
【コード付き】Selenium×Pythonの使い方!Chromeブラウザを自動操作してみようー!


こんにちは!
消費財メーカーでデジタルマーケター・データサイエンティストを経験後、現在は独立して働いているウマたん(@statistics1012)です!
Pythonを使うと非常に色々なことが出来ちゃいます。
その中でもSeleniumを使ったブラウザの自動化は非常に便利。
普段なんとなーく惰性でやっているルーティンワークはもしかしたらSeleniumを使えばぜーんぶ自動化できてしまうかもしれません。

ぜひSeleniumの威力を知って色々な場面で使ってみましょう!
Pythonを基礎から学びたい方は当メディアが運営するスタアカの以下のコースを是非チェックしてみてください!
Pythonの操作方法からライブラリの使い方といった基本を動画を通して着実に学べます!
目次
Seleniumとは

Seleniumはブラウザを操作するためのオートメーションツールです。
この記事では、Pythonを用いて実装していきますが、JavaやRubyなど他のプログラミング言語でも実装することが可能。
Seleniumを使うことでWeb上で行う行動を自動化することができます。
検索やクリック、情報の抽出や画面キャプチャを撮って保存することなどが出来てしまうのです。
ぜひSeleniumを使いこなして普段使っている作業を自動化してみましょう!
