ニューラルネットワークのソフトマックス(softmax)関数についてわかりやすく解説!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
今回はソフトマックス関数について解説していきます!
ソフトマックス関数とは「n個のデータの合計を1にする関数」と定義されています。
ソフトマックス関数はディープラーニングの活性化関数として用いられることが多く、出力値の合計が1なので、出力値はそのまま確率として用いることができる利点があります!
この記事では、活性化関数とソフトマックス関数の定義、そしてそのつながりについて解説していきます!
・活性化関数について解説!
・ソフトマックス関数について解説!
以下のYoutube動画でも解説していますのであわせてチェックしてみてください!
目次
活性化関数について解説!
初めにディープラーニングについてあまり知らない方向けに、活性化関数について解説していきます!
活性化関数とは「ニューラルネットワークのニューロンからの入力・出力の合計から、出力を決定する関数」と定義されています。
ニューラルネットワークの基本形として、複数の入力層からの重みづけ総和を活性化関数に通して出力を決定するモデルがよく使われています!
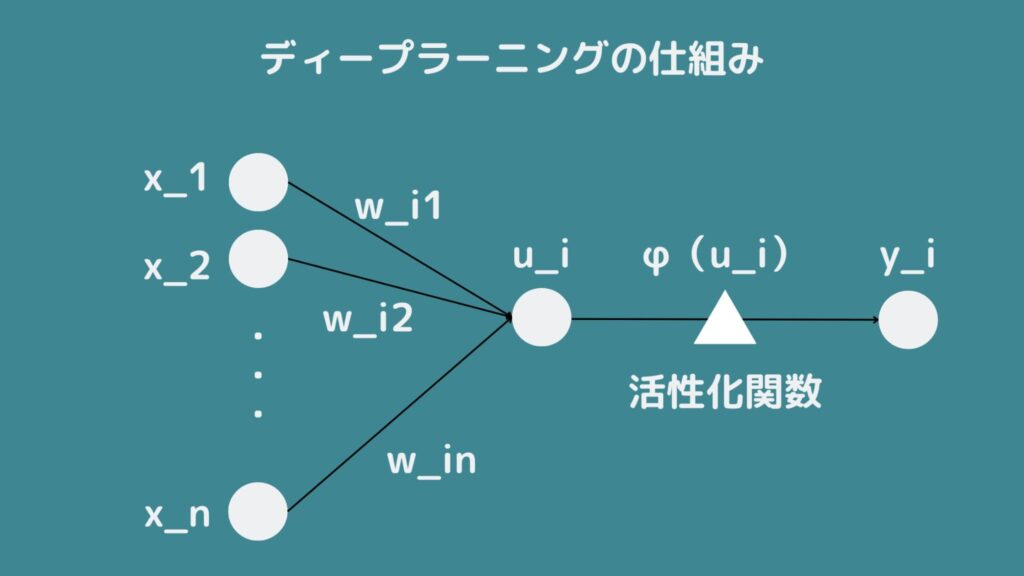
この仕組みを数式化しましょう!まず変数\(x_{1},x_{2},….x_{n}\)の重み付き線形和が\(u_{i}\)なので、以下のような式が成り立ちます。
\(u_{i} = \sum_{j=1}^{n} w_{ij}x_{j}\)
そして\(u_{i}\)に活性化関数\(φ()\)を適用させて予想したクラスを\(y_{i}\)とすると…
\(y_{i} = φ(u_{i}) = φ(\sum_{j=1}^{n} w_{ij}x_{j})\)
このような式が成立します。つまりディープラーニングはデータ\(x\)の線形和を活性化関数に適用させたものが予測値となることが分かりましたね!
ディープラーニングでは回帰や分類など様々な問題に適用できますが、活性化関数はそれらの問題に適合するよう選択する必要があります。
特にソフトマックス関数を選んだ場合、多クラス分類問題で用いられることがほとんどであることを覚えておきましょう!
理由として、クラスを予想するために「そのクラスに所属する確率」を用いるため、ソフトマックス関数の性質は非常に都合がよいことが挙げられます!
ニューラルネットワークや活性化関数の仕組みに関しては以下のUdemy講座で詳しく解説しているのでぜひチェックしてみてください!
ソフトマックス関数について解説!

