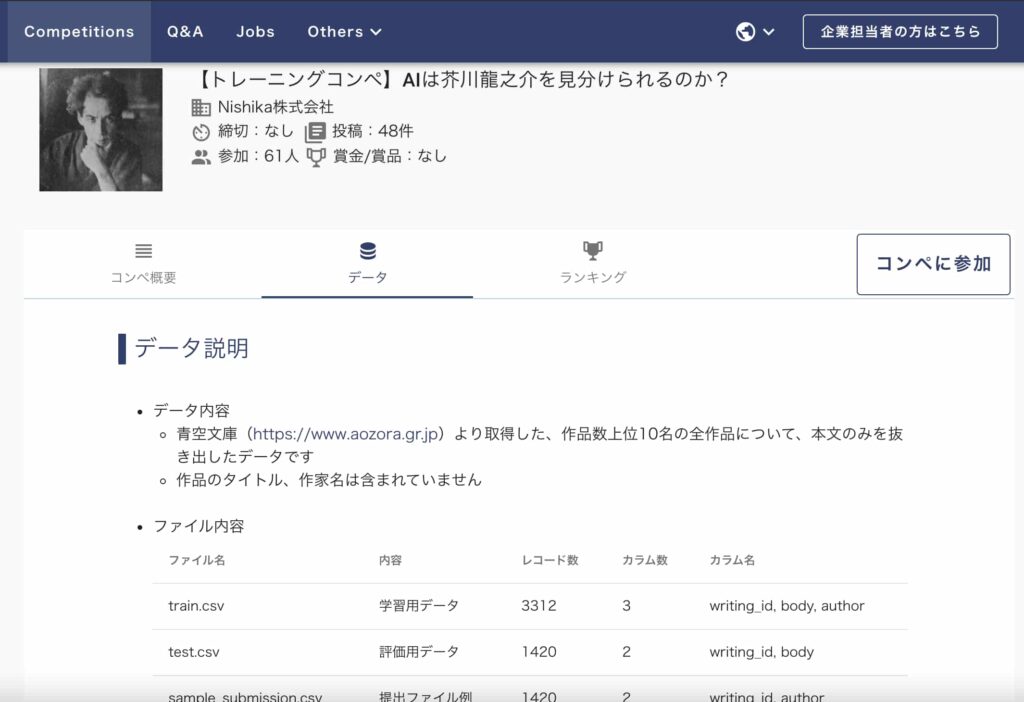
![]() Nishikaに会員登録をしてtrainデータをローカル環境にダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
Nishikaに会員登録をしてtrainデータをローカル環境にダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
データは、3,312個の文章とそれぞれに対して芥川龍之介が否かがラベルで付いているデータになっています。
こちらもMeCabを利用するのでGoogle colaboratory上で実装していきます。
以下のように記述してあげることでMecabが使えるようになります。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7まずは必要なライブラリをインストールします。
import pandas as pd
import numpy as np
import collections
import MeCab
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score続いて必要なデータをデータフレームとして読み込みます。
df = pd.read_csv("/content/drive/MyDrive/Stabiz/python/data-science/nishika_text_data/train.csv")
続いてMeCabにより形態素解析を行い各文章ごとの単語を集計していきます。
m = MeCab.Tagger("")
text_list = []
length_list = []
# それぞれの文書を取り出して形態素解析
for sentence in df["body"]:
ma = m.parse(sentence)
word_list = []
# 形態解析後の単語だけ抽出
for text in ma.split("\n"):
word_list.append(text.split("\t")[0])
# 単語の数を集計
length_list.append(len(word_list))
# 単語の頻度を集計
data = collections.Counter(word_list)
text_data = pd.DataFrame.from_dict(data, orient='index')
text_list.append(text_data)そして3312個の全文章の中で登場する単語の上位100個の頻出単語だけ特徴量とします。
feature = pd.concat(text_list, axis=1)
#Nanを0に置換
feature = feature.fillna(0)
#Arrayに変換
feature_temp = feature.values.sum(axis=1)
#上位k件
K = 100
#上位k件のインデックス
indices = np.argpartition(-feature_temp, K)[:K]
文章ごとに長さが違うので、長さのバイアスを取り除くために各特徴量を各文章の全単語数で割返して特徴量とします。
## 各文書に対して全体で頻出の上位k個の単語の出現数をその文書の単語出現数で割ったものを変数とする ##
modi_feature = []
for index, row in feature.iloc[indices].T.reset_index(drop=True).iterrows():
modi_feature_temp = row/length_list[index]
modi_feature.append(modi_feature_temp)
modi_feature = pd.concat(modi_feature, axis=1).T
# 各文書と作成した特徴量を結合
df = pd.concat([df, modi_feature], axis=1)その上でやっとLight gbmの実装をしていきます!
## Light gbmと実装
df = df.drop(["writing_id", "body"], axis=1)
df_train, df_val = train_test_split(df, test_size=0.2)
col = "author"
train_y = df_train[col]
train_x = df_train.drop(col, axis=1)
val_y = df_val[col]
val_x = df_val.drop(col, axis=1)
trains = lgb.Dataset(train_x.values, train_y)
valids = lgb.Dataset(val_x.values, val_y)
params = {
"objective": "binary",
"metrics": "binary_logloss"
}
model = lgb.train(params, trains, valid_sets=valids, num_boost_round=1000, early_stopping_rounds=100)
最後に得られたモデルから予測値を算出し、その値に対してF-measureを算出しています。
## 予測:量的変数で返ってきているので0.5を閾値にして0,1に振り分ける
predict_list = []
for i in model.predict(val_x):
if i > 0.5:
predict = 1
else:
predict = 0
predict_list.append(predict)
f1_score(val_y, predict_list)この時予測値は連続値で返ってくるので、0.5を閾値にして0,1に振り分けています。
F-measureは分類問題でよく使われる指標で適合率と再現率の調和平均を取っています。

結果的にF-measureの値は・・・0.851となりました!
以下が全コードになっています。
関数化していないので少し処理がわかりにくいですがご容赦を・・・
今回利用したLight gbm については以下の記事で詳しく解説しています!
PythonのMeCabで形態素解析 まとめ

Pythonを用いてスクレイピングを行い、MeCabにより形態素解析そして最後にTF-IDFとCOS類似度を使って文書の類似度を算出してみました。
スクレイピング・MeCabが利用できると様々な分野に応用が効きそうですね!
ちなみに当メディアが運営する学習プラットフォーム「スタアカ」の自然言語処理コースで自然言語処理について詳しく学べますので興味のある方はチェックしてみてください!

Pythonはデータ解析やスクレイピングそしてWebアプリケーション作成まで出来る幅広いプログラミング言語!
スクレイピングとWebアプリケーション開発に関しては以下の記事でまとめています!
また自然言語処理についてもっと詳しく知りたい方はぜひ以下の記事をチェックしてみてください!

以下の記事で初心者がPythonを習得する方法についてまとめていますのでよければご覧ください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















