自然言語処理領域で重要なWord2Vecの仕組みとPython実装についてわかりやすく解説!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では自然言語処理領域の中で非常に重要なWord2Vecについて簡単に解説していきます。
最近の大規模言語モデルは自然言語処理領域の進化の過程で生まれてきましたが、その自然言語処理の領域の今まで登場してきた技術をしっかりおさえておくことは非常に重要です。
ここでしっかり理解しておきましょう!
以下のYoutube動画でも解説していますのでチェックしてみてください!
Word2Vecとは?
まずWord2Vecとはどんな技術なのでしょうか?
Word2Vecは2013年にGoogleの研究員であるTomas Mikolovらによって発表された手法です。
論文は以下になります。
Word2Vecは、その名の通り「ワードをベクトルに変換する技術」です。
ベクトル化することで意味合い的にこの単語とこの単語は近いよねー、この単語は遠いよねーみたいなことがベクトルの向きに落とし込めるんです!
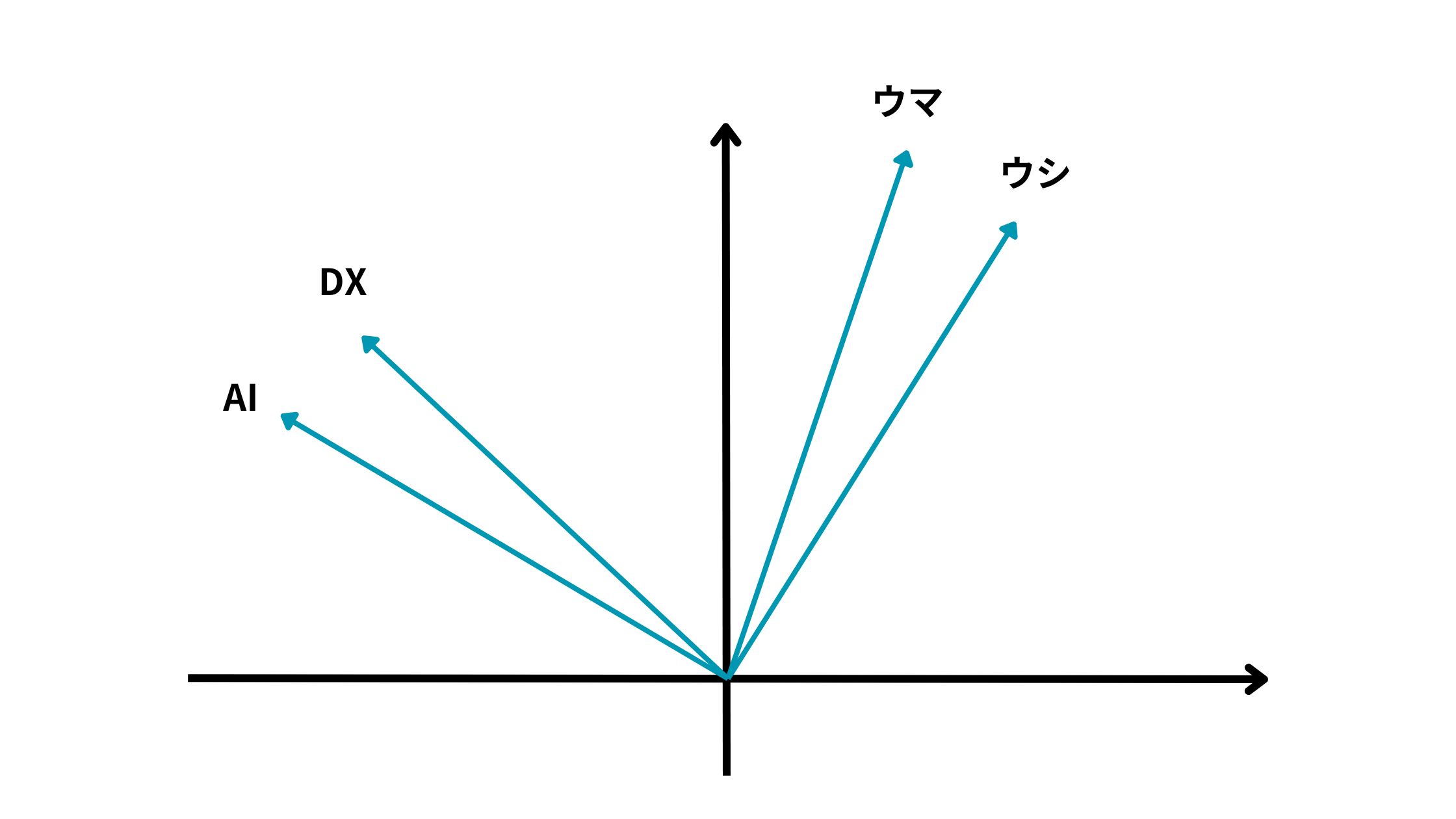
上記の例だとAIとDXは近いベクトル方向を持っている一方で、ウマとウシは遠いベクトル方向を持っているように見えます。
これは簡易的な例ですが、単語をベクトル化することでどの単語同士が近い意味を持つのか遠い意味を持つのかを解釈しようとする試みなのです!
