seq2seqの仕組みをわかりやすく解説!Pythonで翻訳モデルを呼び出して使ってみよう!

こんにちは!データサイエンティストのウマたん(@statistics1012)です!
この記事では、ディープラーニング進化の軌跡の中で重要な手法であるseq2seqについて分かりやすく解説していきます!
ディープラーニング系、その他のAI用語を一挙にまとめた以下の記事も合わせて要チェックです!

それでは見ていきましょう!
以下のYoutube動画でも分かりやすく解説していますのであわせてチェックしてみてください!
seq2seqとは?
seq2seqはその名の通り、sequenceをsequenceに変換する手法。
sequenceとは時系列データ(主に自然言語データ)のことなので、つまりは特定の時系列データを特定の時系列データに変換するということ。
2014年に発表された手法で当時様々な自然言語タスクの精度を向上させ話題になりました。
論文は以下です。
なんとこの論文の著者は、OpenAIの共同創業者でOpenAIの研究開発をリードする「イリヤ・サツケバー」氏。

(出典:TIME100 AI:Ilya Sutskever)
彼は2014年Google Brainの研究者としてseq2seqの論文を発表したのです。
イリヤ・サツケバー氏は2012年のAlexNetの論文にも名を連ねるディープラーニング業界の第一人者で、様々な功績を作ってきています。
OpenAIの各種GPTモデルもイリヤ・サツケバー氏なくして作り上げられなかったことでしょう。
そんなイリヤ・サツケバー氏に関して詳しく知りたい方は以下でまとめていますのでチェックしてみてください。
さて、そんな天才研究者イリヤ・サツケバー氏が発表したseq2seqとはどんな手法なのでしょうか?
seq2seqの仕組み
改めてseq2seqの論文は以下です。
seq2seqは簡単に言うと
RNNという自然言語処理に強いディープラーニングのモデルをエンコーダ・デコーダモデルに投入したもの。
特にRNNの派生モデルであるLSTM(Long short term memory)が使われます。
エンコーダ・デコーダモデルについてはオートエンコーダの記事を参考にしてみてください。

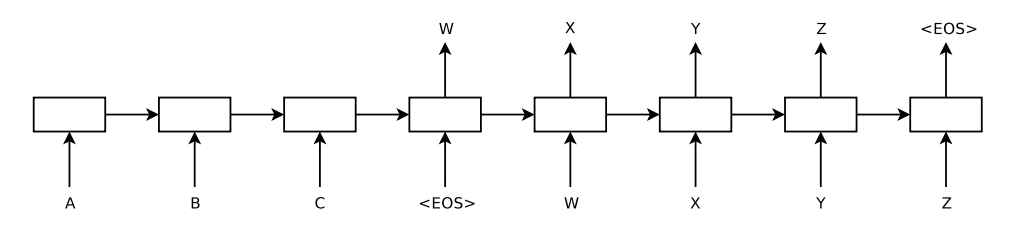
論文に記載されているアーキテクチャは以下です。
 (出典:Sequence to Sequence Learning with Neural Networks)
(出典:Sequence to Sequence Learning with Neural Networks)
1つ1つの四角が層を表しており、A,B,Cまでがエンコーダ、それ以降がデコーダの役割を果たしています。
このアーキテクチャの中では、A,B,Cという文字列をW,X,Y,Zという文字列に変換するタスクの学習が行われているのです!