Selenium×Pythonでいくつか挙動を試してみよう!

それでは、そんなSeleniumについていくつか簡単な実装をおこなっていきたいと思います。
この記事では、先ほど取り上げた4つ
・検索
・クリック
・情報取得
・画面キャプチャ
を自動化してみたいと思います。
前準備(Windowsの場合)
意外とつまづきやすいのが、この前準備。
Seleniumを使ってブラウザを操作するためには専用のドライバーをダウンロードしなくてはいけません。(Windowsの場合)
今回はChromeブラウザを使用するので、Chromeを動かすためのChrome Driverをインストールしていくのですがご自身が使っているChromeのバージョンとダウンロードするChrome Driverのバージョンが一致するようにしましょう!
ここが一致しないと上手く動作しません。
Chrome Driverは以下のページからダウンロードしてください。
自分が使っているChromeブラウザのバージョンはブラウザ右上の3点リーダーメニューから以下のように確認することができます。
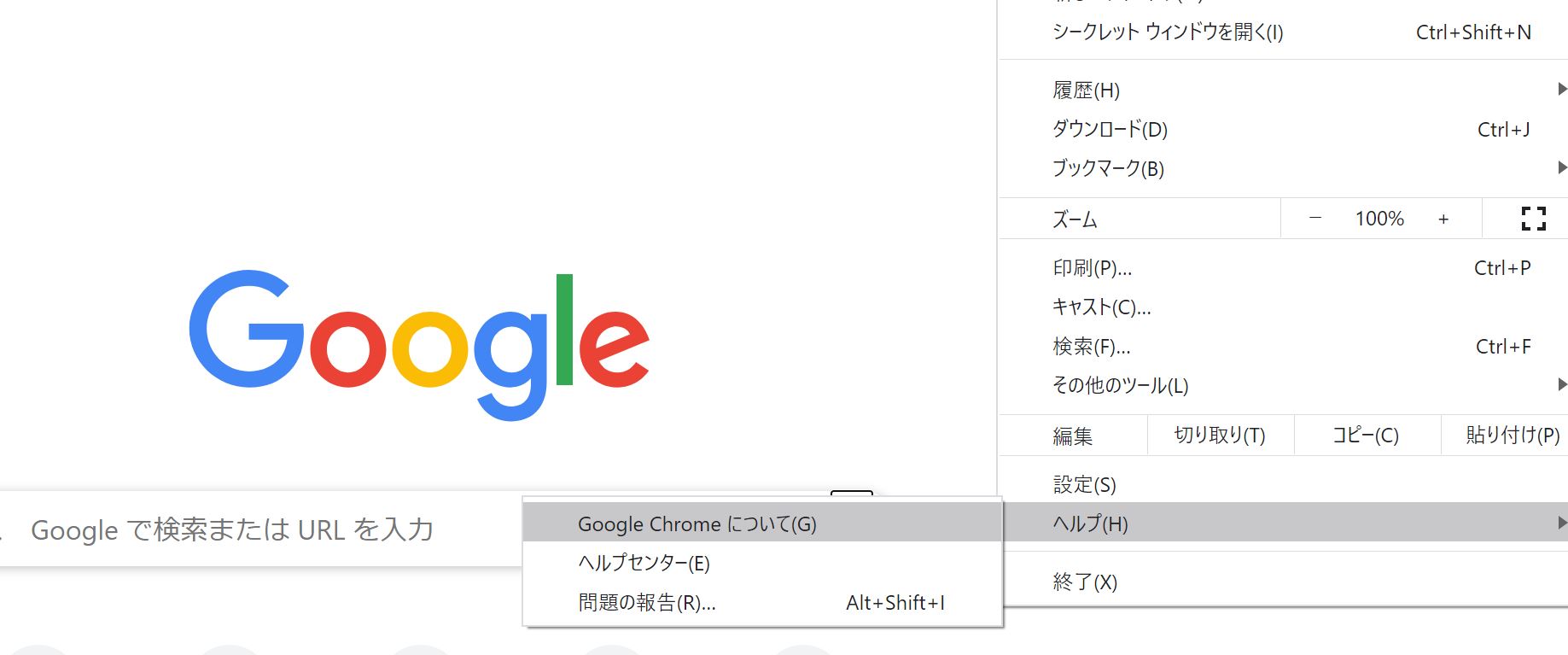
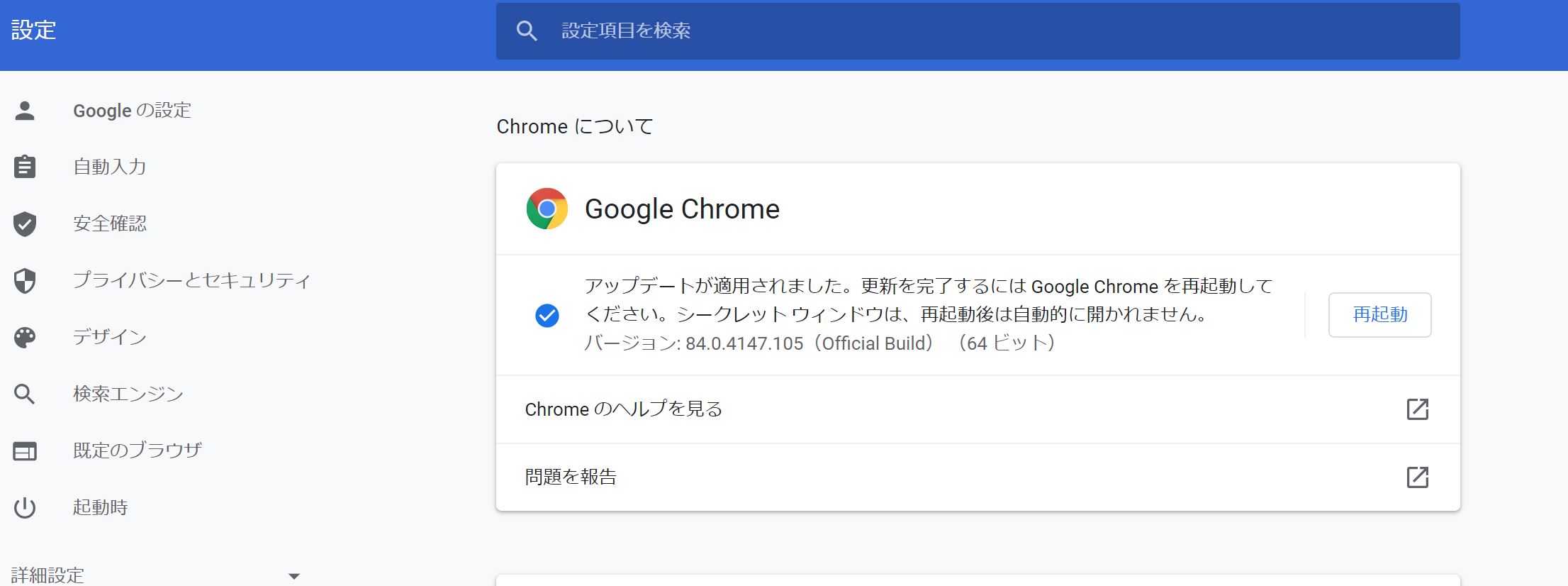
この場合使っているChromeブラウザのバージョンは84なので、Chrome Driverのバージョンも84を選ぶようにしましょう!
