
【入門者向け】scikit-learn(サイキットラーン)の使い方について徹底解説して実装していく!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です。
機械学習手法を簡単に呼び出して使うことのできる必須ライブラリ「Scikit-learn」について解説していきます!
データ加工に使う時もありますよ!
データ分析の工程において、やっぱりモデル構築というのは花形でありデータ分析の醍醐味です。
無数の機械学習手法がある中で「どの手法を選ぶか」は非常に大事。

この記事を読めばScikit-learnの正しい使い方や実装方法が分かるようになります!
ちなみにScikit-learnで登場する各種機械学習について学び実装していきたい方は当メディアが運営するスタビジアカデミーをチェックしてみてください!
業界最安級のデータサイエンティスト特化スクール:スタビジアカデミー
Scikit-learnとは
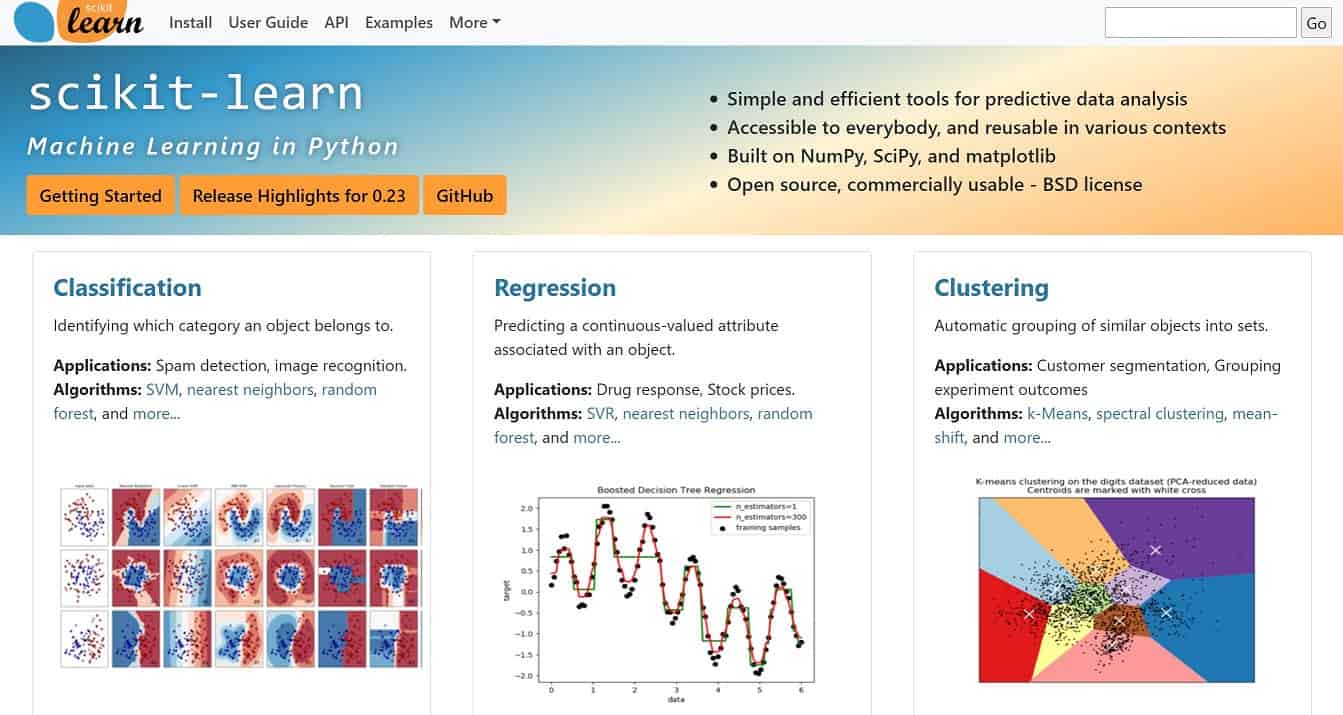
Scikit-learnはPythonのオープンソース機械学習ライブラリです。
Scikit-learn公式ドキュメント:https://scikit-learn.org/stable/
Scikit-learnの読み方は「サイキットラーン」。
誰でも自由に使えて、使える機械学習手法が多岐にわたるのでまずはScikit-learnをおさえておけば、ほとんどの機械学習手法を実装することが可能です。
ただ深層学習まわりはScikit-learnでは実装できないので、TensorflowやKerasなどを利用することになります。
Scikit-learnの使い方

それでは、そんなScikit-learnの使い方について見ていきましょう!
