誤差逆伝播法についてわかりやすく解説!Pythonで実装していこう!


こんにちは!スタビジ編集部です!
ニューラルネットワークについて学習すると、ほとんどの場合セットで出てくるのが誤差逆伝播法。
言葉は知っていても具体的な内容はわからない、、、という人は意外と多いのではないでしょうか!
今回はそんな誤差逆伝播法について、より詳細な部分やPythonでの実装方法を詳しく解説していきます!
以下のYoutube動画でも解説していますのであわせてチェックしてみてください!
目次
誤差逆伝播法とは

誤差逆伝播法とは、ニューラルネットワークにおいて、パラメータを推定する際に用いられるアルゴリズムのことです。
出力層から入力層に向けて勾配(誤差の変化率)を計算し、教師ラベルとの予測結果の差が小さくなるようにパラメータを更新していきます。
ニューラルネットワークの中でも特にディープラーニングを支える重要な技術として非常に有名な手法です。
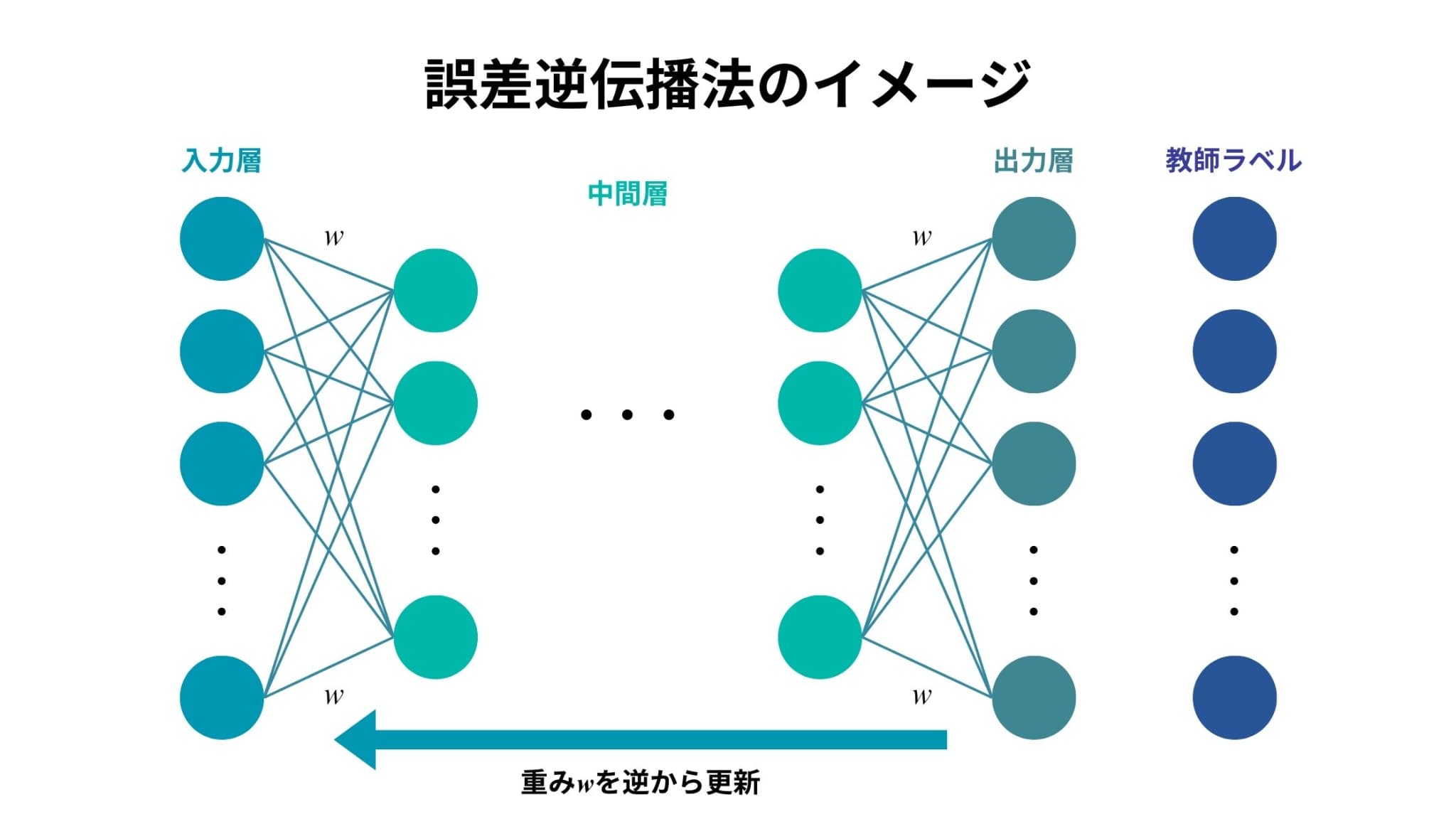
誤差逆伝播法の中身

誤差逆伝播法がパラメータを推定するために用いられるアルゴリズムであることはわかりましたが、実際にはどのような処理が行われているのでしょうか。
数学的理解はやや難易度が高いので、ここではイメージをメインに説明していきます!
