
異常検知の様々な手法(古典的・機械学習)を紹介しオートエンコーダをPythonで実装していく!

こんにちは!データサイエンティストのウマたん(@statistics1012)です!
この記事では異常検知の様々な手法を解説し、最終的にPythonで実装していきます。
実は、大学院時代の研究テーマが異常検知でして海外学会とかでも発表してました!
論文は以下です!対数尤度を用いた異常検知の手法です。
異常検知って一見地味な分野に思えるかもしれませんが、生産工程の機械の劣化による異常を早めに検知したりSNSにおけるスパイクを早めに検知したりクレジットカードの不正利用を検知したり、と意外と色々なとこに応用が可能で非常に重要な技術なんです。
そしてそんな異常検知は古典的な統計学的なアプローチもあれば最新の機械学習やディープラーニングを使ったアプローチまで幅広く存在します!
ということでこの記事では、そんな異常検知の技術を幅広く学んでいきましょう!
以下のYoutube動画でも解説していますのであわせてチェックしてみてください!
目次
そもそも異常検知とは?
そもそも異常検知とは大量のデータから異常のデータを検出したり、状態が異常になっていることを検出したりするアプローチのことを指します。
冒頭でお話したようにクレジットカードの不正利用も生産工程の異常もどれも異常検知の領域になります。
アプローチとしては、まず手元のデータから正常空間を作ってその空間を外れるものを異常と判断するものになります。

このイメージを常に持っておきましょう!
異常検知のアプローチ:統計学編
それでは具体的にどんな手法があるか見ていきましょう!
まずは古典的な統計学に端を発する異常検知手法から見ていきましょう!
MT法・ホテリング管理図
まず最初に紹介したいのがMT法!
タグチメソッドの主要手法であり生産管理分野の異常検知で非常によく使われる手法です。
MT法はマハラノビス距離を用いた、非常に分かりやすくかつ強力な異常検知手法。
マハラノビス距離については以下の動画で解説していますので是非チェックしてみてください!
多変量解析の分野で判別分析という手法がありますが、判別分析は母集団に対等な二群を想定しているのに対して,

MT法では正常と異常という概念で判別を行います。
つまり,正常はある一つの群をなすが、異常は群をなさないというのがMT法が想定しているデータの背景の特徴です。
例えば、健康診断を行って患者が健康か健康でないかを判別したいときにはMT法が良いです。
健康な人は同じような数値をとりますが、「健康でない」というのは様々なものがあります。
例えば体重を考えてみると、体重は重すぎても軽すぎても健康とは言えません。つまり、異常の方向がばらばらなのです。
数値が大きかったら異常、小さかったら正常という風には分けられないためMT法が使われます。
では正常な空間を作るにはどうすればよいでしょうか?
例えば、体重と身長の2変数で考えて異常な人を見つけ出すとしましょう!