ちなみにRNNの層は以下のように前の層の出力を次の層に渡すようなアーキテクチャになっています。
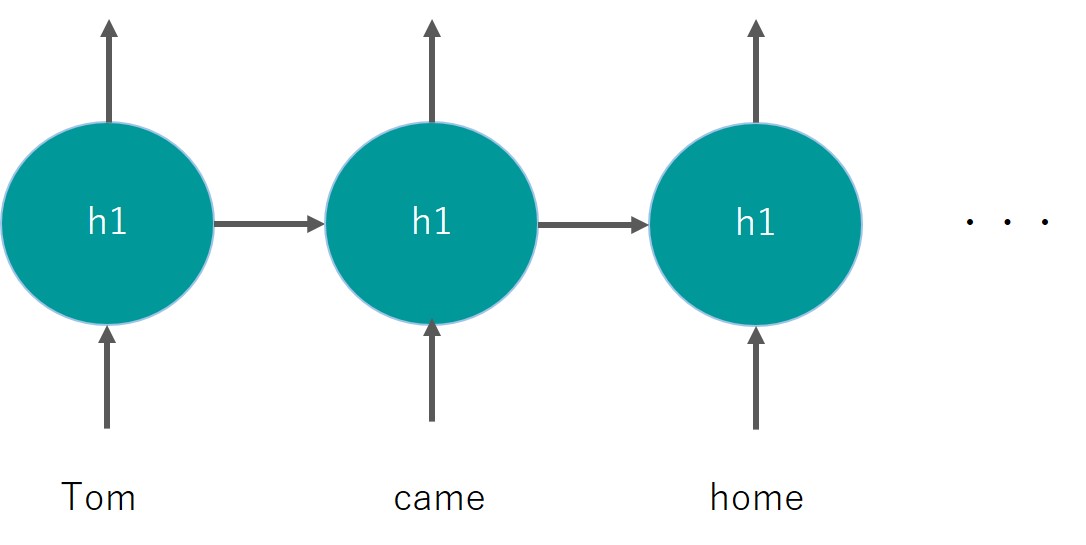
この構造により自然言語などが持っている時系列要素を情報として後続に渡すことができるのです。
ただ、ちょーっと論文のアーキテクチャのままだと分かりにくいので英語を日本語に変換する場合の例を図で見てみましょう!
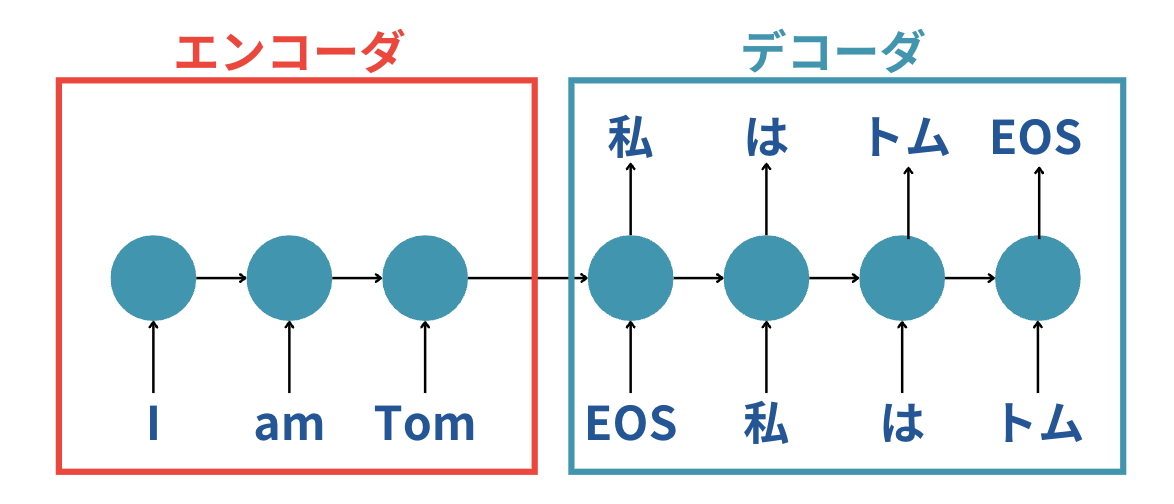
