
次元の呪いとは!?対策/対処法と共にわかりやすく解説!


こんにちは!
スタビジ編集部です!
今回は次元の呪いについて解説していきます!
次元の呪いとは「データが高次元になるにつれて、機械学習における回帰・分類の汎化性能が低下する現象」です。
次元の呪いによって計算量が膨大に増加するので、必ずしも高次元データが良いとは限らないことが考えられますね!
この記事では、次元呪いとその解決方法について解説していきます!
・次元の呪いについて解説!
・次元の呪いの解決方法について解説!
以下のYoutube動画でも解説していますので合わせてチェックしてみてください!
目次
次元の呪いについて解説!

何故高次元になるほど、機械学習モデルの精度が低下するのでしょうか?簡単な例から見てみましょう!
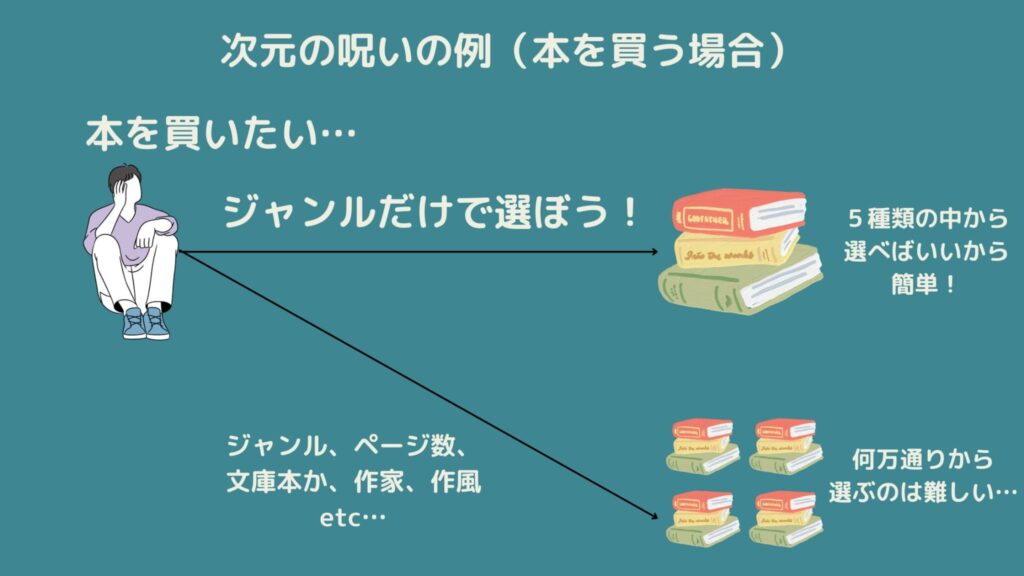
例として書店に行ったとき、どの本を買いたいかを考えたとします。
この時、本を選ぶ基準というのは様々です。
例えば「ジャンル」で考えればSF・ホラー・純文学…などで考えると5種類ぐらいあると考えます。
この特徴量「ジャンル」だけ見れば5通りの中から1つ選ぶだけなので簡単そうですね!
しかしジャンルだけでなく、作者やページ数、評価といった特徴量を考えると何千通りの中から1つ選ぶことになります。
これを繰り返していくと指数関数的に情報量が多くなることが考えられますね!これを「次元の呪い」と呼びます。
情報量が指数関数的に増加することでどういった問題が発生するのでしょうか?
高次元ということは必然的にデータ量を多くなってしまうので計算量が膨大になることが考えられます。
そして不必要な情報も混じっている可能性が高いです。
したがって次元の呪いの問題点は「計算時間は膨大になりつつ、適切な評価ができているかわからないこと」と考えられます!(ビジネスでは致命的になりますね…)
数学的な観点から考えた次元の呪い
次元の呪いを数学的な観点から考えてみると、見え方が少し変わります。
数学的な観点から考えた次元の呪いとは「高次元になると、データが空間の外側に分布してしまう現象」と表せます。
例として、半径rの球体の上に十分に小さい厚さεの薄皮があると考えましょう。
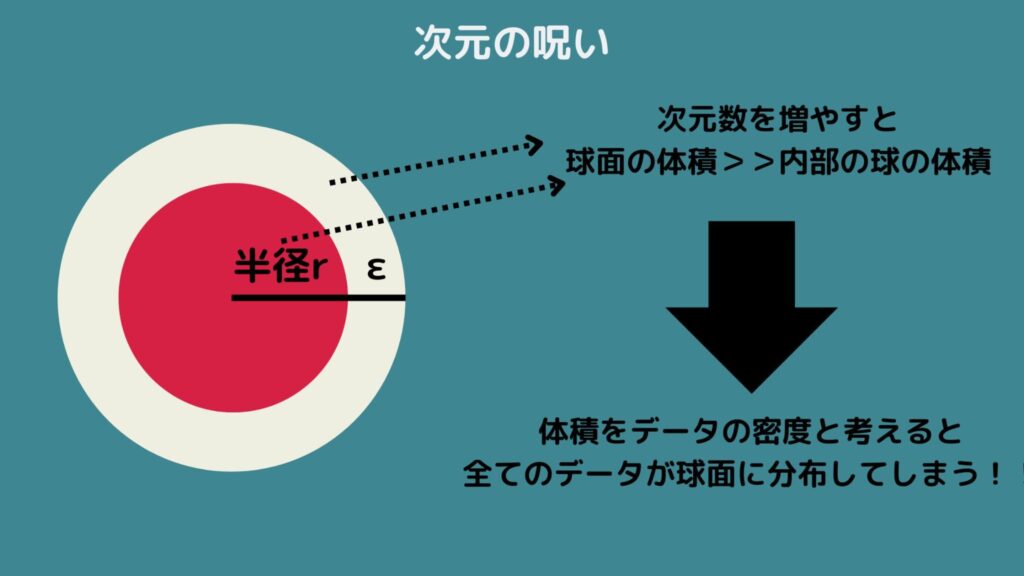
この時、半径がrのd次元球体の体積は以下の通りになります。Γ()はガンマ関数を表しています!
\(V_{r}=\frac{π^{d/2}r^{d}}{Γ(d/2)+1}\)
次に半径r+εの超球の体積は以下の通りになります!先ほどの式とほぼ一緒ですね。
\(V_{r+ε}=\frac{π^{d/2}(r+ε)^{d}}{Γ(d/2)+1}\)
この時、これらの球体の体積の比はどうなるかというと…?
\(\frac{V_{r}}{V_{r+ε}}=(1+\frac{ε}{r})^{-d}\)
つまり次元数dを無限に増加させると、この体積の比は0に近づくことが考えられますね!
したがって薄皮の厚さεの部分の体積と、その内部の半径rのd次元球体の比を考えたとき、表面の体積の割合がほとんど1になり、内部の体積は0になってしまいます!
したがってd次元空間の次元数が大きくなると、体積が0の領域にはデータが生起されないと考えられます。
つまり原点付近のデータがほぼ発生しないことと同じです。
そう考えると空間の外側にデータが分布することになりますね!
次元の呪いの解決方法について解説!
次は次元の呪いを解決する方法を解説します!
次元削減
次元削減をすることで高次元データの次元を削減しつつ、なるべく情報量のロスを抑えることが考えられます。
次元削減の方法はいくつかありますが、代表的な手法は主成分分析(PCA)でしょう。主成分分析とは複数の変数をいくつかの変数に合成する手法です。こちらの記事をぜひ参考にしてみてください!

