
混同行列と評価指標についてわかりやすく解説!Pythonでの実装も!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
今回は混同行列について解説していきます。混同行列とは2値分類問題や多値分類問題で用いられる行列であり、混同行列から様々な評価指標を計算することができるため、分類問題には必須な要素です。
そもそも分類問題でもAccuracy(精度)のみで評価してはいけないのか?と思う方もいるでしょう。場合によりますが、Accuracyのみだとモデルの評価を間違った方向にしてしまう可能性があります。この問題についても解説していきます!
この記事では、そんな混同行列の定義と評価指標について解説していきながらPythonで実装していきます!
・混同行列の定義について解説!
・評価指標の性質について解説!
・Pythonで混同行列を見てみよう!
目次
混同行列について解説!

それでは早速、混同行列と評価指標について一気に解説していきます!
まず混同行列とは「元の教師ラベルと予測結果の2つを表した行列」と定義されています。
教師ラベルは元からサンプルについているラベル(正常・異常)を指します.そして予測結果はデータから推定されたラベル(正常・異常)を指します.したがって混同行列は2×2の行列を示していることが分かりますね!
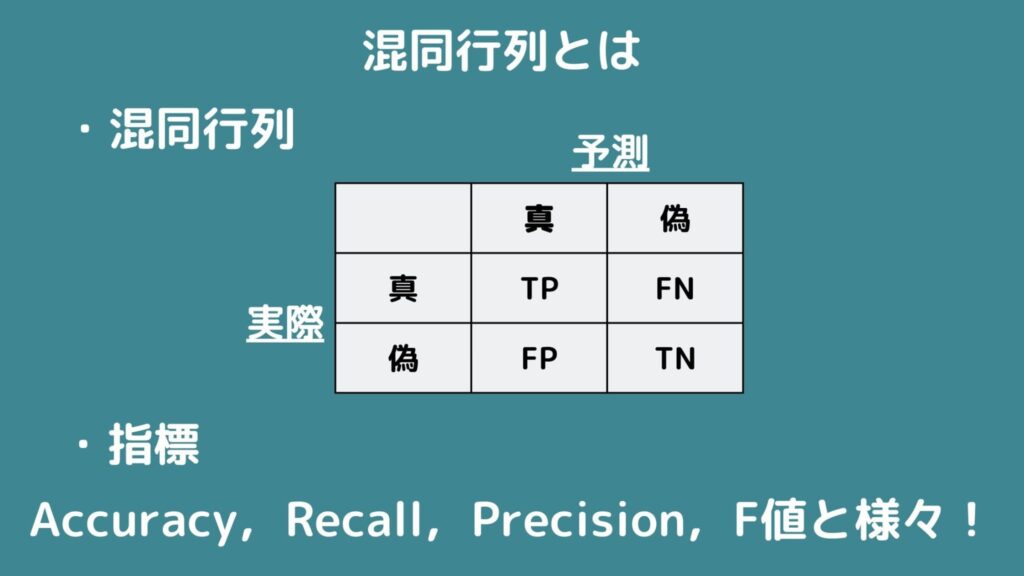

評価指標について解説!

次に評価指標を解説していきます!混同行列における評価指標は大まかに4つあると考えてください。
1. Accuracy(精度)
Accuracy(精度)とは「全データのうち、どれだけ予測が合っていたか」を示しています!一般的に用いられている指標としてはこちらが挙げられますね!
\(Accuracy = \frac{TP+FN}{TP+TN+FN+FP}\)
2. Recall(再現率)
Recall(再現率)は「Positiveな実データのうち、どれだけPositiveと予測できたか」を示しています!「どれだけPositiveな実データを「再現」してるか」と覚えると良いでしょう!
\(Recall = \frac{TP}{TP+FN}\)
3. Precision(適合率)
Precision(適合率)は「Positiveと予測できたデータのうち、実際にPositiveなデータはどれだけあるか」を示しています!「Positiveと予測したデータがどれだけPositiveなデータと適合しているか」と覚えると良いでしょう!
\(Precision = \frac{TP}{TP+FP}\)
4. F値
F値とは「Recallとprecisionの調和平均」を示しています!RecallとPrecisionはトレードオフの関係性にあります。つまりRecallが上がるとPrecisionは下がり、逆も然りです!したがってRecallとPrecisionを偏らせないで評価したい場合はF値を使います!
\(F-measure = \frac{2×Presicion×Recall}{Precision+Recall}\)
評価指標に関しては以下の記事でも詳しく解説していますのでチェックしてみてください!

そもそも何故、混同行列が必要なのか?