Scikit-learnはPythonのsklearnからモジュールを呼び出して使います。
from sklearn import linear_modelたとえばこのように記述することで線形回帰分析が使えるようになります。
Scikit-learnで使える機械学習手法については公式ドキュメントの以下のチートシートが役立ちます。
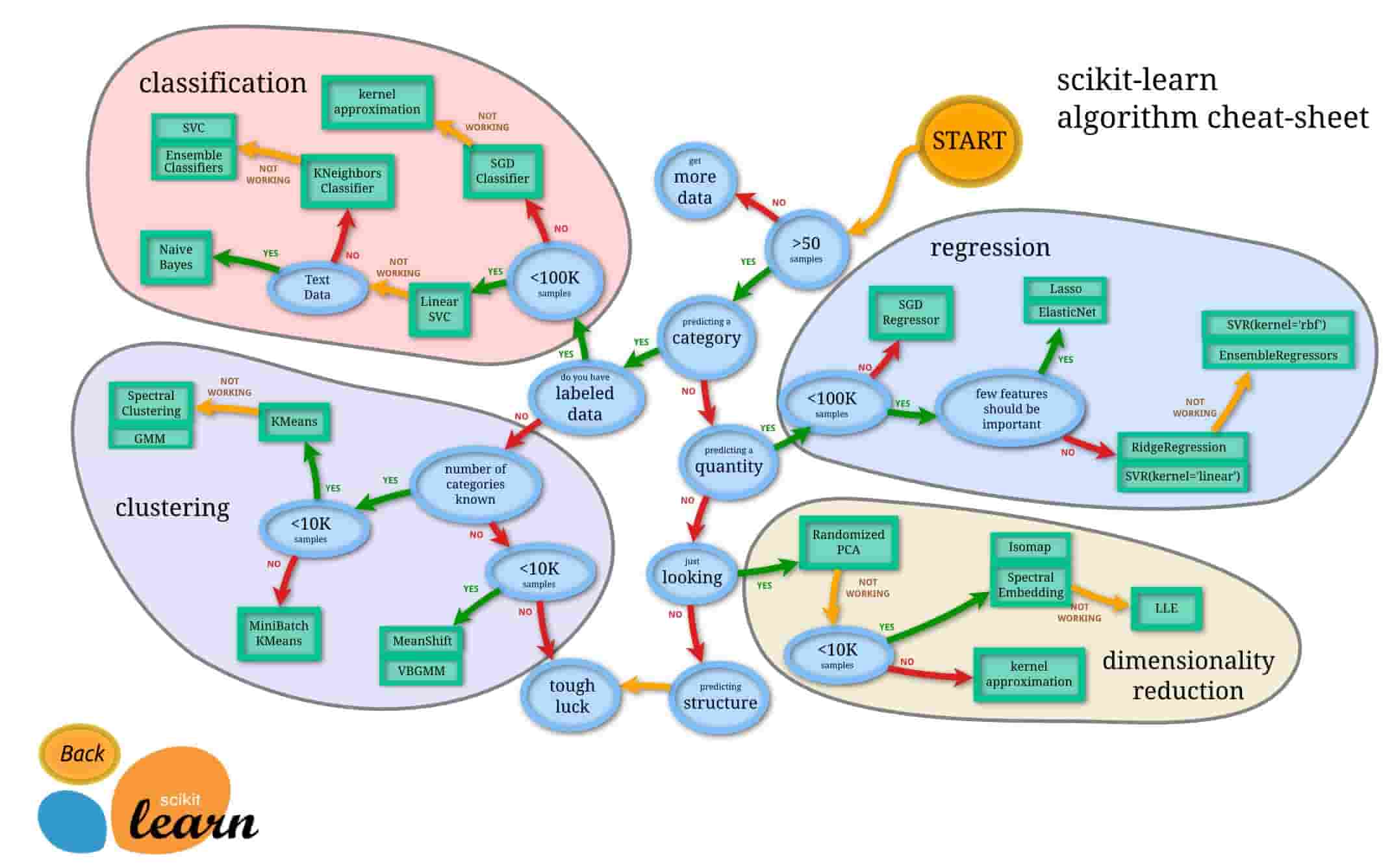 出展:https://scikit-learn.org/stable/tutorial/machine_learning_map/
出展:https://scikit-learn.org/stable/tutorial/machine_learning_map/
まずスタートして、サンプル数が50未満ならデータをもっと集めます。
そこから質的変数なのか量的変数なのか、ラベル付きの教師あり学習なのか否かなどの基準を基に分岐していきます。
何となく感覚で選んでいる機械学習手法が、このチートシートによって分かりやすく分類されます。
ぜひ、Scikit-learnを使って機械学習モデルを構築する際はこのチートシートを参考にデータを分類してみてください!