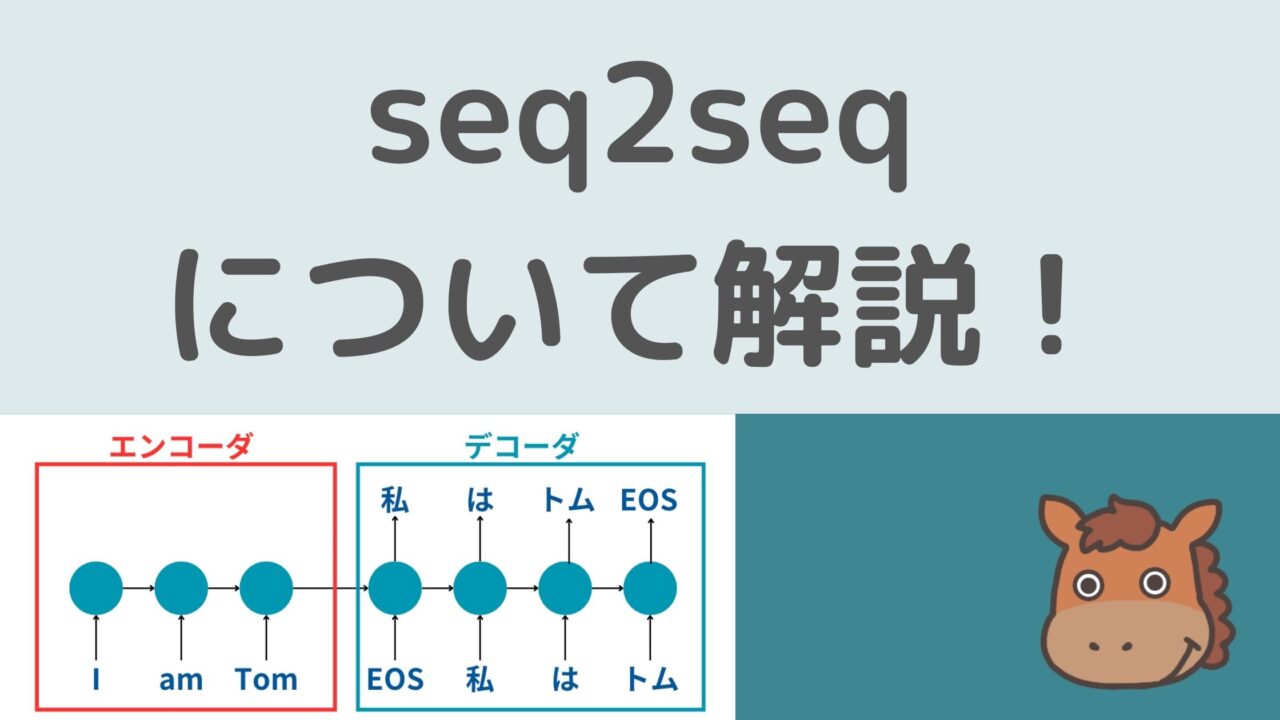
こちらは「I am Tom」という文字列を「私はトム」という文字列に翻訳する場合を取り上げています。
最初にエンコーダの部分で英語の文字列を順番に層を通して渡しながら最終的に1つの情報としてデコーダに渡しています。
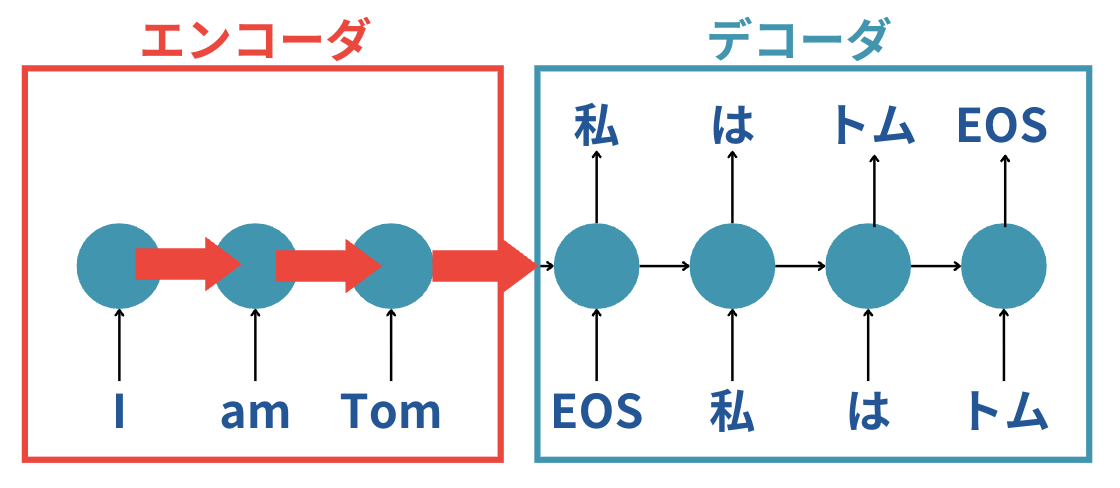
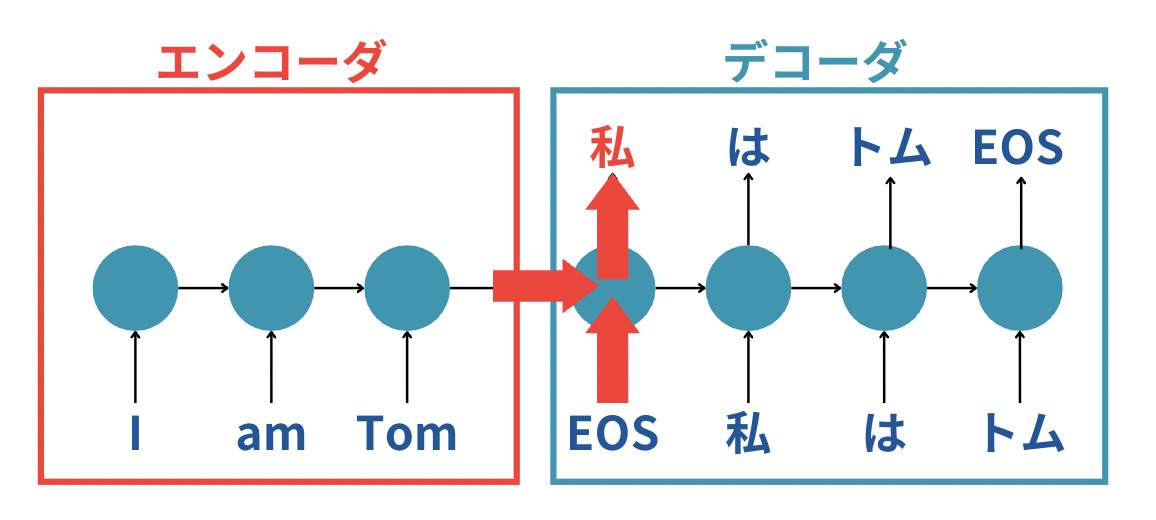
