
【入門】ローカルLLMって何?概要と使い方を徹底解説!


ローカルLLMのメリット・デメリットから実際の使い方まで紹介します!この記事を読んで“自分専用のChatGPT”を立ち上げてみましょう!
こんにちは!スタビジ編集部です!
近年、大規模言語モデル(LLM)の進化により、”ChatGPT“などの高性能な生成AIが一気に身近になりました。
ところが、これらの生成AIはほとんどがクラウド上のサービスなので、機密情報の取り扱いに不安があったり、自由にモデルをカスタマイズしにくいという課題があります。
そこで今回はクラウドに頼らず自分のPCだけで大規模言語モデル(LLM)を動かす”ローカルLLM“について解説していきます。


本記事では、上記のような疑問を解決していきます!
・ローカルLLMとは?
・ローカルLLMの導入方法
・ローカルLLMを使ったアプリ開発
より詳しくローカルLLMの実装方法について知りたい!という方は以下のUdemyの講座で詳しく解説していますのでぜひチェックしてみてください!
【初心者向け】ローカルLLMを使ってRAGを導入したチャットアプリを作ろう!いくら使っても無料のAI環境を手に入れよう!
| 【時間】 | 3時間 |
|---|---|
| 【レベル】 | 初級 |
自分のPCでLLMを実装して無料で動かす環境を手に入れたいならこのコース!
今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
AIサービスと外部データを繋ぐ際はMCPサーバーを利用するのがオススメです。詳しくは以下の記事をチェックしてみて下さい。

目次
ローカルLLMとは
まずは「ローカルLLMとは?」について、概要を見ていきましょう。
以下のYouTube動画でも解説していますので、あわせてチェックしてみてください。
“ローカルLLM(Local Large Language Model)“とは、モデル本体(学習済みパラメータ)を自身のPCや社内サーバーに置き、その中で推論を完結させる仕組みのことです。
クラウド版ChatGPTなどとは違い、「入力 → 推論 → 出力」のすべてが手元で完結するため、外部のサーバーに一切データを送らずにLLMを利用できます。
| 推論の流れ | クラウド LLM | ローカル LLM |
|---|---|---|
| ① プロンプト入力 | ブラウザ → OpenAI等のAPI | ターミナル/GUI → 自分のPC |
| ② 推論(計算) | データセンターのGPU | 手元のGPU/CPU |
| ③ 生成テキスト返却 | インターネット経由 | LAN 内・オフライン |
LLMについては以下の記事で詳しく解説しているので参考にしてみて下さい。
ローカルLLMのメリット
「ローカルLLMのメリット」を見ていきましょう。
ローカルLLMの主なメリットは以下のとおりです。
- セキュリティが高い:自身のPCで完結するため、入力データやモデルが外部に漏れない
- コストがかからない:クラウドLLMの利用時に発生するコスト(トークン数や利用プランなど)がかからない
- カスタマイズ性が高い:モデルを自分仕様に学習し直したり、軽量化したり、カスタマイズ可能
これらのメリットを活かして、ローカルLLMでは以下のような場面で利用されます。
| 利用方法 | 利用シーン | ローカルLLMを使う理由 | |
|---|---|---|---|
| 1 | 社内ナレッジ+RAGチャットボット | 社員ハンドブックや過去問い合わせを検索して回答 | 社内独自PDF・Wikiをローカルに格納・情報漏えいリスクを最小化 |
| 2 | オフラインの現場支援 | 工場ライン・船舶・災害現場でのFAQボットやマニュアル検索 | インターネットが無い環境でも GPU/CPUだけで応答可能 |
| 3 | 開発者向けコード補完/レビュー | VS Code拡張やCIでコード説明・テスト生成 | ソースコードを外部に出さず大量トークンでも従量課金ゼロ |
ローカルLLMのデメリット
続いて「ローカルLLMのデメリット」も見ていきましょう。
ローカルLLMのデメリットは主に下記です。
- 高性能のパソコンが必要:GPUやメモリが少ないと動かないもしくは動いても遅い場合がある
- ハードウェアの限界:GPUを回しっぱなしにするとPCが熱くなり、電気代も多くかかる、また、LLMの並列処理対応が専門知識が必要で難しい
- アップデートやトラブル対応が自己責任:新しいモデルの取り込み、セキュリティ設定、バックアップなどの保守・運用はは自身で対応する必要がある