Scikit-learnを簡単に実装

それでは実際にScikit-learnを実装していきましょう!
決定木とバギングを組み合わせた強力な機械学習手法である「ランダムフォレスト」を使って定番のirisデータを分類していきます。
irisデータとはあやめの種類を分類したデータで目的変数は3カテゴリーの質的変数、説明変数は花びらの幅とか4つです。
サンプルは150個で、分類しやすいデータなのでどんな手法でも割と簡単に分類できます。
先ほどのチートシートに沿って見ていくと・・・
50サンプル以上あって目的変数が質的変数でラベル付きなので、まずは左上のClassificationに分類されますね。
そしてサンプルは100,000未満なのでLinear SVCが良いと出てきます。
Linear SVCとは線形分離をするサポートベクターマシンです。
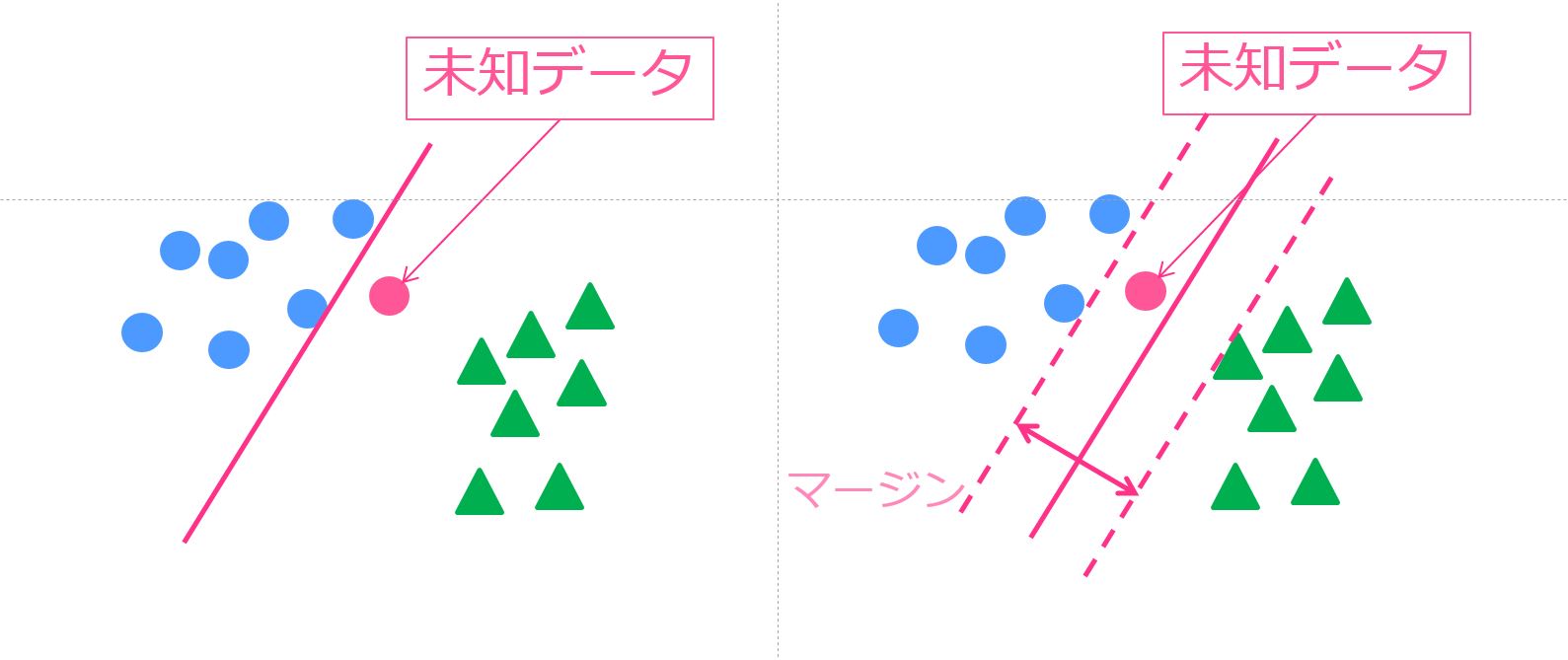
ワークしなかったら次に進めとチートシートには書いてありますが、次に進んでみましょう。
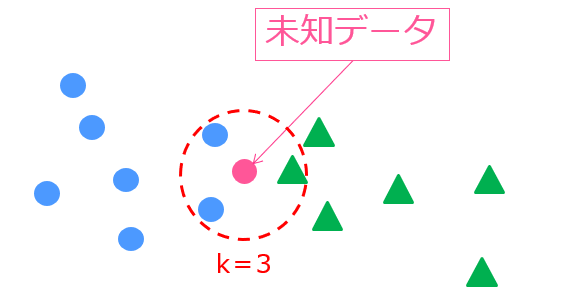
テキストデータではないので、k近傍法になります。
k近傍法は周りの学習データのクラスからその未知データの分類を決定する手法で非常にシンプルで使いやすい手法。
kとは手法に与えるパラメーターで、近くに存在する学習データのクラス数を示しています。
ここからワークしなかったら進めと書いている最終地点までいくと・・・ensemble classificationが登場しました!
