畳み込みニューラルネットワーク(CNN)をわかりやすく解説!Pythonで画像認識を実装してみよう!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
この記事ではディープラーニングの進化の歴史の中でも比較的古くから存在する非常に重要な畳み込みニューラルネットワーク(CNN)について解説していきます。
ディープラーニングを理解する上で非常に重要な手法ですのでしっかり理解しておきましょう!
以下の動画でも解説していますので合わせてチェックしてみてください!
ディープラーニング系、その他のAI用語を一挙にまとめた以下の記事も合わせて要チェックです!

目次
畳み込みニューラルネットワーク(CNN)の特徴
畳み込みニューラルネットワーク(CNN)はYann LeCun(ヤン・ルカン)氏の研究が元となって生み出されました。
畳み込み層
畳み込みニューラルネットワーク(CNN)が登場する以前は、ある層から次の層まで信号が伝播する際に全ての層が結合するような形でした。これを全結合層と呼びます。
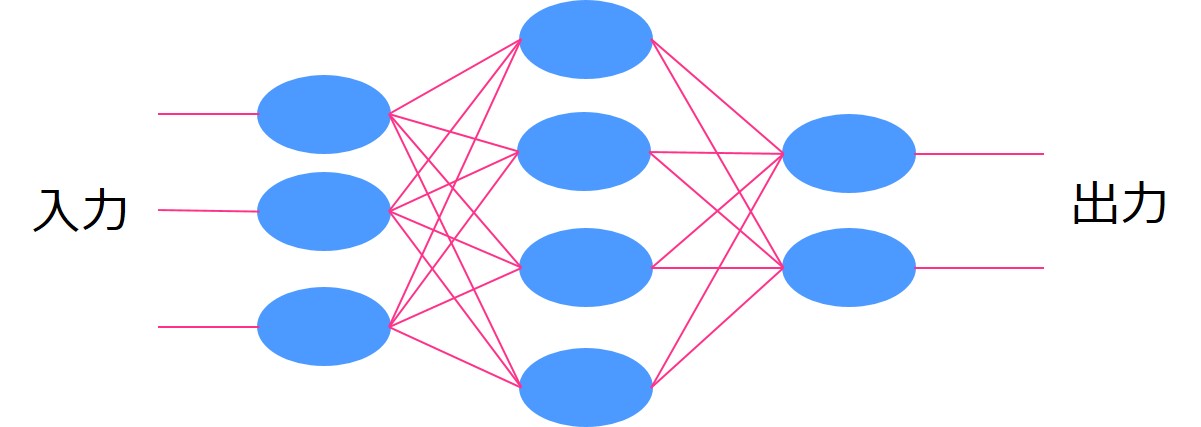
