ランダムフォレスト(random forest)とは?PythonとRで実装してみよう!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
汎化能力の非常に高いかつ簡易的に実装可能なランダムフォレストについてみていきましょう!
今でこそディープラーニングやXGboostなどの台頭により日の目を見なくなりましたが、依然としてパッケージで簡単に実装でき相当良い精度をたたき出す最強手法であることには変わりありません。

さて、ランダムフォレストとは一体どんな手法なのでしょうか?
以下の動画でも解説をしていますよー!
目次
ランダムフォレストとは
まず、ランダムフォレストについてまとめられた海外の論文から引用してみましょう!
Random forests are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest.
引用元:Google-“Random Forests”
ランダムフォレストとはざっくり言うと、
「決定木をたくさん集めて合体させた手法」
です。
決定木に関しては「決定木」を見てください。詳しくまとめています。
決定木は単体だとそれほど強い手法ではありません。
しかし、その決定木をバギングと呼ばれる集団学習法(アンサンブル学習)を用いてたくさん集めてくると最強のランダムフォレストが出来上がるんです。
アンサンブル学習法は、決して精度が高いとはいえない弱いモデルをたくさん構築し、これらの予測結果を統合することで高い精度を出す方法論です。

ランダムフォレストのイメージはこんな感じ。
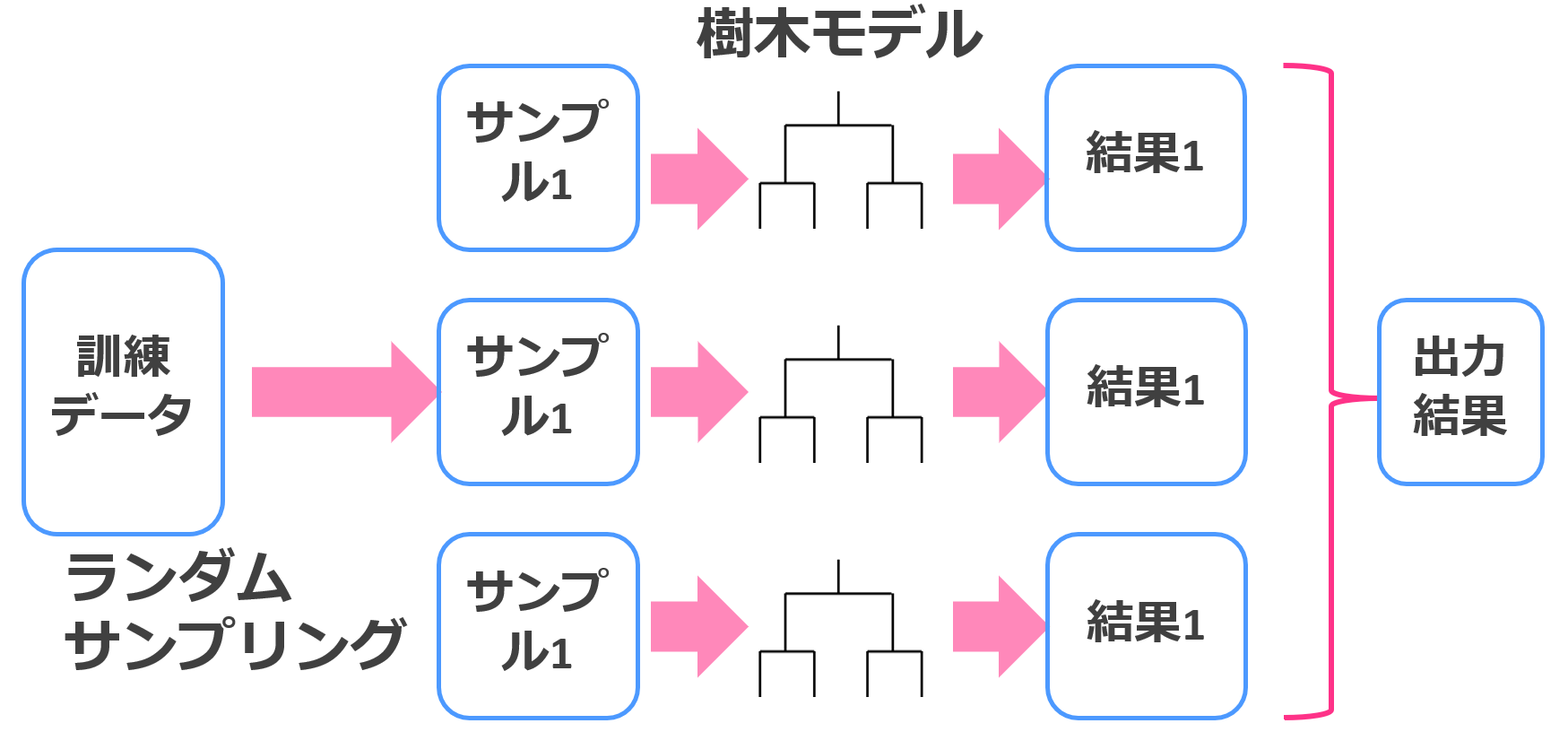
なんでもかんでもバギングすれば良くなるわけじゃないことは注意しておきましょう!
それでは、次に具体的なアルゴリズムを見ていきます
ランダムフォレストのアルゴリズム
アルゴリズムについては、機械学習の教本として有名な「はじめてのパターン認識」から引用していきます!
非常に有名で他の機械学習手法についてもしっかり学べるので興味があれば見てみてください!

