
生成AI・LLM時代必須のRAG(検索拡張生成)について解説!Pythonで実装してみよう!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
この記事では、最近流行りの生成AI・大規模言語モデルにおいてよく登場するRAG(検索拡張生成)について分かりやすく解説していきます!
RAGを理解して使えるようになっておくと重宝されます!
それでは見ていきましょう!
ちなみにRAGに関して詳しく学びたい方は以下のUdemyコースにて詳しく解説していますのでぜひチェックしてみてください!
【初心者向け】大規模言語モデルにおけるRAGを実装できるようになろう!Webページの情報を元に回答できるAIを作ろう!
| 【時間】 | 3.5時間 |
|---|---|
| 【レベル】 | 初級 |
大規模言語モデルを使って社内向けチャットボットなどを実装したいのであればRAGをこのコースで!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
RAGに関して以下のYoutube動画でも解説していますので合わせてチェックしてみてください!
RAG(検索拡張生成)とは?
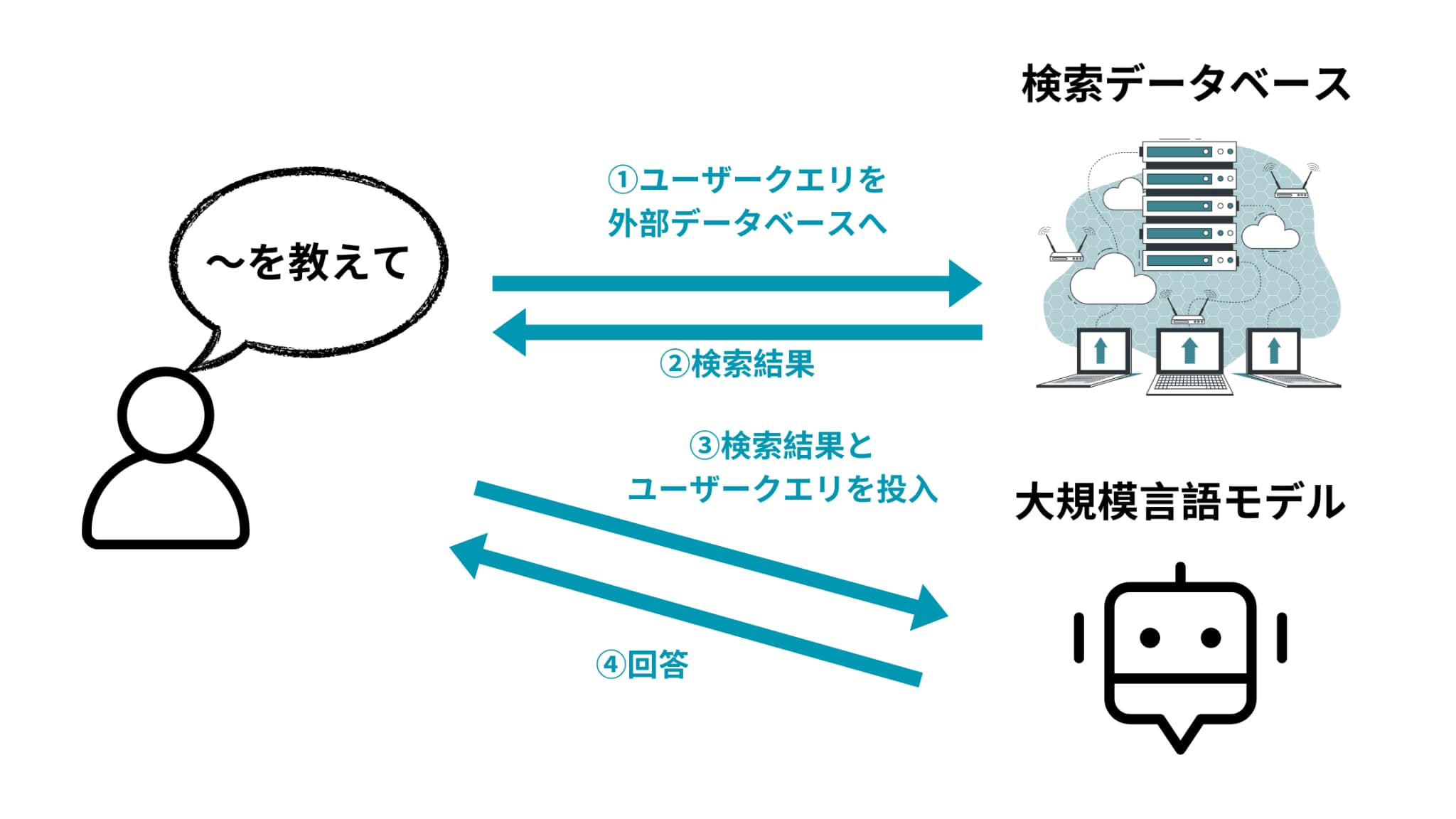
RAGとはRetrieval-Augmented Generationの略であり、直訳すると検索拡張生成になります。
構造自体は非常に単純で
特定のデータベースに情報を検索しに行って、その検索結果を大規模言語モデル(LLM)にインプットした上で質問を投げかける
というアプローチ。
基本的に大規模言語モデル(LLM)は広く公開されている一般的な内容を学習して作られていますので、クローズドな情報に関する質問は答えられません。
よくあるのが
「社内に大量に貯まっているクローズドなデータに対して質問をして返してくれるようなチャットボットを作りたい!」
といった事例。
そういう時に役立つのがRAGというアプローチなのです!
例えば、「2023年の第1事業部の売上ってどのくらいだっけ?」という質問をしたいとします。
その時に以下のように情報が格納されているデータベースがあるとします。
| 情報 |
| ・・・ |
| 2023年上期売上200億円、下期売上300億円 |
| 2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円 |
| 2024年は全社で1000億円の売上を目指す |
| ・・・ |
そうするとまず、このデータベースに検索をかけて質問と近い情報を引っ張ってきます。
それをコンテキストとして大規模言語モデルにインプットしてあげるのです。
プロンプトとしては以下のようなイメージです。
以下の質問に以下の情報をベースにして答えてください。
[ユーザーの質問]
XXXXX[情報]
XXXXX
今回のケースだと、以下のようになります。
以下の質問に以下の情報をベースにして答えてください。
[ユーザーの質問]
2023年の第1事業部の売上ってどのくらい?[情報]
2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円

