
判別分析についてわかりやすく解説!Pythonで実装してみよう!


こんにちは!スタビジ編集部です!
多変量解析の一種である判別分析。
その名の通り、過去のデータを使って未知のデータを判別(分類)する手法です。
古典的でシンプルな手法ではありますが、様々な場で活用することができます!
この記事では、そんな判別分析の特徴とPythonでの実装を見ていきたいと思います。
以下のYoutube動画でも分かりやすく解説しているので併せてチェックしてみてください!
目次
判別分析とは

判別分析とは、過去のデータを使って未知のデータを分類する手法です。
具体的には、過去データからグループの境界線を求め、その線を元に未知データを分類していきます。

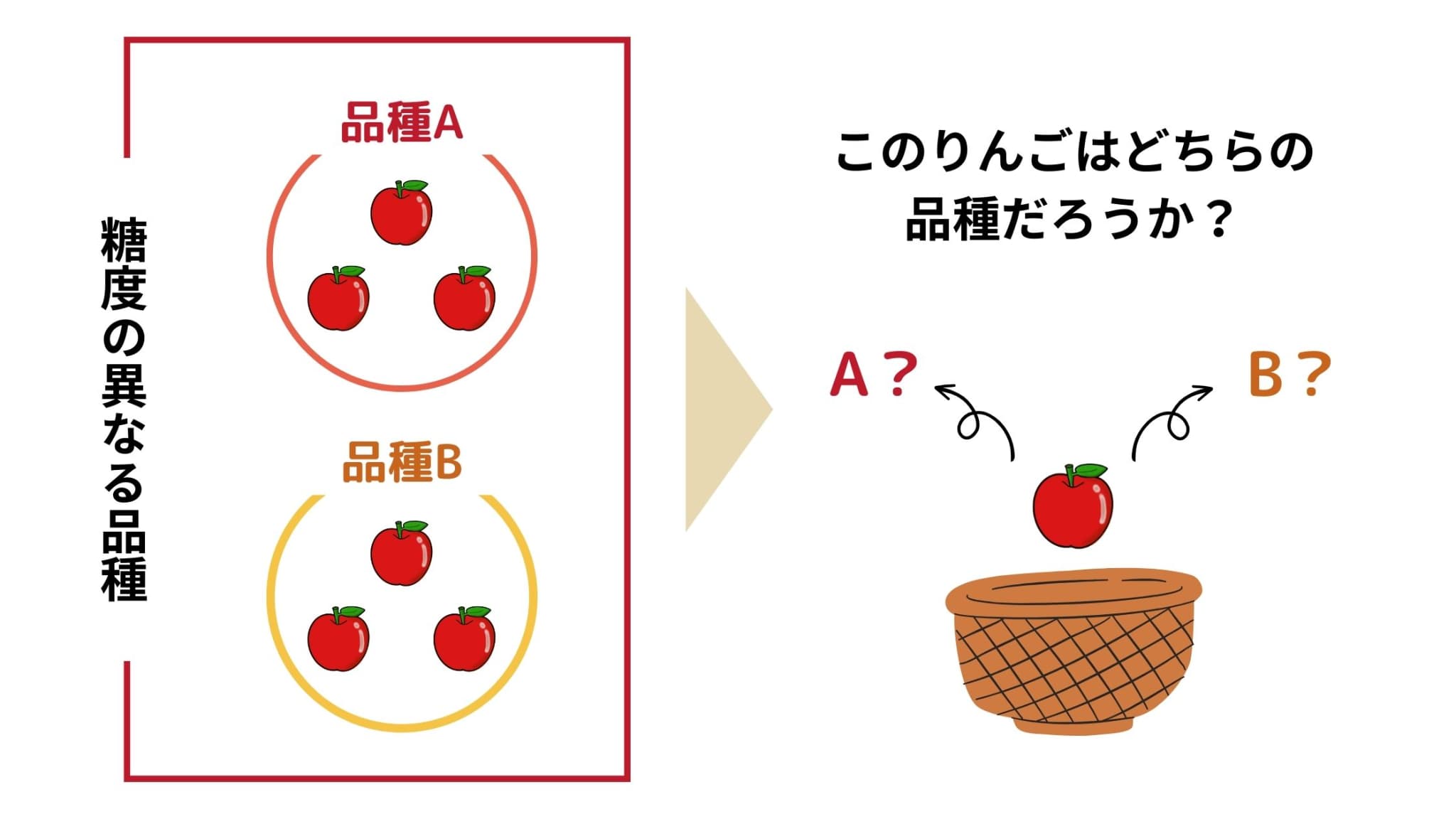
あるりんご農家が、A、Bという2種類のりんご(母集団A、母集団Bとする)を栽培しています。