しかし、全結合層にするとなると例えば画像データにおいて少しの不都合が生じてしまうのです。
画像データは、縦×横×奥行き(色を表現するためのRGBの層が重なっているため奥行きもある)の3次元のデータになっています。
全結合層にインプットするとなると、この3次元のデータを1次元に直さなくてはいけません。
1次元でも問題なくモデル構築は可能なのですが、画像には3次元でないと表現できない重要な情報が存在します。
例えば上下で隣り合うピクセルのデータは近い位置にありますが、情報が1次元になるとこの位置情報が失われてしまうのです。
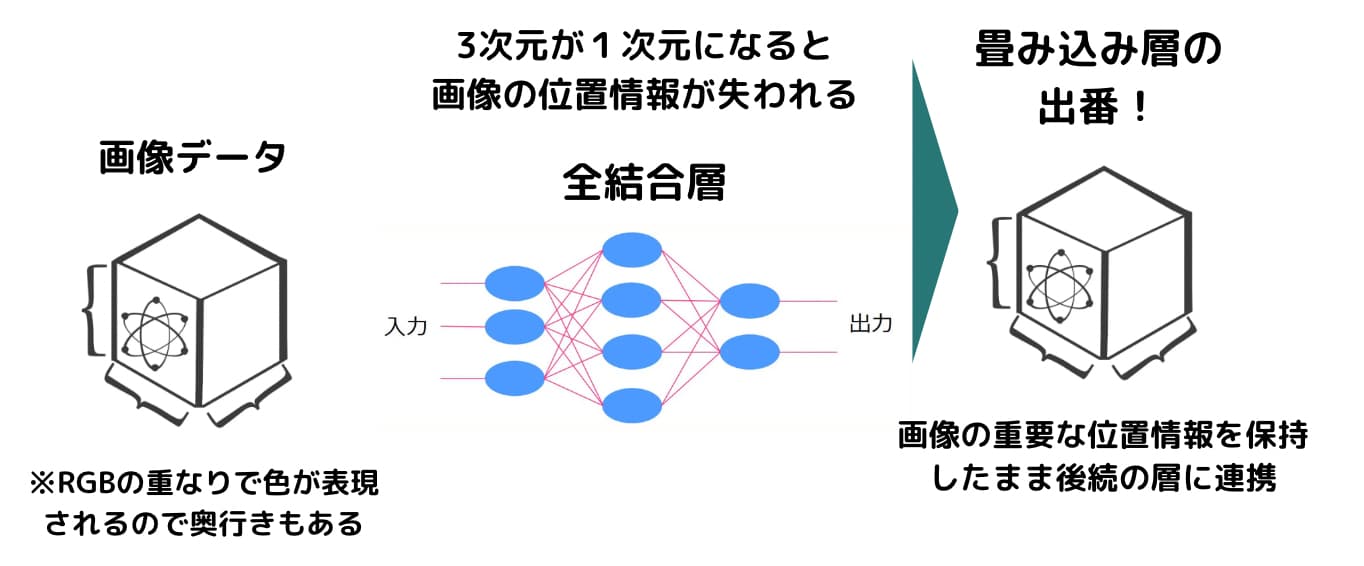
そこでそのような3次元における情報を失わずにニューラルネットワークのモデルを構築しようというのが畳み込みニューラルネットワークの試みです。
畳み込みニューラルネットワークでは、その名の通り畳み込み層という層を全結合層の代わりに使い、「畳み込み演算」という処理をおこなっていきます。
今までの全結合層でもインプットに対して重みが存在していましたが、それと同じような処理を畳み込み層に適用させていきます。
重みにあたるのがフィルターになり、ちょっと特殊な処理を行うのです。