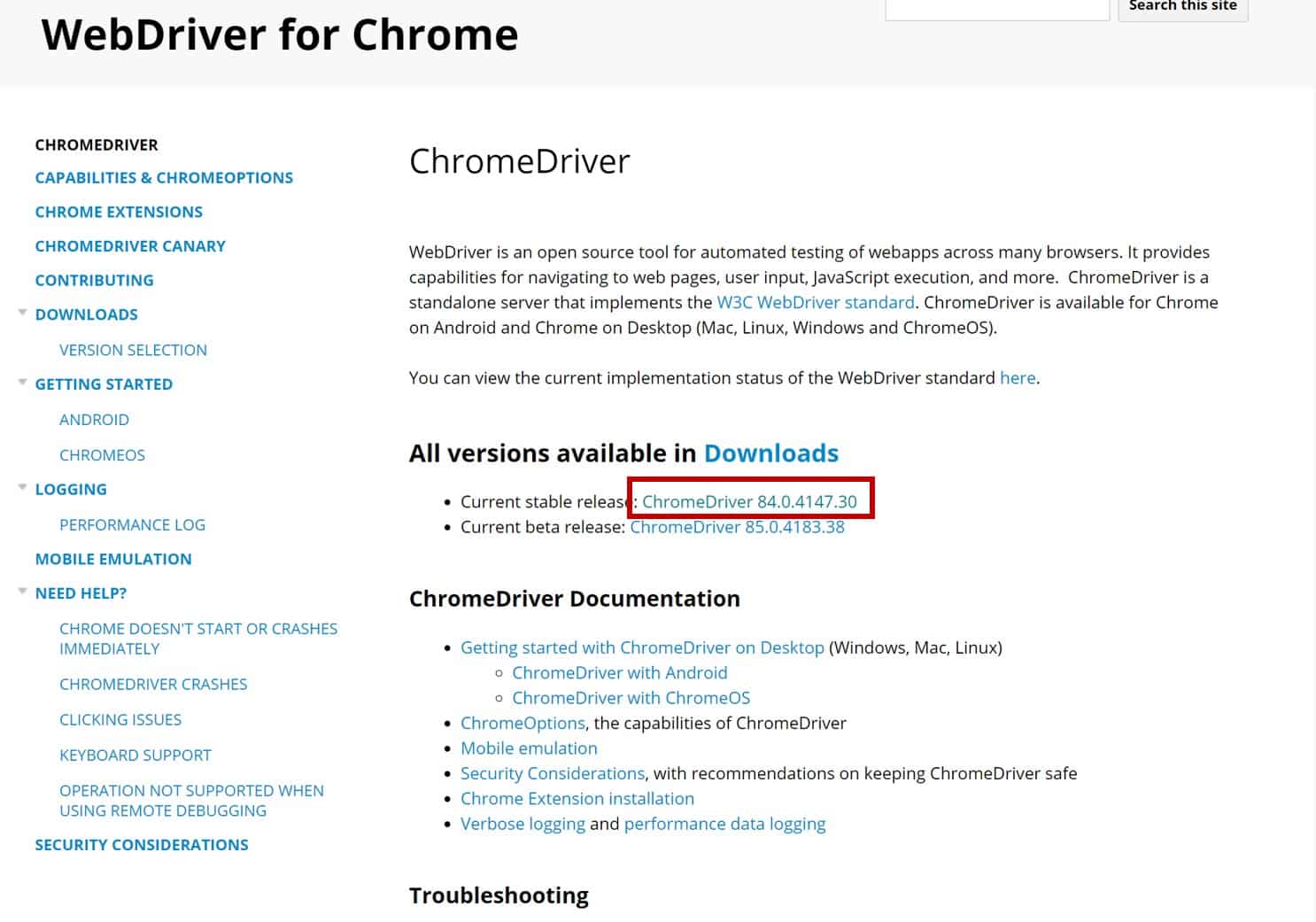
ダウンロードしたChrome Driverは任意のディレクトリフォルダに格納しておきましょう。
以下のコードでChomeブラウザを動かす準備が完了!