例えば以下のように
AI というワードが[0.2, 0.4, 0.5・・・・]というようなベクトルになるイメージです。
そして、ベクトル化の便利なところは様々な演算を施せることです。
有名な例として、
King – Man + Woman = Queen
になるという例があります。
KingのベクトルからManのベクトルを引いて、Womanのベクトルを足してあげると、Queenのベクトルに非常に近いベクトルが生成できるのです。
自然言語処理の世界では、文書や単語をベクトルに置き換えてベクトル表現の状態で比較したり推論したりします。
ベクトル化する方法としてカウントベースと推論ベースがあり、Word2Vecは推論ベースになります。
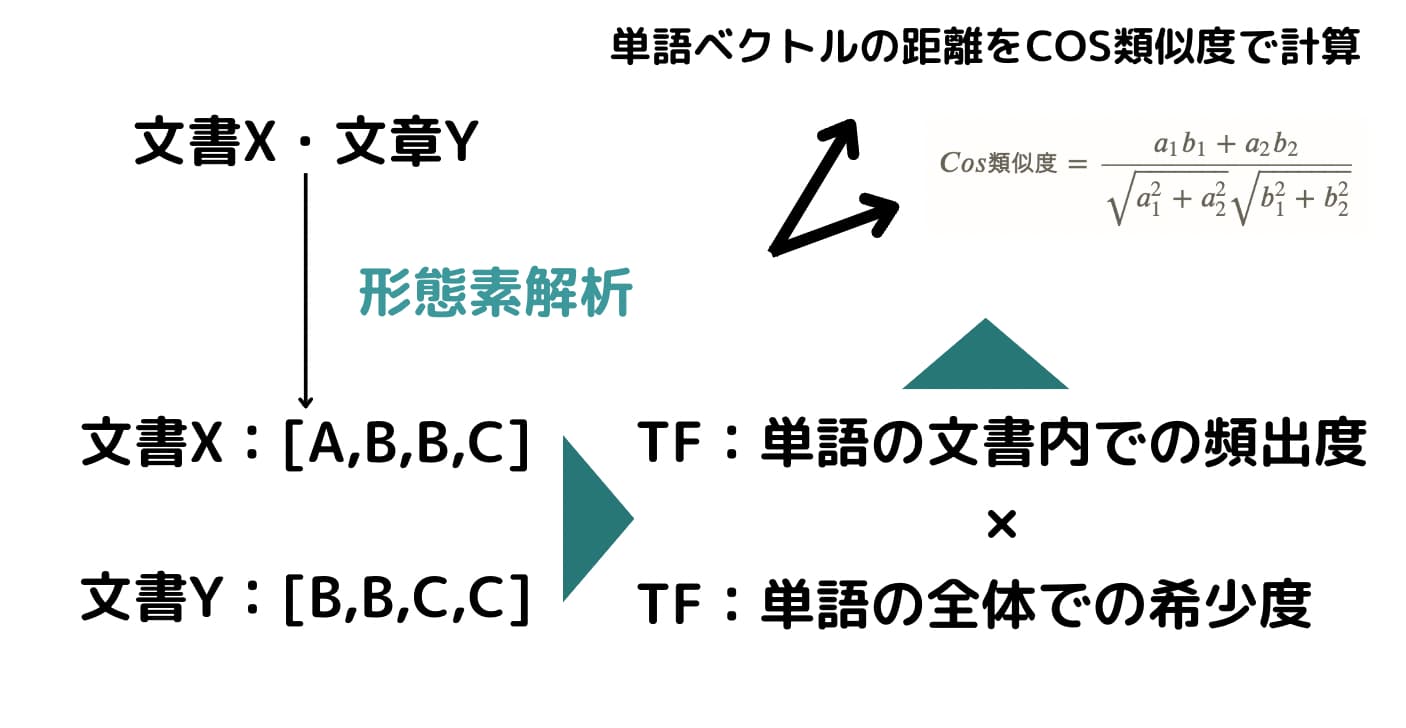
例えばカウントベースには代表的なアプローチとしてtf-idfというものがあり、文章に登場する単語の数を数えてそれをベクトル化します(これは文章のベクトル化なので単語とは違いますが)。
