
大規模言語モデル(LLM)の仕組みや種類について分かりやすく解説!

こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
テキスト生成系のAIのChatGPTや画像生成系AIのStable Diffusionをはじめとする様々な生成系AIの登場でAIブームが訪れました。
その中でもChatGPTなどの大規模なテキストを学習した生成系AIモデルを大規模言語モデル(LLM)と呼び注目を集めています。
この記事では、そんな大規模言語モデル(LLM)について分かりやすく解説していきたいと思います!
Youtube動画でも分かりやすくまとめているので是非チェックしてみてください!
RAGについて、こちらの記事も合わせてご活用ください!

目次
大規模言語モデル(LLM)とは?仕組みは?
まずは大規模言語モデル(LLM:Large Language Model)がどんなモデルなのか?どんな仕組みなのか見ていきましょう!
大規模言語モデル(LLM)は最近になってよく聞くようになりましたが、それ自体は古くから存在する自然言語処理分野の派生でしかありません。

昔から人間の言葉をどのように機械に理解させて翻訳や言語生成など様々なタスクに応用させるかは盛んに研究されてきました。
そんな中、2017年にTransformerというモデルの登場によるブレークスルーと計算機のマシンパワー向上により多くのデータをモデルに学習させて著しく精度を上げることができるようになったことで大規模言語モデル(LLM)が生まれました。
話題になったChatGPTのGPTとはGenerative Pretrained Transformerの略であり、Transformerに事前に大量のテキストデータを学習させたモデルを表しています。
これを起点に大規模言語モデルの戦国時代の幕開けとなったのです。
大規模言語モデル(LLM)のアーキテクチャは基本的にTransformerのアーキテクチャを踏襲しています。
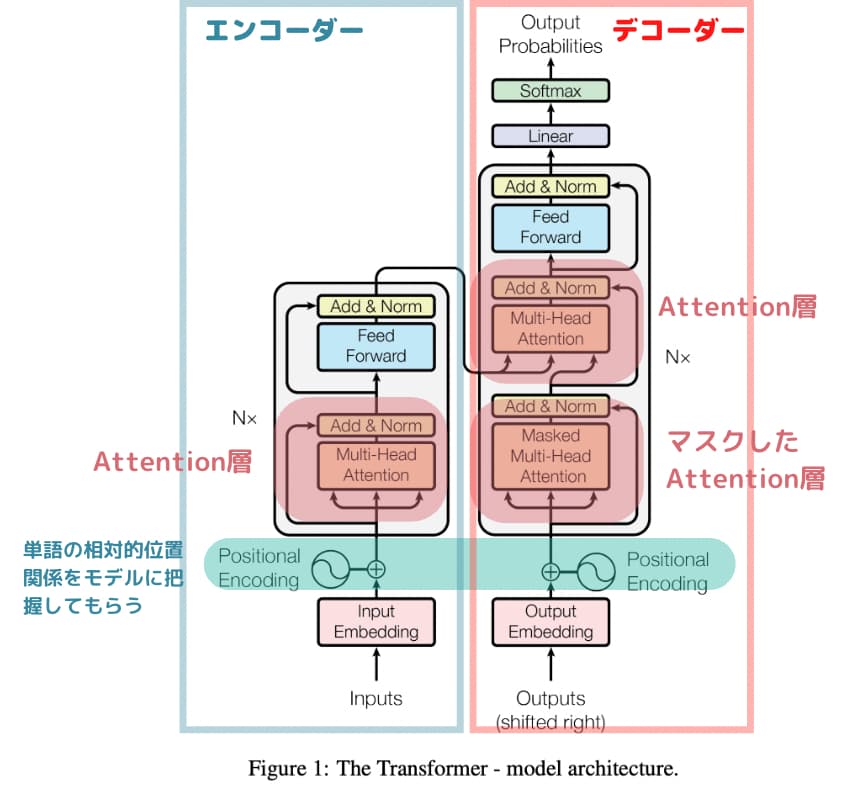
例えばテキストデータは、
私はりんごが好き
的な文章を入れてあげて、
単語分割した後にそれぞれの単語をマスクして
私/ は/ りんご/ が/ ()
みたいなことをやって学習してくれるので人間がわざわざラベル付けをする必要がなく大量のテキストデータを与えてあげることで文脈や言葉の意味が学習してくれるのです。
そして学習した結果から、AIが特定の言葉の後に確率的に続きそうな言葉を並べているのが大規模言語モデル(LLM)なのです。
そして、昨今の大規模言語モデルのすごいところは特定タスクに対してチューニング(ファインチューニング)をする必要なく、テキスト(プロンプト)による指示のみで翻訳や要約などのタスクを行えるところです。
今までだと
・翻訳タスク用の言語モデル
・要約タスク用の言語モデル
などのように各タスクに分かれているのが一般的だったのですが、昨今の大規模言語モデル(LLM)では、プロンプトで「翻訳してー!」「要約してー!」と言うだけでそれぞれのタスクに対応した答えが返ってくるようになっています。
大規模言語モデル(LLM)の種類一覧
さて、それではそんな大規模言語モデル(LLM)にはどんな種類があるのでしょうか?見ていきましょう!