以下を見てみてください。
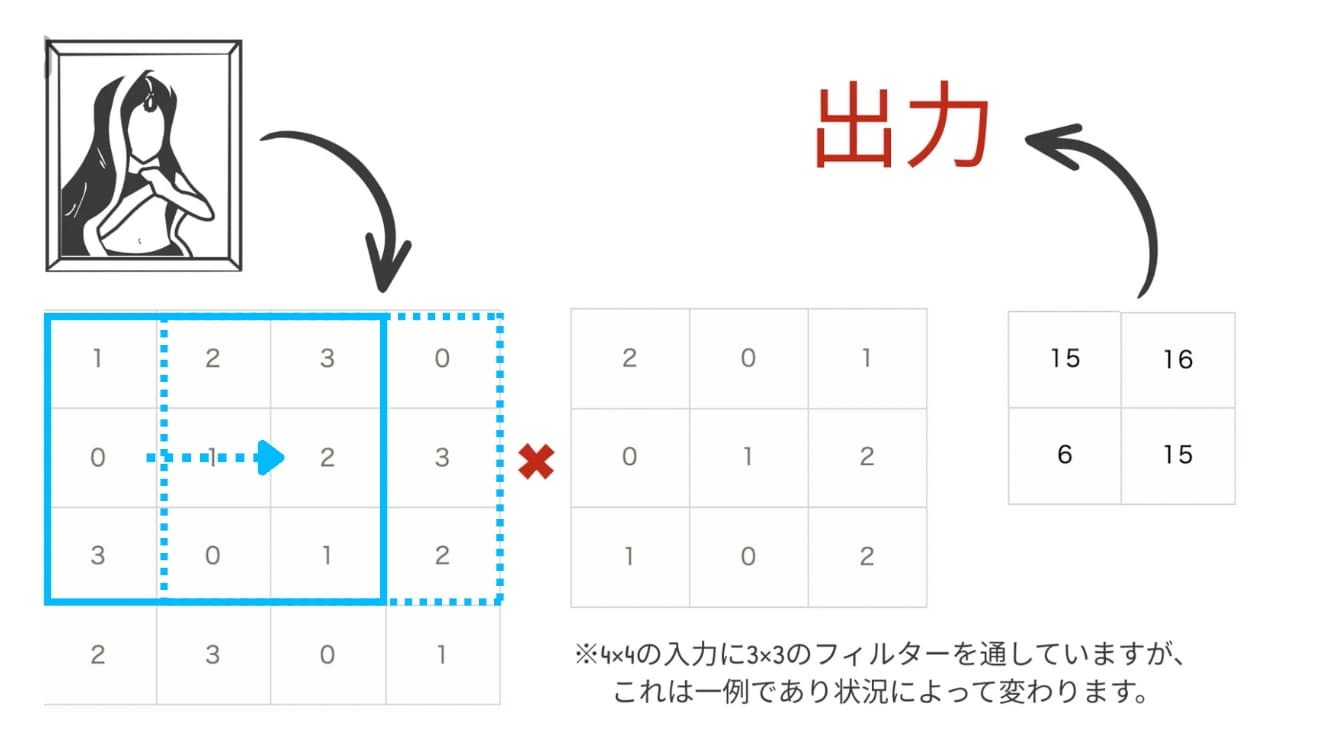
画像のピクセルが4×4で表現されていて、ここにフィルターと呼ばれる重みらしきものを使って畳み込み演算をおこなっています。
この時、入力データ4×4に対してフィルターは3×3になっています。
フィルターを使ってまずは左上の3×3の領域との演算をおこなっていきます。この時各要素をかけあわせたものの総和を求めていきます。
そうすると結果は、1×2+2×0+・・・1×2=15になります。
この演算を、フィルターをずらして各要素に適用させていくと、結果的に2×2の出力が生まれます。
このようにして全結合層と同じようなプロセスを経て畳み込み層から次の出力が生まれるのです。
今回の例では縦×横の2次元で行いましたが、これが3次元になっても一緒です。
畳み込み層を使うと1次元にせずとも次の層へ情報を伝播させていくことが可能なのです。
これによって物体の境界線や色の集合などを捉えやすくなります!
また、畳み込み演算により情報量を失わずにピクセルを小さくできるので計算量を抑えることが可能です。