1. 前提知識(ニューラルネットワークの仕組み)
誤差逆伝播法の具体的な説明の前に、ニューラルネットワークの仕組みについて簡単に復習しておきましょう。
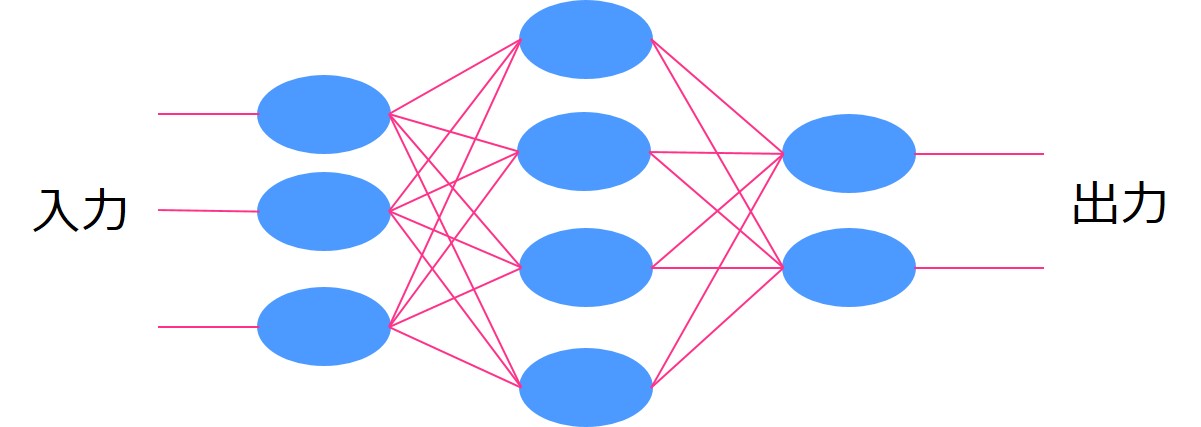
一番左を入力層、一番右を出力層、入力層と出力層の間にある層のことを隠れ層あるいは中間層などと呼びます。
層の中の青い〇をニューロンと言います。
ニューロンからニューロンに情報が渡る時、ある重みがかけられて、その重みによって出力の値が変わってくるんです。
そして、最終的な出力と教師ラベルの誤差をなるべく小さくするように重みをチューニングしていくことでモデルの精度を高めていきます。
これがニューラルネットワークの仕組みです。
2. 重みの更新
ニューラルネットワークでは、重みを更新していくことでモデルの精度を高めていくということがわかりました。

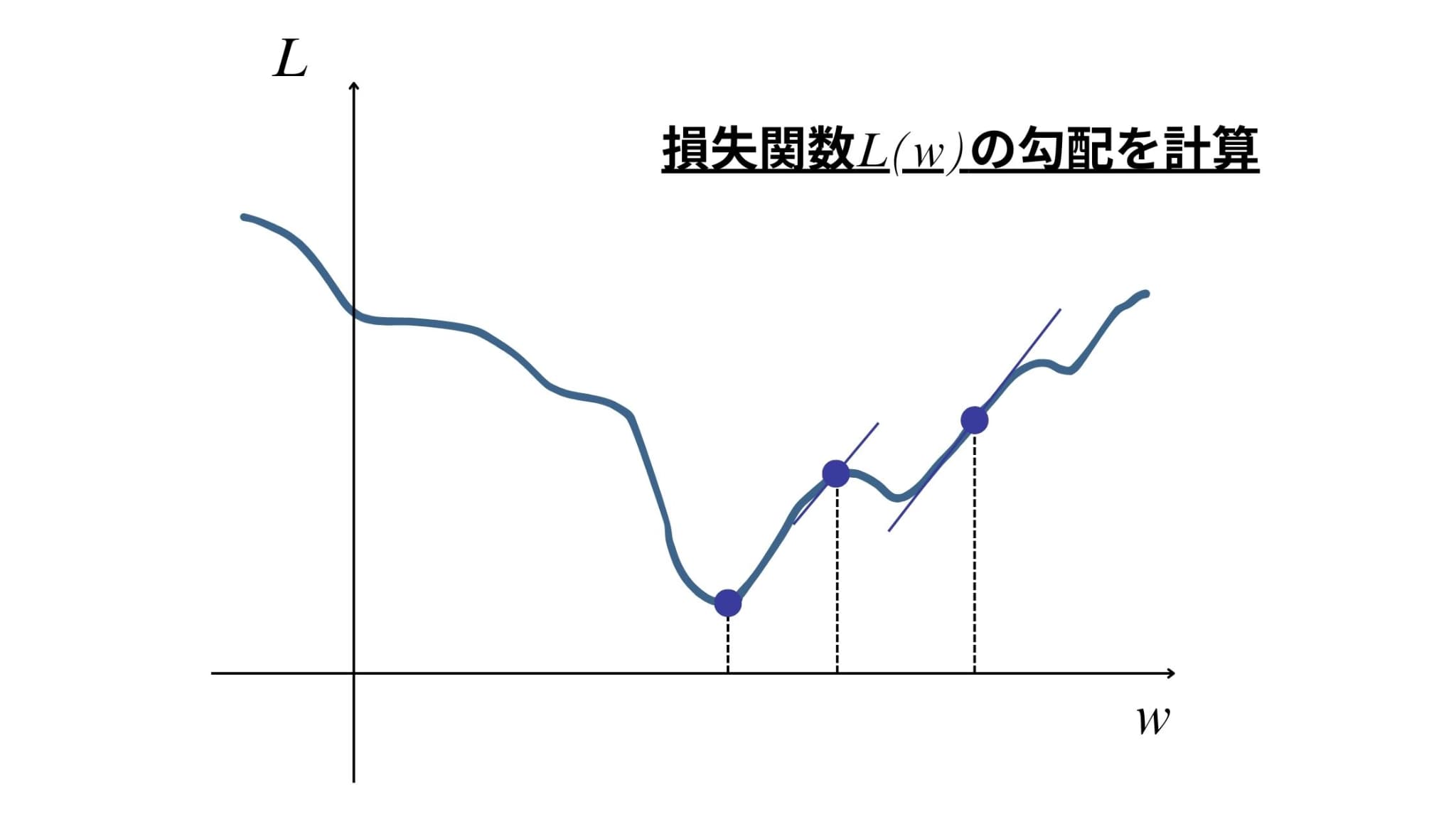
そこで用いられるのが、損失関数に基づく更新方法です。
損失関数を重み\(w\)の関数\(L(w)\)としたとき、その勾配を計算することで、\(w\)をどちらに更新すべきか(より損失関数の値を小さくできるか)の方針を得ることができます。
3. 「逆伝播法」の意味
損失関数の勾配を計算し、最適な重みへと近づけていくことはわかりました。
しかしここで、このような疑問を持っている方もいらっしゃるのではないでしょうか。
確かに今のところ、更新の順番は特に気にしなくてもよさそうに思えます。
しかし、わざわざ逆から更新していくのにはある理由があるのです。
それはズバリ、計算負荷が圧倒的に軽くなるからです。
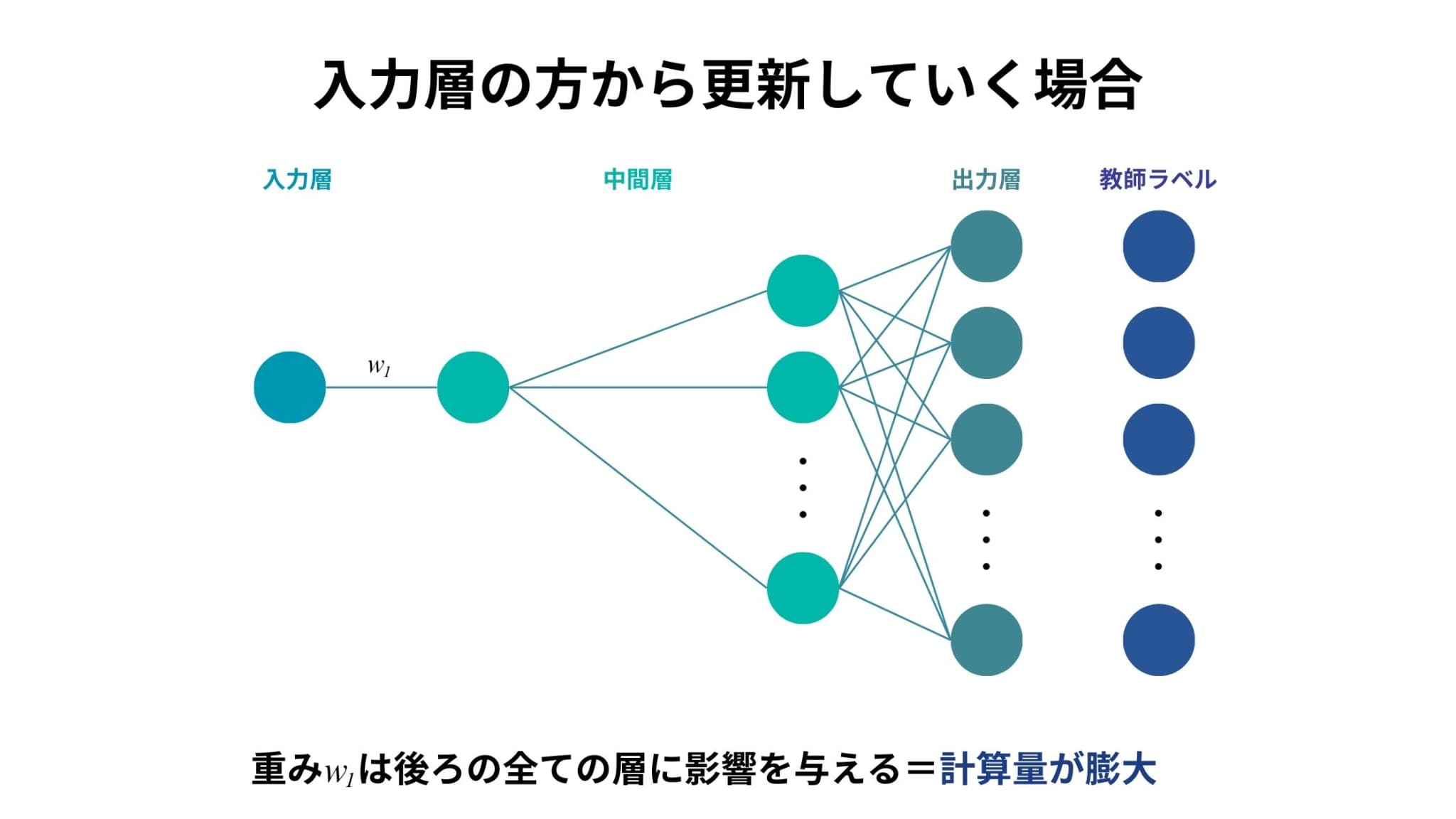
仮に、入力層の方から重みを更新していくことを考えましょう。
入力層から中間層の1層目への重みを\(w_{1}\)としたとき、\(w_{1}\)を少し動かしただけで、それよりも後ろの中間層および出力層の全ての値が変化してしまいます。
