
【5分でわかる】pix2pixについてわかりやすく解説!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
この記事では画像から画像に変換するディープラーニングの手法であるpix2pixについて解説していきます。
最近話題の画像生成系AIにつながる技術を理解する上でもおさえておきましょう!
以下の動画でも解説していますのであわせてチェックしてみてください!
目次
pix2pixとは?
pix2pixはその名の通り、入力画像から特定の別の画像を出力するアプローチでGANベースのアーキテクチャになります。
2017年に発表された手法で論文は以下です。
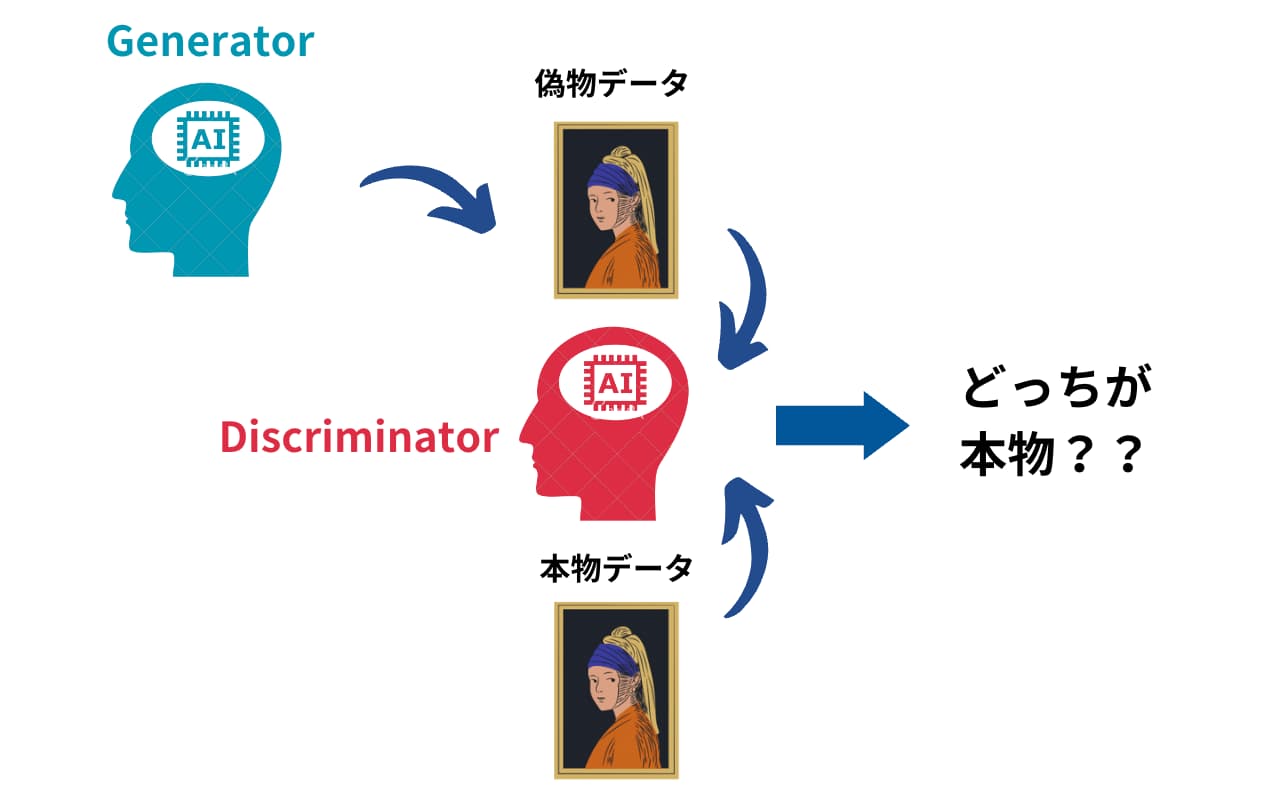
ベースとなっているGANは以下のようなプロセスを経るアプローチでした。
- 2つのGeneratorとDiscriminatorを用意します。
- Generatorは偽物のデータを生成します
- DiscriminatorはGeneratorが生み出した偽物のデータと本物のデータを判別しま
- これらを競い合わせ2・3を繰り返すことで、Generatorが生み出すデータが本物に限りなく近いものになっていきます。
これを画像変換に応用したのがpix2pixというわけです。
以下は、論文に掲載されている実際にpix2pixを使った画像群です。
 (出典:”Image-to-Image Translation with Conditional Adversarial Networks“)
(出典:”Image-to-Image Translation with Conditional Adversarial Networks“)
左上は、セマンティックセグメンテーションで自動車などの対象物をセグメントした画像を元の画像に戻しています。
右上では、白黒の画像に色を付けることに成功していますね!
pix2pixのアーキテクチャ
それではそんなpix2pixのアーキテクチャについて詳しく見ていきましょう!