ディープラーニングでは精度を上げていく上で層をなるべく多く重ねることが重要になります。
その点で畳み込み層で計算負荷を抑えることで層を多く重ねることができるのです!
プーリング層
畳み込みニューラルネットワーク(CNN)には、畳み込み層以外にもプーリング層という重要な層が存在します。
このプーリング層の役割は以下のように計算された各領域の要素の情報を圧縮すること。
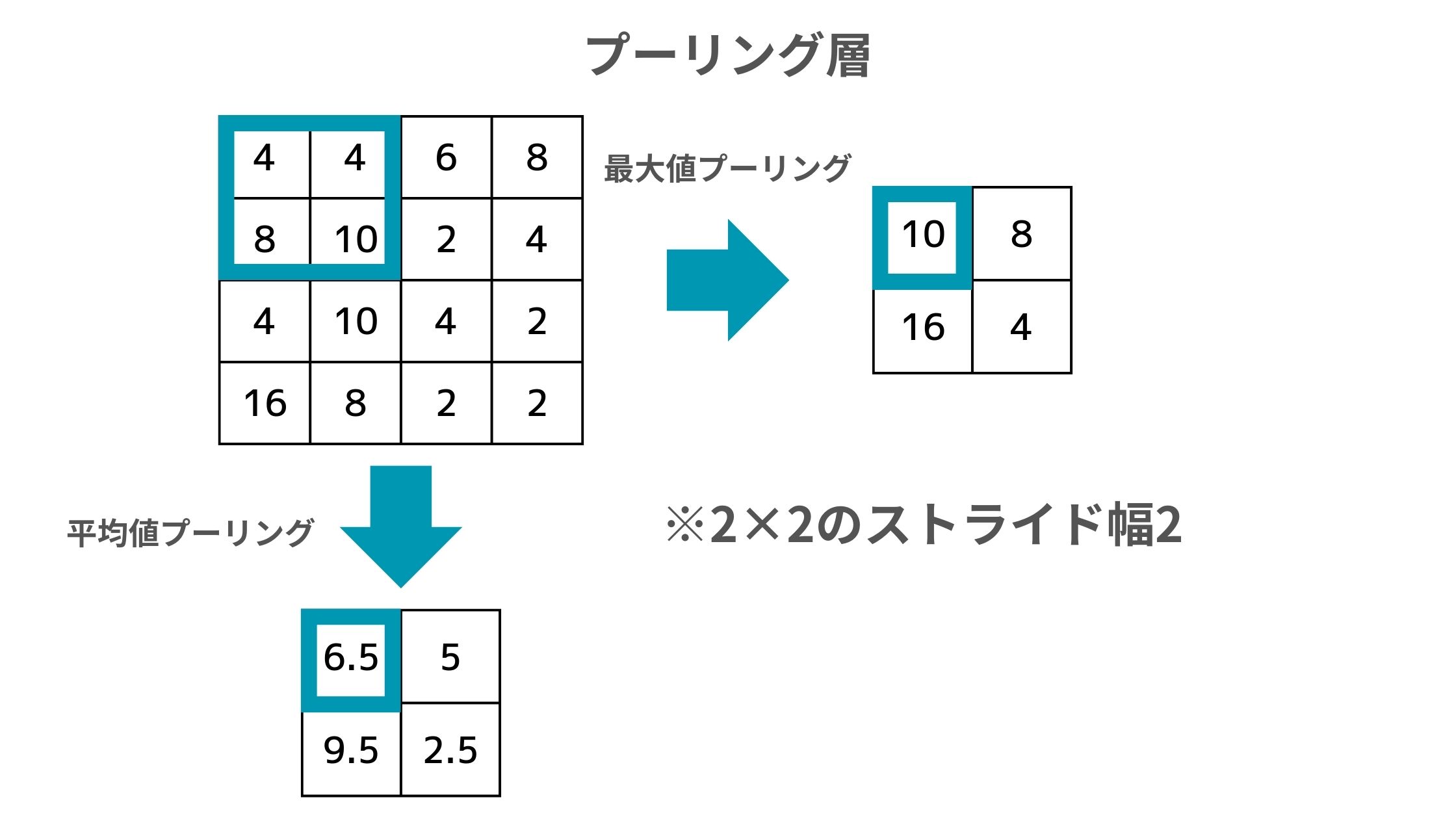
例えばこの場合だと、元のデータの左上4つをフィルタで囲っていて、そこから最大値プーリングであれば最大値の10が抽出され、平均値プーリングであれば4, 4, 8, 10の平均を取った6.5が抽出されます。
この場合は2×2のフィルタでストライド幅は2になっていますが、他のパターンもあります。
この処理により情報を失わずにダウンサンプリングが出来て計算負荷を抑えることができるのです!
また、画像に多少のズレがあってもプーリング層を通すことで特徴を保持して検出しやすくなるというメリットもあります。
例えば以下のように2行目のピクセルが1つ左にずれたとしても、最大値プーリングの結果は変わらずズレを吸収することができるのです!