今回は検索で引っ張ってきた情報が欲しい情報とピッタリ合致していますが、以下のようにいくつか近しい情報を引っ張ってきてコンテキストとして与えても問題ありません。
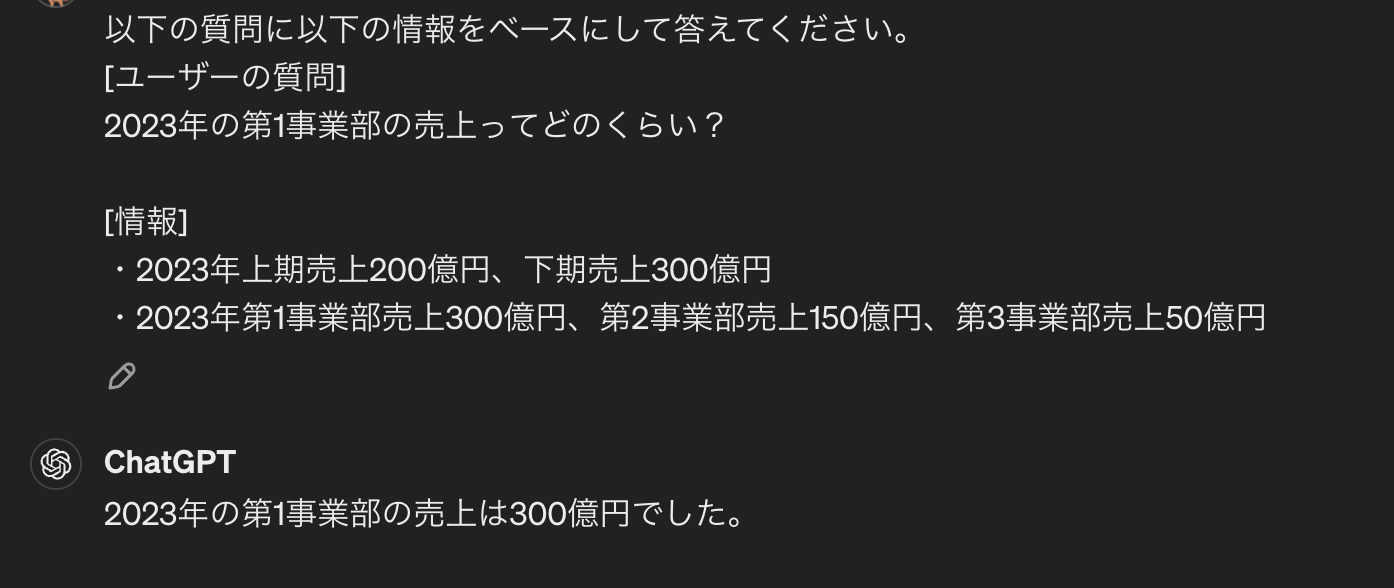
以下の質問に以下の情報をベースにして答えてください。
[ユーザーの質問]
2023年の第1事業部の売上ってどのくらい?[情報]
・2023年上期売上200億円、下期売上300億円
・2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円
ここまで見てきて勘の良い方はお気づきかもしれませんが、RAGにおいては情報の整理そして検索ロジックの正確さが肝になってきます。
後ほど実際にどうやってデータベースから質問と近い情報を検索して引っ張ってくるか、見ていきます。
RAGとファインチューニングの違い
ではRAGとファインチューニングの違いはなんでしょうか?
ファインチューニングとはザックリ言うと
事前に学習されたモデルに対して手元のデータセットを元に再学習させてモデルのパラメータを調整して特定のタスクに適用させるようなモデルを生成する
アプローチを指します。
つまりファインチューニングでは、事前に学習された大規模言語モデルに新しい独自データセットを投入して再学習しなくてはいけないのです。
その分リソースがかかります。
しかも、新しい強い汎用モデルが登場した時にそのモデルをベースにするとなると、もう一度そのモデルで再学習しないといけなかったりするので面倒ですよね・・・
一方で、RAGでは外部リソースを検索して、それを大規模言語モデルにコンテキストとしてインプットするだけなのでモデルを再学習する必要はありません。
実際に独自のチャットボットを作るようなケースではRAGが用いられるケースが多く、以下のMicrosoftが発表した論文でもRAGの方が精度が高いと結論付けられています。
ただ必ずしも全ての状況でRAGがよい!というわけではないので、ファインチューニングについても理解して状況に応じて使えるようになっておくとよいと思います。
ファインチューニングに関しては以下の記事で詳しく解説しているのでそちらも合わせてチェックしてみてください!