身長を縦軸に体重を横軸に取りましょう。
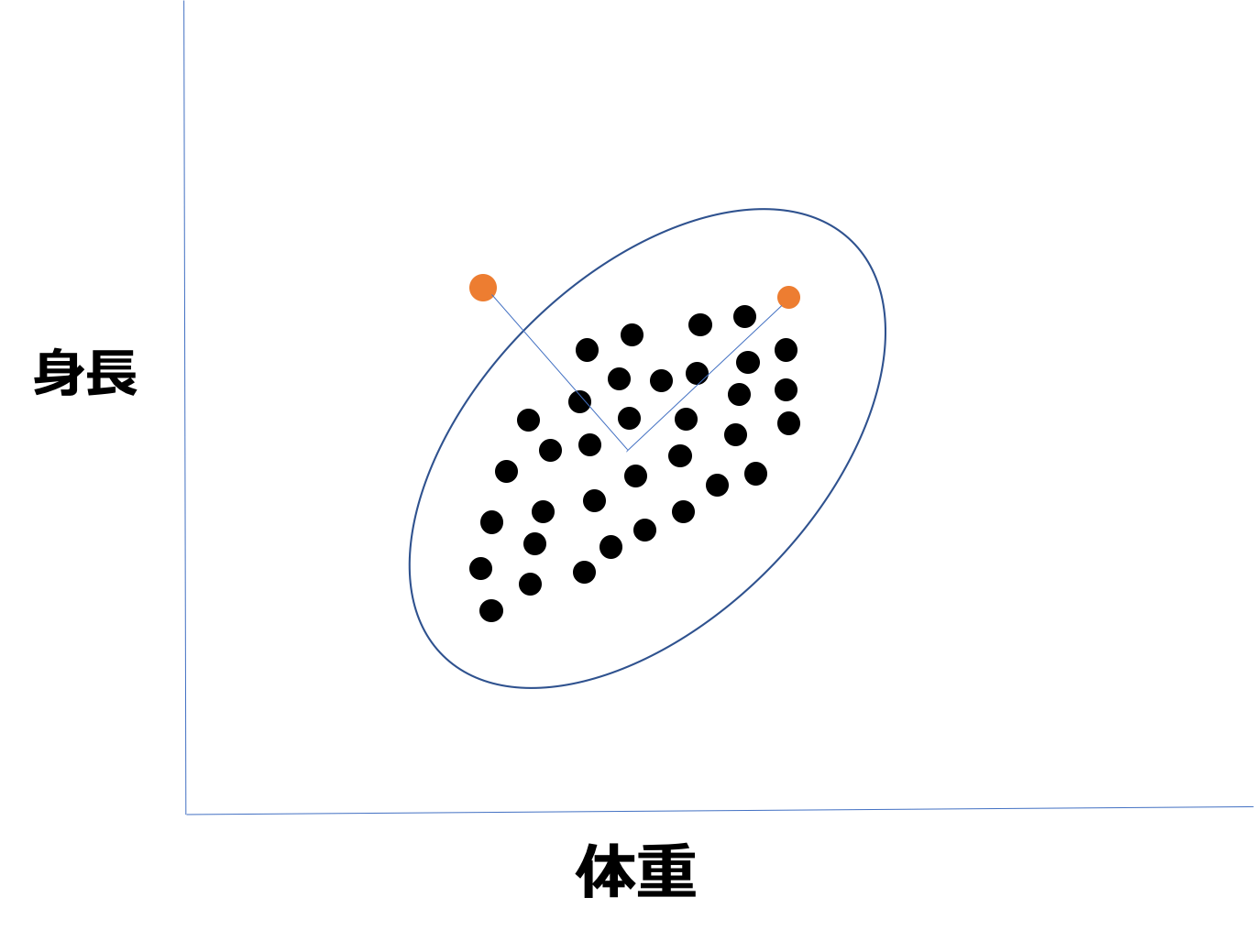
この時、オレンジの点が2つありますよね。どちらが異常でしょうか?