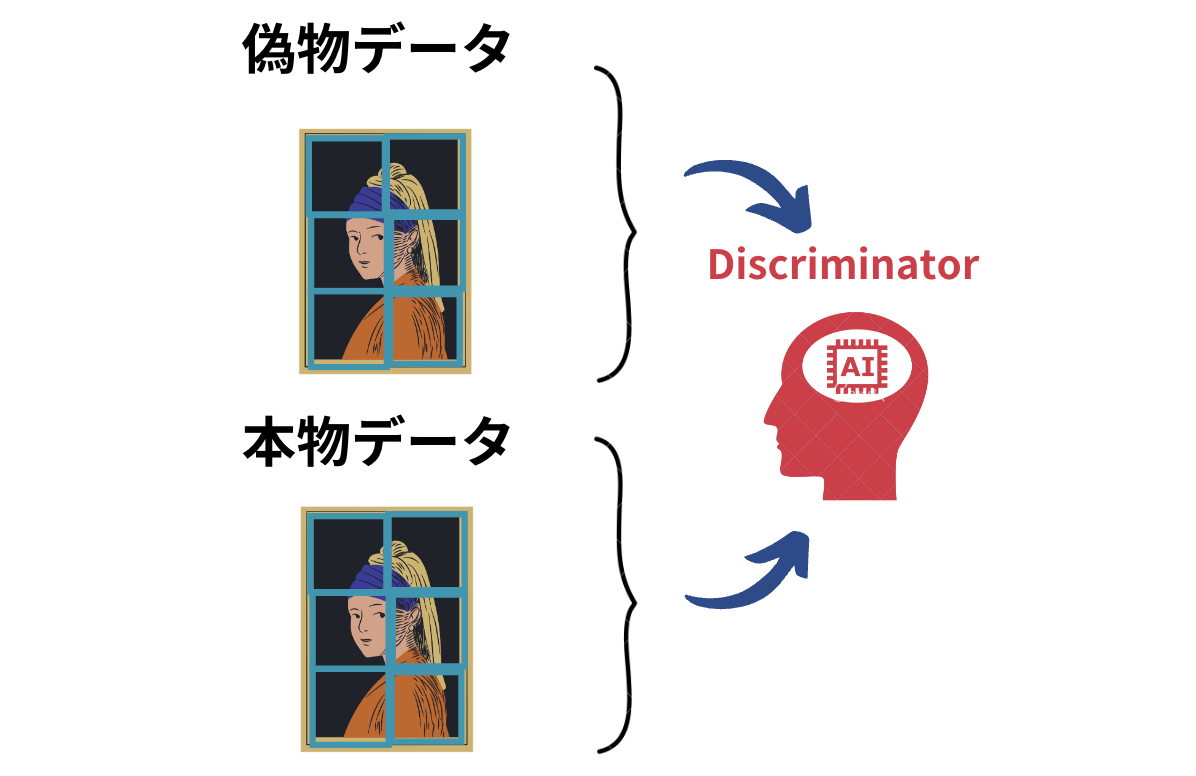
このpix2pix2のアーキテクチャはシンプルで、「元の画像とGeneratorで生成した偽物画像の組み合わせ」と「元の画像と本物画像の組み合わせ」からDiscriminatorが偽物の組み合わせを判断するアーキテクチャです。
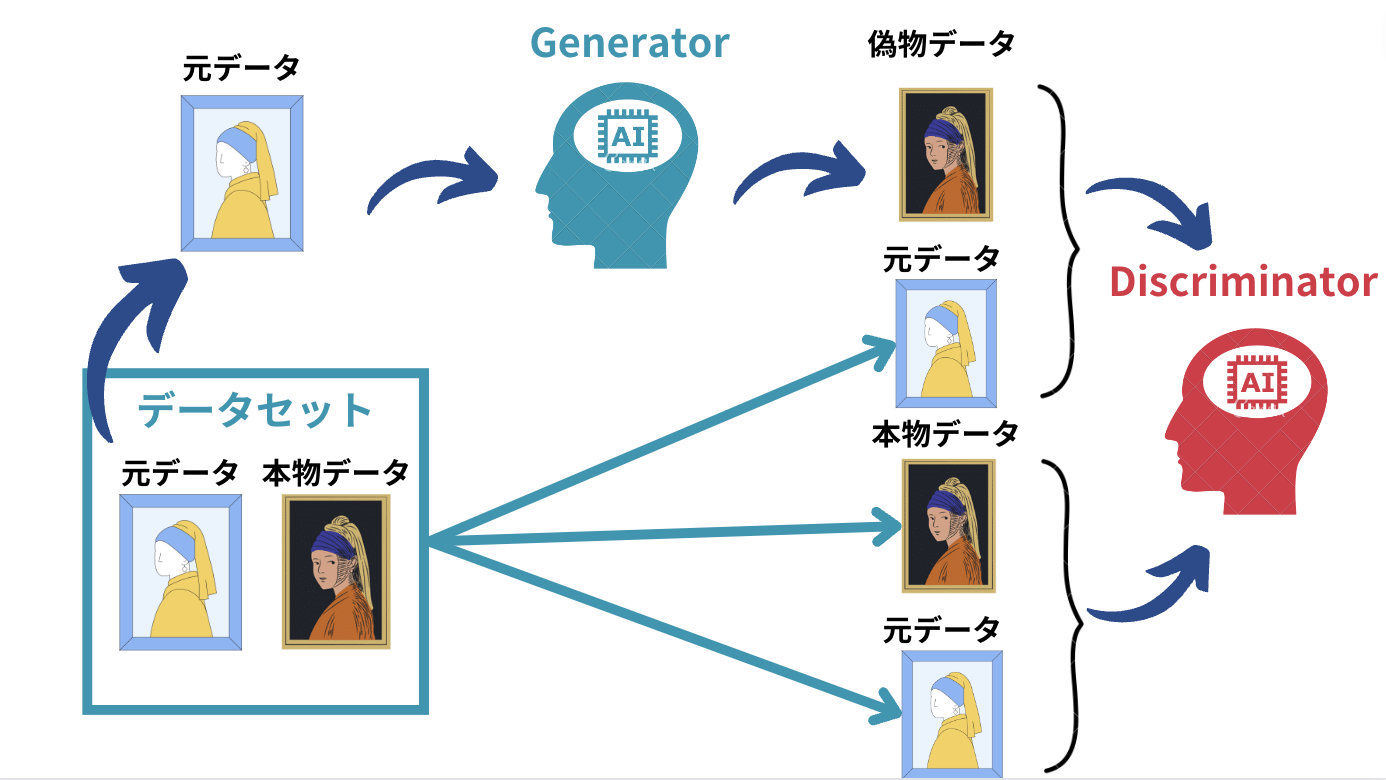
基本はこれだけなのですが、もう少しだけpix2pixで取り入れられているアーキテクチャの特徴を論文をベースに見ていきましょう!
GeneratorにU-Netを使用
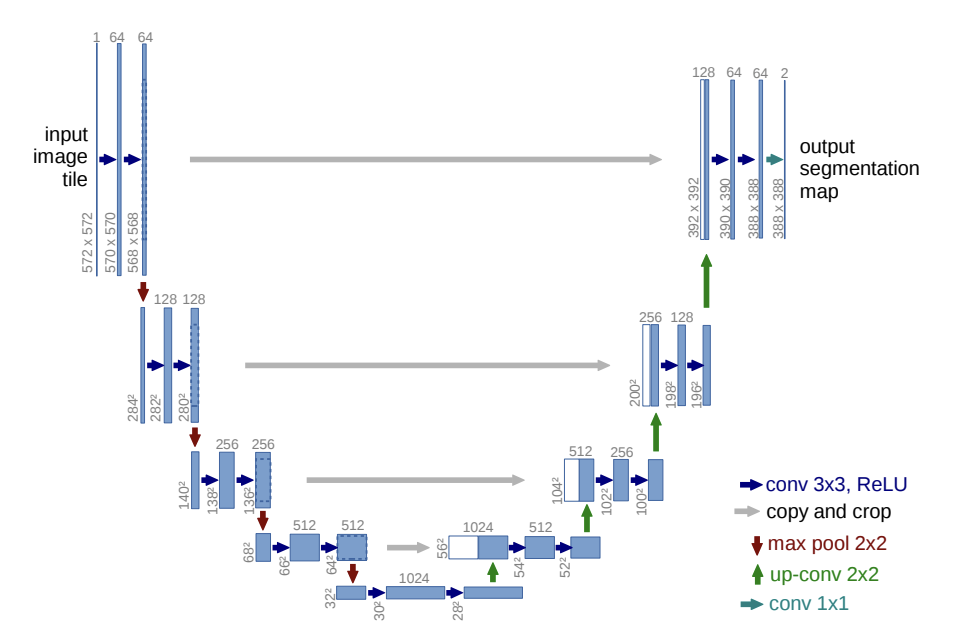
GeneratorにはU-Netという2015年に提案されたセマンティックセグメンテーションのアーキテクチャが用いられています。
 (出典:”U-Net: Convolutional Networks for Biomedical Image Segmentation“)
(出典:”U-Net: Convolutional Networks for Biomedical Image Segmentation“)
アーキテクチャがアルファベットのUに見えることからU-Netという名前がつけられています。
特徴的なのが左側のエンコーダから右側のデコーダへの灰色の矢印であるSkip接続。
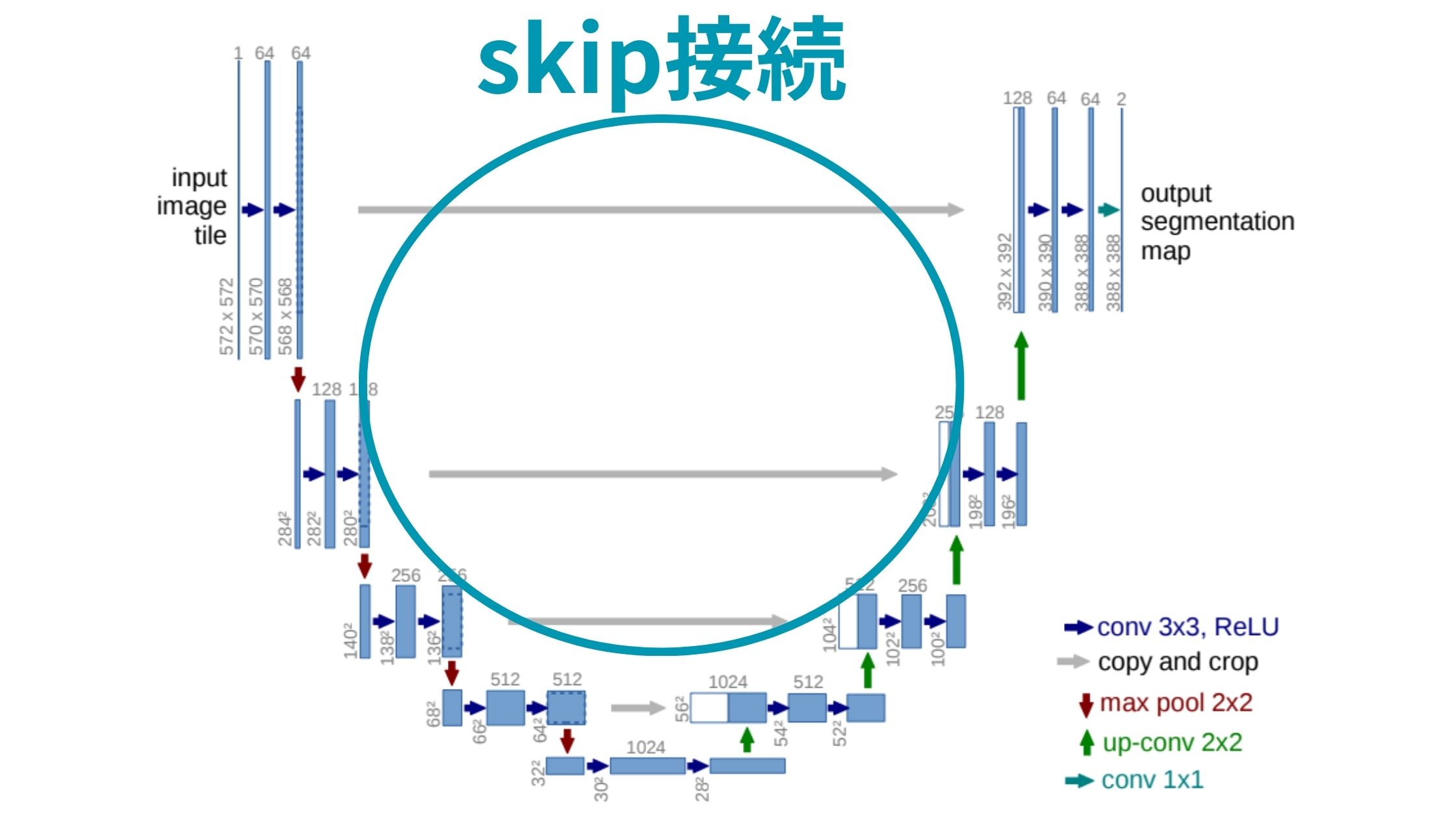
左側のエンコーダアーキテクチャでダウンサンプリングする中で抽出された特徴をそのまま後続のデコーダに直接渡す役割を担っています。
これにより、画像の細かい特徴と抽象的な特徴を捉えることができるようになります。
DiscriminatorにPatchGANを使用
DiscriminatorにはPatchGANというニューラルネットワークアーキテクチャを用いています。
これはPatchという名の通り、画像の一部をパッチ単位で取り出してそのパッチ単位で真偽判定するアーキテクチャです。