そして、それを受け取ったデコーダは「エンコーダから受け取った系列情報」と「EOS」という入力から次に来るであろう「私」を出力するというわけです。
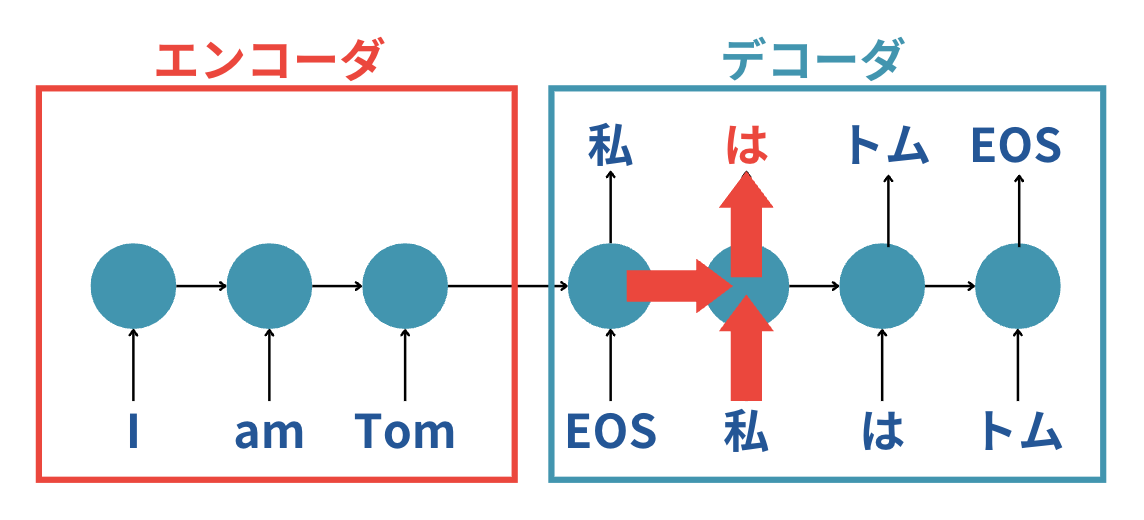
続いてさらに「これまでの過去の系列情報」と「私」というインプットから「は」という文字列を出力します。
このアーキテクチャを元に、多くの英語と日本語のペア教師データを学習していくと、正しい翻訳タスクが出来るモデルが出来上がるというわけなのです!