この時中心からのユークリッド距離はどちらも同じなのですが、左のオレンジの点の方が群から外れている異常値に見えます。
身長が伸びれば伸びるほどそれに比例して体重も増えるはずなので、その相関関係も考えた上で正常空間を考える必要があります。
そこで相関も考慮した距離であるマハラノビス距離が用いられるのです。図の青い線がまさにマハラノビス距離で求めた正常空間になります。
ちなみにMT法はホテリング管理図という古典的な管理図手法をベースに異常に寄与している変数を見つけ出すSN比という指標を取り入れたものです。

その他の管理図
先ほどホテリング管理図が登場しましたが、管理図というのは長年異常検知分野で用いられてきた手法群です。
単一の変数から異常を判断する単変量管理図と複数の変数から異常を判断する多変量管理図があります。
単変量管理図で有名なものにシューハート管理図というものがあります。
正常工程のサンプルから平均値や中央値、範囲を計算し、それらを元に上方管理限界線と下方管理限界線を求めます。
検査したい工程におけるサンプルの挙動を観察し、管理限界線を越えたら異常とします。
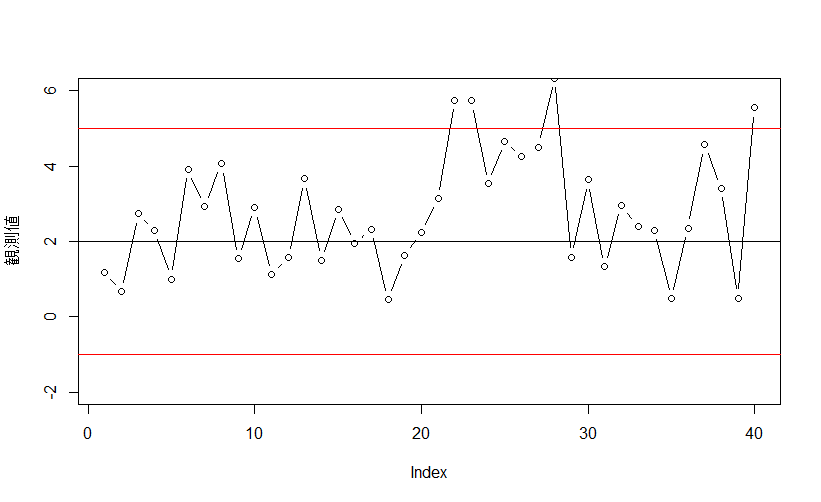
またそれ以外にもサンプルが連続して上方・下方のどちらか片方に7回連続した場合なども異常とみなします。
他にも色々な管理図があり以下で詳しくまとめていますので興味のある方はチェックしてみてください!

異常検知のアプローチ:機械学習編
続いて機械学習分野の異常検知手法を見ていきましょう!
One-Class SVM
SVM(サポートベクターマシン)はマージン最大化とカーネルトリックという2つのアプローチで対象を分類する強力な機械学習手法です。
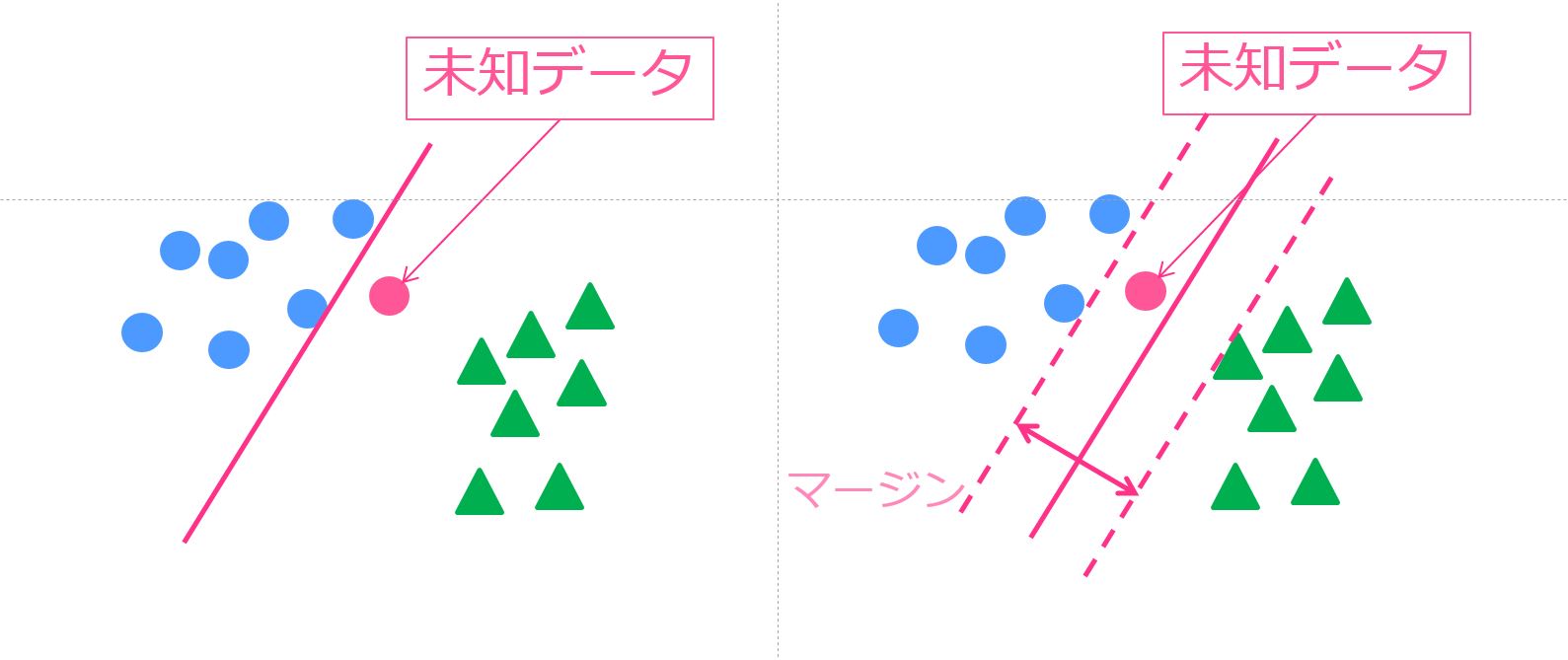
