
ニューラルネットワークの活性化関数ReLU関数をわかりやすく解説!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では、ディープラーニングのブレークスルーを語る上で欠かせないReLU関数について詳しく解説していきたいと思います!
非常にシンプルな関数なのですが、ディープラーニングの精度を著しく向上させる上で非常に重要な役割を果たしているのです!
以下の動画でも分かりやすく解説していますのであわせてチェックしてみてください!
目次
ReLU関数とは
ニューラルネットワークにおいてインプットに特定の関数をかませて変換してアウトプットする関数を活性化関数と呼びます。

活性化関数に利用される関数はいくつかあるのですが、その中でもよく使われるのがReLU(Rectified Linear Unit)関数なのです。
2012年に登場してディープラーニングブームを巻き起こしたAlexNetにも活性化関数としてReLU関数が用いられています。
ReLU関数とは、0より小さい場合は0を出力し、0より大きい場合はそのまま計算結果を出力するという特殊な関数です。
\begin{eqnarray} y= \left\{ \begin{array}{l} x ~~ (x>0) \\ 0~~ (x<=0) \end{array} \right.\end{eqnarray}
グラフにすると以下のようになります。
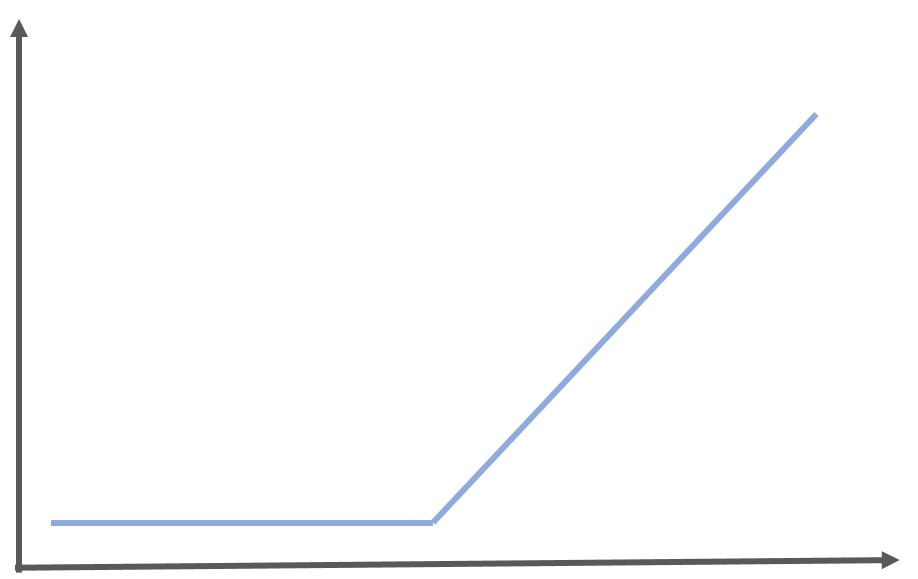
グラフが傾斜のように見えるのでRamp(傾斜)関数とも呼ばれます。
ReLU関数の特徴
それでは、そんなReLU関数がニューラルネットワークでよく使われる理由は何でしょうか?
計算負荷が小さい
1つ目は単純な関数のため計算負荷が小さいこと。
多層ニューラルネットワークであるディープラーニングでは、多くの層で構築されるので計算負荷が大きくなりがちです。
そのためなるべく計算負荷が小さい関数が好まれます。
0以下を0にできるので発火しない層を簡単に表現できる
ReLU関数の数式をもう一度ながめてみましょう!
\begin{eqnarray} y= \left\{ \begin{array}{l} x ~~ (x>0) \\ 0~~ (x<=0) \end{array} \right.\end{eqnarray}
0より小さい場合は強制的に0を出力するため発火しないニューロンを簡単に表現でき精度が向上しやすいです。
画像認識の場面ではマイナスの値は起こり得ずノイズになるのでReLU関数を用いて強制的に負の値を0に変換できることは有用です。
シグモイド関数と違い勾配消失問題が起きにくい
実は、ReLU関数を使うと勾配消失問題というものが起きにくいのです。
ディープラーニングの最適解を求める上で、微分を行い勾配を計算して重みを更新していくのですが、この勾配が0に近くなってしまうと更新幅が小さくなり最適解にたどり着かなくなる問題、これが勾配消失問題なのです!