TFはその文書内での単語の頻出度を表しており、IDFはその単語が全ての文書の中でどれくらいの文書で登場するかすなわち単語の希少度を表しており、それらをもとに算出されるのがtf-idfです。
 以下の記事で解説していますのでチェックしてみてください。
以下の記事で解説していますのでチェックしてみてください。

一方でWord2Vecは推論ベースでベクトル化していきます。次から詳しい仕組みについて見ていきましょう!
Word2Vecの仕組み
それでは続いて簡単にWord2Vecの仕組み・アルゴリズムについて確認していきましょう!
Word2Vecの論文内では2つのアプローチが提案されています。
・CBOW
・Skip-gram
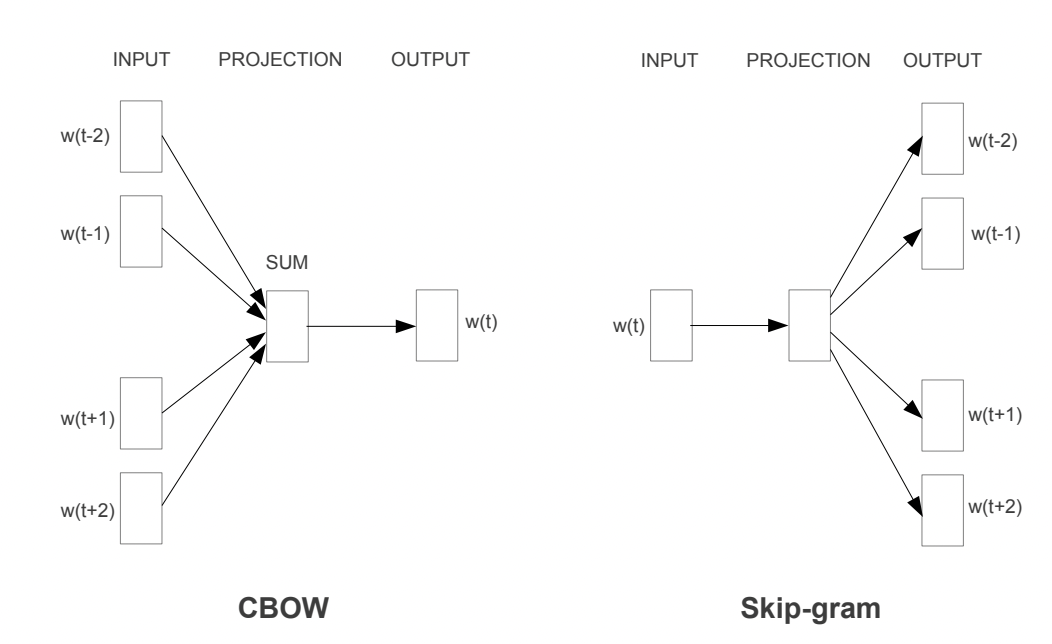
それぞれについて見ていきましょう!
