
【入門】Kerasを使ってディープラーニングのモデルを構築する方法を解説!TensorFlowとの違いも!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
この記事ではディープラーニングを簡単に誰でも実装できるPythonのライブラリKerasについて分かりやすく解説していきます!
Kerasの特性を理解して、色んなディープラーニングのモデルを実装できるようになりましょう!
目次
Kerasとは?
KerasはGoogleのエンジニアによって開発されたオープンソースのニューラルネットワークライブラリです。
コードが分かりやすくシンプルでKerasを使うことで誰でも簡単にディープラーニングを実装することができます。
2017年にはTensorFlowのコアライブラリとしてサポートされることが決まり、TensorFlow経由でKerasを動かすことができます。
KerasとTensorFlowとPyTorchの違いとは
ディープラーニングを実装するライブラリには、Keras以外にも先ほど紹介したTensorFlowやMeta社が開発したPyTorchなどがありますが、どんな違いがあるのか簡単に見ておきましょう!
コードのシンプルさ
Kerasは非常にシンプルなコードで可読性が高く初心者にも使いやすいライブラリになっています(後ほど実装していきます)。
一方でTensorFlowやPyTorchは少々読みにくく初心者にとってハードルの高いライブラリです。
処理速度
ただ、処理速度の観点ではKerasはTensorFlowやPyTorchに劣ります。
使用するモデルにもよりますが、TensorFlowやPyTorchの2倍ほどかかることもザラです。
最新のモデルやカスタマイズ性
SOTA(現時点での最高レベルの精度)を達成したような最新のモデルに関してはPyTorchで利用できる場合が多いです。
また、PyTorchでは複雑なモデルを柔軟に作ることが可能です。
そのため学術研究の領域ではKerasやTensorFlowよりもPyTorchが好まれて使われるケースが多いです。
PyTorchに関しては以下の記事で解説しています!

このように色んな観点でいくつかのライブラリがありますが、Kerasはまずはじめにディープラーニングを実装してみるライブラリとして最適でしょう!
Kerasを使ってディープラーニングを実装
Kerasについて知るためにはとりあえず手を動かしてKerasを触ってみることが大事!
ということで、早速Kerasを使ってディープラーニングのモデルを構築していきましょう!
畳み込みニューラルネットワーク(CNN)をKerasで実装
それでは、手書き文字のMnistに対して畳み込みニューラルネットワークを実装して分類するモデルを作ってみましょう!
Python実行環境としては気軽にGPUが使えるGoogle Colabをオススメします!
コードは、以下のようになります!
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow import keras
from tensorflow.keras import layers, models
from tensorflow.keras.utils import to_categorical
# Kerasに付属の手書き数字画像データをダウンロード
np.random.seed(0)
(X_train_base, labels_train_base), (test_x, test_y) = mnist.load_data()
# Training set を学習データと検証データに8:2で分割する
train_x, valid_x, train_y, valid_y = train_test_split(X_train_base, labels_train_base, test_size = 0.2)
# 各画像のShapeを整形
train_x = train_x.reshape((48000, 28, 28, 1))
valid_x = valid_x.reshape((12000, 28, 28, 1))
test_x = test_x.reshape((10000,28,28,1))
#正規化
train_x = np.array(train_x).astype('float32')
valid_x = np.array(valid_x).astype('float32')
test_x = np.array(test_x).astype('float32')
train_x /= 255
valid_x /= 255
test_x /= 255
# train_y, valid_y をダミー変数化
train_y = to_categorical(train_y)
valid_y = to_categorical(valid_y)
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# モデルを構築
model.compile(optimizer=tf.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy'])
# Early stoppingを適用してフィッティング
log = model.fit(train_x, train_y, epochs=100, batch_size=10, verbose=True,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0, patience=10,
verbose=1)],
validation_data=(valid_x, valid_y))
# テストデータの出力から0~9のどの値か判断
pred_test = np.argmax(model.predict(test_x), axis=1)
sum(pred_test == test_y)/len(pred_test)
以下の箇所でディープラーニングの層構造を設計していることが分かりますね!
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
活性化関数にRelu関数やソフトマックス関数を設定しているのが見て取れます。
詳しくは以下の記事でまとめているのでチェックしてみてください!

ResNetをKerasで実装
畳み込みニューラルネットワークの層を深くしていくと精度が悪化してしまう問題を解決したResNetをKerasで実装してみましょう!
ResNetに関して詳しくは以下の記事をチェックしてみてください!