通常SVMは学習データに多クラスのラベルがついていて、それを元に学習して未知データがどのクラスに分類されるかを求めます。
一方で異常検知に使われるOne-Class SVMとはその名の通り1クラスの学習データを学習してそこから正常データの特徴空間を作り、そこに入らないデータは異常とみなします。
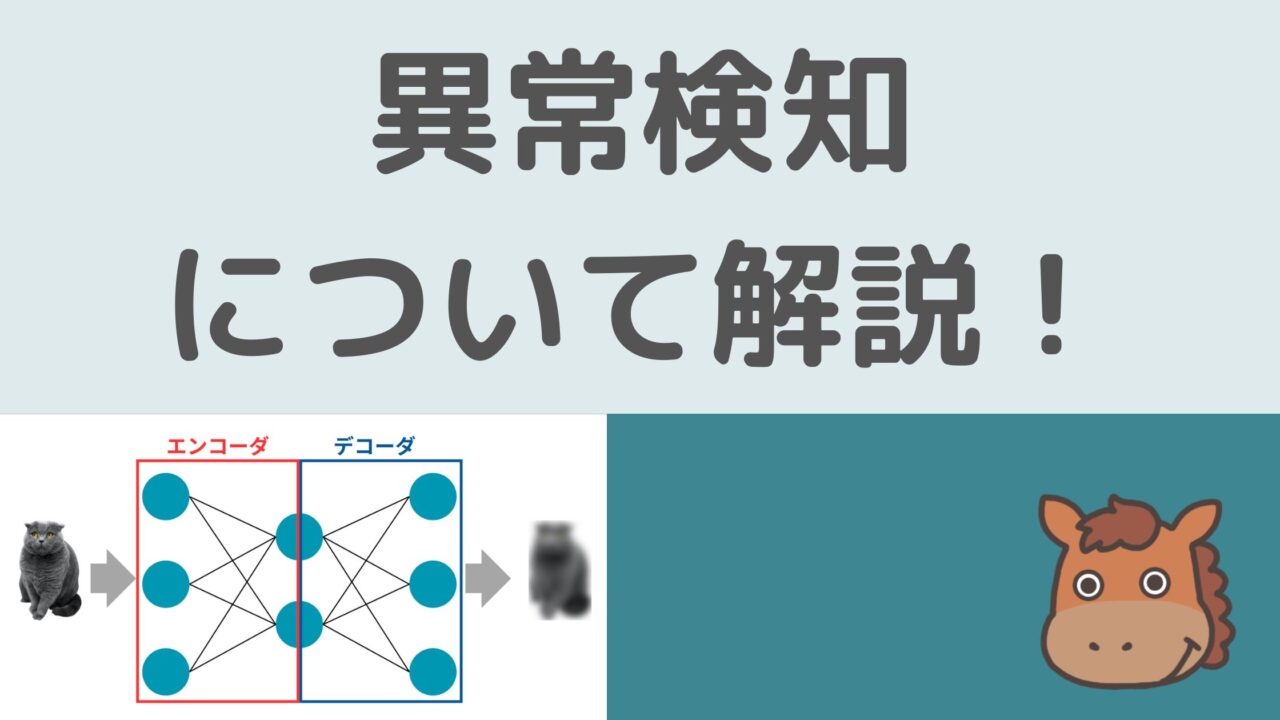
オートエンコーダ
オートエンコーダは2006年にディープラーニングの大家であるジェフリー・ヒントン氏が提案したアプローチです。
ジェフリー・ヒントン氏は2012年にAlexNetを使って画像認識コンペで2位に大差をつけて優勝し、AIブームを巻き起こした張本人です!
オートエンコーダとは、簡単に言うと
特定のインプットデータ(主に画像)の次元を一旦圧縮しそれらの次元を元に戻し、インプットとアウトプットの差分を小さくするようにニューラルネットワークを学習するアプローチ