CBOW
CBOWは、前後の文脈から対象となる単語を推論するアプローチです。
例えば、
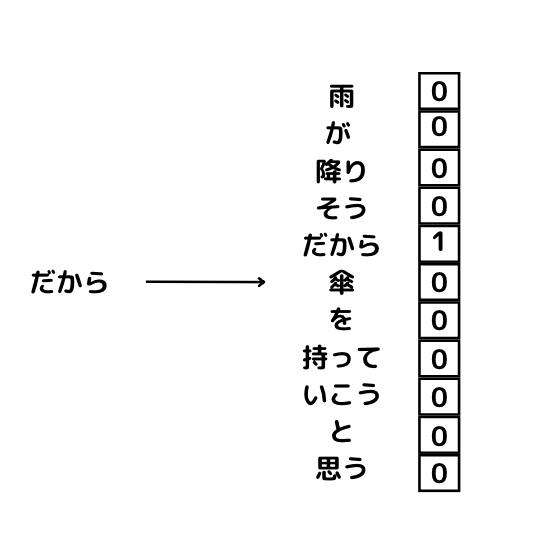
「雨が降りそうだから傘を持っていこうと思う」という文章があった時にその文章は以下のように分解することができます。
雨 / が / 降り / そう / だから / 傘 / を / 持って / いこう / と / 思う
この単語のかたまりのうち傘の部分をマスクしてみましょう!
雨 / が / 降り / そう / だから / ? / を / 持って / いこう / と / 思う
この状態で前後関係からマスクした「?」の部分を推測するのがCBOWです。
前後複数個の単語からマスクした単語を予測するわけです。
まずそれぞれの単語をOne-hot ベクトル化します。
これらのOne-hotベクトル化したものそれぞれに対して重み行列によって次元圧縮して平均を取ったものを最終的に重み行列で元の次元に戻して予測するモデルを構築します。
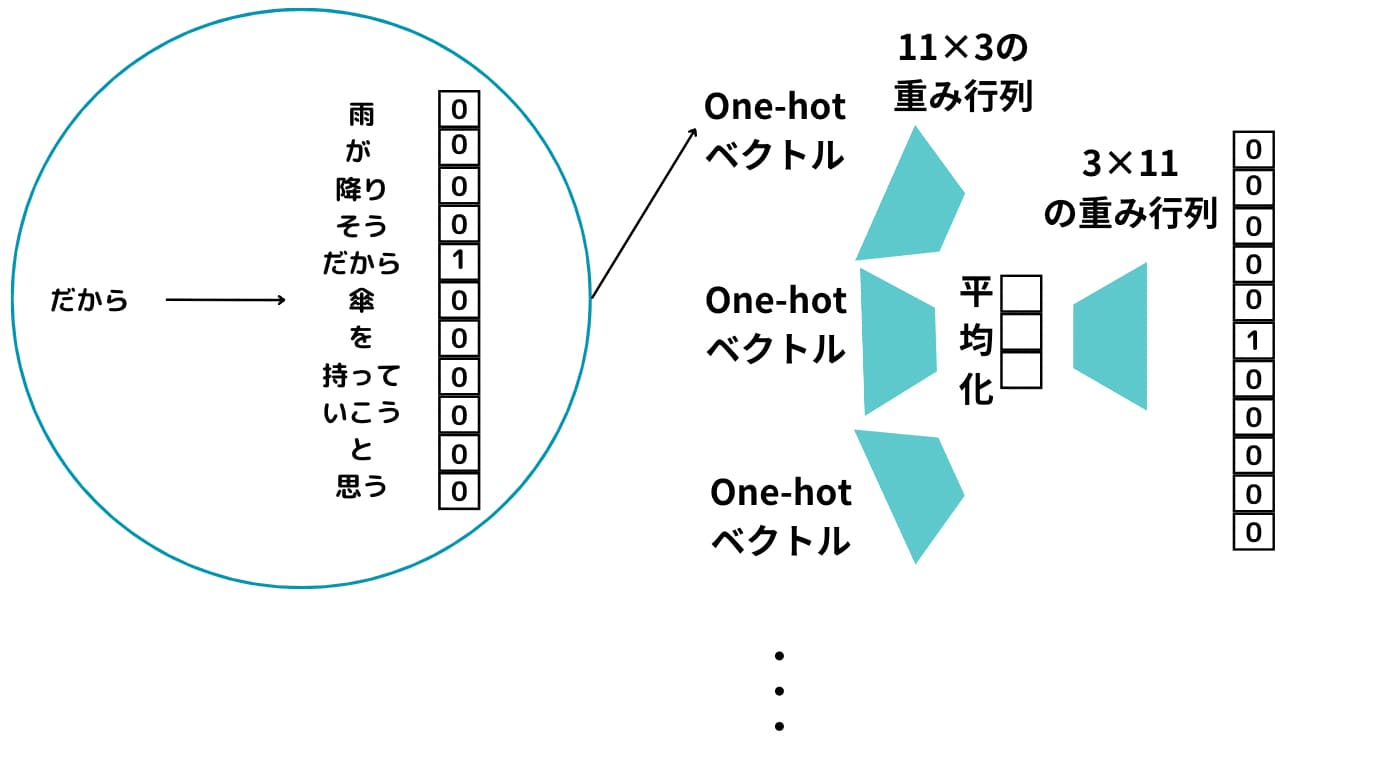
シンプルな2層構造のニューラルネットワークになることが分かりますね!
