
ベクトル検索・セマンティック検索・キーワード検索の違いについて解説!Pythonで実装してみよう!


データサイエンティストのウマたん(@statistics1012)です。
昨今の様々なWebサービスには必ずといっていいほど検索機能が搭載されています。
一見シンプルに見える検索機能も実は非常に複雑で奥が深い世界なのです。
ということで、この記事ではそんな奥の深い検索の世界に足を踏み入れていきましょう!
以下のYoutube動画でも詳しく解説していますので合わせてチェックしてみてください!
目次
検索の種類
検索と聞くとどんなイメージを持つでしょうか?
例えば、「データサイエンス」と調べたら「データサイエンス」というキーワードが入っている文章が検索にヒットするイメージでしょうか?
でも「Data Science」は、検索にヒットしなくて大丈夫でしょうか?
「データサイエンティスト」は、検索にヒットしなくて大丈夫でしょうか?
「データを使って科学する分野的な内容」について語られた文章は、検索にヒットしなくて大丈夫でしょうか?
そう考えていくと意外といろいろなことを考えなくてはいけないことに気付きます。
ということで検索の種類について見ていきましょう!
大きく分けて検索にはキーワード検索とベクトル検索(セマンティック検索)があります。
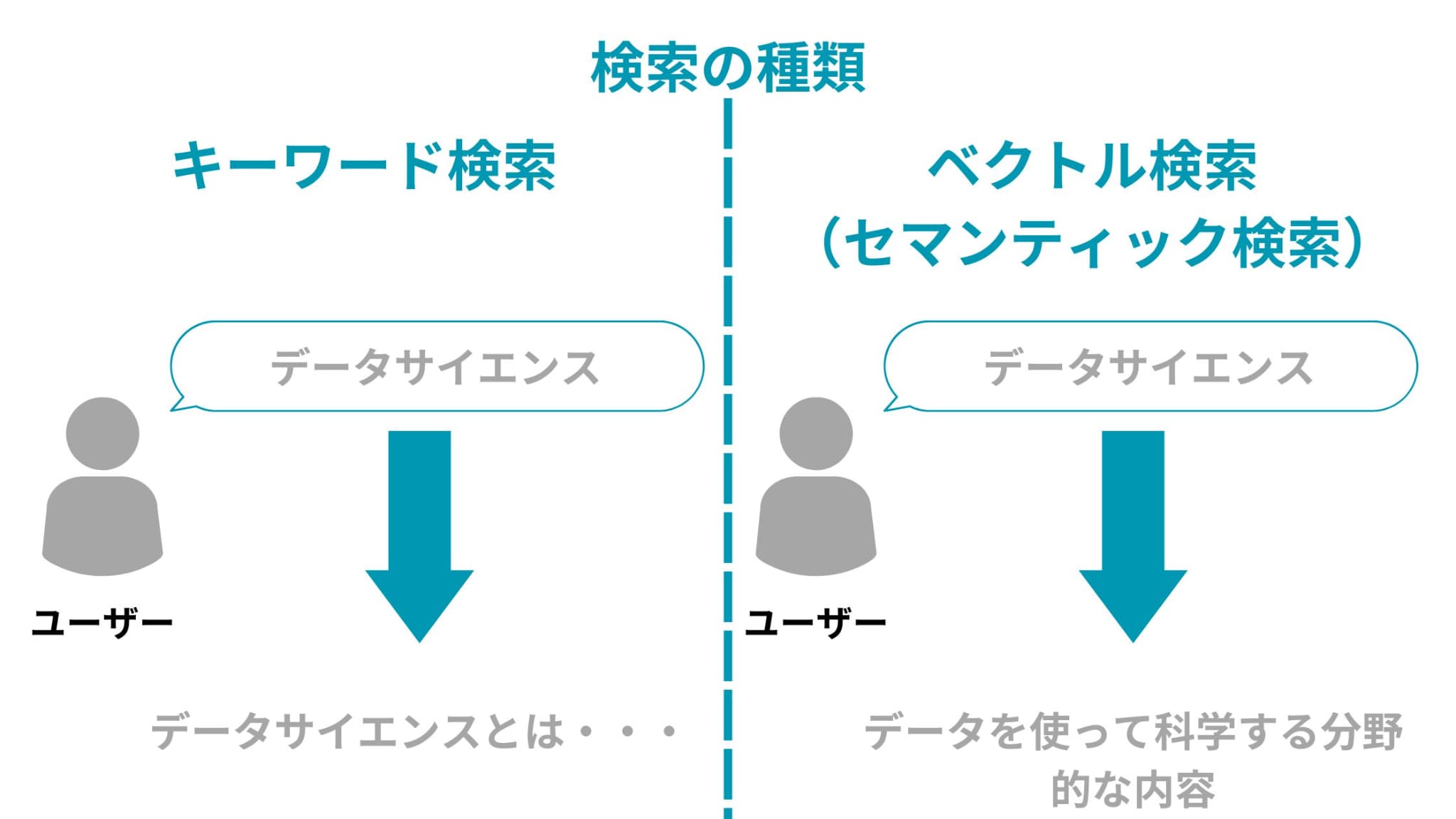 キーワード検索は、一般的なイメージに近い検索方法です。
キーワード検索は、一般的なイメージに近い検索方法です。
「データサイエンス」と検索したらそれに対して「データサイエンス」が含まれる文章が検索に引っかかります。
ベクトル検索(セマンティック検索)は、文章をベクトル化することで意味合いの近い文章を検索に引っかけるアプローチです。
「データサイエンス」と検索したらそれに対して「データを使って科学する分野的な内容」を検索に引っかけるのは、ベクトル検索(セマンティック検索)のアプローチと言えるでしょう。
ちなみにセマンティック検索とは自然言語処理を使って意味の近いもの同士を検索するアプローチのことを指し、その手法として一般的にベクトル化が用いられます。
定義的にはセマンティック検索の方が広いのですが、セマンティック検索=ベクトル検索と考えてしまっても問題ないです。