seq2seqのモデルをPythonで呼び出して翻訳をしてみよう!
それでは続いてseq2seqをベースにしたモデルを呼び出して使ってみましょう!
seq2seqは広い意味でシークエンスをシークエンスに変換するモデルのことを指すので厳密に2014年に発表されたseq2seqのアーキテクチャではないことも多いです。
ここでは、HaggingFaceという機械学習モデルを公開するプラットフォームから見ていきます。
HaggingFaceには翻訳タスクに関するチュートリアルを記載したページがあります。
この翻訳タスクについて解説したページに以下のように記載されています。
Helsinki-NLP という組織が多言語で1000以上のモデルを提供しています。
そう、ヘルシンキのNLPを研究する組織がいろんな翻訳タスクに適用したモデルを公開してくれているのです。
ということで早速そのモデルを呼び出して翻訳をやってみましょう!
実行環境としてGoogle Colabをオススメします。
from transformers import pipeline
# 翻訳パイプラインの初期化(英語からフランス語への翻訳モデルを使用)
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-en-fr")
# 翻訳したい文章
text_to_translate = "Hello, how are you?"
# 翻訳の実行
translated_text = translator(text_to_translate)[0]['translation_text']
print("元の文章:", text_to_translate)
print("変換後の文章:", translated_text)
結果は以下のようになりました。
元の文章: Hello, how are you?
変換後の文章: Bonjour, comment allez-vous ?
変換後の文章がフランス語なので分かりにくいですが、調べるとちゃんと翻訳されていることが分かります。
では、日本語への変換はどうでしょう?
英語から日本語への変換モデルもあるので試してみましょう!
from transformers import pipeline
# 翻訳パイプラインの初期化(英語から日本語への翻訳モデルを使用)
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-en-jap")
# 翻訳したい文章
text_to_translate = "Hello, how are you?"
# 翻訳の実行
translated_text = translator(text_to_translate)[0]['translation_text']
print("元の文章:", text_to_translate)
print("変換後の文章:", translated_text)
結果は以下のようになりました。
元の文章: Hello, how are you?
変換後の文章: 陰府 よ , おまえ は どう し て い る の か.
いや精度悪すぎ・・・陰府とは地獄と同じ意味なのでHelloをHellと勘違いしているようですし、how are youも直訳しすぎて違和感しかないですね・・・
日本語のデータセットが少ないためあまり精度の良いモデルを作ることができていないようです。
そう考えると最近のGPTモデルの精度の高さに改めて驚きますよね。
そもそもGPT3の時点で、特定の翻訳タスクに特化したモデルを作らなくても「英語に翻訳して」という文章の後に確率的に近づく言葉をつないでいったら翻訳タスク的なことができるようになってるのです。
とはいえ、GPTモデルにつながるブレークスルーの中に今回紹介した2014年発表のseq2seqのアーキテクチャが存在することを忘れてはいけません。
seq2seq まとめ
ここまでご覧いただきありがとうございました!
本記事では、seq2seqについて解説してきました!
2014年に発表された手法でこれまでのディープラーニングの進化の礎となっている手法ですのでしっかり理解しておきましょう!
他のディープラーニングの様々なモデルを知りたい方は以下の記事を参考にしてみてください。
・RNN
・AlexNet
・ResNet
・Transformer
より詳しくディープラーニングや最近の大規模言語モデルについて知りたい方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の講座をチェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!