です。
図にすると以下のようなイメージ。
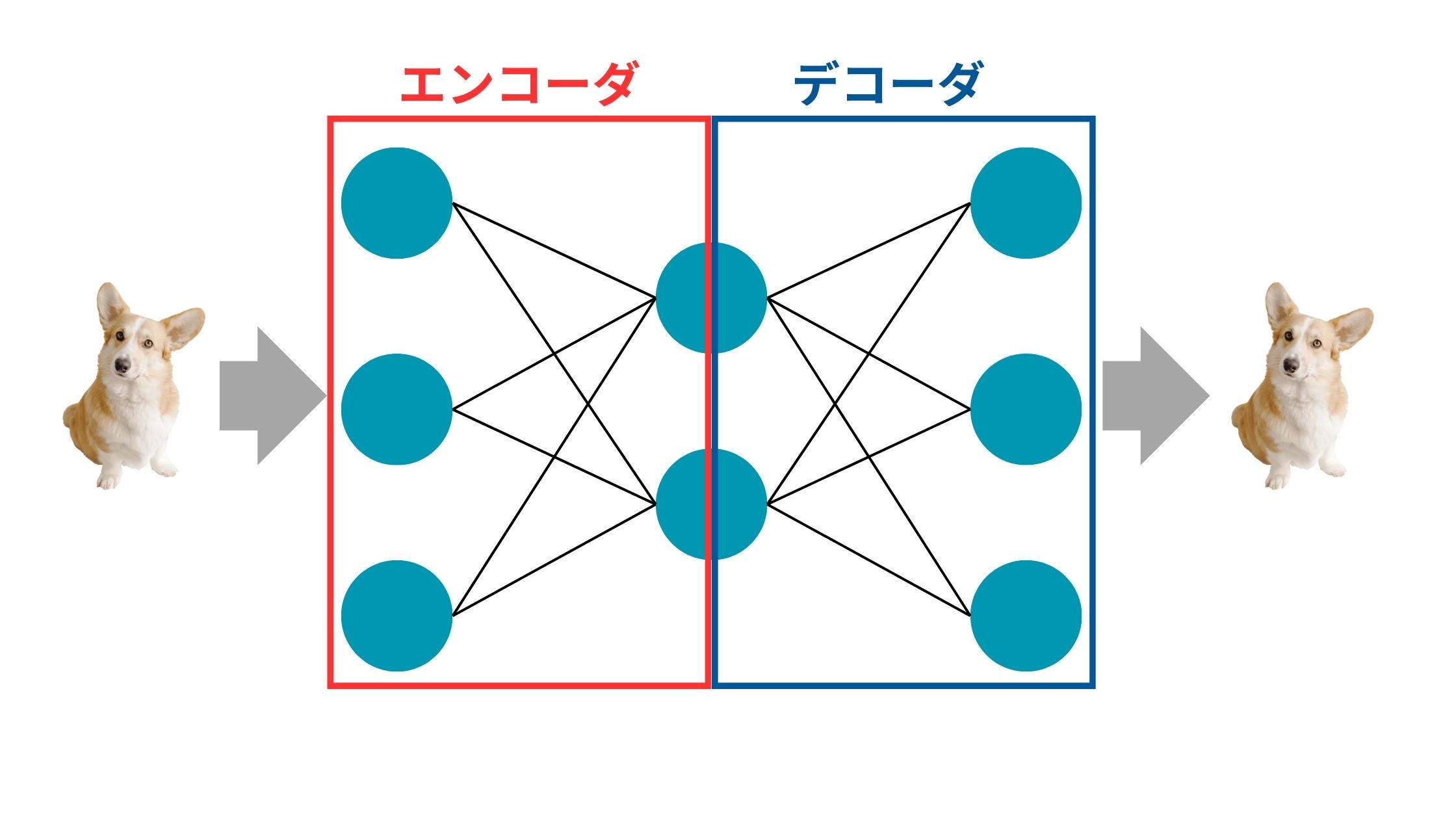
犬の画像を入れてあげて、それを次元圧縮して、それを元の次元に戻して元の画像に近い犬の画像をアウトプットします。
次元圧縮する部分をエンコーダ、圧縮された次元を元に戻す部分をデコーダを呼びます。
ここで犬の画像を元に学習したオートエンコーダのアーキテクチャに猫の画像を投入すると上手く復元できません。
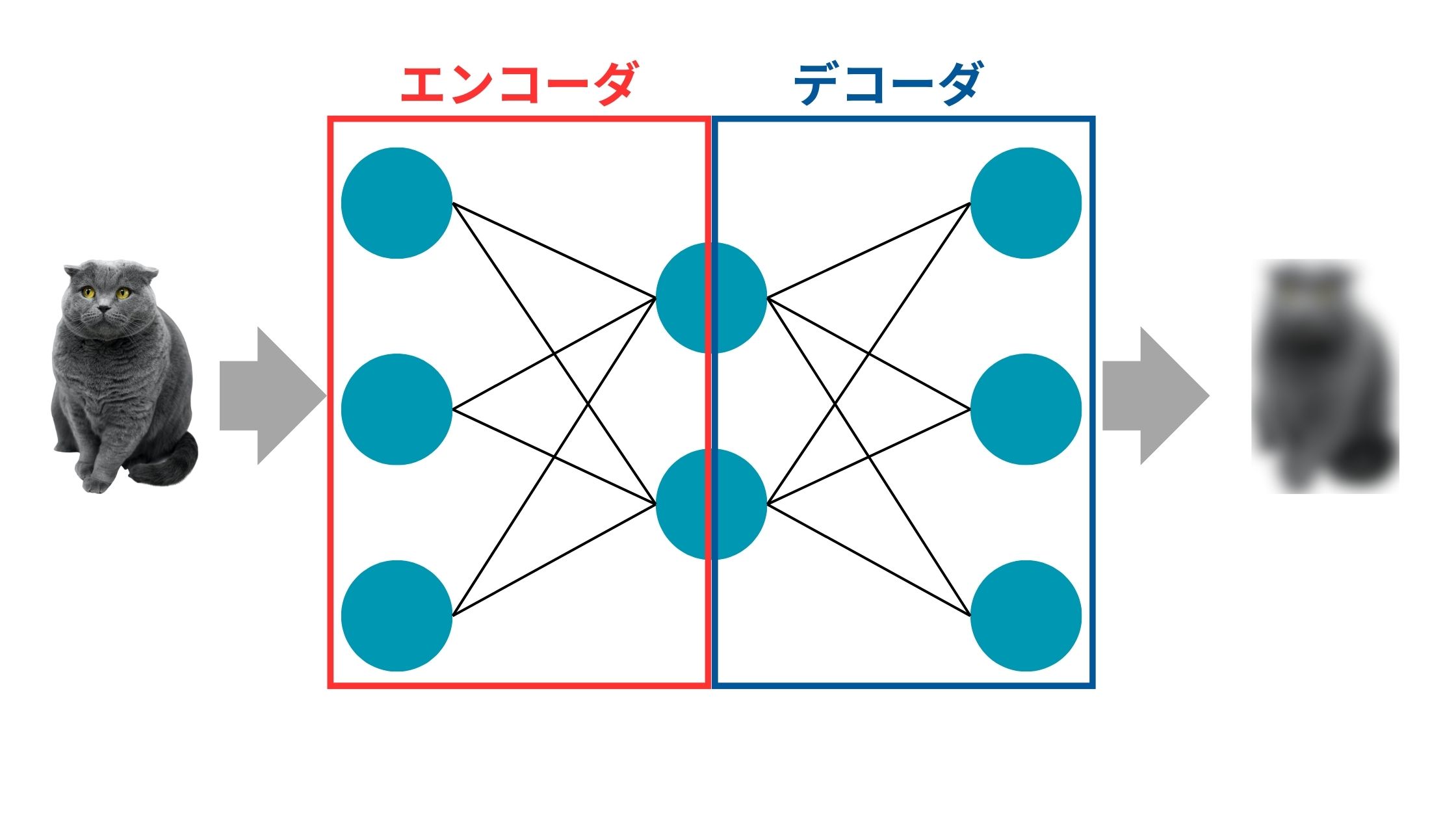
そのようなデータは異常データと判断できるってわけですね!
オートエンコーダに関しては以下の記事で解説していますのでチェックしてみてください!

Pythonで異常検知のアプローチを実装してみよう!