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path='Chrome Driverの格納パス')
前準備(Mac)の場合
Macの方が簡易的に実装することが可能です。
Macの場合はChromedriverをインストールせず以下のようにターミナルに打つだけで実装することが可能です。
ターミナルにて
brew cask install chromedriverと入力してください。
既にchromedriverが入っていて再度インストールしたい場合は
brew cask reinstall chromedriverとしましょう。
そして以下のようにしてあげれば問題ないです。
from selenium import webdriver
import time
driver = webdriver.Chrome()Googleで検索をしてみよう!
それでは準備が整ったところでGoogle検索をおこなってみましょう!
以下の公式HPに載っているSample testのコードを実行するとGoogle検索ができますよ!
#Googleのブラウザを開く
driver.get('https://www.google.com/')
time.sleep(2)
#スタビジを検索
search_box = driver.find_element_by_name('q')
search_box.send_keys('スタビジ')
search_box.submit()
time.sleep(2)これで、Googleでスタビジと検索してくれます。
検索結果をクリックしてみよう!
続いて検索結果をクリックしてみましょう!
ここでは、検索結果の1位をクリックしてみましょう!
#検索結果1位をクリック
g = driver.find_elements_by_class_name("g")[0]
r = g.find_element_by_class_name("r")
r.click()find_elements_by_class_name(‘g’)で、クラスが’g’の要素を引っ張ってきています。
引っ張ってきた要素の中の1つ目の要素のさらにrクラスにアクセスしています。
そしてr.click()で実際にクリックアクションを実行することができるんです!
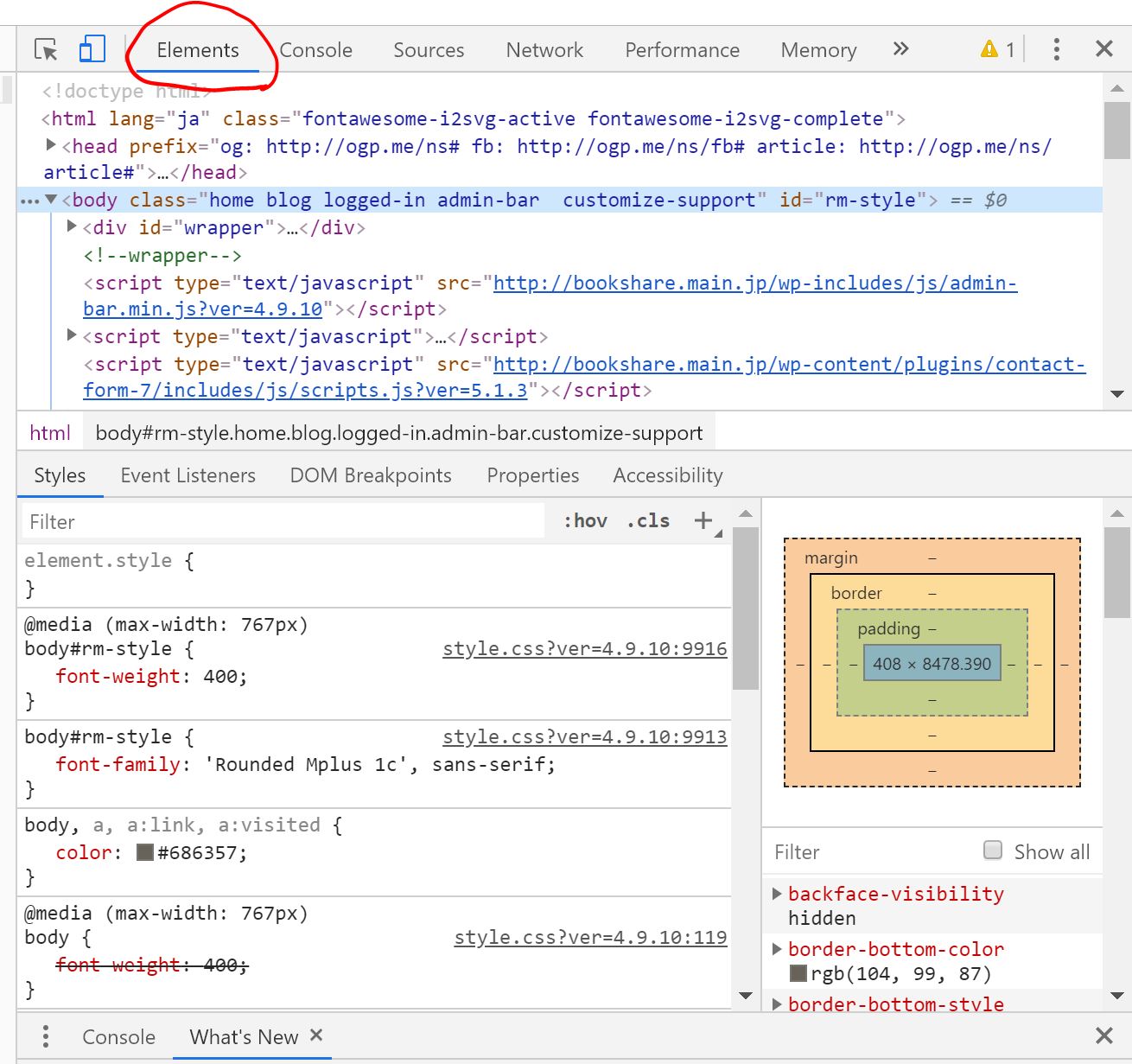
要素を指定する上では、HTMLの要素を把握することが必要です。
Chromeでは、Ctrl+Shift+Iでディベロッパーツールを開くことができ、ディベロッパーツールのElementsから各要素を確認することができます。

Webサイト上の情報を取得してみよう!