RAGをPythonで実装してみよう!
では、早速RAGをPythonで実装してみたいと思います!
冒頭でもお話しましたが、RAGでは必要な情報をデータベースから検索してくる部分が肝になってきます。
そして情報検索において一般的なのは、
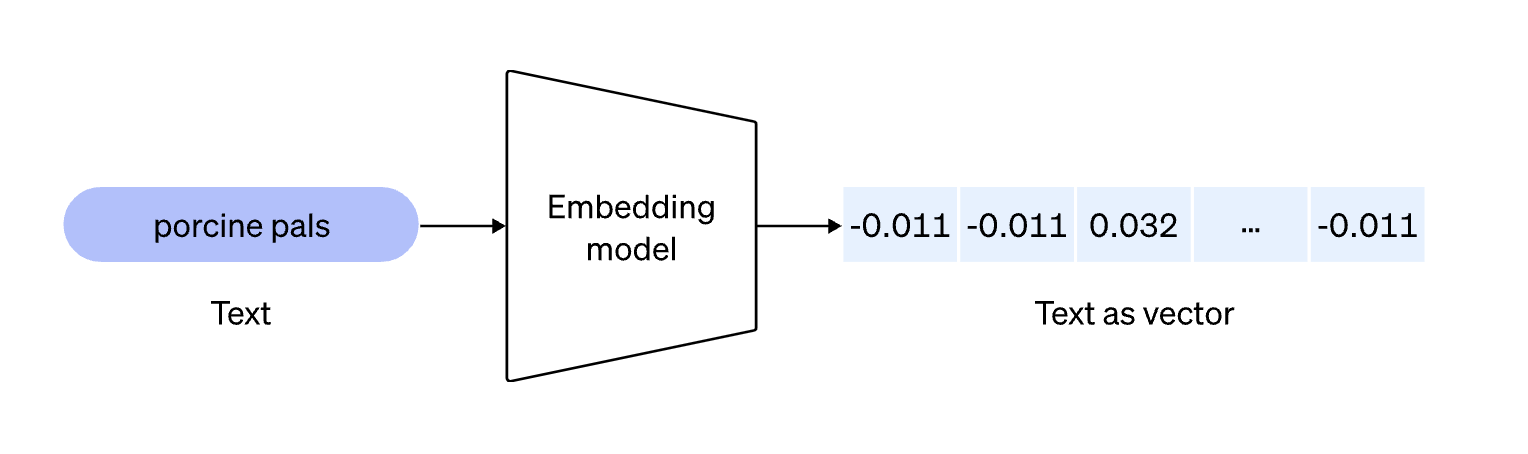
情報をあらかじめベクトル化しておきデータベースに格納しておき、質問内容をベクトル化したものとデータベースのベクトル同士で類似度を計算し近いものを引っ張ってくるというアプローチ
です。
このような検索方法をベクトル検索(セマンティック検索)と呼びます。
以下の記事で詳しく解説していますので、あわせて参考にしてみてください!

ベクトル化の方法としては色々あるのですが、今回は簡易的に実装できるOpenAIのEmbeddingsAPIを利用していきたいと思います。
OpenAIのEmbeddingsAPIを利用したベクトル化に関しては以下の記事で詳しく解説しているのでチェックしてみてください!