目的関数にL2ノルムではなくてL1ノルムを採用
目的関数にも特殊な採用をしています。
以下論文からのピックアップです。
Previous approaches have found it beneficial to mix the GAN objective with a more traditional loss, such as L2 distance [43]. The discriminator’s job remains unchanged, but the generator is tasked to not only fool the discriminator but also to be near the ground truth output in an L2 sense. We also explore this option, using L1 distance rather than L2 as L1 encourages less blurring
(出典:”Image-to-Image Translation with Conditional Adversarial Networks“)
従来研究では目的関数にL2ノルムを損失として追加することで精度が上がることがわかっていたのですが、pix2pixではL1ノルムを損失として追加しています。
L1ノルムやL2ノルムは過学習を防ぐために用いられパラメータが増えれば増えるほど罰則が与えられるようになっています。
L1ノルムはいわゆるマンハッタン距離(絶対値距離の和)でありL2ノルムはユークリッド距離です。
\(L1ノルム:|x_1| + |x_2| + ・・・ + |x_n|\)
\(L2ノルム:\sqrt{x_1^2 + x_2^2 + ・・・ + x_n^2}\)
L2ノルムとL1ノルムに関してはラッソ回帰とリッジ回帰の違いの記事に詳しくまとめているのでぜひチェックしてみてください!