それでは実際に異常検知のアプローチとしてオートエンコーダを題材にPythonで実装してみましょう!
ディープラーニングを実装するためのライブラリであるKerasを使っていきます!
実行環境は特にこだわりがなければGoogle Colabをオススメします。
データセットはMnistという0~9の手書き文字のデータを使っていきます!
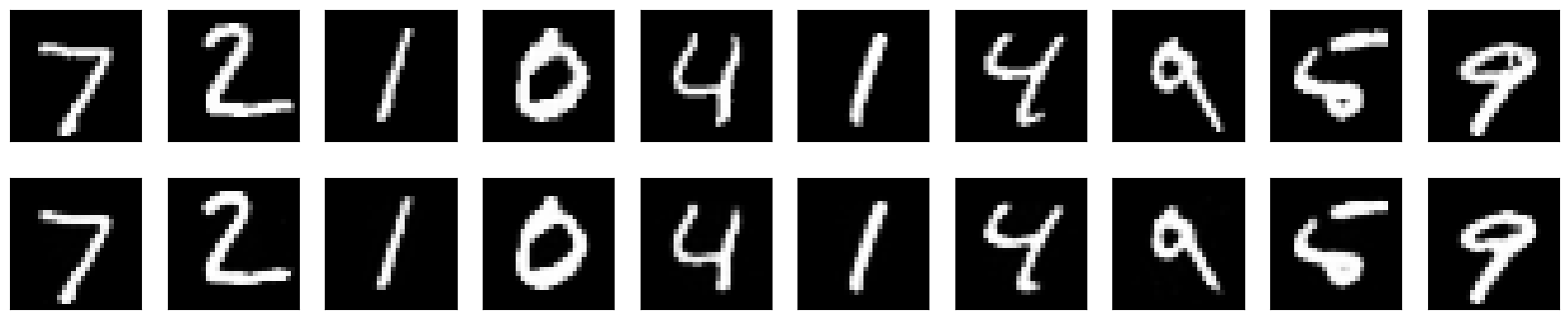
流れとしては、まずオートエンコーダで1の文字のみを使った学習を行いモデルを構築します。
そして出来上がったモデルに1の文字を投入して元の画像と再構築後の画像の差分を算出しそれを元に閾値を設定します。
そして、未知データ(0, 2, 3・・・とか)に対して「元の画像」と「再構築した後の画像」の差分を計算し、それが閾値以上であれば異常と判断するようなアプローチです。
では、早速コードを見ていきましょう!