それでは、もう少し具体的にそれぞれの検索アプローチについて見ていきましょう!
キーワード検索
キーワード検索のベースは先ほどもお伝えした通り、
「データサイエンス」と検索したらそれに対して「データサイエンス」が含まれる文章が引っかかる
なのですが、色々なことを考慮する必要があります。
文章の正規化
このままだと「データサイエンス」を「データ サイエンス」と表記している文章は、検索に引っかかりません。
そこで、空白を削除する正規化を事前に行うことを検討する必要があります。
また、英語で「Data Science」と「data science」を結びつけるためには全てを小文字か大文字に正規化する必要があります。
このように事前にキーワードと文章を特定のルールで正規化することで、より精度の高いキーワード検索を実現することができるのです。
同じ意味合いのキーワード紐づけデータベース
また、「データサイエンス」と「Data Science」を同じキーワードと捉えるためには、事前に同じ意味合いのキーワードの名寄せデータベースを持っておくことを検討する必要があります。
しかしこのデータベースを作って運用するのは非常に工数がかかるので、前述のベクトル検索(セマンティック検索)で代用するとよいでしょう。
レーベンシュタイン距離を使った一致度算出
例えば「テータサイエンス」という誤植があったとしても、それを検索に引っかけたいとしましょう。
このような現象を表記揺れと言いますが、この表記揺れにどのように対応するかも検索において重要です。
そこで用いられるのが、レーベンシュタイン距離という指標。
レーベンシュタイン距離とは、文字の「挿入、削除、置換」それぞれを距離1として、ある文字列からある文字列に変換するために必要な距離数
例えば、「みかん」から「みどり」に変換するためには「か」を「ど」に置換して「ん」を「り」に置換しなくてはいけないので2文字の置換が必要でレーベンシュタイン距離は2になります。

すなわち、「テータサイエンス」と「データサイエンス」の場合は「テ」を「デ」に変換すればいいだけなのでレーベンシュタイン距離は1になります。
これにより表記揺れを考慮した上で検索を行うことができます。
Googleで表記揺れしたキーワードを入力した時に自動的に表記揺れを直してくれたり、あなたが検索したいのは〇〇じゃないですか?と提案してくれるのを見たことはないでしょうか?
