
画像生成AIで頻出の拡散モデルについて分かりやすく解説!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では、「拡散モデル(diffusion model)」について解説していきたいと思います。
拡散モデルとは最近流行りの画像生成AIであるDALL・E2やStable Diffusionなどのベースになっている技術であり話題になっています。
そんな拡散モデルについて簡単に解説していきます。
以下の動画でも分かりやすく解説していますのであわせてチェックしてみてください!
拡散モデル(diffusion model)とは
拡散モデルを発表した最初の論文は以下です。
DDPMと略されることもあり、そのまま直訳するとノイズ除去拡散確率モデルとなります。これを拡散モデルと呼びます。
一言で言うと、「ある画像に対してランダムノイズを徐々に当てていき完全にノイズになったものを逆向きに推定した際にノイズ除去後の画像と元の画像の差分を少なくするように学習した技術」です。
以下は論文から引用した図です。
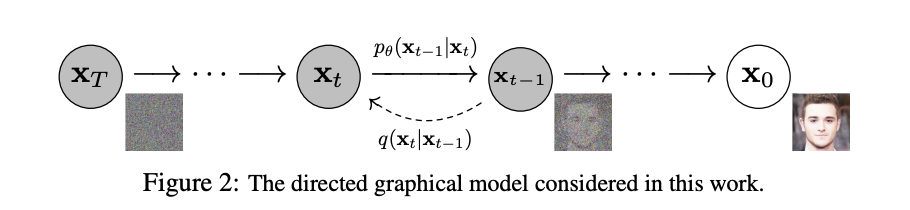
\(X_0\)の人間の顔画像に対してランダムノイズを当てていき、最終的に完全なノイズになっているのが\(X_T\)ですね。
このランダムノイズを与える過程を逆に遡った時に元の画像と近い画像が得られるようにパラメータを最適化するのが拡散モデルの考え方です。