また、その2種類のりんごは見た目に全く差はないが、糖度(\(x\))が異なる品種(Aの母平均\(\mu_{A}\)、Bの母平均\(\mu_{B}\))であるとします。
そして、かごの底に残っていた1つのりんご(未知りんごとする)がどちらの品種かを判別したい状況にあるとしましょう。
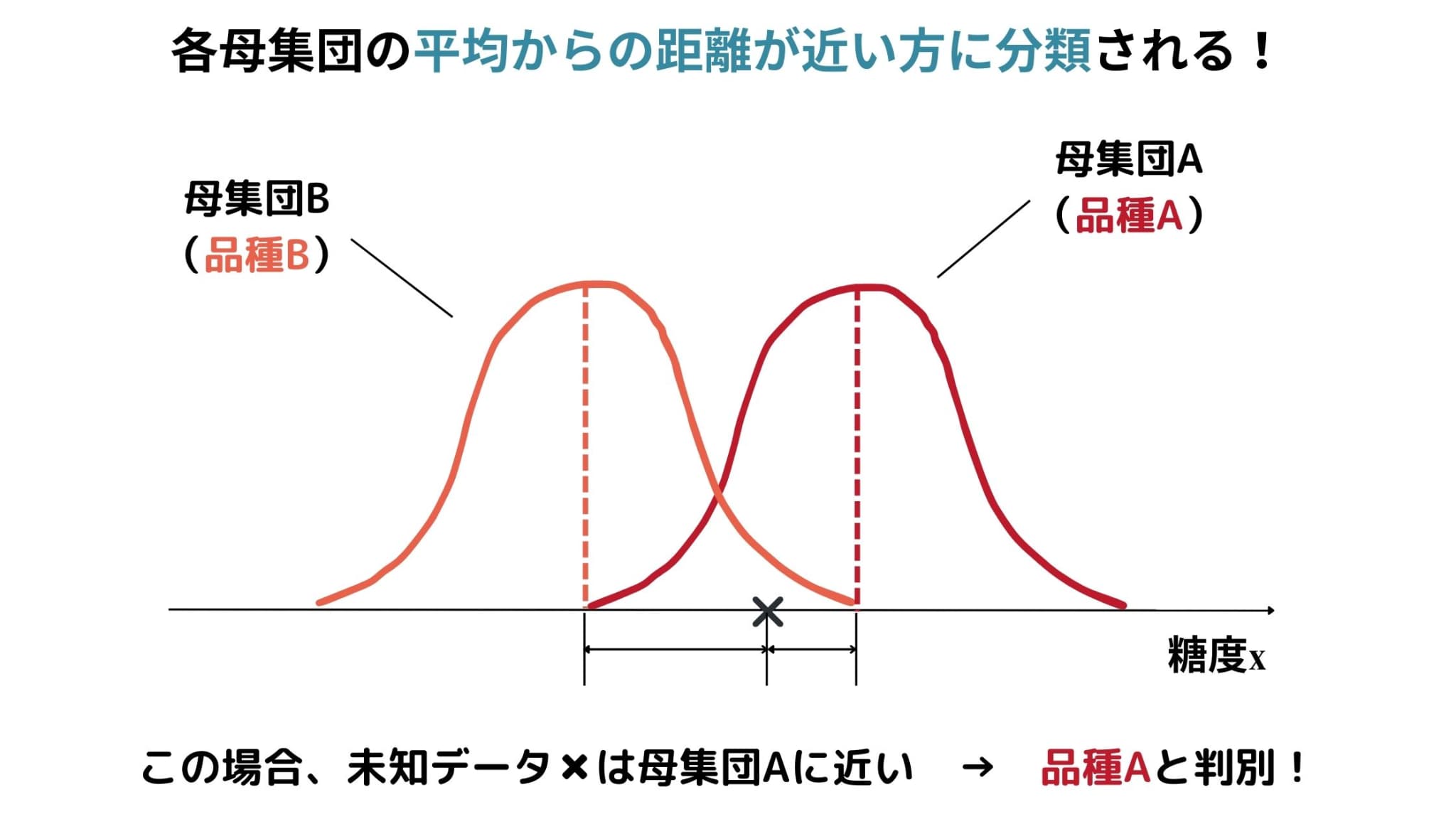
そこでまず、りんごの糖度からそれぞれの母集団への距離として、マハラノビス距離の2乗を次のように定義します(\(\sigma^2\)は母分散で、母集団AとBで同じとする)。
\(\displaystyle D_{A}^2= \frac{(x-\mu_{A})^2}{\sigma^2}\), \(\displaystyle D_{B}^2= \frac{(x-\mu_{B})^2}{\sigma^2}\)
すると、以下のように判別ルールを定めることができるわけです。