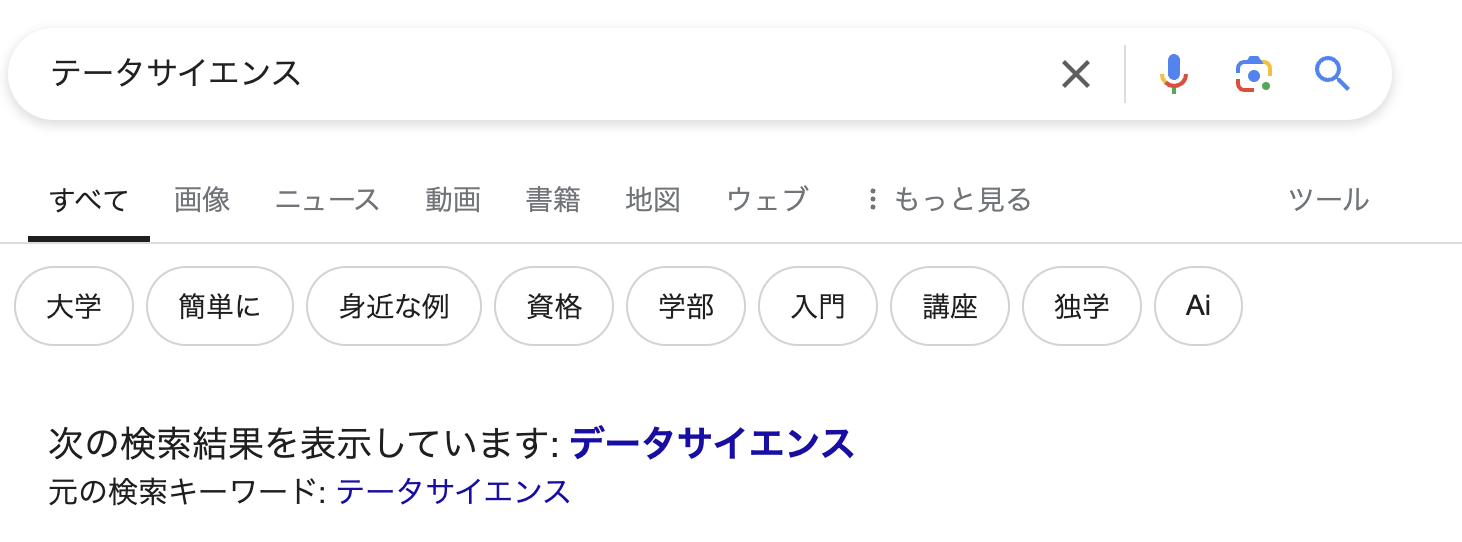
このロジックはもっと複雑かもしれませんが、レーベンシュタイン距離の考え方と同じアプローチが裏で動いているはずです。
n-gramや形態素解析を用いて分解して検索
例えば、「面白いサイト」という検索に対して「〇〇というサイトは非常に面白い」みたいな文章を引っかけたい場合どうすればよいでしょうか?
今までのアプローチだと検索に引っかけられないですよね。
この時、「面白いサイト」を「面白い」と「サイト」に分割して、それらをベースにキーワード検索するアプローチが考えられます。
その分割のアプローチにはn-gramというアプローチと形態素解析というアプローチがあります。
詳しくは以下の記事に詳しくまとめていますので是非チェックしてみてください。

また形態素解析については以下も参考にしてみてください!

ベクトル検索(セマンティック検索)
ここまでキーワード検索について解説してきました。
一口にキーワード検索と言っても考慮すべきことがたくさんあるということが分かっていただけたかと思います。
それでは続いて、ベクトル検索(セマンティック検索)について見ていきましょう!
冒頭にもお伝えしましたが、ベクトル検索(セマンティック検索)はキーワードをベクトル化してベクトルの近い文章同士を紐づけるアプローチです。
「データサイエンス」と検索したらそれに対して「データを使って科学する分野的な内容」を検索に引っかけるのは、ベクトル検索(セマンティック検索)のアプローチと言えるでしょう。
ベクトル化することで意味合い的にこの単語とこの単語は近いよねー、この単語は遠いよねーみたいなことがベクトルの向きに落とし込めるんです!
