過学習とは?ランダムフォレストなどの機械学習における過学習の対策方法をまとめていく!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
普段、嘘みたいに高い予測精度を何も考えず使っていませんか?
アカデミックの世界では、当たり前のように過学習について注意されているのですが、ビジネスの世界では意外とないがしろにされていることも多いようです。
この記事では、モデル構築時に必ず陥る罠「過学習」について見ていきたいと思います。
以下の動画でも解説しています!
過学習とは
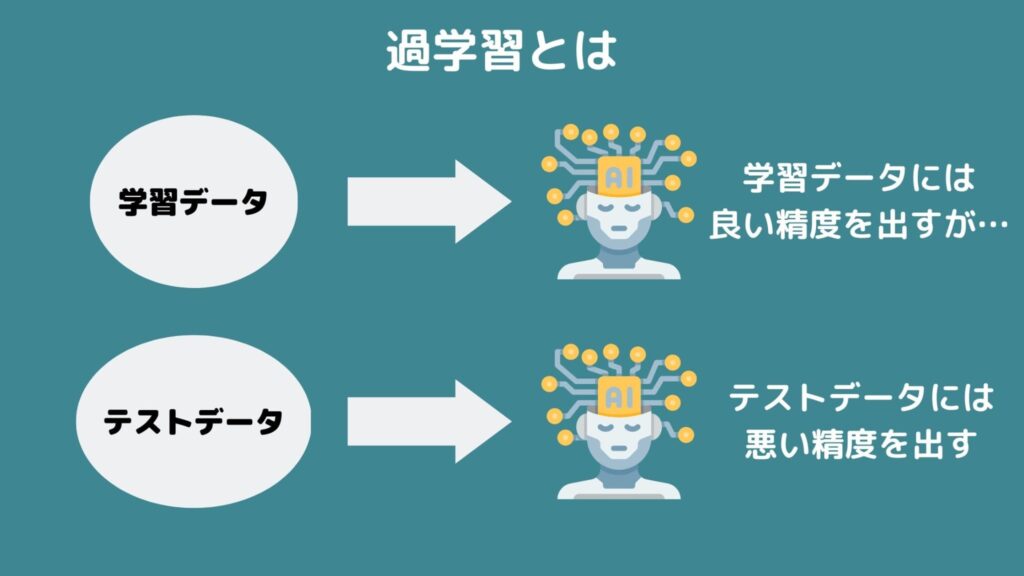
過学習は別名「オーバーフィッティング」・「過適合」とかとも言ったりしますが、データ分析の分野では有名な罠です。
簡単に言うと、手元にあるデータだけにピッタリ合い未知データに対して全く合わないモデルを作ってしまうこと。
手元のデータだけ説明できても未知のデータを説明できるとは限らないんですね。
むしろ手元のデータに対してフィッティングし過ぎると未知データの予測精度は下がってしまいます。
データには必ずノイズ(誤差)が存在するため、完璧に当てることはほぼ不可能です。
完璧に当てようとするとノイズ自体にも適合したムダに複雑なモデルを作ってしまい、未知データには上手く当てはまらなくなってしまうのです。
そんな過学習はバリアンス・バイアスと関係性が深いです。
■バリアンスは予測結果のばらつき
■バイアスは予測結果と実測値の差
もちろんバイアスが低い方がモデルとしては優秀なのですが、バイアスを低くしすぎるとノイズに対しても適合することになるので予測結果のばらつきが大きくなってくる、すなわちバリアンスが大きくなってきます。
つまり、「バリアンスが大きい状態」=「過学習している可能性がある」ということです。
バイアスとバリアンスは基本トレードオフになりますが、バイアスとバリアンスのバランスをとることが重要です。
バリアンス・バイアスに関してはこちらの記事で詳しくまとめています。

過学習を対策する様々な方法
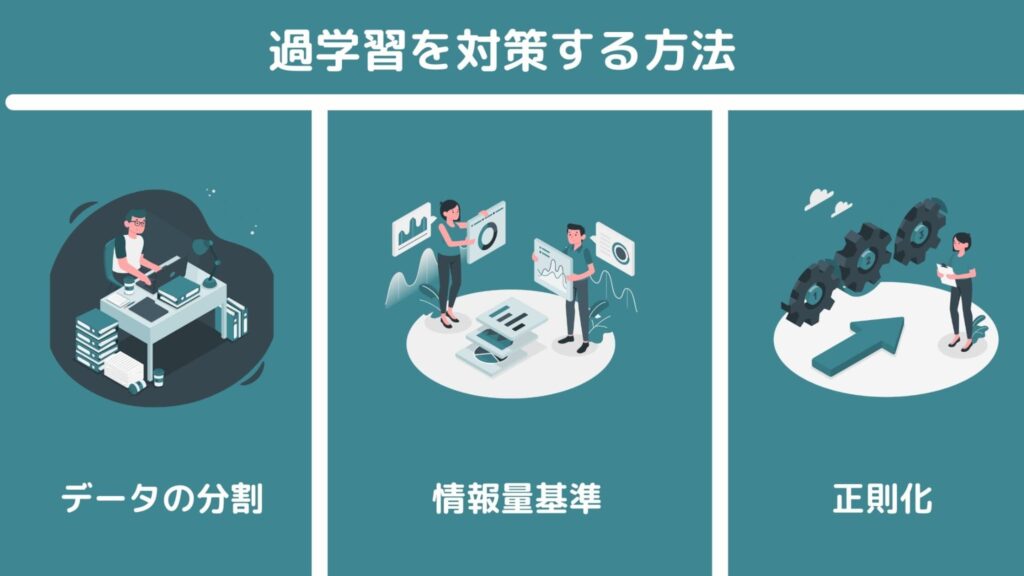
そんな過学習ですが、回避する方法は非常にたくさんあります。
学習データと検証データを分ける