この操作をあらゆる組み合わせでやろうとするととんでもなく時間がかかってしまうことは容易に想像できると思います。
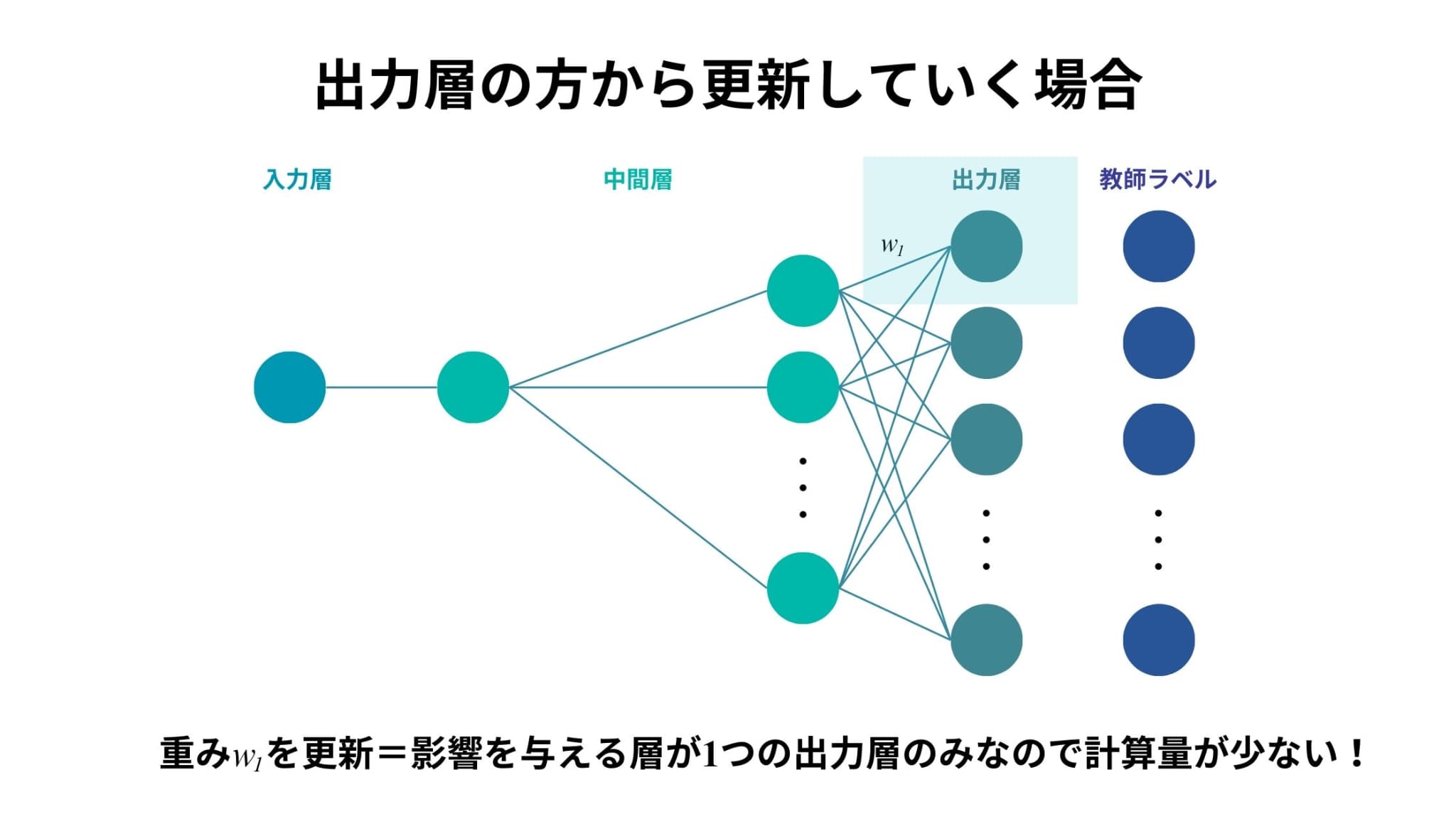
一方で、出力層の方から重みを更新していくことを考えてみます。
一番後ろの中間層から出力層への重みを\(w_{1}\)としたとき、\(w_{1}\)を少し動かしたとしても、影響を受けるのは1つの出力層のみであることがわかります。
つまり、先ほどと比べて計算量が圧倒的に少なくなるということです。
これが「逆伝播法」の名前の由来であり、誤差逆伝播法のメリットでもあります。
誤差逆伝播法をPythonで実装してみよう

ここからはPythonで実際に誤差逆伝播法を実装していきます。
機械学習ライブラリなどを使わずにニューラルネットワークを実装し、誤差逆伝播法のイメージをつかんでいきましょう。
以下の流れで分析を進めていきます。
1. ライブラリ(モジュール)のインストール
2. 使用データの前処理
3. 学習部分(関数)の定義
4. 予測
5. 結果の確認
1. ライブラリ(モジュール)のインストール
まず、今回使用するライブラリなどをインストールしておきます。
今回は乳がんデータを用いて予測を行っていきます。
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler2. 使用データの前処理
特徴量を標準化し、訓練データとテストデータに分割しておきます。
#データのロードと前処理
data = load_breast_cancer()
X = data.data
y = data.target.reshape(-1, 1)
#データの標準化
scaler = StandardScaler()
X = scaler.fit_transform(X)
#訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)3. 学習部分(関数)の定義