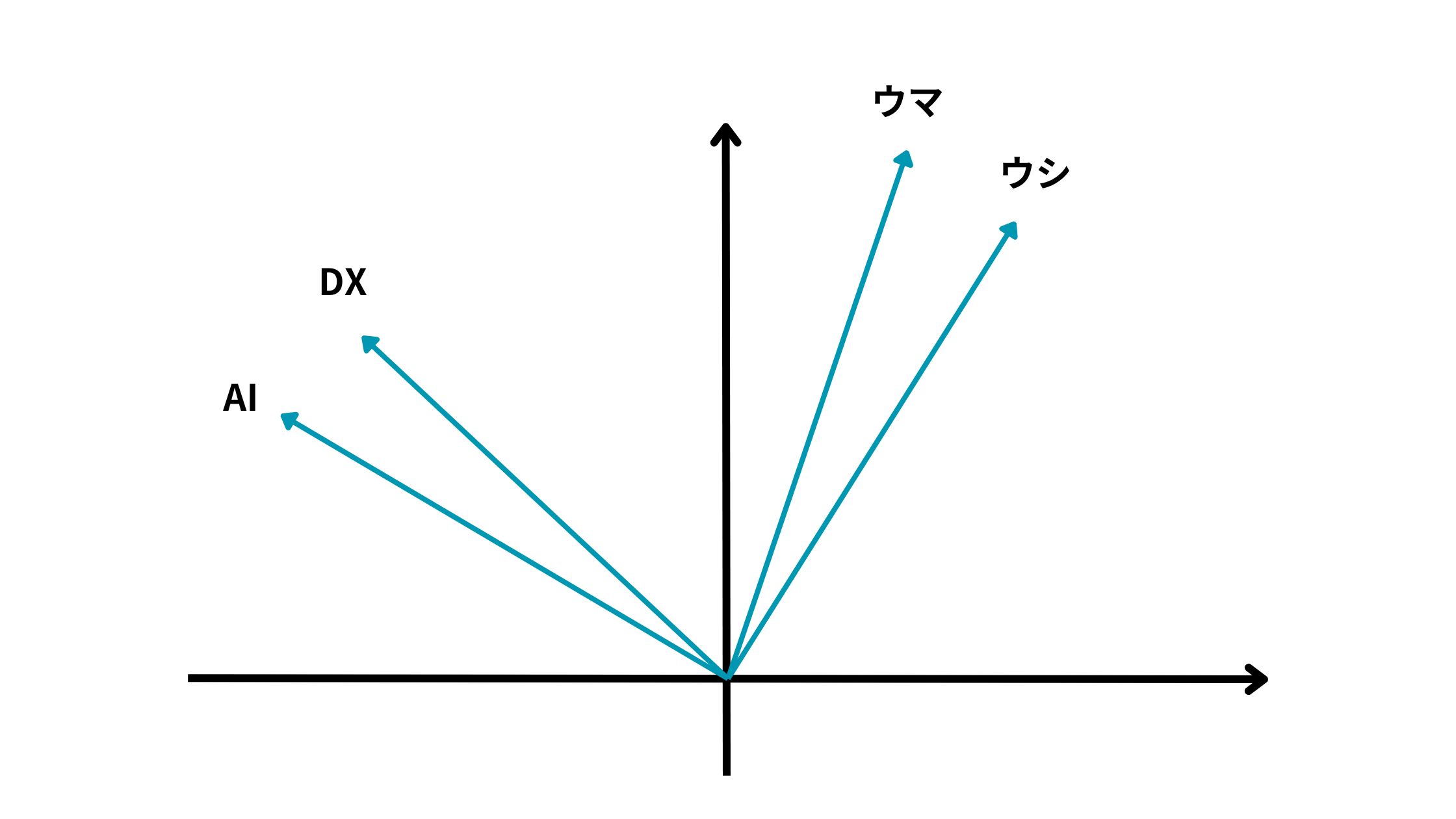
上記の例だとAIとDXは近いベクトル方向を持っている一方で、ウマとウシは遠いベクトル方向を持っているように見えます。
これは簡易的な例ですが、単語をベクトル化することでどの単語同士が近い意味を持つのか遠い意味を持つのかを解釈しようとする試みなのです!
例えば以下のように
AI というワードが[0.2, 0.4, 0.5・・・・]というようなベクトルになるイメージです。
そして、ベクトル化の便利なところは様々な演算を施せることです。
有名な例として、
King – Man + Woman = Queen
になるという例があります。
KingのベクトルからManのベクトルを引いて、Womanのベクトルを足してあげると、Queenのベクトルに非常に近いベクトルが生成できるのです。
このベクトル化にはたくさんのアプローチがあります。
例えばWord2VecやDoc2Vecなどのアプローチが有名です。
Word2Vecはその名の通り単語単位のベクトル化でDoc2Vecは文書単位のベクトル化です。
それらに関しては以下の記事に詳しく解説していますのでぜひチェックしてみてください!


ちなみに古典的なアプローチだとTf-idfというアプローチでカウントベースでベクトル化するようなものもあります。
そしてベクトル化した後は最終的にはCos類似度という指標で類似度を算出することが多いです。
ベクトル検索(セマンティック検索)をPythonで実装してみよう!