Transformer
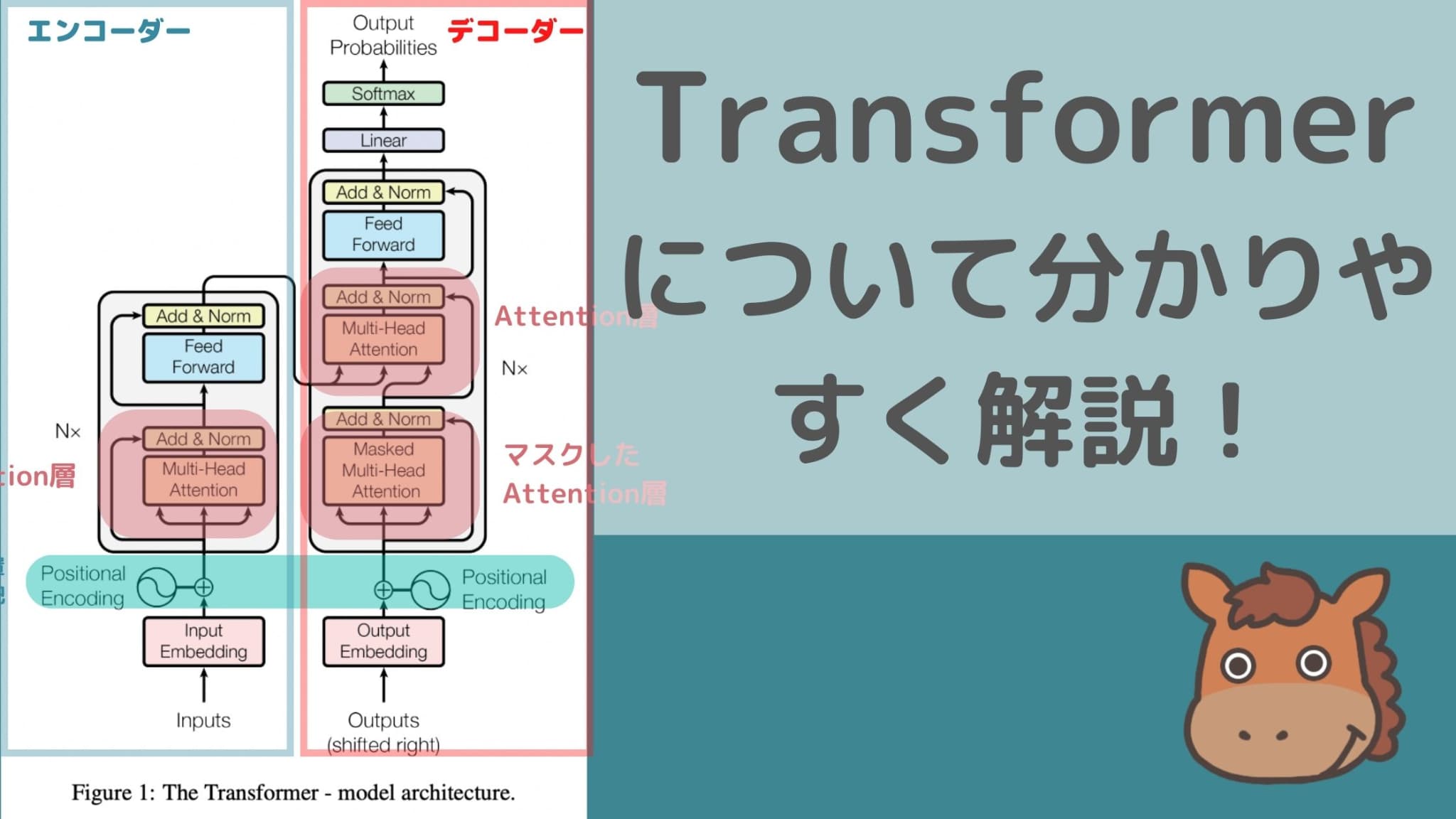
Transformerは大規模言語モデル(LLM)につながるきっかけになったニューラルネットワークアーキテクチャです。
Transformerとは、「Attention Is All You Need」という論文で2017年に発表されたディープラーニングのモデルです。
以下、「Attention Is All You Need」の引用になります。
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
引用元:Google- “Attention Is All You Need”
どんなことを言っているかというと従来のリカレントニューラルネットワークや畳込みニューラルネットワークで利用されていたリカレント層や畳み込み層を使わずにAttention層だけを使うようにしたらなんか精度がめっちゃ良くなったよ!ということです。
「Attention Is All You Need」とは、その言葉通りAttention層だけでいいんだよ!ってことです。
そう、Transformerのすごいところは、今までのRNNやCNNなどの従来のディープラーニングで当たり前に考えられていたReccurent層や畳み込み層を使わずにAttention層だけを使うようにしたということなんです!
そこからBERTやGPTなどの新しい手法の登場につながっています。