詳しい説明は省きますが、この勾配を計算する上で誤差逆伝播法というアプローチを用いて複数回微分を重ねて行うのですが、この際に例えばシグモイド関数を使うと勾配がどんどん小さくなり前述した勾配消失問題が起きてしまうのです!
シグモイド関数は、ロジスティック回帰分析に登場する関数であり出力を0~1に抑えることが可能で、以下のような関数になります。
$$ y= \frac{1}{1+exp(-x)} $$
グラフは以下のようになります。
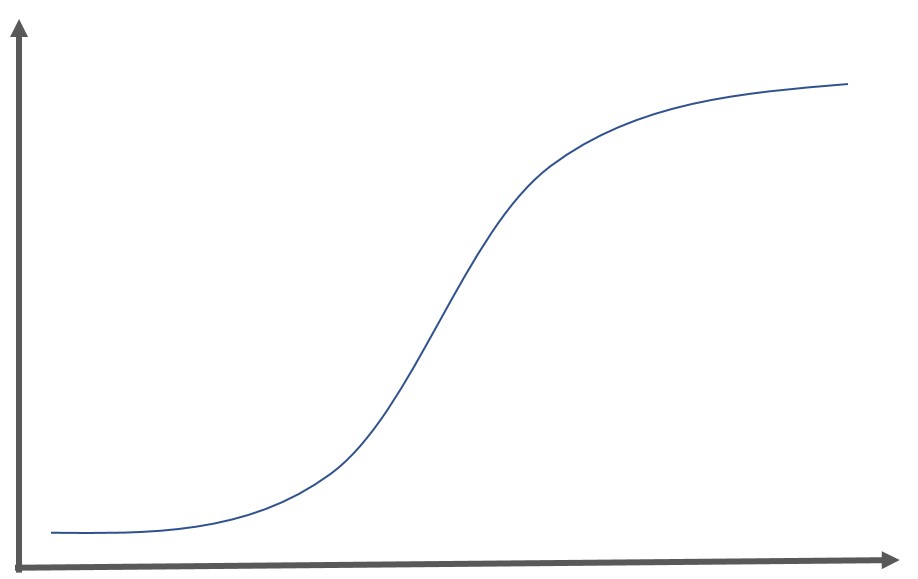
最終的な出力を0~1の確率値で得たいことが多いので、最終的な出力層においてよくシグモイド関数が利用されます。
しかし、このシグモイド関数は微分値の最大値が0.25になるため、シグモイド関数を中間層にたくさん用いてしまうと層が重なるほど勾配が小さくなり勾配消失問題が起きてしまうのです!
一方でReLU関数の微分値の最大値は1になるので勾配を消失させずに層を重ねることが可能なんです。
そのためReLU関数は中間層(隠れ層)でよく用いられます。
一方でReLU関数は出力層の活性化関数としては貧弱なので、出力層では用いられることはほぼありません。
ReLU関数をPythonで使ってみよう!
Pythonには便利なライブラリが備わっていてライブラリを読み込むことで誰でも簡単にディープラーニングを実装することが可能です。
そこでPythonを使ってReLU関数の隠れ層のディープラーニングモデルを作ってみましょう!
今回は定番のMnistという手書き文字のデータセットを用いて、Kerasというライブラリに入ったディープラーニングを使用して画像認識問題を解いていきます!
Mnistは「Gradient-based learning applied to document recognition」で用いられたデータセットであり、現在でも多くの論文で用いられています。
Modified National Institute of Standards and Technologyの略であり、0~9の数字が手書き文字として格納されているデータセットです。
学習用に60000枚、検証用に10000枚のデータセットが格納されています。
まずは、必要なライブラリをインストールしていきましょう!
import numpy as np
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow import keras
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categoricaltensorflowなどのライブラリはあらかじめpip installしておいてくださいね!