また、デメリットではありませんがローカルLLMを利用する上で以下の点も注意しましょう。
- モデルは正しいライセンスで利用する:ローカルLLMで利用する元のLLMのライセンスが『商用利用可能か』『再配布禁止でないか』を確認
- GPU温度と電力を監視する:長時間推論は高温になりやすいので、稼働状況を監視して、PCが故障しないようにチェック
ローカルLLMの導入方法
ここでは「ローカルLLMを自身のPCに導入する方法」について見ていきます。
ローカルLLMを導入する方法は以下のパターンがあります。
- ソースから直接ビルド:Githubリポジトリ(llama.cppやvllm等)をクローンし、自身でビルド
- Dockerなどのコンテナイメージをデプロイ:LLMサーバーが入った完成済みのコンテナイメージをデプロイする
- LLMアプリをインストール:LM StudioやOllamaといったLLM用のアプリをインストールして利用する
- Pythonライブラリから直接呼び出す:Hugging FaceなどのライブラリをPythonで呼び出してプログラム内で実行する
ソースファイルからビルドしたりコンテナイメージをデプロイしたりする方法は自由度が高い一方で、コードの詳細まで理解する必要があります。
アプリをインストールしたりライブラリを呼び出す方法は、手軽にLLMを試せる一方、細かい設定まではできない場合があります。
今回は”Ollama“を使ったローカルLLMの導入方法を見ていきます。
Ollamaのインストール
“Ollama“とはLLMをダウンロード・起動・API 公開まで一気通貫で実行できるアプリです。
Ollamaをインストールすることでローカル環境で簡単にLLMを利用することが出来ます。
Ollamaは”ダウンロードページ“から実行ファイルをダウンロードします。
ダウンロードした実行ファイルを実行することでインストールできます。
OllamaはCLIツールのため、ターミナルで下記コマンドを実行して結果が返ってくればインストールされています。
ollama --version本記事では”client version is 0.9.0″を利用します。
Ollamaを使ってLLMを動かしてみる
実際に「Ollamaを使ってLLMを動かす」ことをやっていきましょう。
次の順序でLLMを動かします。
- モデルのインストール
- Ollamaサーバーの起動
- プログラムからモデルを実行
① モデルのインストール
自身のPCでLLMを実行するため、Ollamaのレジストリからモデルをインストールします。
モデルの一覧はOllamaの”公式ページ“か”Github“で確認できます。
# ollama pull <モデル名>
ollama pull llama3.1:8b上記コマンドでモデルをインストールできます。
単純にLLMを使ってテキスト推論をしたい時は、下記コマンドを実行します。
# ollama run <モデル名>
ollama run llama3.1:8b上記コマンドではモデルがインストールされていない時は自動でインストールも行ってくれます。
コマンド実行後、対話モード(インタラクティブモード)になり、質問をしたり要約を依頼したりすることが出来ます。
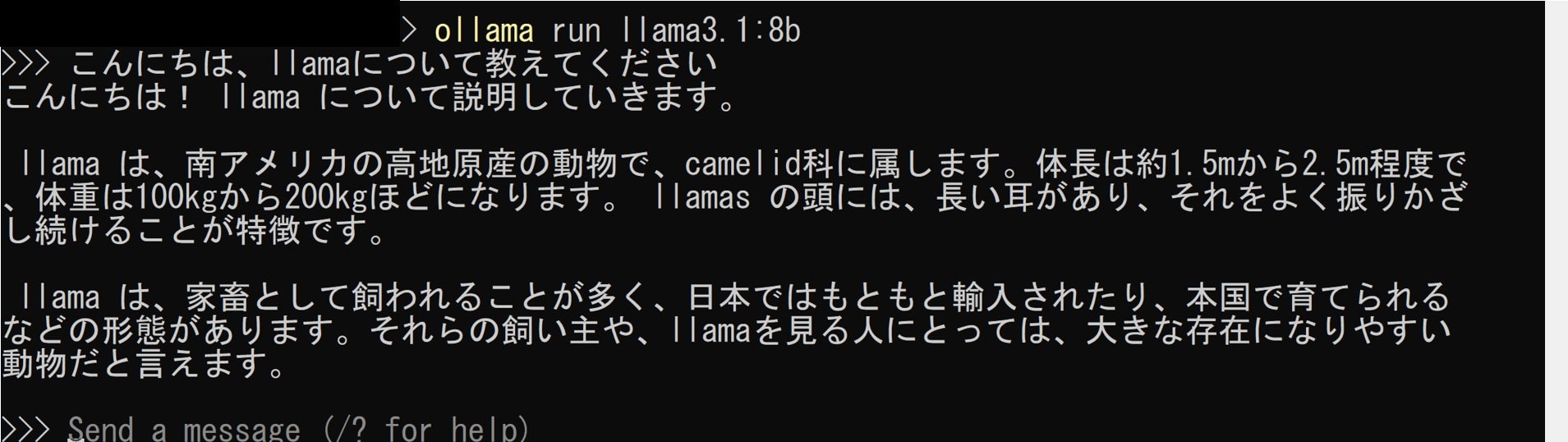
また、下記オプションを設定することも可能です。
| 主なオプション | 役割 | 例 |
|---|---|---|
-p, --prompt | 一度に渡すユーザープロンプト | -p "要約してください" |
--system | システムプロンプトで役割固定 | --system |
--temperature | 出力のランダム性 | --temperature 0.2 |
モデルを終了する際は「Ctrl + d」 or 「/bye」を入力することで終了できます。
② Ollamaサーバーの起動
自身のPCでインストールしたLLMをアプリから呼び出したい場合、Ollamaサーバーとして起動します。
起動コマンドは下記です。
ollama serveただ、PCによっては下記のようなエラーメッセージが出る場合があります。
Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.これは、ollamaのプロセスがデフォルトで”11434″番ポートを利用するのですが、そのポートが利用できないため、エラーになっています。