- データセットからN個のブートストラップサンプルを作成する。
- ブートストラップサンプルの中から分岐に用いる変数をM個ランダムサンプリングし、決定木を作成する。
- 1~2を繰り返す。
- 量産された決定木に対して、予測したいデータを入力する。
- 全ての結果を統合(回帰の問題では平均、分類の問題では多数決)して、1つの予測結果として出力する。
引用元:「はじめてのパターン認識」
ランダムサンプリングする変数の数Mはユーザが自由に設定することができますが、一般的には変数の数の正の平方根を取ることが多いです。
ランダムフォレストはどんな時に使える?
ランダムフォレストのアルゴリズム自体はそれほど複雑ではありませんが、決定木を弱学習器として用いており結果を解釈するのにはそれほど向いていません。
精度と解釈容易性は比較的トレードオフの関係にあるため、解釈容易性を求めるなら決定木を用いたほうが良いです。

精度を徹底的に求めるならランダムフォレストなどの機械学習手法を使いましょう!
無論、XGboostやLight gbmなどの勾配ブースティング木が強いことは言うまでもありませんが笑
ちなみにランダムフォレストでも、変数重要度を算出することができどの変数が寄与しているのかを可視化することは可能です。
ランダムフォレストをPythonで実装してみよう!

それでは早速、Pythonでランダムフォレストを実装していきます。
データ分析コンペ Nishikaの「中古マンション価格予測」というトレーニングコンペのデータに対してランダムフォレストを実装してみたいと思います。
まず![]() Nishikaに会員登録をして中古マンション価格予測のデータから学習データとテストデータをダウンロードしてローカルのフォルダに入れておきましょうー!(※会員登録をしないとデータをダウンロードできません)。
Nishikaに会員登録をして中古マンション価格予測のデータから学習データとテストデータをダウンロードしてローカルのフォルダに入れておきましょうー!(※会員登録をしないとデータをダウンロードできません)。
学習データには複数CSVが入っているので、それらをglobで結合させてデータフレーム化していきます。
globは、ディレクトリに格納されたファイル名を抽出するのに便利なライブラリです。

コードは以下!
そのあと一部カラムに関しては分析しやすいように加工していきます。
そしてランダムフォレストを以下の部分で実装しています。
model = RandomForestRegressor(n_estimators=100)
model.fit(train_x, train_y.values)
pre = model.predict(val_x)
r2_score(val_y, pre)ここでは評価指標に決定係数を使っています。
結果は0.853となりました!
それなりの精度。
ランダムフォレストをRで実装してみよう!