続いてMnistのデータを学習データとテストデータに分けます。
そしてさらに学習データからパラメータチューニングのための検証データを取り出します。
# Kerasに付属の手書き数字画像データをダウンロード
np.random.seed(0)
(X_train_base, labels_train_base), (X_test, labels_test) = mnist.load_data()
# Training set を学習データ(X_train, labels_train)と検証データ(X_validation, labels_validation)に8:2で分割する
X_train,X_validation,labels_train,labels_validation = train_test_split(X_train_base,labels_train_base,test_size = 0.2)この時画像データは、描画がしやすいように28×28の行列になっているのですが、1×784に直しましょう!(畳み込み層を使う場合はそのままでも大丈夫ですがここでは一旦畳み込み層を使わず実装していきます)
さらに0~255のスケールを正規化しましょう!
# 各画像は行列なので1次元に変換→X_train,X_validation,X_testを上書き
X_train = X_train.reshape(-1,784)
X_validation = X_validation.reshape(-1,784)
X_test = X_test.reshape(-1,784)
#正規化
X_train = X_train.astype('float32')
X_validation = X_validation.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_validation /= 255
X_test /= 255続いてラベルをダミー変数化します。
# labels_train, labels_validation, labels_test をダミー変数化して y_train, y_validation, y_test に格納する
y_train = to_categorical(labels_train)
y_validation = to_categorical(labels_validation)
y_test = to_categorical(labels_test)ここでデータの成型が終了したので、ディープラーニングのネットワーク構築に入ります。
# パラメータの設定
n_features = 784
n_hidden = 100
bias_init = 0.1
# 学習率
rate = 0.01
# Sequentialクラスを使ってモデルを準備する
model = Sequential()
# 隠れ層を追加
model.add(Dense(n_hidden,activation='relu',input_shape=(n_features,)))
model.add(Dense(n_hidden,activation='relu'))
model.add(Dense(n_hidden,activation='relu'))
# 出力層を追加
model.add(Dense(10,activation='softmax'))
隠れ層で、今回学んだReLU関数を用いて出力層ではソフトマックス関数(多クラス分類に使われる)を用いています。
Model.addを使うことで隠れ層をいくつも積み重ねることが可能です。
ネットワークの構築が終了した後は、最適な重みを見つけていきます。
# TensorFlowのモデルを構築
model.compile(optimizer=tf.optimizers.Adam(rate),
loss='categorical_crossentropy', metrics=['mae', 'accuracy'])
# Early stoppingを適用してフィッティング
log = model.fit(X_train, y_train, epochs=3000, batch_size=100, verbose=True,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0, patience=10,
verbose=1)],
validation_data=(X_validation, y_validation))AdamOptimizerは最近よく使われている最適化手法です。
Early stoppingとはもう精度が改善しないようなら学習を止めてしまう条件です。
これによってムダな学習を省くことが可能です。
最後のvalidation_dataで過学習が起こらないように検証を行っています。
最後にテストデータで予測を実行して実測値と予測値の正解率を求めます!
# テストデータの出力から0~9のどの値か判断
pred_test = np.argmax(model.predict(test_x), axis=1)
sum(pred_test == test_y)/len(pred_test)最終的な結果は・・・・96.96%!!
そこそこな精度をたたき出すことができました。パラメータをいじることで精度を99%まで伸ばしてみてください!
最後にまとめてコードを載せておきます。
ReLU関数 まとめ
ここまでご覧いただきありがとうございました!
本記事ではReLU関数について簡単に解説してきました!
さらに色んなディープラーニングの手法を詳しく知りたい方は以下の記事を参考にしてみてください!
また、より詳しくディープラーニングや最近の大規模言語モデルについて知りたい方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の講座をチェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