手元の全てのデータを用いてモデルを作成しようとするから過学習が起きてしまうのです。
学習モデルと検証データを分けてモデルを構築することで過学習の起きにくいモデルを作成することができます。
分けた後の学習モデルを使ってモデルを構築して検証データの推定値を算出し、得られた推定値と検証データの実測値の誤差を計算します。
この時、学習データは上手く推定出来ているのに検証データでは誤差が大きいのであれば、上手くモデル構築出来ていないということになります。過学習の疑いがあります。
このように疑似的に将来のデータを作り出すことで過学習を未然に防ぐモデル構築が行えるのです。
そしてこの学習データを検証データを分けて検証を行うことをバリデーションと呼びます。
実は、バリデーションにはいくつかの方法があるんです。
ざっくり学習データと検証データにランダムに振り分けてモデル構築を行うhold-out法、データをいくつかグループ分けして1つのグループデータセットを他のグループで作成したモデルで予測するcross-validation法、データを1個だけ取り出してそれ以外でモデル構築を行い1個の予測を行う作業をサンプル数分繰り返すleave-one-out法などなど。
hold-out法はランダムに分けたデータセットの組み合わせ次第では精度がムダに高く出てしまう可能性があるので、シミュレーションを何回か繰り返して平均を取った方が良いです。
leave-one-out法はサンプル数が多いと物凄く計算負荷がかかるのであまりオススメしません。
ちなみに僕の場合は普段hold-out法を1000回くらい繰り返して精度比較しています。
データ分割する手法について詳しくは以下の記事にまとめています!

AIC/BIC
実は、学習データと検証データを分けなくても過学習を回避する方法はあるんです。
AIC(赤池情報量基準)・BIC(ベイズ情報量基準)などは、変数の数を罰則項として考えることで、過学習を回避しています。
モデルの評価=(予測精度)ーf(変数の数)
変数の数に対してどのように罰則を付けるかは情報量基準によって違いますがどれも変数が多ければ多いほどモデルの評価を下げる式になっています。
これにより、あまりにも多くの変数を用いて作った複雑なモデルは評価が低くなり、過学習を回避することができるのです。

以下の動画の中盤では、AICについて分かりやすく解説をしています!
正則化
正則化は推定した回帰係数に対して罰則項を設けることで、過学習を防ぐ方法です!
主にL1正則化とL2正則化という考え方があります。
正則化に関しては以下の記事で詳しくまとめていますので良ければご覧ください!

またL1正則化であるスパース推定に興味のある方はこちらもご覧ください!

手法やパラメータを簡易的なものにする
高度な手法でゴリゴリのパラメータチューニングを行う場合、過学習に陥りやすいです。
ただ、この場合でもしっかり適切な形に学習データと未知データを分けてバリデーションをおこなえば大丈夫。
ただ、まずは過学習しにくい簡易的な手法でパラメータチューニングをせず実装してみるのも手です。
過学習 まとめ
本記事では、過学習を抑える方法を4つ紹介してきました!
学習データと検証データを分ける
AIC/BIC
正則化
手法やパラメータを簡易的なものにする
実際に過学習を回避するようにモデルを構築しても、未知データの予測がどうなるかは分かりません。
最強のデータサイエンティストが集うデータ分析コンペ「Kaggle」でも最後の最後まで順位は分かりません。
既存のデータに対するフィッティングで仮順位が出ているのですが、最終的な順位は本番データによって決まります。
本番データで順位が大変動することも往々にしてあるのです。
過学習は気を付けておけば基本大丈夫ですが、突き詰めようとすると非常に奥が深い分野なんです!
機械学習についてもっと詳しく知りたい方はぜひ以下の記事を見てみてください!

ちなみに今回解説した過学習をはじめ機械学習について網羅的に学ぶのであれば当メディア運営のスタアカが本当にオススメです!
ぜひチェックしてみてください!
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!