ResNetの仕組みについて論文からわかりやすく解説!Pythonで実装してみよう!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では、ディープラーニングの進化の歴史の中で欠かせない「ResNet」について解説していきたいと思います!
ResNetについて正しく理解しておきましょう!
ResNetに関しては以下の動画でもわかりやすく解説していますのであわせてチェックしてみてください!
ResNet登場以前の課題
ResNetは2015年にMicrosoft Researchチームが発表したアプローチです。
論文は以下です!
ResNetの説明に入る前にResNet登場前にディープラーニングが抱えていた課題を見ていきましょう。
ディープラーニングの中でも画像認識タスクで高い精度を出力していたCNN(畳み込みニューラルネットワーク)では層を深くしモデルを複雑にすることで精度を高めてきていました。
基本的にCNNのモデルは層を深くすることで複雑な問題に対しても適応させることができ精度が高くなると考えられていました。
しかし一定以上層を深くすると何故か精度が悪くなってしまっていたのです。
以下がその現象を表した論文に記載されている実験結果です。
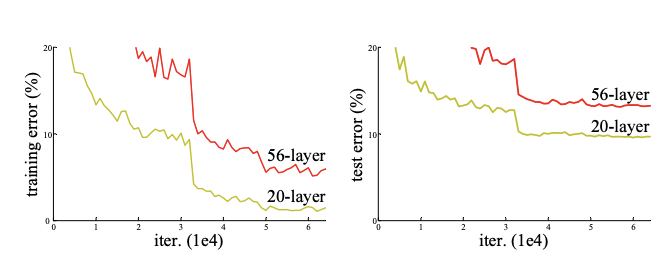
左が学習データで右がテストデータ、赤が56層のCNNで黄色が20層のCNNになります。
そうなんです、モデルが複雑になることで学習データに過度に適合してしまう過学習が起きてテストデータで精度が下がることは考えられますが、その場合は学習データでは精度が上がるはずです。
しかし今回のケースは学習データでも層が深いモデルの方が精度が下がっている・・・ということは過学習ではない根本的な問題が起きているんです。
論文には以下のように記載されています。
When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error
劣化問題 (degradation problem)という問題が起きて、これにより精度改善の頭打ちが起きている、そしてどうやら過学習による問題ではなさそうだということが書いてありますね。
この課題を解決したのが、まさにResNetなのです!!
ResNetとはどんなモデル
それではResNetではどうやって先ほどの課題を解決したのでしょうか?
論文からアーキテクチャを拝借して見てみましょう!
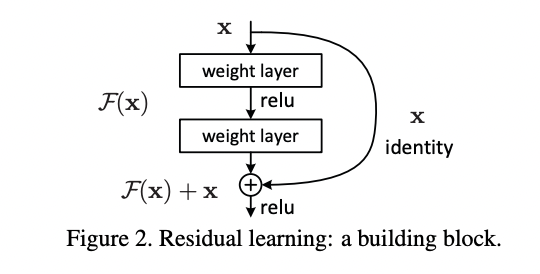
xという入力に対して、通常のレイヤー(層)を通るルートとレイヤーを通らずにショートカットしている層があることが分かると思います!
これによりシンプルな\(F(x)\)だったのが\(F(x) + x\)になることが分かります。
ちなみにこのショートカットのことを論文では「shortcut connections」と表現しています。
それでは、これは一体何がよいのでしょうか?
層が複雑になってくると入力の結果をそのまま出力する恒等写像をしたい場合が出てきます。
恒等写像は\(F(x) = x\) になる恒等関数で表現できます。
一般的にF(x)の関数のパラメータは膨大になっているので、入力に出力を合わせる\(F(x) = x\)にするのはそんなに簡単ではありません。
そこでその作業をディープラーニングに頑張ってもらうよりも作為的に恒等関数を作りやすい環境を作ってあげようよというのがResNetのアプローチなのです。
\(F(x) + x\)であれば\(F(x)\)内のパラメータを全て0にして\(F(x) = 0\)にしてしまえば、\(F(x) + x = x\)になりますよね?