ベクトル化の方法としては色々あるのですが、今回は簡易的に実装できるOpenAIのEmbeddingsAPIを利用していきたいと思います。
OpenAIのEmbeddingsAPIを利用したベクトル化に関しては以下の記事で詳しく解説しているのでチェックしてみてください!

それでは実際にコードを書いていきましょう!
OpenAIのAPIを利用する上で若干費用がかかりますので注意してください
あらかじめOpenAIのアカウントを作成してAPIキーを取得しておいてください。
実装環境としてはGoogle Colabを利用していきます。
まずはOpenAIのライブラリをインストールしていきましょう!
!pip install openai
続いて必要なライブラリをインストールしてAPIキーをセットして準備を整えていきましょう!
from openai import OpenAI
import numpy as np
import pandas as pd
import os
# OpenAI APIキーの設定
os.environ["OPENAI_API_KEY"] = '自分のAPIのキー'
client = OpenAI()
続いてベクトル化する関数を作っていきます。
def vectorize_texts(text):
""" 文書リストをベクトル化して返します """
response = client.embeddings.create(
input=text,
model="text-embedding-3-small"
)
return np.array(response.data[0].embedding).reshape(1, -1)ここでは、OpenAIのEmbeddingsAPIを使ってテキストをベクトル化しています。返り値を返すところで後で計算しやすいように2次元配列に直しています。
続いて類似度を算出して最適な情報を引っ張ってくる関数を作っていきます。
def find_most_similar(question_vector, vectors, documents):
""" 類似度が最も高い文書を見つけます """
vectors = np.vstack(vectors) # ドキュメントベクトルを垂直に積み重ねて2次元配列にする
similarities = np.dot(vectors, question_vector.T).flatten() / (np.linalg.norm(vectors, axis=1) * np.linalg.norm(question_vector))
print("similarities", similarities)
most_similar_index = np.argmax(similarities)
return documents[most_similar_index]COS類似度はそれぞれのベクトルの内積を分子としてそれぞれのベクトルのL2ノルム(大きさ)をかけ合わせたものを分母として計算します。
そして最もCOS類似度が高い情報(文書)を抽出しています。
ここでは、各文書との類似度をprint文で出力しています。
それでは最後に文書と質問キーワードを渡して結果を見ていきましょう!
# 情報
documents = [
"2023年上期売上200億円、下期売上300億円",
"2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円",
"2024年は全社で1000億円の売上を目指す"
]
# 文書をベクトル化
vectors = [vectorize_texts(doc) for doc in documents]
# 質問
question = "2023年の第1事業部の売上ってどのくらい?"
# 質問をベクトル化
question_vector = vectorize_texts(question)
# 最も類似した文書を見つける
similar_document = find_most_similar(question_vector, vectors, documents)
print(similar_document)結果はどうなるでしょう・・・?
最終的な結果は以下のようになりました。
similarities [0.6021774 0.85588556 0.62325224]
2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円
COS類似度を見ると、ちゃんと2番目の文書が最も高くなっていて、質問に対応する情報が入っている文書がちゃんと検索に引っかかっていることが分かります。
これこそがベクトル検索(セマンティック検索)なのです。
ちなみにこの処理で取り出された結果を大規模言語モデル(LLM)に投入することで、ちゃんとした回答を自然言語で返してくれるチャットボットを作ることができます。
そのようなアプローチをRAGといい、昨今のAI時代で独自チャットボットを作る上で非常によく使われていますので興味のある方はぜひチェックしてみてください!

ちなみにRAGに関して詳しく学びたい方は、以下のUdemyコースにて詳しく解説していますのでぜひチェックしてみてください!
【初心者向け】大規模言語モデルにおけるRAGを実装できるようになろう!Webページの情報を元に回答できるAIを作ろう!
| 【時間】 | 3.5時間 |
|---|---|
| 【レベル】 | 初級 |
大規模言語モデルを使って社内向けチャットボットなどを実装したいのであればRAGをこのコースで!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
ベクトル検索・セマンティック検索・キーワード検索 まとめ
ここまでご覧いただきありがとうございました!
本記事では、検索における様々なアプローチを紹介してきました。
ちなみに我々が開発するYomeruという書籍のレビューサービスにも検索機能があり、今回紹介したアプローチが取り入れられています。
うちの凄腕エンジニアが実装しています。検索には考慮することがたくさんあるのです!
現代において検索機能はなくてはならないアプローチ。ぜひおさえておきましょう!
さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















