
Googleの画像生成系AI「Imagen」について分かりやすく解説!DALL・E2との違いは!?


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
様々な企業が生成AI開発にしのぎを削る中、Googleが2022年にリリースしたImagen。
先行してリリースされていたDALL・E2よりも良いパフォーマンスを出力したことなどが報告され話題になりました。
この記事では、そんなImagenについてなるべく分かりやすく解説していきます!
以下のYoutube動画でも分かりやすく解説していますので合わせてチェックしてみてください!
Imagenとは
それではImagenについて詳しく見ていきましょう!
ImagenはGoolgleが2022年5月にリリースした画像生成系AIで以下は実際にImagenが生成した画像群です。

論文とGoogle公式のリリースHPは以下です。
論文:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Google公式HP:Imagen:unprecedented photorealism × deep level of language understanding
それでは、Imagenのアーキテクチャを見ていきましょう!
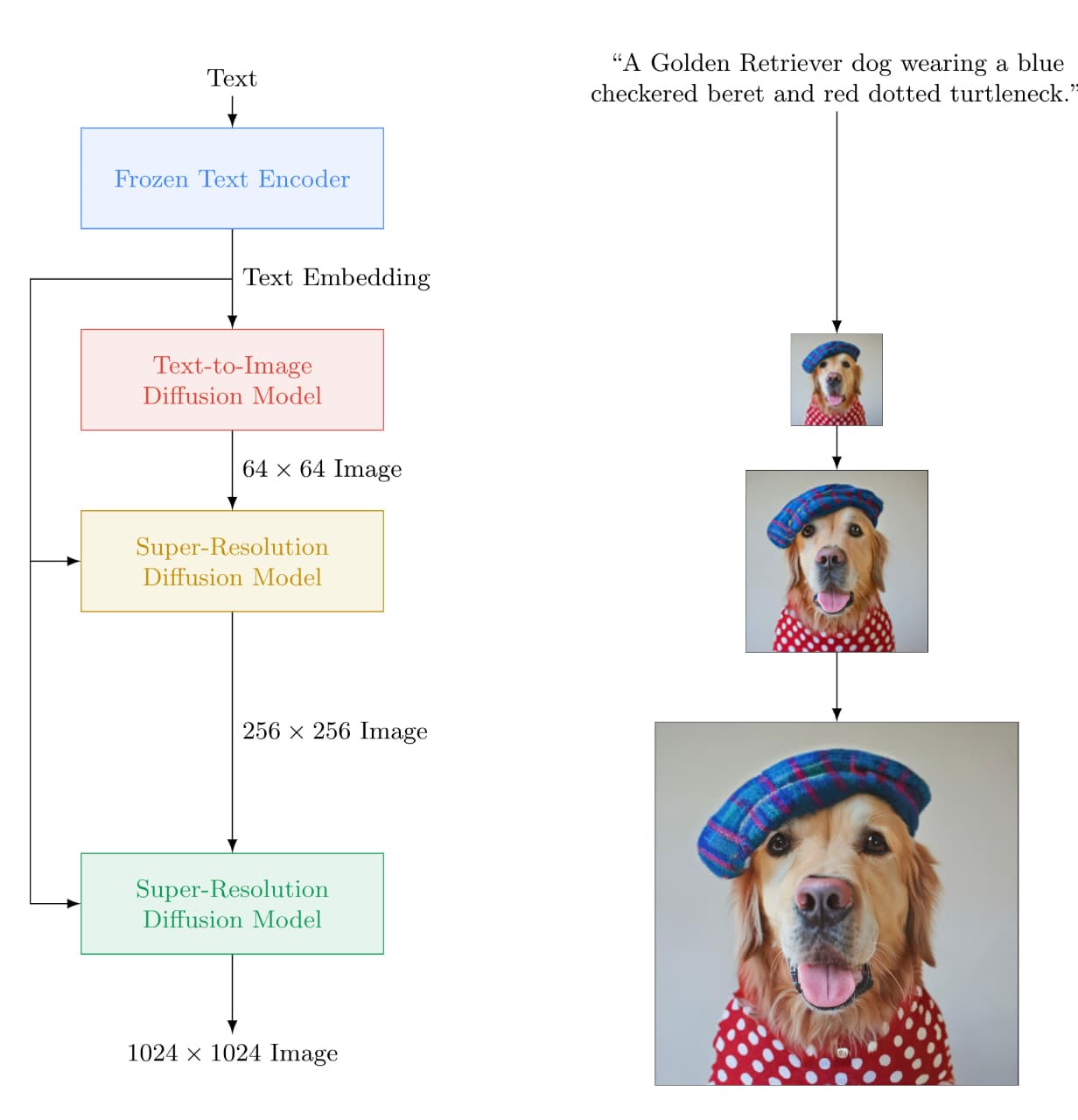
左側がImagenのアーキテクチャになります。
非常にシンプルでして、
- Frozen Text Encoder:まず最初にテキストをエンコーディング
- Text-to-Image Diffusion Model:テキストを画像に変換する拡散モデル
- Super-Resolution Diffusion Model × 2:画像の解像度を上げる拡散モデル
の流れになっています。
そして大きく分けるとテキストをエンコーディングするフェーズと拡散モデルにより画像を生成するフェーズに分かれます。
テキストをエンコーディングするフェーズ
実は、Imagenのキーポイントはテキストをエンコーディングする部分のモデルを非常に巨大な大規模言語モデルにしたところにあるのです。
論文から一部文章を引用してみましょう!