コードは以下のようになります。
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.optimizers import Adam
# Load CIFAR-10 data
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# Preprocess the data
train_images = train_images.astype('float32') / 255
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# Define the model
model = models.Sequential()
model.add(ResNet50(include_top=False, weights=None, input_shape=(32, 32, 3), pooling='avg'))
model.add(layers.Dense(10, activation='softmax'))
# Compile the model
model.compile(optimizer=Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# Train the model with a reduced number of epochs to minimize processing time
model.fit(train_images, train_labels, epochs=1, batch_size=64, validation_split=0.1)
# Evaluate the model
test_loss, test_acc = model.evaluate(test_images, test_labels)
# Print the test accuracy
print(f'Test accuracy: {test_acc:.4f}')
今回はCIFAR-10という10個のクラスに分けられたカラー写真のデータセットを使っていますが、基本的な流れは先ほどと同じで非常にシンプルなのが分かると思います。
モデル定義のところでResNetを指定していますね!
LSTMをKerasで実装
続いて自然言語処理領域において利用されてきたRNNの派生型モデル「LSTM」をKerasで実装していきましょう!
LSTMに関して詳しくは以下の記事をチェックしてみてください!

import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# データ生成 (サンプルのため、sin関数を用います)
timesteps = 10
data = np.sin(np.linspace(0, 20 * np.pi, 1000))
# 入力データと正解データの作成
X = []
Y = []
for i in range(len(y) - timesteps):
X.append(data[i:i+timesteps])
Y.append(data[i+timesteps])
X = np.array(X).reshape(-1, timesteps, 1)
Y = np.array(Y).reshape(-1, 1)
# モデルの定義
model = Sequential()
model.add(LSTM(50, input_shape=(timesteps, 1), return_sequences=True))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
# モデルの学習
model.fit(X, Y, epochs=50, batch_size=32)
# 予測
test_input = np.array([np.sin(np.linspace(20*np.pi, 21*np.pi, timesteps))]).reshape(-1, timesteps, 1)
predicted_output = model.predict(test_input)
print("予測結果:", predicted_output)
今回は時系列のシミュレーションデータを発生させています。こちらもモデル定義部分でLSTMと指定するだけで実装できていますね!
オートエンコーダをKerasで実装
続いてオートエンコーダ!
オートエンコーダは、
特定のインプットデータ(主に画像)の次元を一旦圧縮しそれらの次元を元に戻し、インプットとアウトプットの差分を小さくするようにニューラルネットワークを学習するアプローチ
です!
ノイズを除去したり異常検知に使われるアプローチで、オードエンコーダの考えがベースになって昨今のAIが生まれています。
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
# MNISTデータセットの読み込み
(x_train, _), (x_test, _) = mnist.load_data()
# データの前処理
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# オートエンコーダのモデルを定義
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
# モデルのコンパイル
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer=Adam(), loss='binary_crossentropy')
# オートエンコーダの訓練
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
# テスト画像をエンコードおよびデコード
encoded_imgs = autoencoder.predict(x_test)
decoded_imgs = autoencoder.predict(encoded_imgs)
# 結果の表示
n = 10 # 表示する画像の数
plt.figure(figsize=(20, 4))
for i in range(n):
# 元の画像
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 再構築された画像
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
いままでの分類タスクや予測タスクとは違いMnistの画像をオートエンコーダにかけて復元しています。
結果は以下のようになり、上が元の画像で下が復元後の画像になるのですが、一番右側の9の元画像にあるノイズが復元後画像で除去されていることが分かると思います!
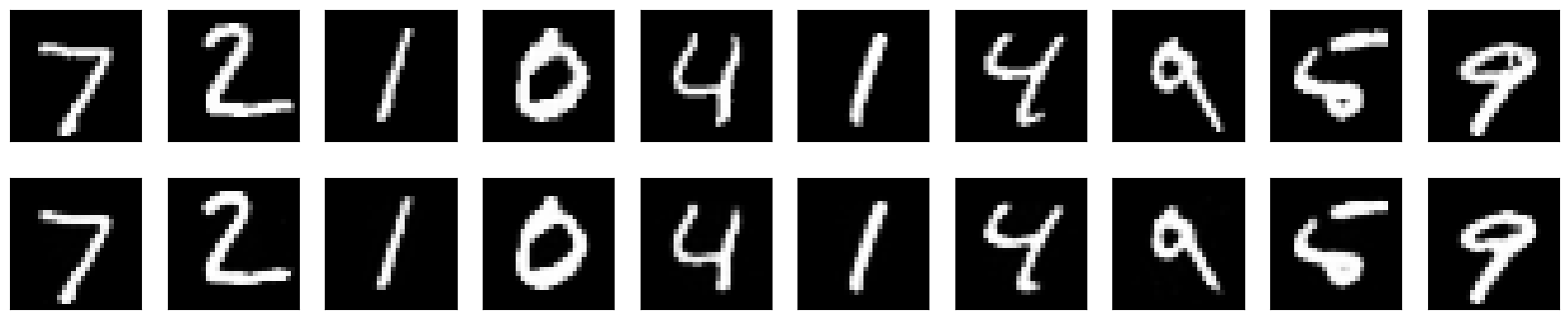
これこそがオートエンコーダなのです!
このように様々なディープラーニングのモデルがKerasを使って実装できることが分かったと思います!
ぜひ色んなディープラーニングのモデルを実装してみましょう!
Keras まとめ
ここまでご覧いただきありがとうございました!
今回はKerasについて解説していきました。
Kerasを使いこなしてディープラーニングを実装していきましょう!
さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
ディープラーニングの基礎からKerasを使ったCNN実装まで詳しく学べる「08.ディープラーニング」コースもありますよ!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















