
交差検証法(クロスバリデーション)の概要とRで実装方法を解説!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
データ解析を行う上で気を付けておきたい「過学習」の問題。
過学習は、別名「オーバーフィッティング」・「過適合」とかとも言ったりしますが、データ分析の分野では有名な罠です。
簡単に言うと、手元にあるデータだけにピッタリ合い未知データに対して全く合わないモデルを作ってしまうこと。
過学習については以下の記事で詳しくまとめています!

手元のデータだけ説明できても未知のデータを説明できるとは限らないんですね。
むしろ手元のデータに対してフィッティングし過ぎると未知データの予測精度は下がってしまいます。
そんな過学習を回避したモデルを作成するために利用されるのが交差検証法(cross validation)!
この記事では、交差検証法について具体的に見ていくと共に実際にRを用いて交差検証法を用いたモデル作成を行っていきたいと思います。
以下のYoutube動画でも解説しています!
交差検証法とは
いきなりですが、交差検証法という言葉の定義をご存知でしょうか?
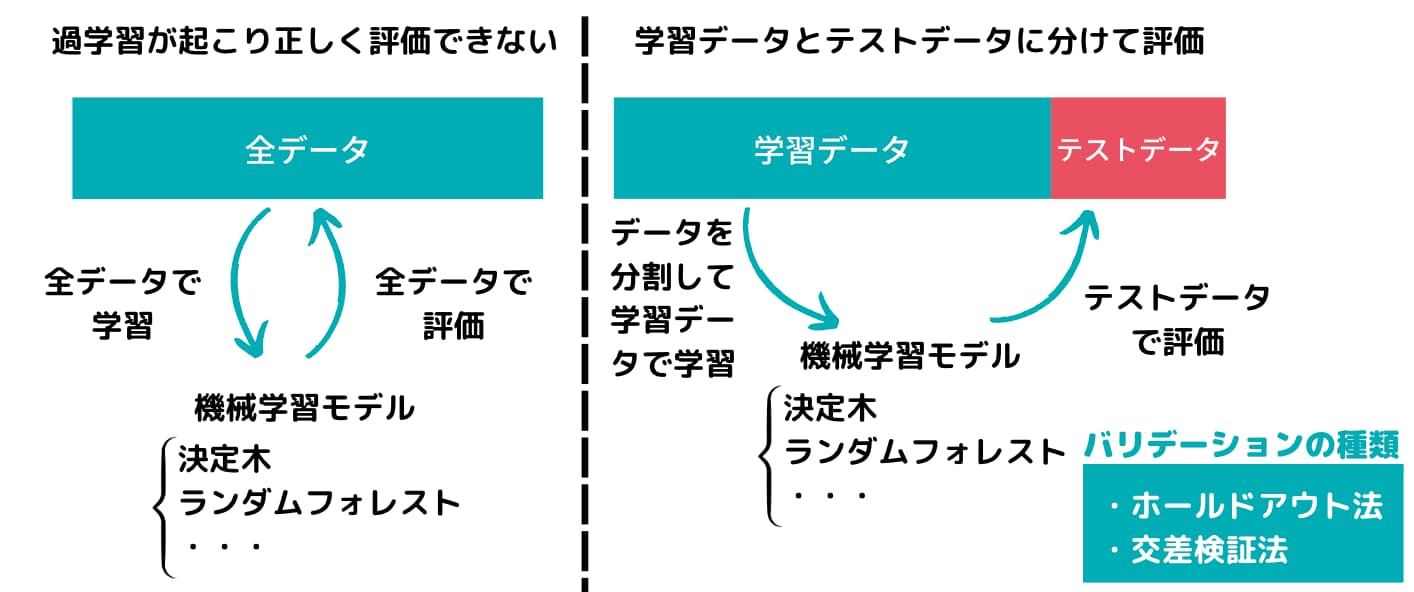
実は交差検証法とは「学習データとテストデータを分割する手法の1つ」
学習データとテストデータを分割する手法にはいくつか手法があります。

hold-out法
hold-out法は、学習データとテストデータを適当な比率で分けて(テストデータを少なめにすることが多い)、学習データを用いてモデルを構築しテストデータに当てはめる方法です。
hold-out法は、データのサンプルが多い時に用いられます。
k-分割交差検証法
こちらがいわゆる一般的な交差検証法。別名cross-validation法になります。
交差検証法では、データを複数のデータセットに分けて1つのデータセットをテストデータ、他のデータを学習データにしてモデルの構築を行います。
全てのデータセットを順番にテストデータにしてモデル構築していくのが交差検証法になります。
交差検証法はデータ数がある程度ある時に用いられます。
Leave one out法
Leave one out法はジャックナイフ法とも呼ばれ、交差検証法が複数グループに分けるところを、1つのサンプルにした方法になります。
1つのサンプルをテストデータとして、それ以外を学習データとしてモデル構築を行います。
それをデータ数分繰り返すのがLeave one out法なのです。
Leave one out法はデータ数が極端に少ない時に用いられます。

実際にRを用いて解析を行ってみよう!