Our key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and imagetext alignment much more than increasing the size of the image diffusion model
(出典:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding)
この研究でのキーとなる発見は自然言語モデルにあると言ってますね。
事前学習済み大規模言語モデルのサイズを大きくした方が拡散モデルのサイズを大きくするよりも効果的だと述べています!
現実だとなかなか存在しないような難しい表現も大規模言語モデルにより文脈を理解し画像に落とし込むことが可能になってるんです!
拡散モデルで画像を生成するフェーズ
そしてそして拡散モデルのフェーズ。
ご多分に漏れずImagenもDALL・E2やStable Diffusionと同じく拡散モデルをベースにしています。
拡散モデルとは、一言で言うと「ある画像に対してランダムノイズを徐々に当てていき完全にノイズになったものを逆向きに推定した際にノイズ除去後の画像と元の画像の差分を少なくするように学習した技術」です。
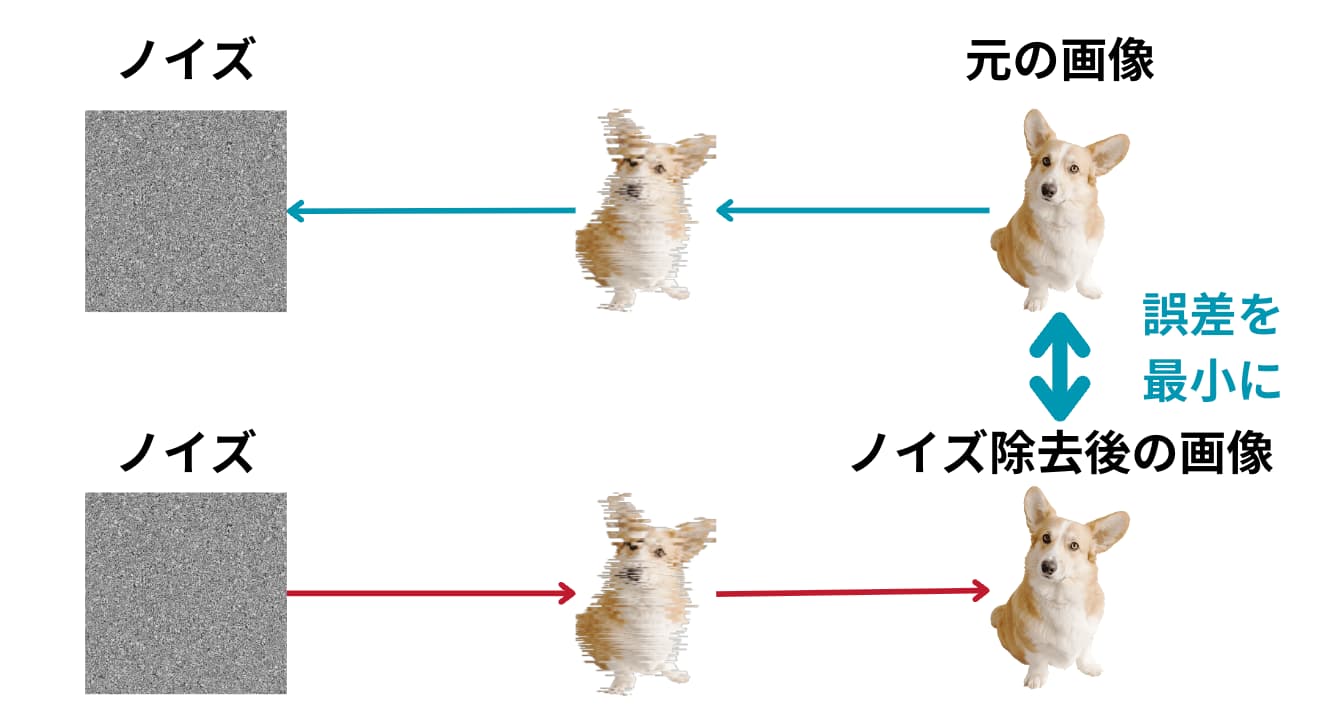
図のように犬の画像に対してノイズを乗せて、そのノイズを逆に取り除く際にノイズを取り除く部分は複数のパラメータを用いて定式化することが可能です。
ちなみに一般的にノイズには正規分布(ガウス分布)に従うノイズが当てられます。
この「ノイズ取り除く過程を定式化した部分のパラメータを調整して元の画像との差分を小さくする試み」が拡散モデルなのです!