続いて、ニューラルネットワークにおける学習の部分を関数として定義します。
今回は中間層が1層の単純なニューラルネットワークを実装していきます。
また、入力層のノード数は30(乳がんデータセットにおける説明変数の数)、中間層のノード数は5、出力層のノード数は1となっています。
さらに学習の部分では、
1. 順伝播の計算(予測値の算出)
2. 誤差(損失)の計算
3. 逆伝播による重みの更新
というステップを繰り返すという構造になっています。
#シグモイド関数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
#シグモイド関数の導関数
def sigmoid_derivative(x):
return x * (1 - x)
#誤差逆伝播法による学習
def backpropagation(X, y, learning_rate, epochs):
#重みの初期化
input_neurons = X.shape[1]
hidden_neurons = 5
output_neurons = 1
weights_input_hidden = np.random.uniform(size=(input_neurons, hidden_neurons))
weights_hidden_output = np.random.uniform(size=(hidden_neurons, output_neurons))
#学習
for epoch in range(epochs):
#順伝播
hidden_layer_input = np.dot(X, weights_input_hidden)
hidden_layer_output = sigmoid(hidden_layer_input)
output_layer_input = np.dot(hidden_layer_output, weights_hidden_output)
output_layer_output = sigmoid(output_layer_input)
#誤差
error = y - output_layer_output
#誤差の計算と重みの更新(逆伝播)
d_output = error * sigmoid_derivative(output_layer_output)
error_hidden_layer = d_output.dot(weights_hidden_output.T)
d_hidden_layer = error_hidden_layer * sigmoid_derivative(hidden_layer_output)
weights_hidden_output += hidden_layer_output.T.dot(d_output) * learning_rate
weights_input_hidden += X.T.dot(d_hidden_layer) * learning_rate
return weights_input_hidden, weights_hidden_output4. 予測
上で定義した関数に、訓練データの特徴量と目的変数およびハイパーパラメータを代入してモデルを学習させ、予測をしていきます。
#ハイパーパラメータ
learning_rate = 0.1 #学習率
epochs = 10000 #学習回数
#誤差逆伝播法による学習
weights_input_hidden, weights_hidden_output = backpropagation(X_train, y_train, learning_rate, epochs)
#学習した重みで予測
def predict(X, weights_input_hidden, weights_hidden_output):
hidden_layer_input = np.dot(X, weights_input_hidden)
hidden_layer_output = sigmoid(hidden_layer_input)