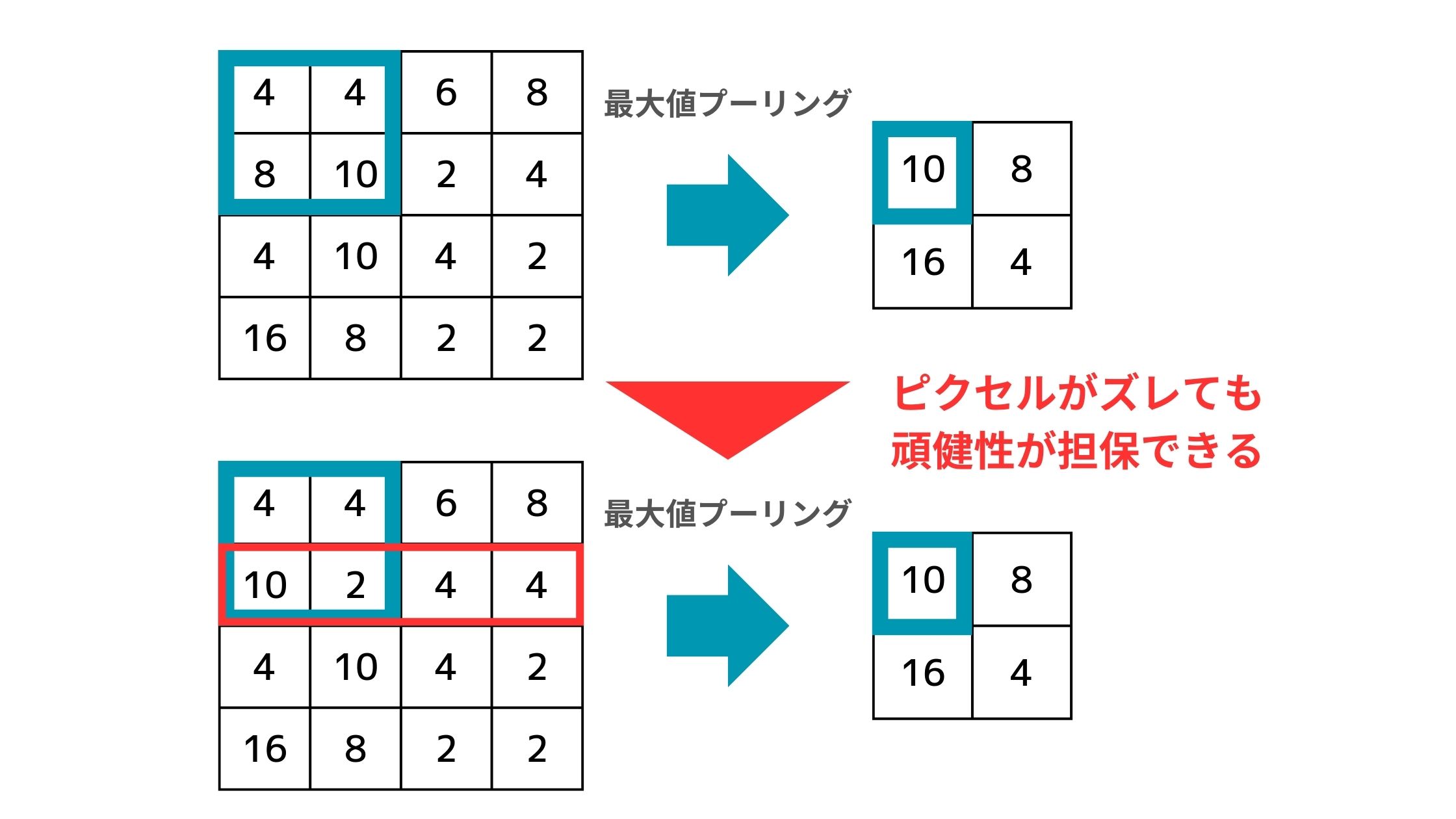
畳み込みニューラルネットワークは、このように畳み込み層による画像特徴の検出とプーリング層によるズレの吸収をしつつ計算負荷を抑えて層を重ねていくアーキテクチャになっているのです。
CNNをベースにした他のディープラーニング手法
それではそんなCNNをベースにした手法の中でも有名どころを取り上げていきましょう!
AlexNet
まずはAlexNet!