続いてサイトの情報を取得してみましょう!
これは先ほどのクリック時におこなった方法で要素を指定して抽出していきます。
Web上の情報を取得する行為はWebスクレイピングと呼ばれ、非常に汎用性が高く色々なところで利用されていますが、サイトやサービスによっては規制されていることも多いので注意しましょう!
#h2の要素を取得
for h2 in driver.find_elements_by_tag_name("h2"):
print(h2.text)ここでは、簡易的にH2のタグ要素を全て取得しました。
新着記事
データサイエンス
Python
おすすめサイト
Webマーケティング
スタビジでは、いくつかのカテゴリをトップページに並べており、それらが取得できましたね!
画面をスクリーンショットでキャプチャしてみよう!
最後に画面をスクリーンショットで保存する方法を紹介しておきます。
#画面キャプチャ
driver.maximize_window()
driver.save_screenshot('スタビジ.png')
#ブラウザを閉じる
driver.quit()driver_maximize_window()で画面を最大化します。
そしてdriver.save_screenshot(‘○○.png’)でpng形式で画像を保存することができます。
この場合は、Pythonファイルと同ディレクトリに保存されますが、保存場所を明示的に示せばそこに保存することができます。
最後に全てのコードを1つにまとめて置いておきます。
Seleniumを勉強する方法

SeleniumはUdemyの以下のコースで非常に優良で分かりやすくまとめていますので是非チェックしてみてください。
Seleniumを動かすところからある程度の実装までであれば、この動画を見れば問題ないです。
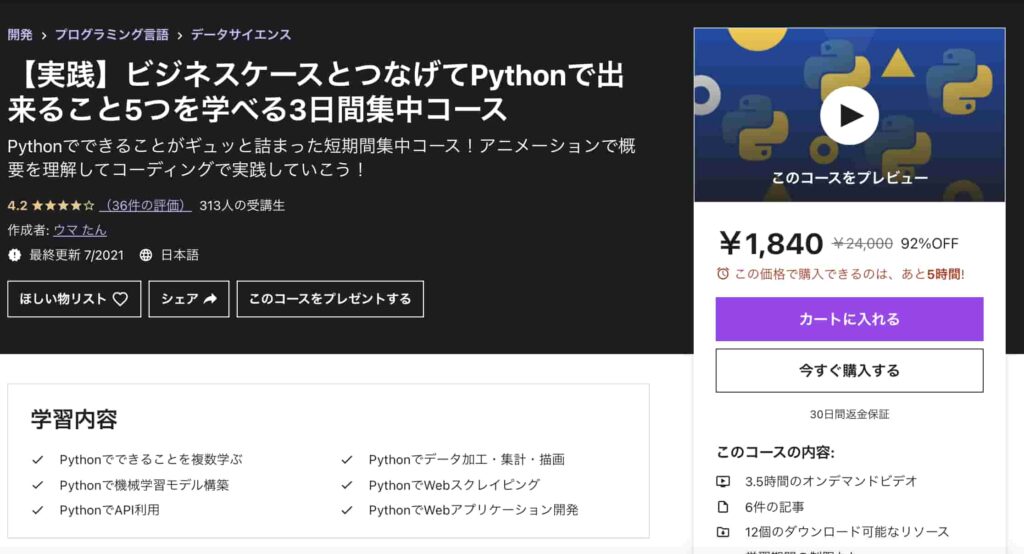
【実践】ビジネスケースとつなげてPythonで出来ること5つを学べる3日間集中コース
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 3.5時間 |
| 【レベル】 | 初級~中級 |
Pythonで出来ることのうち以下の5つを網羅して学んでいきます。
・データ集計・加工・描画
・機械学習を使ったモデル構築
・Webスクレイピング
・APIの利用
・Webアプリケーション開発
データ集計・加工・描画と機械学習モデル構築に関してはKaggleというデータ分析コンペティションのWalmartの小売データを扱いながら学んでいきます。
WebスクレイピングとAPI利用とWebアプリケーション開発に関しては、楽天の在庫情報を取得してSlackに自動で通知するWebアプリケーションを作成して学んでいきます。
Pythonで何ができるのか知りたい!という方には一番はじめにまず受けていただきたいコースです!