例えば犬10匹と猫100匹を分類する問題を考えてみましょう!データを収集し、モデルに学習させたところ、次のようになったと考えます。犬は10匹猫と予測されましたが、猫は100匹猫と予測できました!
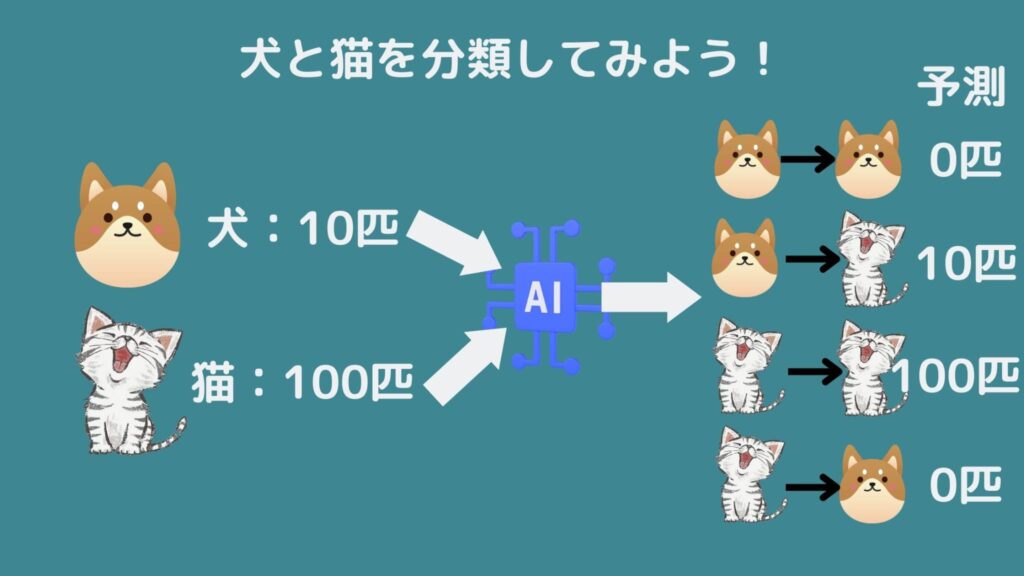
さて、この予測モデルをAccuracyで評価してみましょう!
\(Accuracy = \frac{0+100}{0+100+0+10}=0.90…\)
素晴らしい予測精度が出ました!予測精度が約90%なので、このモデルはきっと良いモデルです…とはならないのです。
このモデルは猫の予測には役に立つでしょうが、犬の予測には全く役に立たないことが分かりますね.何故なら犬をきちんと予測した数は0なのですから!
実際に犬を正解とした場合のRecallとPrecisionを計算すると、TP=0なのでどちらも0になります!これはデータが偏っていることを示していることが考えられますね!
このようにPositive, Negativeの数が偏っている場合にAccracyで評価してしまうと、間違った方向に結論付ける危険性があります!したがって問題に適した評価指標を使うことが重要です!
また「犬を犬と予測した数」を5になったとしましょう!そうするとRecall、Precisionは\(Recall = 5/(5+5)=0.5, Precision=5/(5+0)=5\)となり、犬に対する予測精度がある程度改善されていることが確認できました!
混同行列をPythonで実装!

それでは実際に混同行列と評価指標をPythonで実装しましょう!
混同行列はsklearn.metricsのconfusion_matrix関数、各評価指標はsklearn.metricsから実装できます!このときヒートマップを使って混同行列を表すと見やすいと思います!
import numpy as np
import seaborn as sns
from sklearn.metrics import confusion_matrix, accuracy_score, recall_score, precision_score,f1_score
y_true = [0,0,0,0,0,
0,1,0,1,0,
1,0,1,0,1,
1,1,1,1,1]
y_pred = [0, 1, 0, 1, 0,
1, 1, 1, 1, 1,
0, 1, 0, 1, 0,
1, 0, 1, 0, 1]
cm = confusion_matrix(y_true,y_pred)
sns.heatmap(cm)
print("Accuracy:",accuracy_score(y_true,y_pred))
print("Recall:",recall_score(y_true,y_pred))
print("Presicion:",precision_score(y_true,y_pred))
print("F-measure:",f1_score(y_true,y_pred))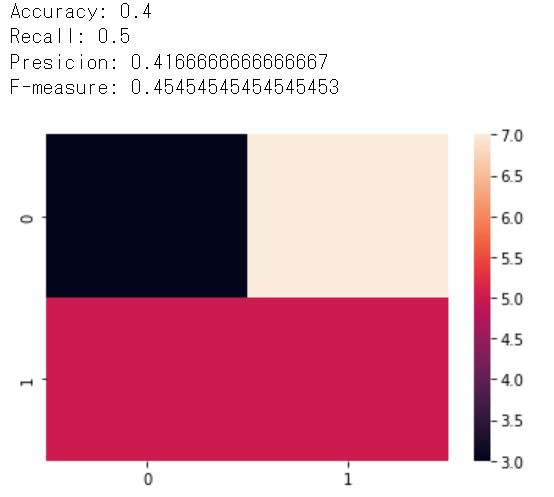
混同行列と評価指標 まとめ

ここまでご覧いただきありがとうございました!
本記事では混同行列と分類問題の評価指標についてまとめました!
分類問題では混同行列に基づいてROC曲線・AUCといった指標を用いることがあります。この指標もモデルを評価するうえで非常に重要な概念となりますので、ぜひスタビジで学びましょう!
このようなデータサイエンスの力を身に付けるためにはスタビジの記事やスクールを活用すると良いでしょう。
そして僕の経験を詰め込んだデータサイエンス特化のスクール「スタアカ(スタビジアカデミー)」を運営していますので,興味のある方はぜひチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解などもあわせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
データサイエンスに関する記事はこちら!


データサイエンスを勉強できるスクールやサイトは、ぜひこちらを参考にしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