もう少し単純化して図で見てみましょう!
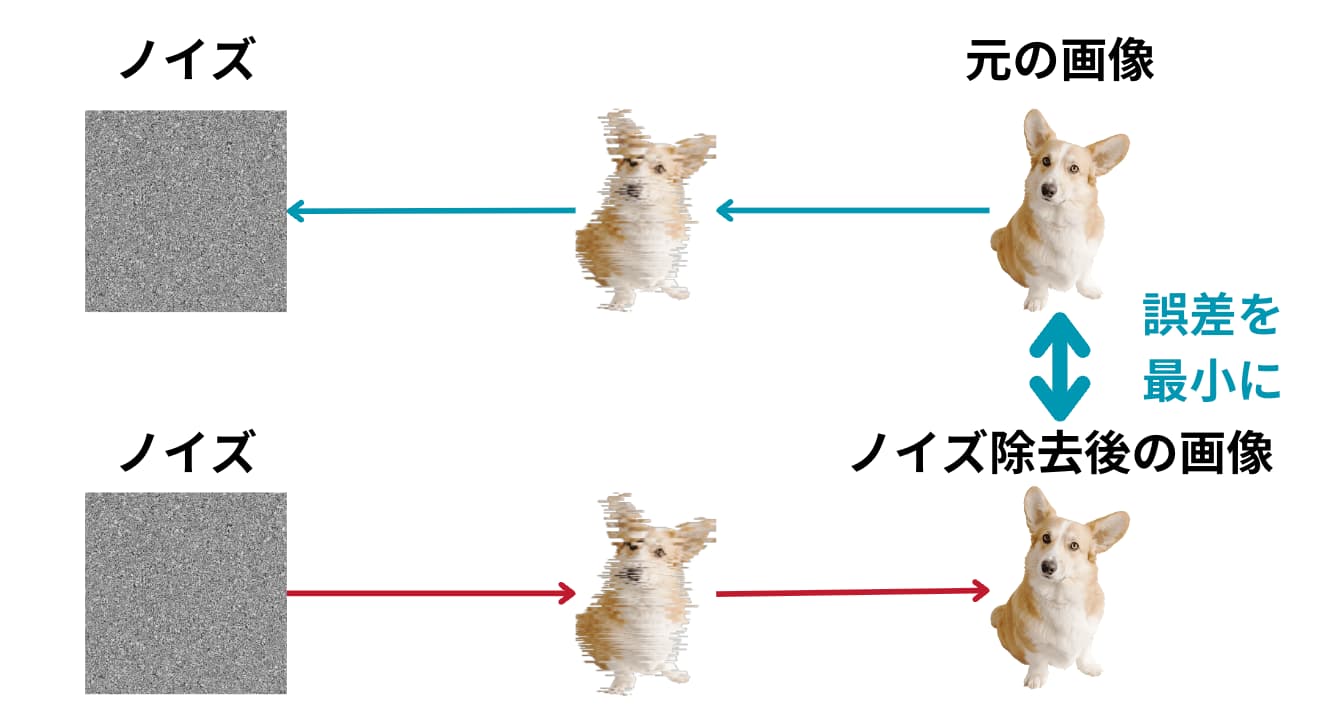
図のように犬の画像に対してノイズを乗せて、そのノイズを逆に取り除く際にノイズを取り除く部分は複数のパラメータを用いて定式化することが可能です。
ちなみに一般的にノイズには正規分布(ガウス分布)に従うノイズが当てられます。
この「ノイズ取り除く過程を定式化した部分のパラメータを調整して元の画像との差分を小さくする試み」が拡散モデルなのです!
このノイズ取り除き過程におけるパラメータ推定にはTransformerというニューラルネットワークをベースにしたアーキテクチャが使われることが多いです。
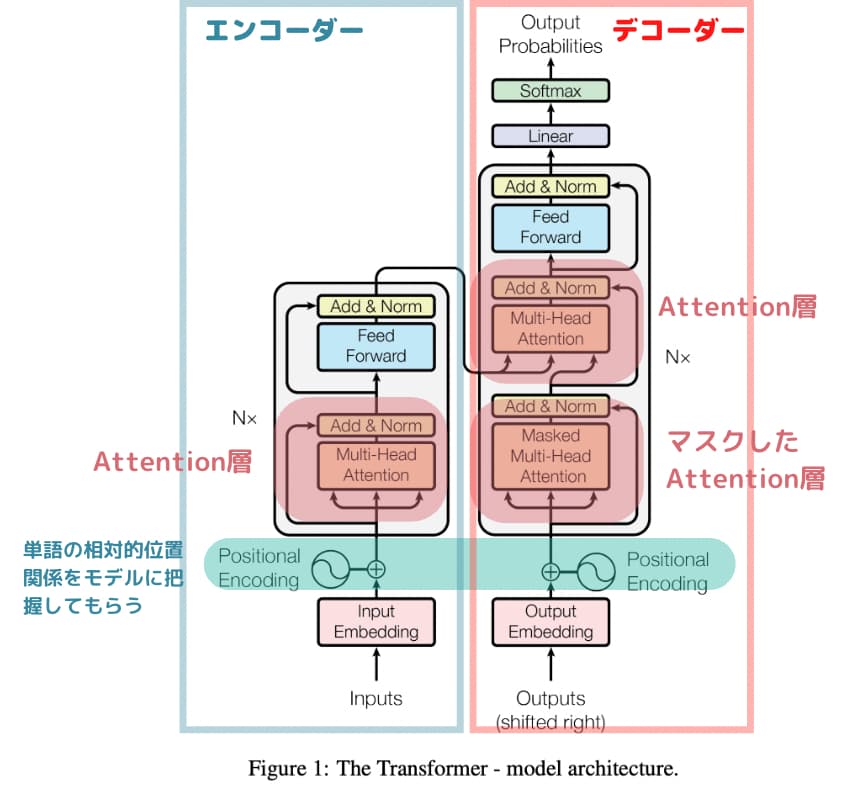
Transformerは2017年に登場した手法であり、昨今のAIブームはこのTransformerの登場によるものと言っても過言ではありません。
詳しくは以下の記事でまとめています。
ちなみに拡散モデル以前もGANなど他の画像生成手法がありましたが、拡散モデルは従来の手法に比べてバリエーションに富んだ画像を生成することが可能です。
拡散モデルを用いた応用手法
前述の拡散モデルのアーキテクチャを見ると、どうやって指定した画像を生成するの?と思った方も多いのではないでしょうか?