Transformerに関しては以下の記事に詳しく解説していますので是非チェックしてみてください!
BERT
BERTは2018年10月にGoogleからリリースされたモデルで、論文にはこのように記載されています。
BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks
(引用元:Google-“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”)
BERTはシンプルでありながら非常に強力で一般的な11つの言語処理指標において優位な結果を収めたと・・
実はBERTは事前学習モデルであり他の既存モデルと組み合わせることで効果を発揮するものなんです。
BERTとは「Bidirectional Encoder Representations from Transformers」
BERTは、双方向から文脈を学習できるようになったのです。
BERTに関しては以下の記事に詳しく解説していますので是非チェックしてみてください!

GPTシリーズ
続いてChatGPTで有名になったGPTモデル!
GPTモデルとはどのようなアルゴリズムになっているのでしょうか?
簡単に見ていきましょう。
GPTの論文はOpenAIから2018年に発表されました。
we explore a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and supervised fine-tuning. Our goal is to learn a universal representation that transfers with little adaptation to a wide range of tasks.
引用元:“Improving Language Understanding by Generative Pre-Training”
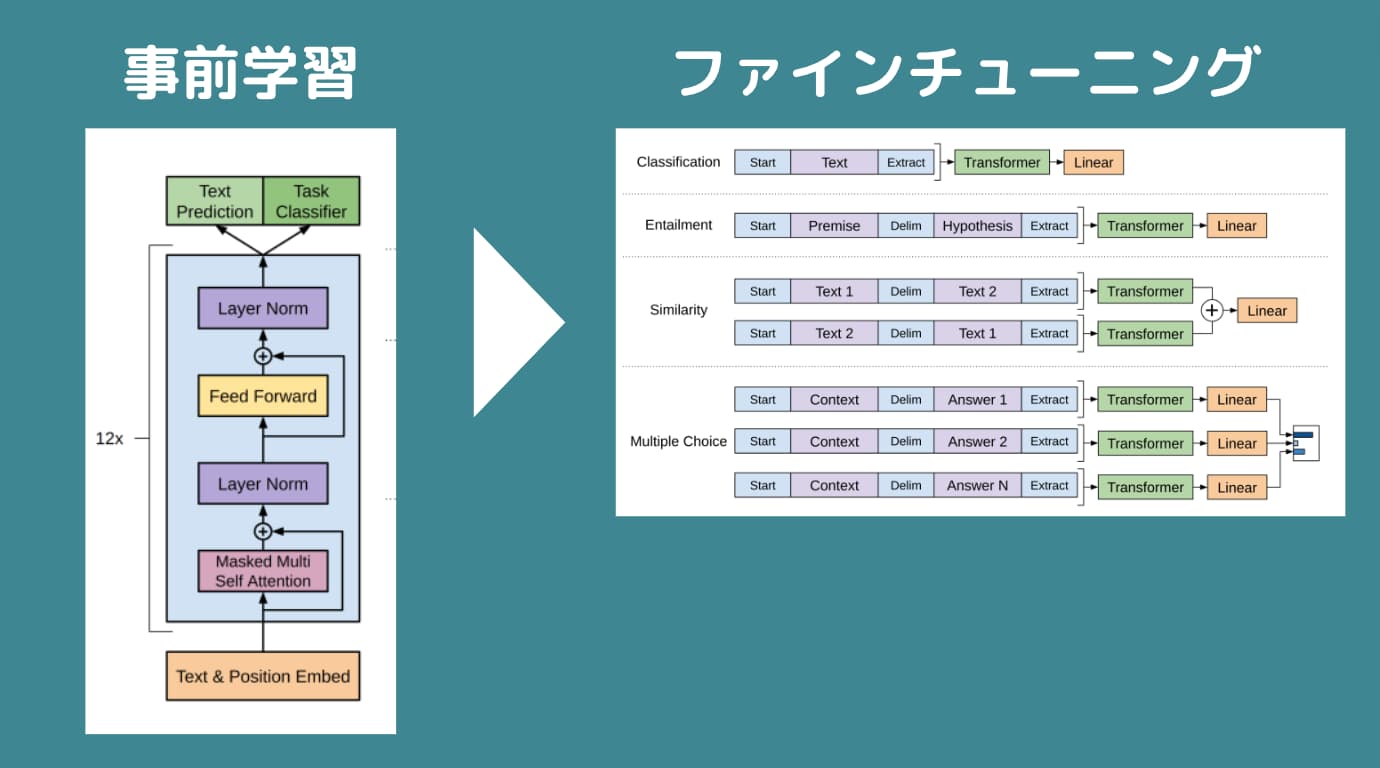
GPTは、大規模なテキストデータを事前学習した後にファインチューニングと呼ばれる各タスクに適した学習をしていく2段階のモデルです。
まず最初の事前学習の構成は以下になります。
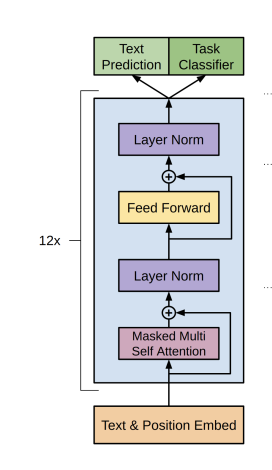
デコーダーによる事前学習をした後に2段階目である各タスクに合わせたファインチューニングを行います。
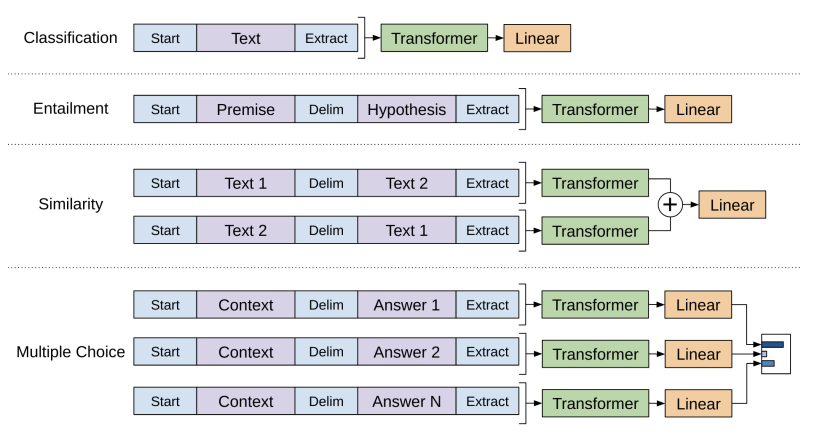
これが教師あり学習にあたります。
つまり、従来のモデルでは入力に対して出力ラベルがついた教師データを大量に用意してそれをエンコーダー・デコーダーモデルにインプットする必要があったのですが、GPTではまず事前学習モデルでラベル付与なく教師なし学習をして、その後に特定タスクにあわせてファインチューニングすることで大規模データの学習を可能にしたのです。
GPTシリーズに関しては以下の記事に詳しく解説していますので是非チェックしてみてください!