Twitterアカウント(@statistics1012)にメンションいただければ1500円になる講師クーポンを発行いたします!
【応用】Selenium×PythonでGoogle検索の検索順位を取得するプログラムを作ってみよう!
Seleniumを勉強する講座を紹介してきましたが、この記事ではおまけとしてSelenium×PythonでGoogle検索の検索順位を取得する方法を見てきます。
普段Google検索をした時に上位の記事から順番に見ていきますよね?
例えば、「化粧水 おすすめ」と調べた時に上位に出てくる記事はなんでしょう?
このタイミングで調べてみると以下のようになりました。
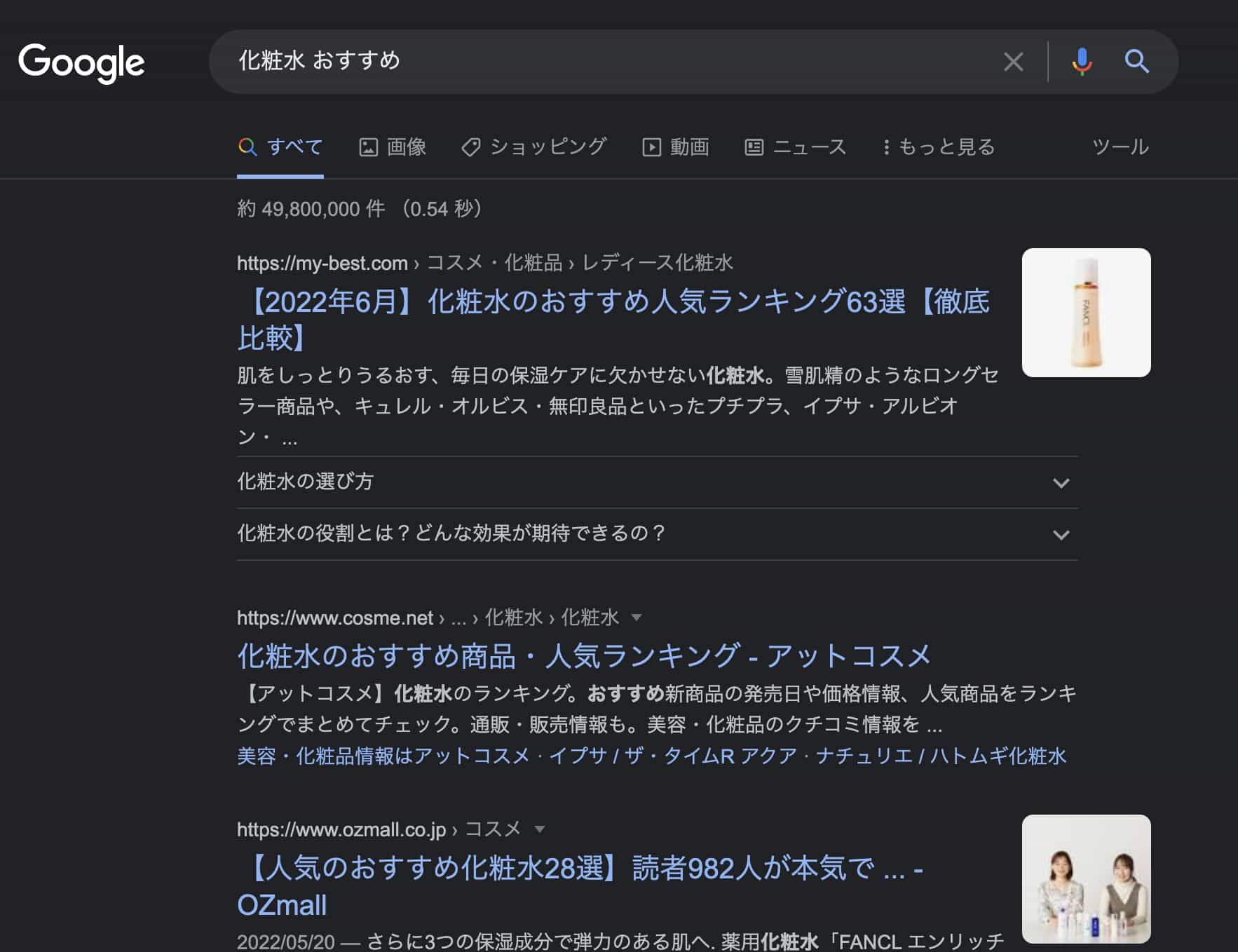
※タイミングによって検索順位は変わるので必ずしも一致するとは限りません。
ちなみにGoogleで検索順位を調べる時は、自分の検索履歴や位置情報に左右されてしまうのでプライベートブラウザで調べることをオススメします。
Googleの検索で上位を取れば取るほど多くの人の目に触れるため、多くの企業がいかに検索上位を取るかにしのぎを削っています。
このGoogleで検索上位を取る活動をSEO(Search Engine Optimization)と呼びます。
SEOに関して詳しく知りたい方は以下の記事を見てみてください!

たとえば「化粧水 おすすめ」で自分の記事がどのくらいの順位につけているかを定点的に観測したいという需要があるでしょう。
しかし、それを手動でやるのは面倒です。
そこで、、、Seleniumの出番なのです!!!そんなプログラムは自動でやらせてしまいましょう!
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import pandas as pd
options = Options()
# driver = webdriver.Chrome("{ご自身のディレクトリ}chromedriver.exe", options=options)
driver = webdriver.Chrome(options=options)
Keywords_list = pd.read_csv("Google_search_keyword.csv")
Keywords = Keywords_list["Keyword"]
df_list = []
for Keyword in Keywords:
url = f"https://www.google.com/search?q={Keyword}"
driver.get(url)
time.sleep(2)
article_list = driver.find_elements_by_class_name("tF2Cxc")
url_list = []
for article in article_list:
url = article.find_element_by_tag_name("a").get_attribute("href")
url_list.append(url)
title_list = []
text_num_list = []
images_num_list = []
h1_tag_list = []
h1_tag_num_list = []
h2_tag_list = []
h2_tag_num_list = []
h3_tag_list = []
h3_tag_num_list = []
h4_tag_list = []
h4_tag_num_list = []
h5_tag_list = []
h5_tag_num_list = []
for url in url_list:
driver.get(url)
time.sleep(2)
title_list.append(driver.title)