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
# MNISTデータセットの読み込み
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 1から9の数字のみを選択
x_train = x_train[np.isin(y_train, [1,2,3,4,5,6,7,8,9])]
y_train = y_train[np.isin(y_train, [1,2,3,4,5,6,7,8,9])]
# データの前処理
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# 訓練データとバリデーションデータに分割
x_train, x_valid = train_test_split(x_train, test_size=0.2, random_state=42)
# オートエンコーダのモデルを定義
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input_img, decoded)
# モデルのコンパイル
autoencoder.compile(optimizer=Adam(), loss='binary_crossentropy')
# オートエンコーダの訓練
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_valid, x_valid))まず、ここまでで学習データと検証データの準備、そしてオートエンコーダモデルの構築をおこなっています。
ここから実際に閾値を算出していきます。
# バリデーションデータセットで再構成誤差の計算
decoded_imgs = autoencoder.predict(x_valid)
reconstruction_error_valid = np.mean(np.abs(x_valid - decoded_imgs), axis=1)
threshold = np.mean(reconstruction_error_valid) + np.std(reconstruction_error_valid)元の画像とオートエンコーダを使って再構成した画像の距離を計算し1標準偏差を足してそれを閾値と設定しています。
この閾値を超えた場合は異常とみなします。
それでは、実際にテストデータセットに含まれる0の文字列を投入してどうなるか見てみましょう!
# "0"の数字の画像をテストデータセットから選択
x_test_zero = x_test[y_test == 0]
# テストデータセットで再構成誤差の計算
decoded_imgs_test = autoencoder.predict(x_test_zero)
reconstruction_error_test = np.mean(np.abs(x_test_zero - decoded_imgs_test), axis=1)
# 異常検知
anomalies_test = reconstruction_error_test > threshold
sum(anomalies_test)/len(anomalies_test)1.0
結果は100%となり全て異常と判定されていることが分かります。
それでは一方で1の文字列を投入した場合はどうなるでしょうか?
# "1"の数字の画像をテストデータセットから選択
x_test_one = x_test[y_test == 1]
# テストデータセットで再構成誤差の計算
decoded_imgs_test = autoencoder.predict(x_test_one)
reconstruction_error_test = np.mean(np.abs(x_test_one - decoded_imgs_test), axis=1)
# 異常検知
anomalies_test = reconstruction_error_test > threshold
sum(anomalies_test)/len(anomalies_test)0.04933920704845815
結果は4.9%となり、ほとんど正常と判定されていることが分かります!
オートエンコーダを使うことで異常検知を行うことができました!
オートエンコーダの異常検知以外の使い方については以下の記事で解説していますのであわせてチェックしてみてください!
異常検知 まとめ

ここまでご覧いただきありがとうございました!
本記事では異常検知についてまとめてきました!
一口に異常検知と言っても本当に幅広い手法があるのが理解いただけたと思います!
異常検知は非常に重要な技術なのでぜひ理解して使えるようになっておきましょう!
また、さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