\(D_{A}^2\leq D_{B}^2 \iff\) 母集団Aに属する \(\iff\) 品種Aのりんごである
\(D_{A}^2> D_{B}^2 \iff\) 母集団Bに属する \(\iff\) 品種Bのりんごである
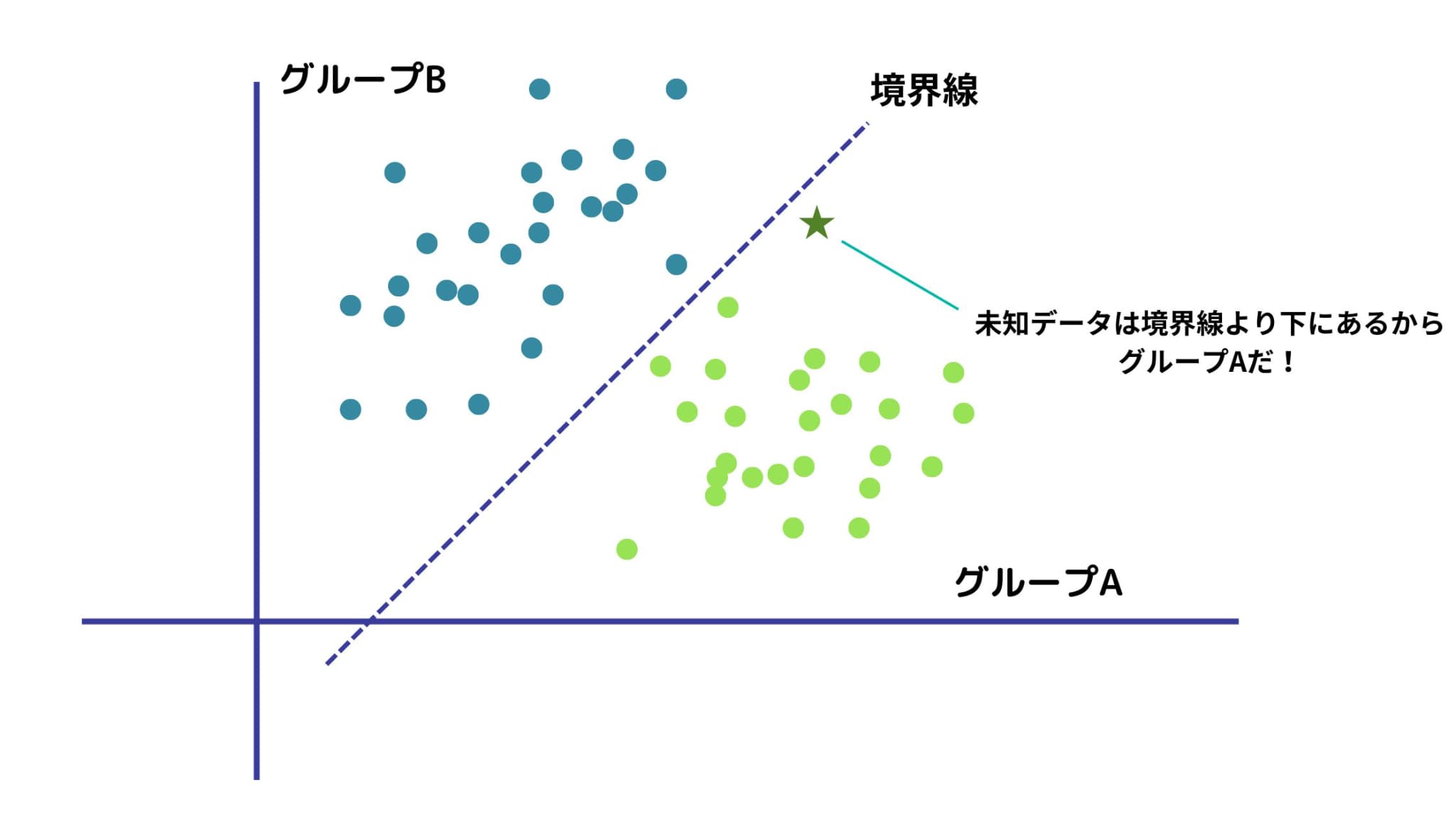
イメージはこんな感じ。
また、上で定義したマハラノビス距離の2乗の値の差は
\(\displaystyle D_{B}^2 – D_{A}^2 = \frac{2(\mu_{A}-\mu_{B})}{\sigma^2}\left(x – \frac{\mu_{A}+\mu_{B}}{2}\right)\)
と表すことができ、これを2で割った、
\(\displaystyle z = \frac{D_{B}^2 – D_{A}^2}{2} = \frac{(\mu_{A}-\mu_{B})}{\sigma^2}\left(x – \frac{\mu_{A}+\mu_{B}}{2}\right)\)
を判別関数と呼びます。
この判別関数が、判別分析における境界線となるわけです。
判別関数を用いると、先ほどの判別ルールも以下のように書き換えることができます。
\(z\geq 0\iff D_{A}^2\leq D_{B}^2 \iff\) 母集団Aに属する \(\iff\) 品種Aのりんごである
\(z<0\iff D_{A}^2> D_{B}^2 \iff\) 母集団Bに属する \(\iff\) 品種Bのりんごである
なお、\(\mu_{A}\)や\(\mu_{B}\)、\(\sigma^2\)は未知の値なので、過去のデータから推定します。
そして、その推定値とサンプルの値(未知りんごの糖度)を判別関数に代入して得られた値を基に、判別を行っていきます。
今回は糖度という一つの変数で判別することを考えていきましたが、複数の変数が観測されている場合も同様に考えていくことができます。
判別分析のメリット