それでは続いてランダムフォレストを使ってRで解析を行ってみましょう!
ここで行う分析は2つ。
有名な花びらのirisデータを用いた簡単な解析とデータ解析コンペKaggleでも代表的なデータとして取り上げられているタイタニックのデータを使ったシミュレーションを何回か行う解析を行っていきます。
irisデータをランダムフォレストで分類
irisデータとはあやめの種類を分類したデータで目的変数は3カテゴリーの質的変数、説明変数は花びらの幅とか4つです。
サンプルは150個で、分類しやすいデータなのでどんな手法でも割と簡単に分類できるんですが、どうなるでしょう!
今回はランダムフォレスト以外に決定木とサポートベクターマシンとニューラルネットワークで比較しました。
ランダムフォレスト
pred.forest setosa versicolor virginica
## setosa 29 0 0
## versicolor 0 25 1
## virginica 0 2 18
決定木
pred.cart setosa versicolor virginica
## setosa 29 0 0
## versicolor 0 26 3
## virginica 0 1 16
SVM
pred.svm setosa versicolor virginica
## setosa 29 0 0
## versicolor 0 25 1
## virginica 0 2 18
ニューラルネット
pred.nn setosa versicolor virginica
## setosa 29 0 0
## versicolor 0 25 2
## virginica 0 2 17結果はこんな感じになりました!
予想通りどれもいい感じに分類できてますね~!まあirisデータは分類しやすいので!
タイタニックでの生死予測をランダムフォレストと他の手法で比較
続いて!
タイタニックのデータを用いて解析を行っていきます。Kaggleの公式サイトからデータをダウンロードできます。
まず、データのクレンジングを行い、欠損値は削除、不要と考えられる項目は削除しました。
項目8つ
Survived:生死 pclass:客室のクラス sex:性別 age:年齢 sibsp:兄弟・配偶者の数 parch:親・子供の数 fare:乗船料金 embarked:乗船した港
サンプル数714
この時、生死を目的変数としそれ以外を説明変数とします。
サンプル数714のうちランダムに400個のデータを取り出し学習データとし、残りの314を予測データとします。
学習データで予測モデルを作り、予測データにあてはめ真値と予測値の判別率を精度として比較します。
シミュレーション回数は10回とし、上記の手順を10回繰り返し、結果を平均したものを最終アウトプットとします。シミュレーション回数をもっと増やせば精度の信頼性は上がります。
ランダムフォレストをサポートベクターマシン、ナイーブベイズ、ニューラルネットワーク、XGboost、k近傍法の5手法と比較します!
基本的に引数は全部デフォルトで!果たして結果はどうなるでしょうか!
randomForestというパッケージに入っているrandomForestという関数を用いて解析を行っていきます。
##randomForest##
rf<-randomForest(Survived~.,train.data)
test.data.rf<-cbind(test.data,"predict"=predict(rf,test.data))
result[i,1]<-sum(test.data.rf$predict==test.data.rf$Survived)/nrow(test.data.rf)
データ加工は描画でいくつかコードを書いていますが、実際にランダムフォレストを行っているのはこの数行!
Survived~.はSurvivedを目的変数としてそれ以外を説明変数にするよーということです。
結果は以下のようになりました!
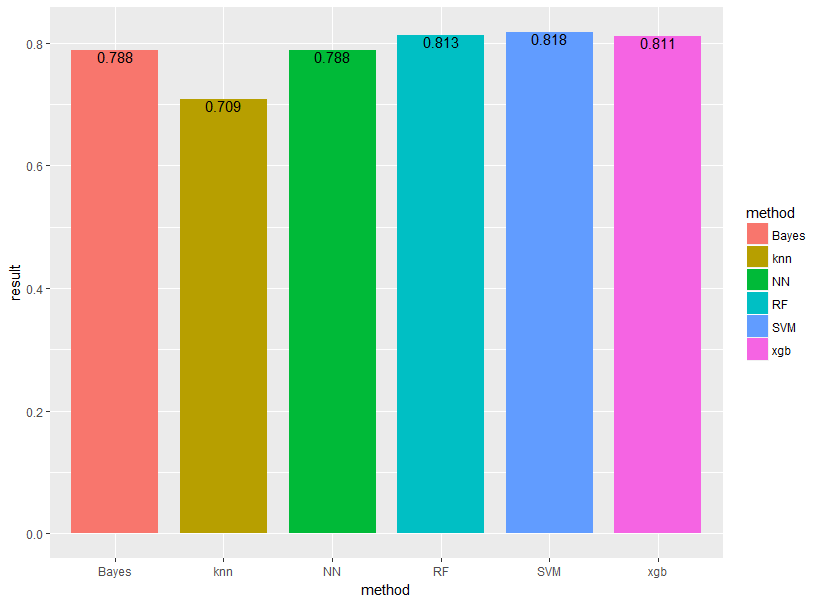
それぞれBayes(ナイーブベイズ)、knn(k近傍法)、NN(ニューラルネットワーク)、RF(ランダムフォレスト)、SVM(サポートベクターマシン)、xgb(XGboost)と表示しています。
やはりランダムフォレスト・SVM・XGboostあたりが強いですね!
他の手法についても是非見てみてください!
ランダムフォレスト まとめ
本記事では、ランダムフォレストについて見てきました!
簡単に実装できる割には精度が高いことが特徴です。
最後にランダムフォレストについてまとめておきましょう!
・ランダムフォレストは決定木とバギングを組み合わせた手法
・ランダムフォレストは簡単に高精度をたたき出すコスパの良い手法
・RでもPythonでもライブラリ使えば簡単に使用できる
ランダムフォレストに関してもっと詳しく知りたいかたは以下の書籍を参考にしてみてください!

ちなみにランダムフォレストをはじめとした機械学習手法に関して深く勉強したい方は以下の記事を見てみてください!


またデータサイエンスや統計学について勉強したい方は以下の記事でまとめていますのでチェックしてみてください!


RとPythonで実装をおこなってきましたが、機械学習手法の実装にはPythonの方がオススメ!
Pythonの学習法は以下の記事でまとめていますのでぜひチェックしてみてください!

データサイエンスを幅広く学びたい方には当メディア運営のスクール「スタアカ」がオススメです!
ご受講お待ちしております。
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!