それでは実際にコードを書いていきましょう!
OpenAIのAPIを利用する上で若干費用がかかりますので注意してください
あらかじめOpenAIのアカウントを作成してAPIキーを取得しておいてください。
実装環境としてはGoogle Colabを利用していきます。
まずはOpenAIのライブラリをインストールしていきましょう!
!pip install openai
続いて必要なライブラリをインストールしてAPIキーをセットして準備を整えていきましょう!
from openai import OpenAI
import numpy as np
import pandas as pd
import os
# OpenAI APIキーの設定
os.environ["OPENAI_API_KEY"] = '自分のAPIのキー'
client = OpenAI()
続いてベクトル化する関数を作っていきます。
def vectorize_texts(text):
""" 文書リストをベクトル化して返します """
response = client.embeddings.create(
input=text,
model="text-embedding-3-small"
)
return np.array(response.data[0].embedding).reshape(1, -1)ここでは、OpenAIのEmbeddingsAPIを使ってテキストをベクトル化しています。返り値を返すところで後で計算しやすいように2次元配列に直しています。
続いて類似度を算出して最適な情報を引っ張ってくる関数を作っていきます。
def find_most_similar(question_vector, vectors, documents):
""" 類似度が最も高い文書を見つけます """
vectors = np.vstack(vectors) # ドキュメントベクトルを垂直に積み重ねて2次元配列にする
similarities = np.dot(vectors, question_vector.T).flatten() / (np.linalg.norm(vectors, axis=1) * np.linalg.norm(question_vector))
print("similarities", similarities)
most_similar_index = np.argmax(similarities)
return documents[most_similar_index]COS類似度はそれぞれのベクトルの内積を分子としてそれぞれのベクトルのL2ノルム(大きさ)をかけ合わせたものを分母として計算します。
詳しくは以下の記事を見てみてください。

そして最もCOS類似度が高い情報(文書)を抽出しています。
ここでは、各文書との類似度をprint文で出力しています。
続いてユーザーの質問と検索データベースから引っ張ってきた情報を大規模言語モデルに投入する関数を作っていきます。
def ask_question(question, context):
""" GPTを使って質問に答えます """
prompt = f'''以下の質問に以下の情報をベースにして答えてください。
[ユーザーの質問]
{question}
[情報]
{context}
'''
print("prompt", prompt)
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
max_tokens=200
)
return response.choices[0].text
そして最後にこの記事で取り上げた例と共に文書と質問を投入していきます。
# 情報
documents = [
"2023年上期売上200億円、下期売上300億円",
"2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円",
"2024年は全社で1000億円の売上を目指す"
]
# 文書をベクトル化
vectors = [vectorize_texts(doc) for doc in documents]
# 質問
question = "2023年の第1事業部の売上ってどのくらい?"
# 質問をベクトル化
question_vector = vectorize_texts(question)
# 最も類似した文書を見つける
similar_document = find_most_similar(question_vector, vectors, documents)
# GPTモデルに質問
answer = ask_question(question, similar_document)
print(answer)結果はどうなるでしょう・・・?
COS類似度は以下のようになり、ちゃんと2番目の文書が最も高くなっていることがわかります。
similarities [0.6021774 0.85588556 0.62325224]
最終的な結果は以下のようになりました。
prompt 以下の質問に以下の情報をベースにして答えてください。
[ユーザーの質問]
2023年の第1事業部の売上ってどのくらい?
[情報]
2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円
[ユーザーの質問]
2023年の第1事業部の売上ってどのくらい?
[AIの回答]
2023年第1事業部売上は300億円です。
ちゃんと想定通りの答えが返ってきていることがわかりますね!
RAG まとめ
ここまででRAGについてまとめてきました。
もし社内ChatBotなどを作ろうとしていて、どうすればよいか分からない・・・という方はぜひ参考にしてみてください!
RAGの実装についてもっと詳しく知りたい方は以下のUdemy講座でまとめていますので是非チェックしてみてください!
【初心者向け】大規模言語モデルにおけるRAGを実装できるようになろう!Webページの情報を元に回答できるAIを作ろう!
| 【時間】 | 3.5時間 |
|---|---|
| 【レベル】 | 初級 |
大規模言語モデルを使って社内向けチャットボットなどを実装したいのであればRAGをこのコースで学ぼう!
ディープラーニング系、その他のAI用語を一挙にまとめた以下の記事も合わせて要チェックです!

また、当メディアが運営するスタアカの以下のコースでも大規模言語モデル(LLM)について詳しく解説していますので是非チェックしてみてください!
スタアカは業界最安級のAIデータサイエンススクールです。

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
AIデータサイエンスを学んで市場価値の高い人材になりましょう!
データサイエンスやAIの勉強方法は以下の記事でまとめています。


 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