PaLM
PaLMは2022年にGoogleから発表されたモデルで「Pathways Language Model」の略です。
論文は以下になります。
論文はなんと87ページにも及ぶ超大作なのですが、正直特別革新的なアーキテクチャが登場するわけではなく、ベースとなるのはやはり2017年に同じくGoogleが発表したTransformerというアーキテクチャです。
PaLMでは端的に言うと、「とにかく大量のパラメータを持ったモデルで大量のデータを最強のマシン構成で学習させたようなモデル」なのです!
パラメータの数が5400億個もあります。
PaLMよりも前に発表されたOpenAIのGPT-3のパラメータが1700億個。
そしてMicrosoftから発表されたMegatron-Turing NLGのパラメータが5300億個。
Megatron-Turing NLGも絶妙に100億個パラメータが多いところがGoogleの意地を感じます。
ちゃんと論文には、ご丁寧に他の大規模言語モデル(LLM)と比較してどれだけPaLMがどれだけスゴイのかが記載されています。
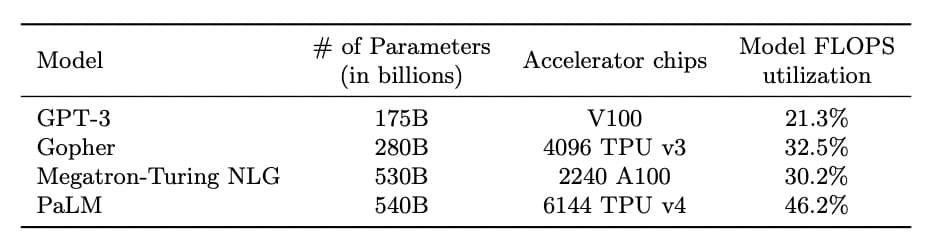 (出典:「Scaling Language Modeling with Pathways」)
(出典:「Scaling Language Modeling with Pathways」)
PaLM2が2023年5月に発表され、多くのGoogleプロダクトに適用されることが決まりました。
PaLMについて詳しく知りたい方は以下の記事をチェックしてみてください!

LLaMA
LLaMAは(Large Language Model Meta AI)の略であり、Metaが2023年2月に発表した大規模言語モデルです。
以下がLLaMAの論文になります。
LLaMAは、OpenAIに開発するGPTモデルや、Googleの開発するPaLMなどと比較すると圧倒的に少ないパラメータ数のモデルになっています。
LLaMAは、パラメータ数をおさえながら高精度を実現しているため、世界中の研究者がLLaMAをベースに様々な大規模言語モデルの可能性を探ることが可能になっているんです。
LLaMAのコードはGithubに上がっておりオープンソースとして公開されています。
LLaMAの特徴は少ないパラメータ数です。
各モデルのパラメータ数は以下のようになっています。
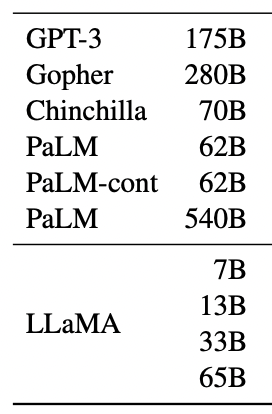
(出典:LLaMA: Open and Efficient Foundation Language Models)
LLaMAにはそれぞれ、
・70億個(正確には67億個)
・130億個
・330億個(正確には325億個)
・650億個(正確には652億個)
のパラメータ数のモデルが存在しています。
これでも十分パラメータ数は多い気がしますが、GPT-3の1700億個やGoogleのPaLMの5400億個などに比べると圧倒的に少ないのが分かるでしょう!
少ないパラメータでも他のモデルに匹敵する精度を出力しているのがLLaMAのすごいところです。
詳しいアーキテクチャについては以下の記事で解説していますので参考にしてみてください!