拡散モデルについて詳しくは以下の記事で解説しています!
ImagenとDALL・E2の違い
それでは、続いてImagenとDALL・E2との違いについて見ていきましょう!
まずはアーキテクチャの違いを見て、手法の比較検証結果について見ていきましょう!
アーキテクチャの違い
DALL・E2の論文は以下です。
以下がDALL・E2のアーキテクチャです。
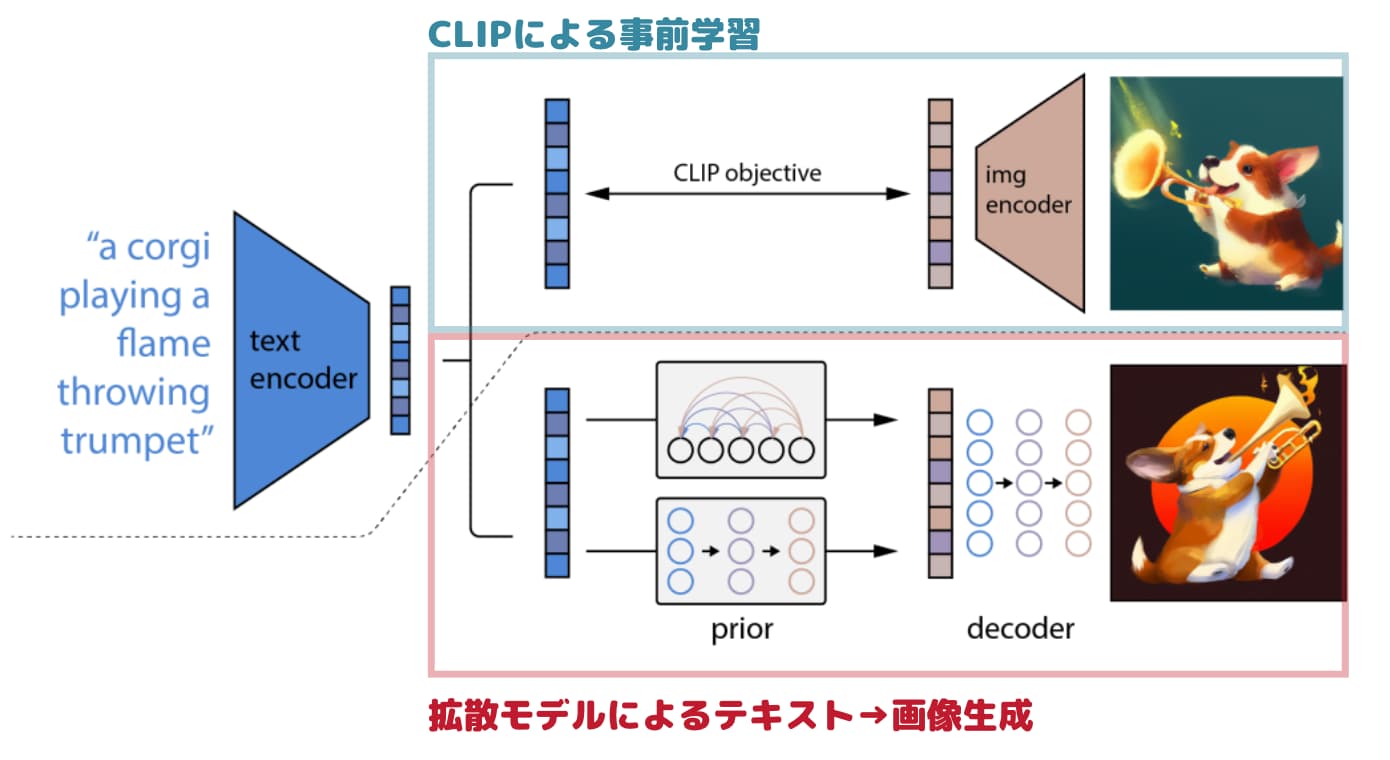
ザックリ言うとDALL・E2はCLIPと拡散モデルの組合わせで出来ています。
CLIPとは画像とテキストの類似度を算出して学習するアプローチです。

Imagenはテキストのみで大量に学習させた大規模言語モデルであったのに対して、DALL・E2ではCLIPというアプローチでテキストと画像の組み合わせの類似度を算出しているということです。
Imagenのアプローチの方が圧倒的に多くのデータを学習できるため複雑なテキストインプットに対しても適切な画像を生成できると述べられています!
手法の比較結果
それでは実際に各手法の精度を比較した結果を見てみましょう!