ノイズベクトル
以下の部分では、ノイズベクトルについての言及がされています。
Without z, the net could still learn a mapping from x to y, but would produce deterministic outputs, and therefore fail to match any distribution other than a delta function. Past conditional GANs have acknowledged this and provided Gaussian noise z as an input to the generator, in addition to x (e.g., [55]). In initial experiments, we did not find this strategy effective – the generator simply learned to ignore the noise – which is consistent with Mathieu et al. [40]. Instead, for our final models, we provide noise only in the form of dropout, applied on several layers of our generator at both training and test time. Despite the dropout noise, we observe only minor stochasticity in the output of our nets. Designing conditional GANs that produce highly stochastic output, and thereby capture the full entropy of the conditional distributions they model, is an important question left open by the present work
(出典:”Image-to-Image Translation with Conditional Adversarial Networks“)
従来のGANでは、そのままインプットからGeneratorを通すアーキテクチャで学習すると、最終的に同じような画像のアウトプットになってしまうため、生成画像に多様性を持たせるためにノイズベクトルZを加えて学習させるアーキテクチャになっています。
しかし、このpix2pixではノイズベクトルZを加えてもノイズを無視して学習してしまうため、dropoutとしてノイズを加えてみたけどそれでもあんまり上手くいかず今後の課題になっているようです。
pix2pix まとめ
今回はpix2pixについて解説してきました。
改めてまとめておきましょう!
・基本はGANのアーキテクチャ
・GeneratorにはU-Net
・DiscriminatorにはPatchGAN
・目的関数にはL1ノルムを付与
・ノイズはDropoutで代用
同じような手法でCycleGANという手法があり、そちらは以下の記事でまとめていますのでチェックしてみてください!

pix2pixのPythonでの実装は以下のGithubに詳しくまとめてあります。
PyTorchを使うパターンとTensorFlowを使うバージョンがあります。
少々時間がかかりますが、興味のある方は実装してみましょう!
他にも多くのディープラーニングのモデルがあります。
ディープラーニングの様々なモデルを知りたい方は以下の記事を参考にしてみてください。
・RNN
・AlexNet
・ResNet
・Transformer
また、さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