よって簡単に恒等写像を実現できるのです!!
ResNetのパフォーマンス
それでは、そんなResNetのパフォーマンスをながめてみましょう!
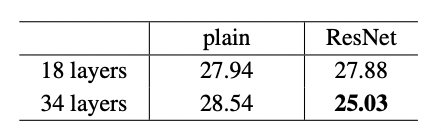
この結果を見てみると、通常(Plain)のモデルでは18層から34層に層を深くするとエラー率が悪化してしまっているのですが、ResNetでは34層に増やすことでエラー率が改善していることが分かります。
論文には他にも様々なパフォーマンス比較結果がまとめられているので興味のある方はぜひ論文を見てみてください!
ResNetをPythonで実装してみよう!
それではResNetをPython×Kerasで実装してみましょう!
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.optimizers import Adam
# Load CIFAR-10 data
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# Preprocess the data
train_images = train_images.astype('float32') / 255
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# Define the model
model = models.Sequential()
model.add(ResNet50(include_top=False, weights=None, input_shape=(32, 32, 3), pooling='avg'))
model.add(layers.Dense(10, activation='softmax'))
# Compile the model
model.compile(optimizer=Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# Train the model with a reduced number of epochs to minimize processing time
model.fit(train_images, train_labels, epochs=1, batch_size=64, validation_split=0.1)
# Evaluate the model
test_loss, test_acc = model.evaluate(test_images, test_labels)
# Print the test accuracy
print(f'Test accuracy: {test_acc:.4f}')
ここでは、CIFAR-10のデータセットを使用しています。
CIFAR-10は10個のクラスに分けられたカラー写真のデータセットで画像認識の評価によく利用されます。
# Define the modelの箇所でResNetのアーキテクチャを定義しています。
models.Sequential()は、層を順番に積み重ねたモデルを作成します。このモデルでは層が一列に並んでます。
その後、ResNet層を追加しています。
ResNetの引数について確認しておきましょう!
まずはinclude_top引数!
include_top引数は、モデルの出力層(全結合層)を含めるかどうかを決定します。
Falseに設定すると、出力層を含まず、特徴抽出部分のみを取得します。
これにより、新しい出力層を追加してタスクに合わせてモデルをカスタマイズできます。
weightsは、モデルを初期化するための重みを決定します。
Noneを設定すると、ランダムな初期値から学習を始めます。
‘imagenet’を設定すると、ImageNetデータセットで事前訓練された重みを使用します。
input_shape=(32, 32, 3)はモデルの入力サイズを定義します。
CIFAR-10の画像は32×32ピクセルで、3チャンネル(RGB)ですので、この値を設定しています。
pooling=’avg’は、include_top=Falseとした場合に、モデルの最後の層の後にGlobal Average Pooling層を追加するかどうかを指定します。
値は’avg’(平均プーリング)または’max’(最大プーリング)が選べます。
また、model.fit(train_images, train_labels, epochs=1, batch_size=64, validation_split=0.1)の箇所でepochsを1と指定していますが、通常はエポック数は複数回ある方が望ましいので適宜指定してください。
エポック数が多いと処理に時間がかかるため今回は1を指定しています。
ResNet まとめ
ここまでご覧いただきありがとうございました!
本記事ではResNetについて解説してきました。
ResNetはディープラーニングの進化の歴史の中でも大きなブレークスルーを起こした重要な手法です。
しかし、そのアプローチは「恒等写像を簡単に作るために入力をショートカットしてプラスする処理を追加する」というシンプルなものだったのです!
AIは日進月歩で日々進化しています。
最新の生成系AIについて知りたいという方はぜひスタビジアカデミーの大規模言語モデル・生成系AIコースを覗いてみてください!
「スタアカ(スタビジアカデミー)」は当メディアが運営するAI特化の教育サービス。興味のある方はチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!