判別分析のメリットは主に2つあります。
1. サンプルサイズの大小が精度に影響を与えにくい
上で説明したように、判別分析の理論はかなりシンプルなものです。
そのため、少ないデータしか手元にない場合に精度がガクッと落ちる、といったことは起こりにくいです。
最新の機械学習手法などに対して精度の面ではやや劣るかもしれませんが、少ないサンプルでも予測ができるというのは大きなメリットの1つです。
2. 多クラスの場合でも予測が可能
判別分析は、目的変数が多クラスの場合でも同様に予測を行うことができます。
2クラス分類のみしかできないという分析手法もいくつかある中、これだけシンプルな理論のもとで多クラス予測を行うことができるのは立派なメリットであると言えます。
判別分析を行う際の注意点

判別分析を行う際、注意しなければならないことがあります。
それは、目的変数が質的変数(カテゴリ変数)の場合のみ適用できるということです。
予測の対象が量的変数の場合は、重回帰分析などを用いるようにしましょう。

判別分析の活用例

ここでは2つの分野での活用例を紹介していきます。
1. マーケティング
よく判別分析が用いられるのがマーケティング関連のデータ。
以下のような場面で適用することができます。
・アンケートデータを用いた顧客の満足度予測(満足・不満足)
・顧客情報データを用いた商品購買予測(購入する・しない)
・財務諸表データを用いた企業の倒産予測(倒産する・しない)
さらに予測だけでなく、予測にどの変数が効いているのかも把握できるので、マーケティング戦略を立てるのにも役立ちます。
マーケティングに関しては以下の記事で解説していますので参考にしてみてください!

2. 医療
判別分析は医療分野でも用いられることが多いです。
・検査結果データを用いた病気の有無の予測(ある・ない)
・生活習慣データを用いた発がん可能性予測(発がんする・しない)
・脳画像データを用いた統合失調症患者の判別(患者・健常者)
医療分野では大量のデータを集めることが難しいケースが多いため、小サンプルでも精度が比較的変わりにくい判別分析が重宝されます。
判別分析をPythonでやってみよう