その場合、下記コマンドでollamaのプロセスのポートを別の番号に変更しましょう。
# Windows
$env:OLLAMA_HOST="127.0.0.1:12000"
# macOS/Linux
OLLAMA_HOST=127.0.0.1:12000 ollama serve上記は一時的な対応なので、実行のたびに設定が必要になります。恒久的にPC設定で環境変数を直接変更してもよいです。
サーバーの起動の確認は下記コマンドで出来ます。
curl http://localhost:12000/v1/modelsStatusCodeが”200″で返ってくれば、サーバーは起動できています。
③ プログラムからモデルを実行
自身のPCのプログラムからインストールしたモデルを実行します。
呼び出し方法は普段クラウドのLLMのAPIを呼び出す方法と同じになります。
from openai import OpenAI
client = OpenAI(
api_key="ollama", # ←任意の文字列でOK
base_url="http://localhost:12000/v1" # ←ローカルのollamaサーバーを指定
)
response = client.chat.completions.create(
model="llama3.1:8b",
messages=[{"role": "user", "content": "こんにちは、LLMについて教えて"}],
)
print(response.choices[0].message.content)違いとしてはAPIの宛先が②で起動したサーバーになることです。
プログラムを実行するとちゃんと答えが返ってくることを確認できます。

自分の環境で動かすからToken数とかコストを気にせず実行できる!
※上記モデル(llama3.1:8b)ではメモリを6GBほど使います。足りない場合は軽量モデルをインストールしてください。
ローカルLLMを使ったアプリ開発
最後にローカルLLMを使って、自分なりのチャットアプリを作っていきます。
以下の機能を実装します。
・個人情報のテキスト情報を元に回答する
・StreamlitでWebアプリとして実行
RAG機能を搭載したチャットアプリを作っていきます。
RAGについては以下の記事で詳しく解説しているので、参考にしてみて下さい。

インデックス作成
まずは回答の元になるインデックスを作成していきます。
import faiss
import pickle
from sentence_transformers import SentenceTransformer
texts = [
"私の名前はうまたんです。",
"私は32歳でジョージアに住んでいます。仕事はプログラマーで、Pythonを使ったデータ分析や自動化が得意です。",
"趣味はアニメ鑑賞とブログ運営です。自分のブログではPythonやAI関連の情報を分かりやすく発信しています。",
"最近、ローカルLLMに興味があり、自分のPCで大規模言語モデルを動かすことを試しています。",
"好きな食べ物はラーメンと寿司で、特に週末は美味しいラーメン屋を探すことが楽しみです。",
"ブログのURLは「https://toukei-lab.com」で、主に初心者にも理解しやすいAIやPython活用法の記事を書いています。"
]
embedder = SentenceTransformer("all-MiniLM-L6-v2")
vecs = embedder.encode(texts)
index = faiss.IndexFlatL2(vecs.shape[1])
index.add(vecs)
pickle.dump((index, texts), open("personal_faiss.pkl", "wb"))上記のPythonプログラムを実行すると”personal_faiss.pkl”ファイルが作成されます。
Webアプリを実行
Webアプリは”Streamlit“を使って作っていきます。
Streamlitについては以下の記事で詳しく解説しているので、参考にしてみて下さい。

import os
import pickle
import faiss
import numpy as np
import streamlit as st
from openai import OpenAI
from sentence_transformers import SentenceTransformer
# OllamaローカルAPIを指定
client = OpenAI(