body = driver.find_element_by_tag_name("body").text
text_num_list.append(len(body))
images = driver.find_elements_by_tag_name("img")
images_num_list.append(len(images))
h1_list = driver.find_elements_by_tag_name("h1")
h1_tag = []
for h1 in h1_list:
h1_tag.append(h1.text)
h1_tag_list.append(h1_tag)
h1_tag_num_list.append(len(h1_tag))
h2_list = driver.find_elements_by_tag_name("h2")
h2_tag = []
for h2 in h2_list:
h2_tag.append(h2.text)
h2_tag_list.append(h2_tag)
h2_tag_num_list.append(len(h2_tag))
h3_list = driver.find_elements_by_tag_name("h3")
h3_tag = []
for h3 in h3_list:
h3_tag.append(h3.text)
h3_tag_list.append(h3_tag)
h3_tag_num_list.append(len(h3_tag))
h4_list = driver.find_elements_by_tag_name("h4")
h4_tag = []
for h4 in h4_list:
h4_tag.append(h4.text)
h4_tag_list.append(h4_tag)
h4_tag_num_list.append(len(h4_tag))
h5_list = driver.find_elements_by_tag_name("h5")
h5_tag = []
for h5 in h5_list:
h5_tag.append(h5.text)
h5_tag_list.append(h5_tag)
h5_tag_num_list.append(len(h5_tag))
df = pd.DataFrame([title_list, text_num_list, images_num_list, h1_tag_list, h1_tag_num_list, h2_tag_list, h2_tag_num_list, h3_tag_list, h3_tag_num_list, h4_tag_list, h4_tag_num_list, h5_tag_list, h5_tag_num_list]).T
df.columns = ["title", "char_num", "images_num", "h1_list", "h1_num", "h2_list", "h2_num", "h3_list", "h3_num", "h4_list", "h4_num", "h5_list", "h5_num"]
df["index"] = df.reset_index()["index"] + 1
df["Keyword"] = Keyword
df_list.append(df)
df_all = pd.concat(df_list)
driver.quit()
df_all.to_csv("Google_search_result.csv")
“Google_search_keyword.csv”のファイルは、調べたいキーワードを1行ずつ格納して上記のPythonファイルと同ディレクトリに置いておきましょう。
そうすることでSeleniumが勝手にそれぞれのキーワードの順位を調べてにいってくれるんです!