output_layer_input = np.dot(hidden_layer_output, weights_hidden_output)
output_layer_output = sigmoid(output_layer_input)
return output_layer_output
predictions = predict(X_test, weights_input_hidden, weights_hidden_output)5. 結果の確認
最後に、作成したモデルによる予測結果を確認していきます。
予測値は0〜1の連続値で出力されるので、0.5より大きいか小さいかで良性・悪性を決定します。
#予測結果を確認
predictions_binary = (predictions > 0.5).astype(int)
accuracy = np.mean(predictions_binary == y_test)
print("Accuracy:", accuracy)精度(accuracy)は約0.96となり、かなり精度の高いモデルを作成することができました。
層の数を増やしたり、ハイパーパラメータの値を変えたりすることで、さらに精度の高いモデルを作ることができるでしょう。
まとめ
ここまでご覧いただきありがとうございました!
本記事では誤差逆伝播法のより詳細な部分やPythonでの実装方法を解説していきました。
普段は機械学習ライブラリなどを使ってなんとなくの理解のまま実装していたかもしれませんが、今回のように自分の手でその中身を実装することでより理解が深まっていくと思います!
他にも、もし理解が浅いまま使ってしまっているような手法があれば、ぜひ自分の手で一から実装してみましょう!
また、今回分析に用いたPythonについて勉強したい方は以下の記事を参考にしてみてください!

さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!