AlexNetは、ImageNetを使った画像認識精度を競うILSVRC (ImageNet Large Scale Visual Recognition Challenge)2012という大会において2位と圧倒的な差をつけて優勝した手法です。
ImageNetは1400万枚以上の画像に対してラベルが付けられている巨大な画像のデータセットです。

(出典:ImageNet Large Scale Visual Recognition Challenge)
2012年以前は画像から特徴量を人間が定義しそれを元にモデルを構築するアプローチが主流でCNNをベースとしたニューラルネットワークはまだまだよい精度を出力できていませんでした。
そんな中、2012年に突如登場したAlexNetという巨大なニューラルネットワークアーキテクチャが登場したのです。
AlexNetはカナダのトロント大学のジェフリー・ヒントン研究室から発表されました。
論文は以下です。
論文に掲載されているアーキテクチャは以下です。
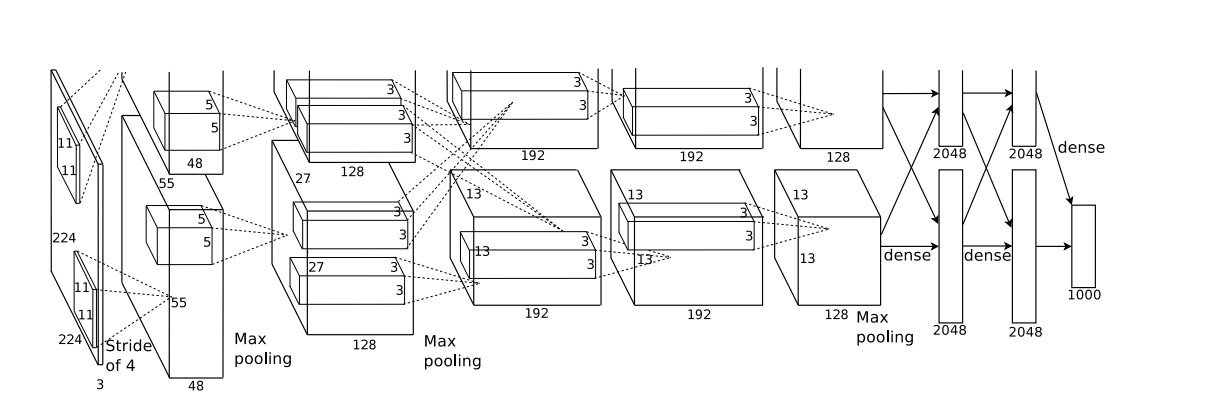
少々わかりにくいですが、畳み込み層とプーリング層、全結合層が組み合わさった巨大なニューラルネットワークになっていてCNNの構造を踏襲していることがわかります。
AlexNetでは活性化関数にReLU関数を採用しているのも非常に大きいポイントです。
AlexNetについて詳しく知りたい方は以下の記事をチェックしてみてください!
ResNet
ResNetは2015年にMicrosoft Researchチームが発表したアプローチです。
論文は以下です!
AlexNetの登場以降、ディープラーニングの中でも画像認識タスクで高い精度を出力していたCNN(畳み込みニューラルネットワーク)では層を深くしモデルを複雑にすることで精度を高めてきていました。
基本的にCNNのモデルは層を深くすることで複雑な問題に対しても適応させることができ精度が高くなると考えられていました。
しかし一定以上層を深くすると何故か精度が悪くなってしまっていたのです。
以下がその現象を表した論文に記載されている実験結果です。
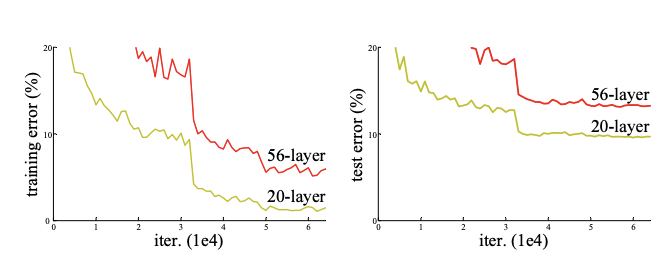
左が学習データで右がテストデータ、赤が56層のCNNで黄色が20層のCNNになります。
そうなんです、モデルが複雑になることで学習データに過度に適合してしまう過学習が起きてテストデータで精度が下がることは考えられますが、その場合は学習データでは精度が上がるはずです。
しかし今回のケースは学習データでも層が深いモデルの方が精度が下がっている・・・ということは過学習ではない根本的な問題が起きているんです。
それではResNetではどうやって先ほどの課題を解決したのでしょうか?
論文からアーキテクチャを拝借して見てみましょう!
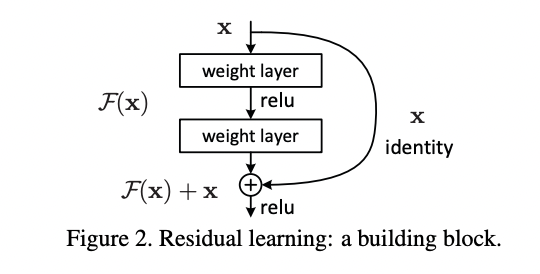
xという入力に対して、通常のレイヤー(層)を通るルートとレイヤーを通らずにショートカットしている層があることが分かると思います!