実はその通りで、拡散モデル単体ではどんな画像を生成したいかを人間がコントロールする術がありません。
しかし現実世界では自分の生成したい画像を生成できないとあまり意味がありません。
そこで拡散モデルと他のアプローチを用いて多くの手法が提案されています。
DALL・E2
例えばOpenAIが発表したDALL・E2では、CLIPというアプローチを用いてテキストによる制御をした上で画像を生成しています。
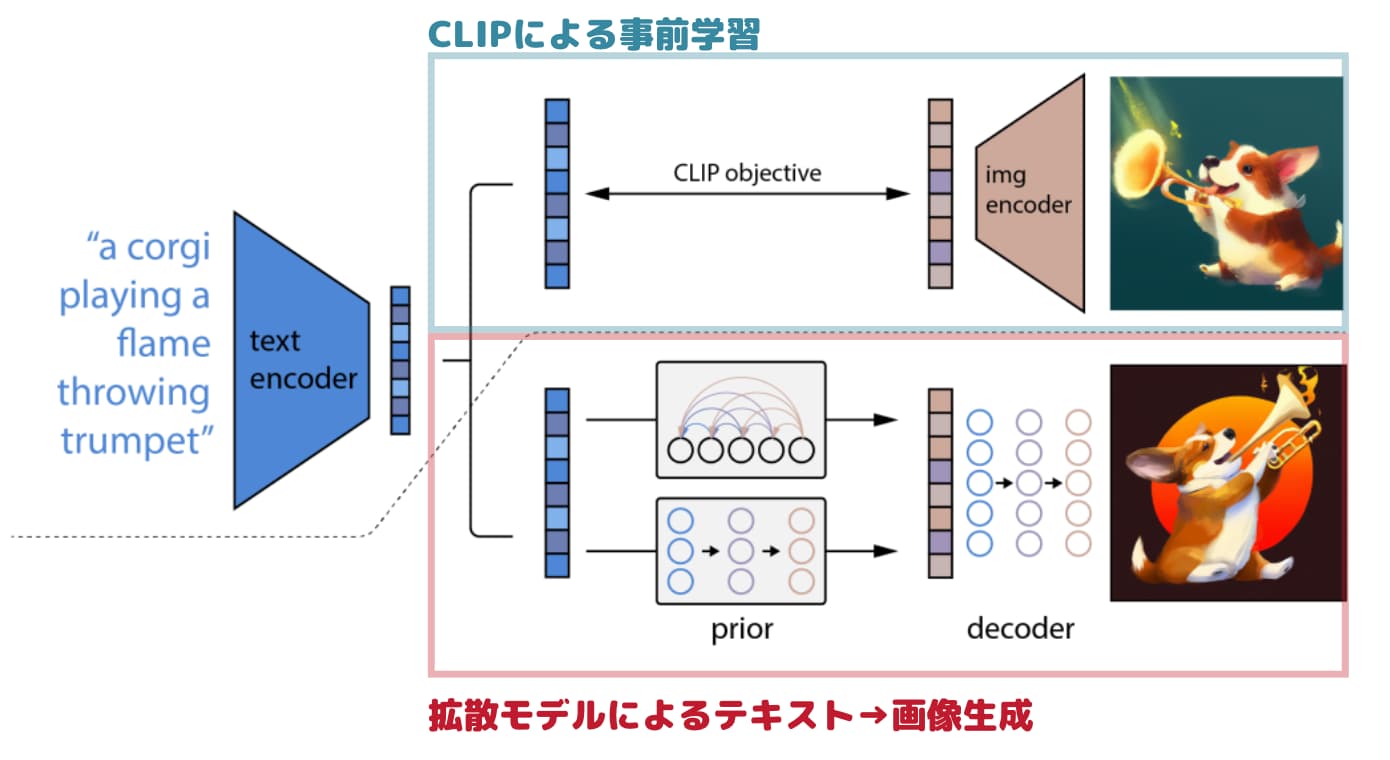 (参考:Learning Transferable Visual Models From Natural Language Supervision)
(参考:Learning Transferable Visual Models From Natural Language Supervision)
テキストによる条件付けをすることによりテキストによって画像生成を制御することが可能になるのです!