このensemble classification(アンサンブル クラシフィケーション)に内包されるのが「ランダムフォレスト」!
決定木をバギング(アンサンブル学習の1つ)した手法なんです。
今回はirisデータにはオーバースペックですが、このランダムフォレストを実際に使っていきましょう!
これだけの記述でirisデータの分類モデルを構築して未知データの分類まで出来ちゃいました。
分類精度は0.9734!
分類しやすいデータなのでどの手法を使ってもそれなりの精度が出るのですが、まずまずの精度ですね!
どのような処理をおこなっているのか順を追って見ていきましょう!
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
from sklearn.model_selection import train_test_splitまずは、こちらでランダムフォレストの関数を呼び出しています。
datasetsには様々なデータセットが格納されていてirisデータはここから呼び出します。
また最後のtrain_test_splitは学習データと未知データにデータセットを分類するためのものです。
モデル構築に使ったデータをモデル評価に使ってしまうと、現状のデータに過度にフィッティングしてしまう”過学習”という問題が起きます。
予測精度の高いモデルを構築するためには、学習データと未知データを必ず分けるようにしましょう!
# irisデータの読み込み
iris = datasets.load_iris()
# 特徴量とターゲットの取得
data = iris['data']
target = iris['target']
#学習データをテストデータを分割
train_data,test_data,train_target,test_target = train_test_split(data,target,test_size=0.5)irisデータを読み込み、目的変数と説明変数に分け、学習データと未知データに分類しています。
#モデル学習
model = RandomForestClassifier(n_estimators=100)
model.fit(train_data, train_target)ここで実際にモデル構築をしています。
n_estimatorsはバギングに用いる決定木の数です。
デフォルトでは10になっています。
# 正解率を表示
model.score(test_data, test_target)最後に未知データに対してどれだけの予測精度をたたき出すことができたか算出しています。
Scikit-learnを使えば、こんなに簡単に複雑な機械学習手法を使うことが出来ちゃうんです!
ぜひScikit-learnを使ってランダムフォレスト以外の手法も使ってみてください!
Scikit-learn まとめ
本記事では、Scikit-learnの使い方や実際の実装について簡単に見てきました。
機械学習の手法はたくさんあるので、どれを使えばよいか迷うことも多いでしょう。
そんな時はぜひこのScikit-learnチートシートを見てみてください!
Scikit-learnで登場する各種機械学習について学び実装していきたい方は当メディアが運営する以下のスタビジアカデミーがオススメです!
 公式サイト:https://toukei-lab.com/achademy/
公式サイト:https://toukei-lab.com/achademy/
| 【価格】 | 98,000円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【データサイエンティスト範囲】 | Python、機械学習、統計学、ディープラーニングからDXの考え方・機械学習のビジネス導入・SQLまで必要な要素を全て網羅 |
他のスクールと比較して圧倒的なコスパでカリキュラムを提供していますよ!
また、機械学習手法やデータサイエンティストへの勉強法、Pythonの勉強法について以下の記事で詳しくまとめていますのでこちらもあわせてチェックしてみてください!



 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