ここからは、Pythonで実際に判別分析をやっていきます。
分析の目的は、未知データの予測を行うこと!
以下の流れで分析を進めていきます。
1. ライブラリのインストール
2. データの準備
3. データの加工
4. 判別分析の実行
5. 予測結果の評価
1. ライブラリのインストール
今回はscikit-learnのLinearDiscriminantAnalysis(LDA)を使って判別分析を行っていきます。
分析で使用する他のモジュール等もここで全てimportしておきます。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.metrics import acccuracy_score, recall_score, precision_score,f1_score2. データの準備
データはscikit-learnが提供しているワインデータを使用します。
#ワインデータセットの読み込み
df = datasets.load_wine(as_frame=True).frame
df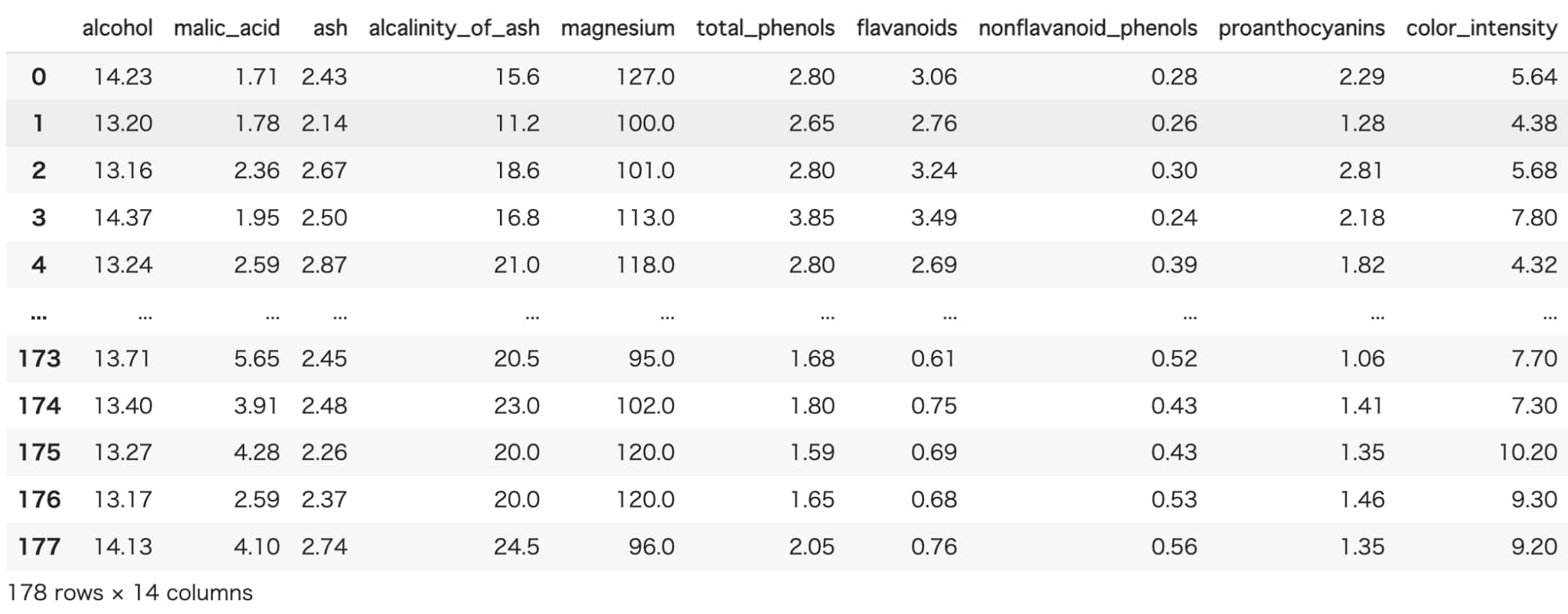
アルコール濃度やリンゴ酸濃度、ワインの種類など計14変数のデータセットとなっています。
目的変数をワインの種類、説明変数をその他の変数として判別分析を行っていきます。
サンプルサイズは178です。
3. データの加工
今回の目的は未知データの予測のため、既存のデータセットを訓練データとテストデータ(未知データとして用いる)に分割します。
比率は、訓練データ:テストデータ = 7:3です。
#訓練データとテストデータに分ける
x, y = df.iloc[:, :-1].values, df.iloc[:, -1].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, stratify=y) #訓練データ:テストデータ = 7:3で分割4. 判別分析の実行
訓練データを用いて判別関数(モデル)を作成し、テストデータの予測を行います。
#判別分析の実行
#訓練データを用いて判別関数を作成
LDA = LinearDiscriminantAnalysis()
LDA.fit(x_train, y_train)
#テストデータの予測
y_pred = LDA.predict(x_test)
print(y_pred)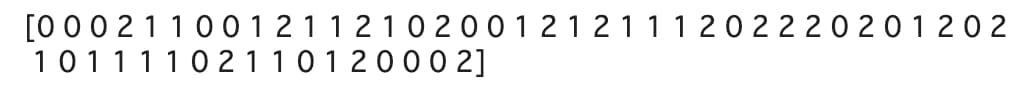
y_predに、ワインの種類を予測した結果(0,1,2)が格納されていることがわかります。
5. 予測結果の評価
最後に、予測結果の評価を行います。
正解率、適合率、再現率、f1(F値)の4つで評価を行います。

#評価指標の算出
print("Accuracy:",accuracy_score(y_test,y_pred))
print("Recall:",recall_score(y_test,y_pred,average='macro'))
print("Presicion:",precision_score(y_test,y_pred,average='macro'))
print("F-measure:",f1_score(y_test,y_pred,average='macro'))
どの評価指標も1に近く、とても高い精度で予測を行うことができていますね。
余裕のある方は、判別関数の偏回帰係数の値から「どの変数が予測に影響を与えているか」を考察してみましょう!
まとめ
ここまでご覧いただきありがとうございました!
本記事では、判別分析の概要からPythonでの実装方法まで解説していきました。
判別分析は、様々な場で活用することのできる手法です。
未知データを分類することはもちろん、手法の理論を知っておくことで他の分類手法の理解が容易になります。
複数の変数が観測されているデータが手元にあり、分類を行いたい場合は積極的に判別分析を行っていきましょう!
また、今回分析に用いたPythonについて勉強したい方は以下の記事を参考にしてみてください!

さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