この時上手く出力結果が、「傘」になるようにニューラルネットワークの重みを調整します。
この過程で出力される重み行列の各行がWord2Vecで求められる単語ベクトルになるんです!
つまり、特定単語の前後から特定単語を予測する問題を解いている過程で生成されるベクトルがまさにWord2Vecで手に入れたい単語ベクトルになるんです。

Skip-gram
Skip-gramはCBOWの逆です。
? / ? / ? / ? / ? / 傘 / ? / ? / ? / ? / ?
特定の単語から前後の単語を予測するモデルを構築します。
Skip-gramの方が精度が高いですが、計算負荷が高く処理に時間がかかります。
ちなみにWord2Vecの派生版で文書をベクトル化するアプローチであるDoc2Vecについては以下の記事で解説していますので是非チェックしてみてください!

Word2VecをPythonで実装
それでは、Word2VecをPythonで実装してみましょう!
Pythonでの実装方法は極めて簡単です。
以下がコードです。MeCabという形態素解析のツールを使っているのですが、MeCabを使えるようにするには少々前準備が必要なので使ったことがない人は以下を参考にしてみてください。
from gensim.models import Word2Vec
import MeCab
# MeCabのTokenizer初期化
m = MeCab.Tagger("-Owakati")
# サンプルの文章データ
raw_sentences = [
"猫は外を歩いている。",
"夏の夜は暑くて寝苦しい。",
"彼はりんごとオレンジを食べた。",
"電車は時間通りに到着した。",
"子供たちは公園で遊んでいる。"
]
# 文章を単語に分割
sentences = [m.parse(sentence).strip().split() for sentence in raw_sentences]
# Word2Vecモデルの初期化とトレーニング
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# モデルの保存
model.save("word2vec_example.model")
# 保存したモデルのロード
model = Word2Vec.load("word2vec_example.model")
# 似ている単語を取得
similar_words = model.wv.most_similar("猫", topn=5)
print(similar_words)これで猫と近いベクトル表現を持つ単語を取得できます。
[(‘を’, 0.17115190625190735), (‘通り’, 0.13660389184951782), (‘に’, 0.13258132338523865), (‘外’, 0.103121317923069), (‘オレンジ’, 0.09587009996175766)]
今回は自分でサンプル文章を用意して学習しましたが、本来はもっと大量の文章で学習します。
もしくは学習済みモデルを利用するのが良いでしょう!
当メディアが運営する教育サービス「スタビジアカデミー」の自然言語処理コースでは、livedoorニュースのテキストを利用してWord2Vecで学習していますので参考にしてみてください。

Word2Vec まとめ
ここまでご覧いただきありがとうございました!
本記事では、Word2Vecについて簡単に解説してきました!
Word2Vecは自然言語処理分野の中で非常に有名な手法ですので是非この機会におさえておきましょう!
ちなみにOpenAIがEmbeddingAPIという単語をベクトル化するAPIを提供しており、そちらを使えば簡易的に単語をベクトル化することが可能です(少々API利用料がかかりますが・・・)。
以下の記事で詳しく解説しているのでぜひチェックしてみてください!

先ほどもお伝えしましたが、自然言語処理についてもっと詳しく知りたいという方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の自然言語処理講座をチェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!