api_key="ollama",
base_url="http://localhost:11434/v1"
)
embedder = SentenceTransformer("all-MiniLM-L6-v2")
index, texts = pickle.load(open("personal_faiss.pkl", "rb"))
st.title("🦙 個人的RAGチャット(ローカルLLM版・履歴付き)")
# 履歴をセッションで保存
if "history" not in st.session_state:
st.session_state.history = []
query = st.text_input("質問を入力してください:")
if st.button("送信") and query:
# ベクトル検索で上位2件
qvec = embedder.encode([query])
D, I = index.search(np.array(qvec), k=2)
context = "\n".join([texts[i] for i in I[0]])
# 過去の履歴も含めてmessagesを構成
messages = []
for h in st.session_state.history:
messages.append({"role": "user", "content": h["user"]})
messages.append({"role": "assistant", "content": h["bot"]})
# 今回の質問をプロンプトとして追加
prompt = f"""
あなたは質問に対して、以下の情報を参考にしながら、丁寧で簡潔に日本語で答えてください。
### 参考情報:
{context}
### 質問:
{query}
### 回答:
"""
messages.append({"role": "user", "content": prompt})
# LLMに問い合わせ
rsp = client.chat.completions.create(
model="llama3.1:8b",
messages=messages,
temperature=0.5,
)
answer = rsp.choices[0].message.content.strip()
# 履歴に追加
st.session_state.history.append({"user": query, "bot": answer})
# 履歴を下に表示
if st.session_state.history:
st.markdown("## 💬 履歴")
for i, h in enumerate(st.session_state.history):
st.markdown(f"**Q{i+1}:** {h['user']}")
st.markdown(f"**A{i+1}:** {h['bot']}")内容としては先ほど作成したインデックスの情報を元に回答するチャットアプリになります。
LLMはollamaでインストールしたモデルを指定しています。
ollamaのサーバーを起動して、Streamlitを実行します。
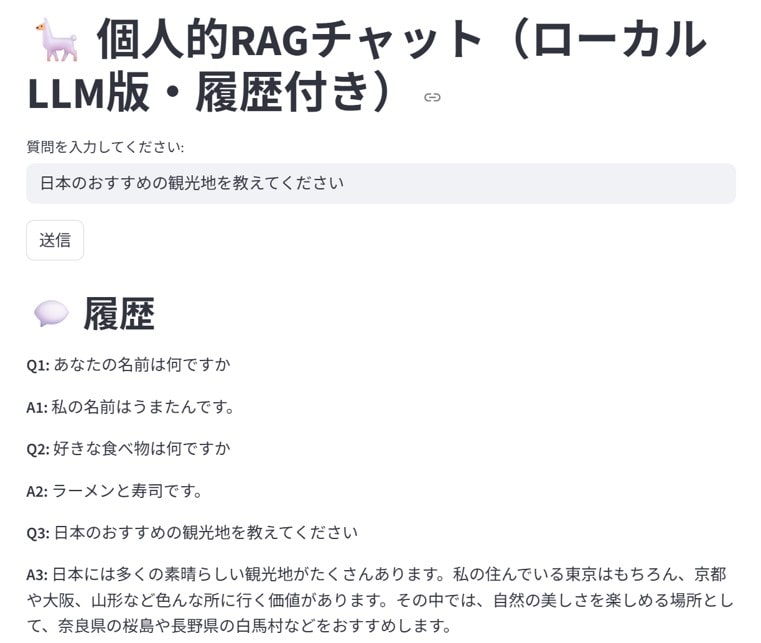
個別情報に関する質問は事前に用意したテキストを元に回答出来ています。
今回はサンプルテキストを元にしていますが、PDFやExcelなど大量のデータを元にRAGを作成することも可能です。
機密情報を扱う場合とかは便利そう!
ローカルLLM まとめ
“ローカルLLM“について解説していきました。
ここでローカルLLMのメリットをおさらいします。
- セキュリティが高い:自身のPCで完結するため、入力データやモデルが外部に漏れない
- コストがかからない:クラウドLLMの利用時に発生するコスト(トークン数や利用プランなど)がかからない
- カスタマイズ性が高い:モデルを自分仕様に学習し直したり、軽量化したり、カスタマイズ可能
初心者だけど本格的にPythonでアプリ開発をやってみたい方は、当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」を以下の講座チェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムですので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