学習過程で画像をエンコーディングした情報をインプットしてあげれば、画像から画像を生成するimage to imageを行うことが可能です。

DALL・E2に関しては以下の記事で解説していますので是非チェックしてみてください!

Stable Diffusion
高精度の画像を生成できることで話題のStable Diffusion!
Stable Diffusion自体の論文は公開されていませんが、詳しい解説が公式のGithub上に記載されています。
Stable Diffusionはオープンソースで世界中の誰でもプログラムを確認できるようになっているんです!
リポジトリの最初に書いてある文章を見てみましょう!
Stable Diffusion is a latent text-to-image diffusion model. Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512×512 images from a subset of the LAION-5B database. Similar to Google’s Imagen, this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
(出典:Stable Diffusionの公式Githubリポジトリ)
CLIPはDALL・E2と一緒で潜在拡散モデルは画像の特徴をおおまかに捉えた低次元の潜在空間に変換してあげて拡散過程を適用させて計算量を減らしているアプローチになります。
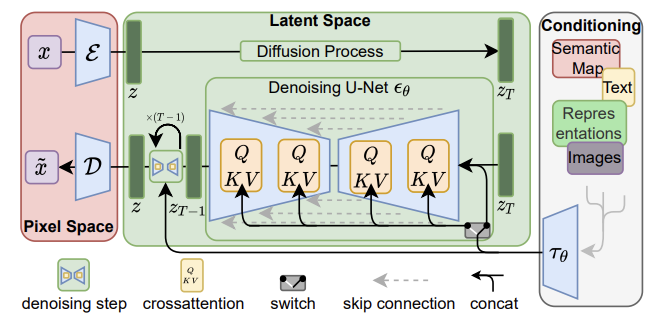 (出典:High-Resolution Image Synthesis with Latent Diffusion Models)
(出典:High-Resolution Image Synthesis with Latent Diffusion Models)
Stable DiffusionではLAIONという非営利組織が提供するLAION-5BというデータセットのサブセットLAION-AESTHETICSを利用して学習しています。

LAION-5Bは、前述のCLIPでフィルタリングされた58億5千万組の画像・テキストデータセットです。
そのLAION-5Bから美しい画像のみをピックアップして構成されているLAION-AESTHETICSを元に学習することで高画質の美しい画像をアウトプットできるようにしているのも特徴の1つです。
詳しくは以下の記事で解説していますのでチェックしてみてください!

Imagen
続いてImagen。
ImagenはGoolgleが2022年5月にリリースした画像生成系AIで以下は実際にImagenが生成した画像群です。

論文とGoogle公式のリリースHPは以下です。
論文:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Google公式HP:Imagen:unprecedented photorealism × deep level of language understanding
それでは、Imagenのアーキテクチャを見ていきましょう!