次にソフトマックス関数について解説していきます!ソフトマックス関数は以下の式で表すことができます。
\(φ(u_i) = \frac{e^{u_i}}{\sum_{k=1}^{N} e^{u_k}}\)
ソフトマックス関数のイメージはこのようになります。
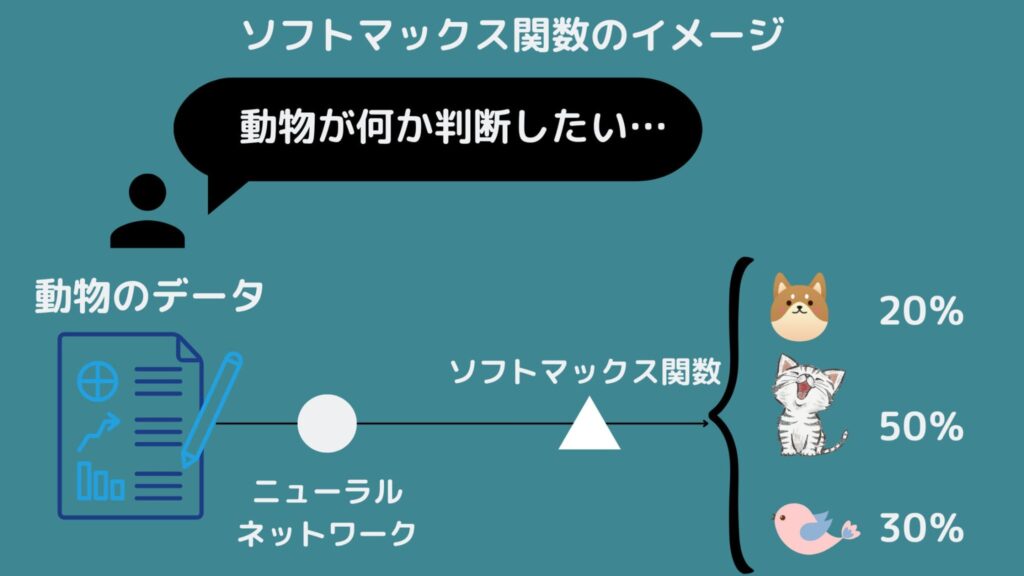
動物が犬・猫・鳥のどれかに判別したい場合、この図を見ると猫である確率が最も高いため、このデータは猫を示している可能性が高いことが分かりますね!
しかし実際にpythonなどでソフトマックス関数を実装すると、オーバフローを起こす可能性があります。
オーバーフローとはメモリの限度を超えて無限と表示してしまう現象を指します。メモリは桁を無限に持つことができない、かつ指数関数は値が大きくなりやすい性質があるため、オーバフローしやすいです。
したがって実装する際はデータの最大値Cを用いることでオーバーフローをできます!
\(φ(u_i) = \frac{e^{u_i+C}}{\sum_{k=1}^{N}(e^{u_k}+C)}\)
ソフトマックス関数を使ったディープラーニングのモデル構築をしてみよう!
ここまでソフトマックス関数について解説してきましたが、最後にソフトマックス関数を活性化関数に使用したディープラーニングのモデルを構築していきましょう!
今回は定番のMnistという手書き文字のデータセットを用いて、Kerasというライブラリを使用して画像認識問題を解いていきます!
Mnistは「Gradient-based learning applied to document recognition」で用いられたデータセットであり、現在でも多くの論文で用いられています。
Modified National Institute of Standards and Technologyの略であり、0~9の数字が手書き文字として格納されているデータセットです。
学習用に60000枚、検証用に10000枚のデータセットが格納されています。
コードは以下のようになります!
以下の部分でモデルを定義していて最終的な出力層の活性化関数としてソフトマックス関数(softmax)が使用されていることが分かりますね!
# Sequentialクラスを使ってモデルを準備する
model = Sequential()
# 隠れ層を追加
model.add(Dense(n_hidden,activation='relu',input_shape=(n_features,)))
model.add(Dense(n_hidden,activation='relu'))
model.add(Dense(n_hidden,activation='relu'))
# 出力層を追加
model.add(Dense(10,activation='softmax'))
ちなみに途中の隠れ層ではRelu関数という関数が使用されています。
ソフトマックス関数 まとめ
 (AIによるイメージ生成)
(AIによるイメージ生成)
本記事ではソフトマックス関数についてまとめました!
ディープラーニングについて詳しく知りたい方は、以下の記事をチェックしてみてください!




このようなデータサイエンスの力を身に付けるためにはスタビジの記事やスクールを活用すると良いでしょう。
そして僕の経験を詰め込んだデータサイエンス特化のスクール「スタアカ(スタビジアカデミー)」を運営していますので,興味のある方はぜひチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
データサイエンスに関する記事はこちら!


データサイエンスを勉強できるスクールやサイトは、ぜひこちらを参考にしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!