素晴らしいですね!
ちなみにseleniumのバージョン違いによってエラーを吐くことが多いので、それが煩わしいという人は「chromedriver_binary」というライブラリを使ってみてください!
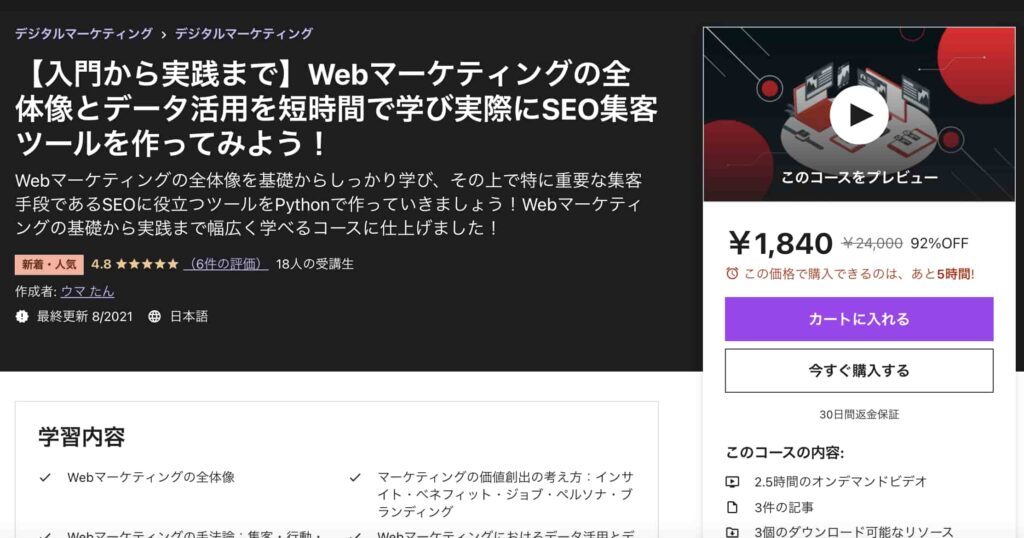
ちなみにGoogle検索の順位を取得するコードやSEOの概要を含めたマーケティング全般については以下のUdemy講座で解説しているので、もっと詳しく学びたい!という方は受講してみてください。
【入門から実践まで】Webマーケティングの全体像とデータ活用を短時間で学び実際にSEO集客ツールを作ってみよう!
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 2.5時間 |
| 【レベル】 | 初級 |
今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
Selenium×Python まとめ
ここまでご覧いただきありがとうございました!
Seleniumは非常に便利で面白い使い方が出来るのでぜひ色々と触ってみてください!
要素の抽出はBeautifulsoupでも出来るのでBeautifulsoupと組みあわせて使ってみてください!

また、Pythonでの自動化については以下の記事でまとめています!

この記事では、SeleniumをPythonで動かす方法について見てきましたが、Pythonは他にも色んな使い方ができます。
データ分析や生成AIの実装などPythonで出来ることを網羅的に体験したい方は当メディアが運営するスタアカをチェックしてみて下さい。
GPTモデルをはじめとした大規模言語モデルの理論やPythonでの扱い方などを幅広く学んでいきます!

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
Pythonの勉強は以下の記事にまとめていますので是非チェックしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