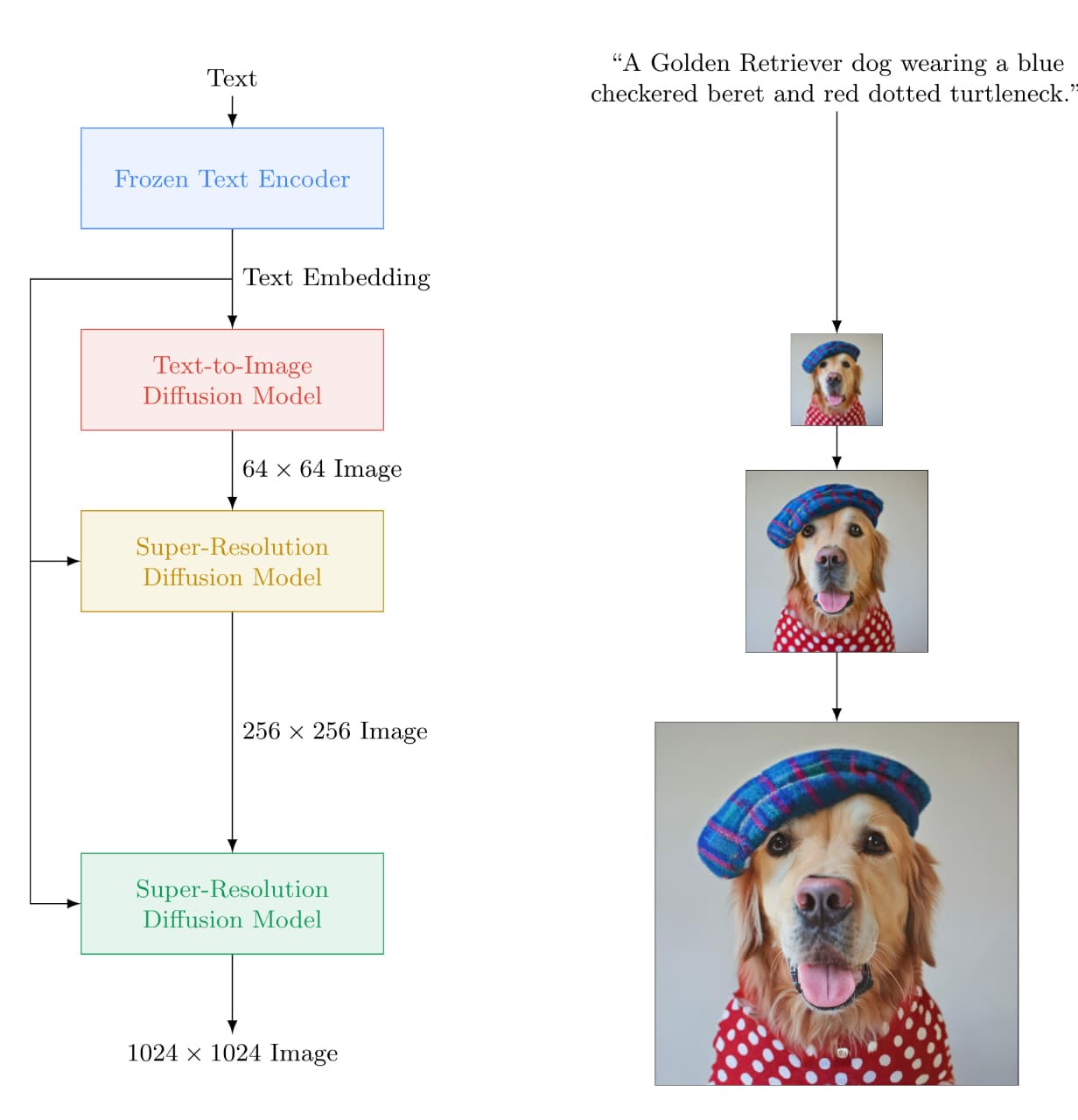
左側がImagenのアーキテクチャになります。
非常にシンプルでして、
- Frozen Text Encoder:まず最初にテキストをエンコーディング
- Text-to-Image Diffusion Model:テキストを画像に変換する拡散モデル
- Super-Resolution Diffusion Model × 2:画像の解像度を上げる拡散モデル
の流れになっています。
Imagenについて詳しくは以下の記事で解説しています!

拡散モデル まとめ
ここまでご覧いただきありがとうございました!
今回は画像生成分野において多くの手法に用いられている拡散モデルについて簡単にまとめてきました!
拡散モデルの概要を理解した後は、実際に画像生成技術を触ってみることが大事です!
生成系AIを利用する方法を知りたい方は当メディアが運営するスタアカの以下のコースを是非チェックしてみてください!
スタアカは業界最安級のAIデータサイエンススクールです。

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
・生成系AIの基礎や使い方を学ぶ
AIデータサイエンスを学んで市場価値の高い人材になりましょう!
データサイエンスやAIの勉強方法は以下の記事でまとめています。


 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