僕がよく用いるのは、同じデータセットに対してHold-out法を複数回行う方法です。
Hold-out法はランダムにデータセットを分けるので、Hold-out法を同じデータセットに複数回行うのはいわゆる交差検証法と同じような結果になります。
実際に簡易的なデータで実装してみましょう!
使用するデータは有名なタイタニックのデータ。Kaggleの公式サイトからデータをダウンロードできます。
まず、データのクレンジングを行い、欠損値は削除、不要と考えられる項目は削除しました。
項目8つ
Survived:生死 pclass:客室のクラス sex:性別 age:年齢 sibsp:兄弟・配偶者の数 parch:親・子供の数 fare:乗船料金 embarked:乗船した港
サンプル数714
この時、生死を目的変数としそれ以外を説明変数とします。
サンプル数714のうちランダムに400個のデータをランダムに取り出し学習データとし、残りの314を予測データとします(これ自体はHold-out法)。
学習データで予測モデルを作り、予測データにあてはめ真値と予測値の判別率を精度として比較します。
ランダムフォレスト、サポートベクターマシン、ナイーブベイズ、ニューラルネットワーク、XGboost、k近傍法の6手法を比較します!
基本的に引数は全部デフォルトで!果たして結果はどうなるでしょうか!
まずはHold-out法単発でどのような結果になるか見ていきましょう!
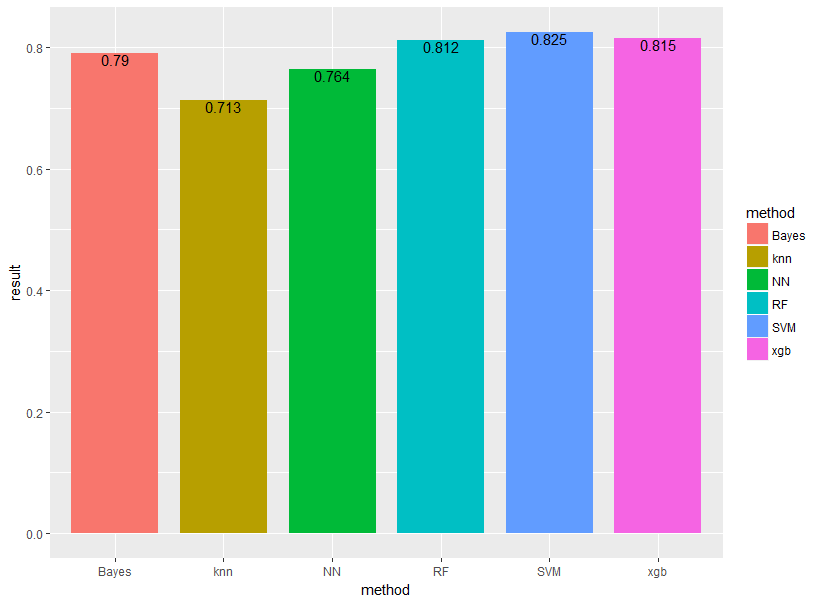
それぞれBayes(ナイーブベイズ)、knn(k近傍法)、NN(ニューラルネットワーク)、RF(ランダムフォレスト)、SVM(サポートベクターマシン)、xgb(XGboost)と表示しています。
knnが最も悪くなっており、最も良いのはSVMになっております。
続いてHold-out法を何回か繰り返す方法を取ります(交差検証法に近い)。
繰り返し回数は100回とし、上記の手順を100回繰り返し、結果を平均したものを最終アウトプットとします。
結果は以下のようになりました!
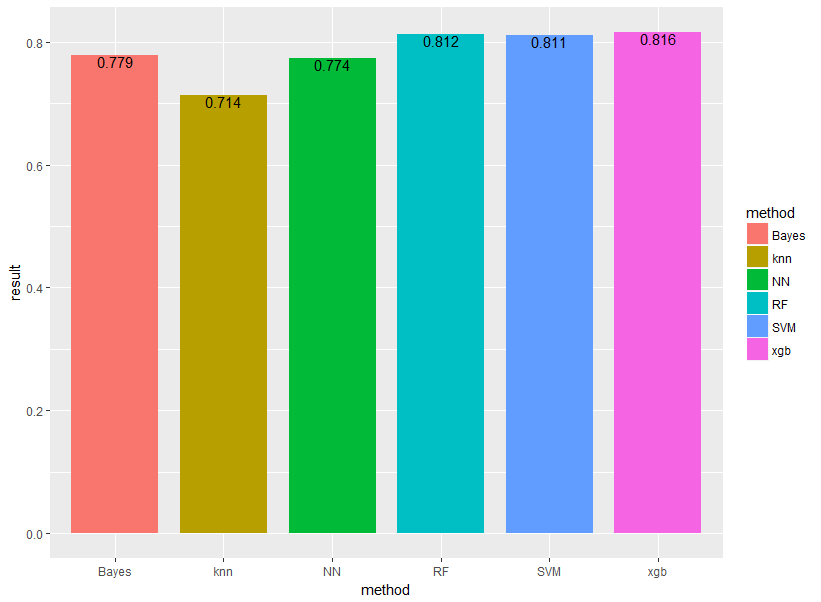
概ね傾向は変わりませんが、ナイーブベイズとニューラルネットワークの精度が近くなったのと、SVMよりもランダムフォレスト・XGboostの精度の方が良くなりました。
やはり、単発で行った場合と何回か繰り返した場合とでは結果が変わってくるということが分かりました。
単発の結果では過学習が起きやすくなっています。
交差検証法 まとめ
交差検証法は、過学習を防ぐデータ分割法の1つであり、よく使われる手法です。
そしていくつか仲間があるということを見てきました。
・hold-out法→学習データとテストデータを大きく2分割
・cross-validation法(交差検証法)→グループ分けしてテストデータを順番に回す
・Leave one out法→データを一つだけ取り出しテストデータとする手順を全てのデータに適用
データ解析を行う際は注意しましょう!
データサイエンティストや機械学習について学びたい方はぜひ以下の記事で見てみてください!


ちなみにデータ分析を実践的に学ぶなら当メディアが運営するスクールであるスタビジアカデミー、略して「スタアカ」がオススメです!
ご受講お待ちしております!
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