特徴量選択
特徴量選択をすることで、有用な特徴量のみを選択しつつ次元を削減する方法が考えられます。
特徴量選択の基準として、ランダムフォレスト・XGBoostで使われる特徴量重要度が考えられます。
またLasso回帰によって、不要な特徴量の係数を0にすることも挙げられます。これらの記事もぜひ見てくださいね!



次元の呪いについて検証してPythonで主成分分析を使って次元削減に挑戦!
次元の呪いの影響について実際にシミュレーションデータを発生させて確認してみましょう!
ここでは2値分類の1000サンプルのデータセットを作成します。
次元数は5, 10, 20, 50, 100で検証してみましょう!
コードは以下のようになります。
次元数を上げると分類精度はどうなるでしょう・・・?
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
from sklearn.metrics import accuracy_score
import numpy as np
# Parameters
n_samples = 1000
n_features_list = [5, 10, 20, 50, 100]
n_classes = 2
# Function to generate data, train model and calculate accuracy
def test_dimensionality(n_features):
# Generate synthetic data
X, y = make_classification(n_samples=n_samples, n_features=n_features, n_classes=n_classes, random_state=0)
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# Train a logistic regression model
model = LogisticRegression(solver='liblinear', random_state=0)
model.fit(X_train, y_train)
# Predict and calculate accuracy
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
return accuracy
# Test for different number of features
accuracies = {n_features: test_dimensionality(n_features) for n_features in n_features_list}
print(accuracies){5: 0.9566666666666667, 10: 0.95, 20: 0.9633333333333334, 50: 0.9533333333333334, 100: 0.8866666666666667}
次元数5~50までは分類精度はそれほど変わりませんが、次元数が100になり大きく分類精度が下がっていることが分かります。※シンプルなロジスティック回帰で分類しています
それでは、この問題を解消するために100次元のデータセットに主成分分析を適用させてみましょう!
# Test PCA for 100 dimensional data
X, y = make_classification(n_samples=n_samples, n_features=100, n_classes=n_classes, random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# Apply PCA
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# Train and test logistic regression on PCA-transformed data
model_pca = LogisticRegression(solver='liblinear', random_state=0)
model_pca.fit(X_train_pca, y_train)
y_pred_pca = model_pca.predict(X_test_pca)
accuracy_pca = accuracy_score(y_test, y_pred_pca)
print(accuracy_pca)結果は、0.93となりました!
PCAを適用させて次元圧縮することで精度が改善していることが分かりますね!
次元の呪い まとめ

ここまでご覧いただきありがとうございました!
本記事では、次元の呪いについてまとめました!
このようなデータサイエンスの力を身に付けるためにはスタビジの記事やスクールを活用すると良いでしょう。
当メディアでは、データサイエンティストの経験を詰め込んだデータサイエンス特化のスクール「スタアカ(スタビジアカデミー)」を運営していますので、興味のある方はぜひチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
データサイエンスに関する記事はこちら!


データサイエンスを勉強できるスクールやサイトは、ぜひこちらを参考にしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