このショートカット層により、簡単に恒等写像F(x) = xが実現でき精度を悪化させずに層を深くすることができるようになったのです!
ResNetについて詳しく知りたい方は以下の記事をチェックしてみてください!

畳み込みニューラルネットワーク(CNN)をPythonで実装
CNNについて理解が進んだところでPythonでの実装を見ていきましょう!
今回は定番のMnistという手書き文字のデータセットを用いて、Kerasというライブラリに入ったディープラーニングを使用して画像認識問題を解いていきます!
KerasはTensorFlowや、CNTK、Theanoなどの、より基本的な機械学習ライブラリを「バックエンド」として呼び出して使うようになっており、ディープラーニングのモデルを層を重ねるイメージで簡単に構築することができるようになっています。
Mnistは「Gradient-based learning applied to document recognition」で用いられたデータセットであり、現在でも多くの論文で用いられています。
Modified National Institute of Standards and Technologyの略であり、0~9の数字が手書き文字として格納されているデータセットです。
学習用に60000枚、検証用に10000枚のデータセットが格納されています。
Pythonの実行環境としては、普段使っている環境を使ってもらって問題ないのですが、はじめての方はGoogle Colabを利用することをオススメします!
早速全体のコードを見ていきましょう!以下のように実装していきます。
まず必要なライブラリをインストールしています。
import numpy as np
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow import keras
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical
tensorflowなどのライブラリはあらかじめpip installしておいてくださいね!
続いてMnistのデータを学習データとテストデータに分けます。
そしてさらに学習データからパラメータチューニングのための検証データを取り出します。
# Kerasに付属の手書き数字画像データをダウンロード
np.random.seed(0)
(X_train_base, labels_train_base), (X_test, labels_test) = mnist.load_data()
# Training set を学習データ(X_train, labels_train)と検証データ(X_validation, labels_validation)に8:2で分割する
X_train,X_validation,labels_train,labels_validation = train_test_split(X_train_base,labels_train_base,test_size = 0.2)その後に画像に前処理をかけています。
# 各画像のShapeを整形
train_x = train_x.reshape((48000, 28, 28, 1))
valid_x = valid_x.reshape((12000, 28, 28, 1))
test_x = test_x.reshape((10000,28,28,1))
#正規化
train_x = np.array(train_x).astype('float32')
valid_x = np.array(valid_x).astype('float32')
test_x = np.array(test_x).astype('float32')
train_x /= 255
valid_x /= 255
test_x /= 255
# train_y, valid_y をダミー変数化
train_y = to_categorical(train_y)
valid_y = to_categorical(valid_y)
ここからモデルを構築していきます。
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
Conv2Dで2次元畳み込み層をMaxPoolingで2次元プーリング層を定義しています。
続いてFlattenでフラット化し、Dense層(全結合層)で活性化関数ReLU関数・SoftMax関数を通して結果を出力します。
そしてモデルのアーキテクチャ構築後は以下のコードで実際に学習を進めています。
# モデルを構築
model.compile(optimizer=tf.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy'])
# Early stoppingを適用してフィッティング
log = model.fit(train_x, train_y, epochs=100, batch_size=10, verbose=True,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0, patience=10,
verbose=1)],
validation_data=(valid_x, valid_y))
# テストデータの出力から0~9のどの値か判断
pred_test = np.argmax(model.predict(test_x), axis=1)
sum(pred_test == test_y)/len(pred_test)最終的な結果は0.91となりそこそこの精度になりました。
ご自身の環境でもぜひコードを動かしてみてください。
CNN まとめ
ここまでご覧いただきありがとうございました!
本記事では、CNNについて解説してきました。
CNNはAIの進化の歴史の中でも非常に重要な手法です。ぜひ理解しておきましょう!
ディープラーニングの様々なモデルを知りたい方は以下の記事を参考にしてみてください。
・RNN
・AlexNet
・ResNet
・Transformer
また、さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスの「08.ディープラーニング」コースや
「大規模言語モデル(LLM)・生成系AI」コースで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!