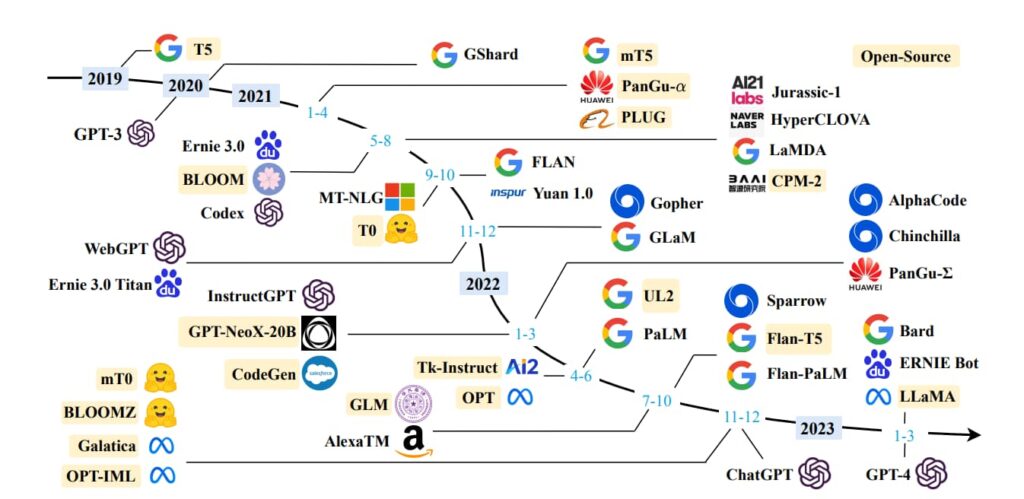
他にもたくさんの大規模言語モデル(LLM)があり、軌跡が以下の論文に詳しくまとまっています!
大規模言語モデル(LLM)の課題
ただ、そんな大規模言語モデルですがいくつかの課題が残っているんです。
学習データのバイアスによる偏見や差別
学習データのバイアスによる偏見や差別が生じ問題に発展する可能性があります。
AIは世の中の一般的な情報を大量に吸い上げて学習しているので、LLMにお願いしてテキストを生成した時にアウトプットに「看護師と言えば女性だし、お金持ちと言えば男性」みたいな偏見や差別が勝手に入り込む可能性があります。
個人情報・プライバシーの問題
また各種LLMを使う際に個人情報データや機密情報データをインプットすると、それを勝手に学習されてしまうという恐れがあります。
そのため企業によっては社員がChatGPTなどのLLMツールを利用するのを禁止しているケースもありますし、国自体が国民に使用を禁止しているケースもあります。
明確に学習に使わないと断言している場合もありますが、使用する際はくれぐれも注意しましょう!
正確性の問題
そもそも大規模言語モデル(LLM)は確率的に高いテキストを並べているだけなので、必ずしも正確な答えをアウトプットするとは限りません。
割と普通に嘘をつきます。
この正確性の問題は今後ある程度解決していくかとは思いますが、人間も完璧に正確なことを言うとは限らないので、そういうものだと思って付き合っていくしかないでしょう!
インプットする言語による精度差
大規模言語モデル(LLM)では、学習データであるテキストデータに様々な言語が混ざっているため、言語によってモデルの精度に差が生じます。
英語が一番精度が高く、日本語も比較的精度が高めです。
そのためより高い精度のアウトプットを求めるなら英語を使った方がよいでしょう!
以下はGPT-4の言語別の精度差になります。
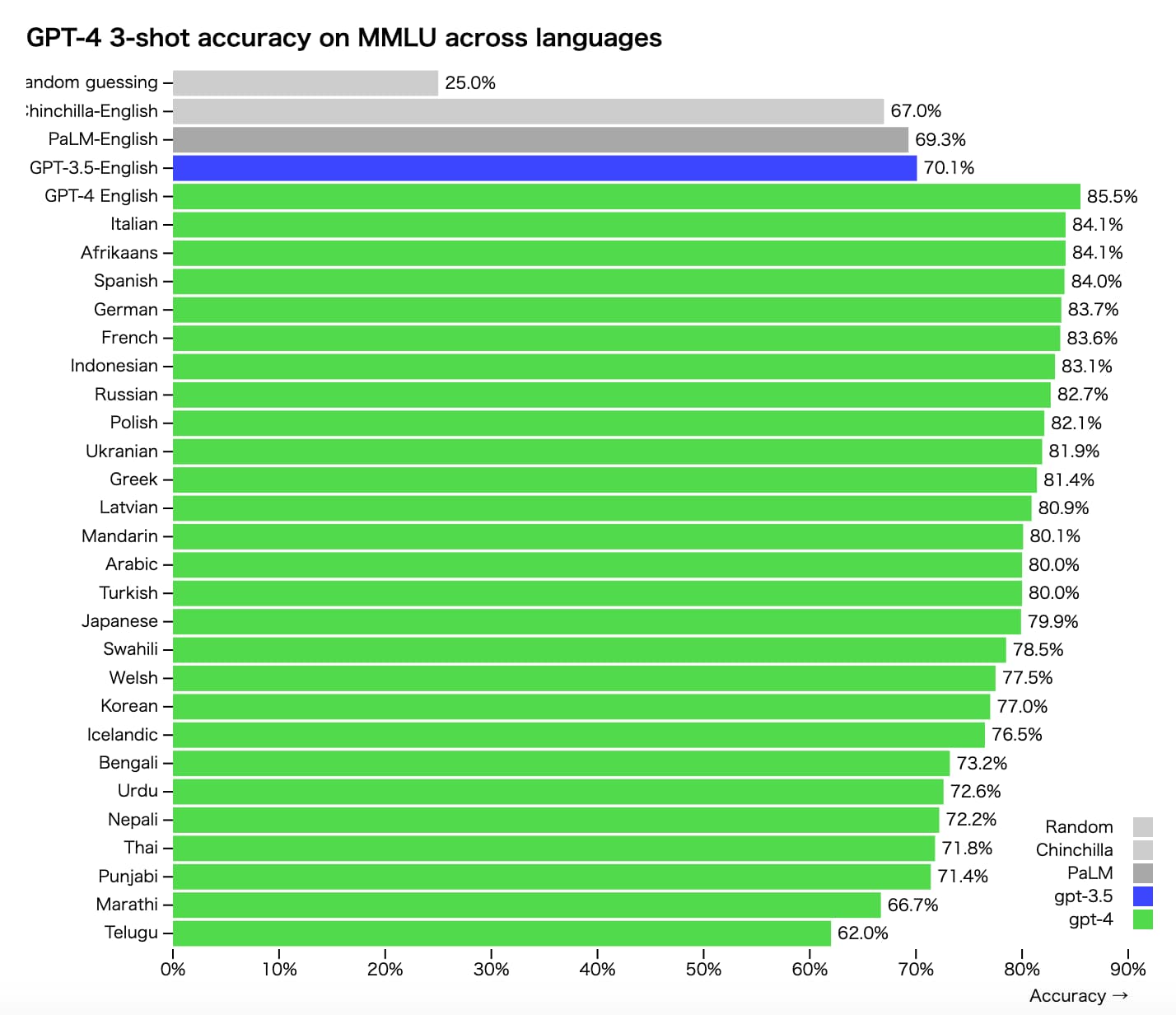 (出典:https://openai.com/research/gpt-4)