以下が結果です。
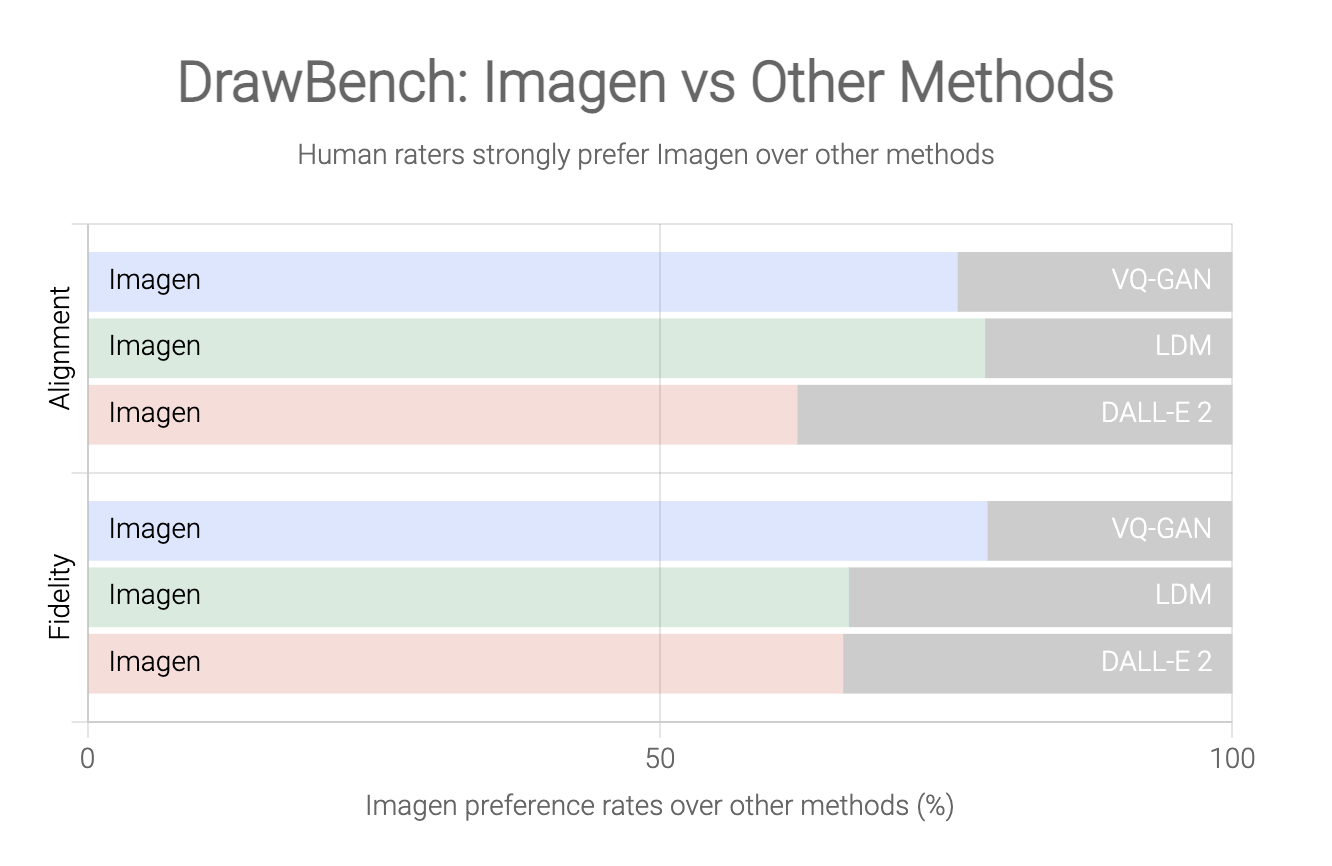
AlignmentとFidelityという指標が登場しましたが、それぞれ
Alignment:整合性と訳され、生成画像が本物の画像にどれだけ近いかを測る指標
Fidelity:忠実度と訳され、生成画像がテキストで指示したものにどれだけ近いかを測る指標
となります。
すなわち「犬」というテキストがあった時にアウトプットがちゃんと犬になっているかどうかを測るのがFidelityであり、どんなアウトプットであったとしてもそれが本物の画像に近いかどうか・違和感はないかを測るのがAlignmentだということですね!
それぞれのモデル(LDMはLatent Diffusion Modelで潜在拡散モデル)と比較してImagenが良い精度を叩き出していることが分かりますね!
Imagen まとめ
ここまでご覧いただきありがとうございました!
本記事では、Googleが2022年にリリースした画像生成系AIのImagenについて解説してきました!
画像生成系AIの進化には今後も期待ですね!
ぜひ他の画像生成系AIについても理解を深めておきましょう!
より詳しくディープラーニングや最近の大規模言語モデルについて知りたい方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の講座をチェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