(出典:https://openai.com/research/gpt-4)
圧倒的な計算量によるコスト
また、圧倒的な計算量によるコストも課題です。
ChatGPTを開発するOpenAIは2022年に赤字5億4000万ドル(約730億円)を計上しており、高精度の大規模言語モデル(LLM)を開発するためには莫大なコストがかかることが伺えます。
大規模言語モデル(LLM)まとめ

ここまでご覧いただきありがとうございました!
本記事では、大規模言語モデル(LLM)について簡単にまとめてきました!
ここまでは、大規模言語モデル(LLM)がどんなものなのかザックリ見てきましたが、ある程度理解した後はGPTシリーズなどの各種モデルを具体的に手を動かしながら実装してみることが大事です。
各種大規模言語モデル(LLM)をPythonで利用する方法を知りたい方は以下のUdemy講座でまとめていますので是非チェックしてみてください!
大規模言語(LLM)モデル・生成系AIを学ぼう!概要を理解した後はPythonで動かしてみよう!
各種テキスト生成AIや画像生成AIの概要をアニメーションで学んだ後に実際にPythonを使ってAPI触っていきます!
大規模言語モデルや生成系AIの基礎を理解したいのであればこれ!
今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
また、当メディアが運営するスタアカの以下のコースでも大規模言語モデル(LLM)について詳しく解説していますので是非チェックしてみてください!
スタアカは業界最安級のAIデータサイエンススクールです。

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
AIデータサイエンスを学んで市場価値の高い人材になりましょう!
データサイエンスやAIの勉強方法は以下の記事でまとめています。


 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















