ディープラーニングの歴史を変えたAlexNetの構造を分かりやすく解説しPythonで実装!

こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では、ディープラーニングの歴史を語る上で外せないAlexNetについて詳しく解説していきたいと思います!
昨今、大規模言語モデルの登場で世間を騒がせているAIですが、その進化のきっかけの1つが今回解説するAlexNetなのです!
以下の動画でも解説していますのであわせてチェックしてください!
目次
AlexNetとは
AlexNetは、ImageNetを使った画像認識精度を競うILSVRC (ImageNet Large Scale Visual Recognition Challenge)2012という大会において2位と圧倒的な差をつけて優勝した手法です。
ImageNetは1400万枚以上の画像に対してラベルが付けられている巨大な画像のデータセットです。

(出典:ImageNet Large Scale Visual Recognition Challenge)
ILSVRC2010年〜2017年の間データセットとして利用されました。
2012年以前は画像から特徴量を人間が定義しそれを元にモデルを構築するアプローチが主流でしたが、2012年に突如登場したAlexNetは特徴量を人間が定義せずにモデルが特徴を抽出して画像認識をしてくれる巨大なニューラルネットワークアーキテクチャでした。
これにより2位に認識誤差率10%以上の圧倒的な差をつけて優勝したのです。
AlexNetの構造を見ていこう!
それではAlexNetの構造のどこが画期的だったのが論文をベースに見ていきましょう!
AlexNetはカナダのトロント大学のジェフリー・ヒントン研究室から発表されました。
論文は以下です。
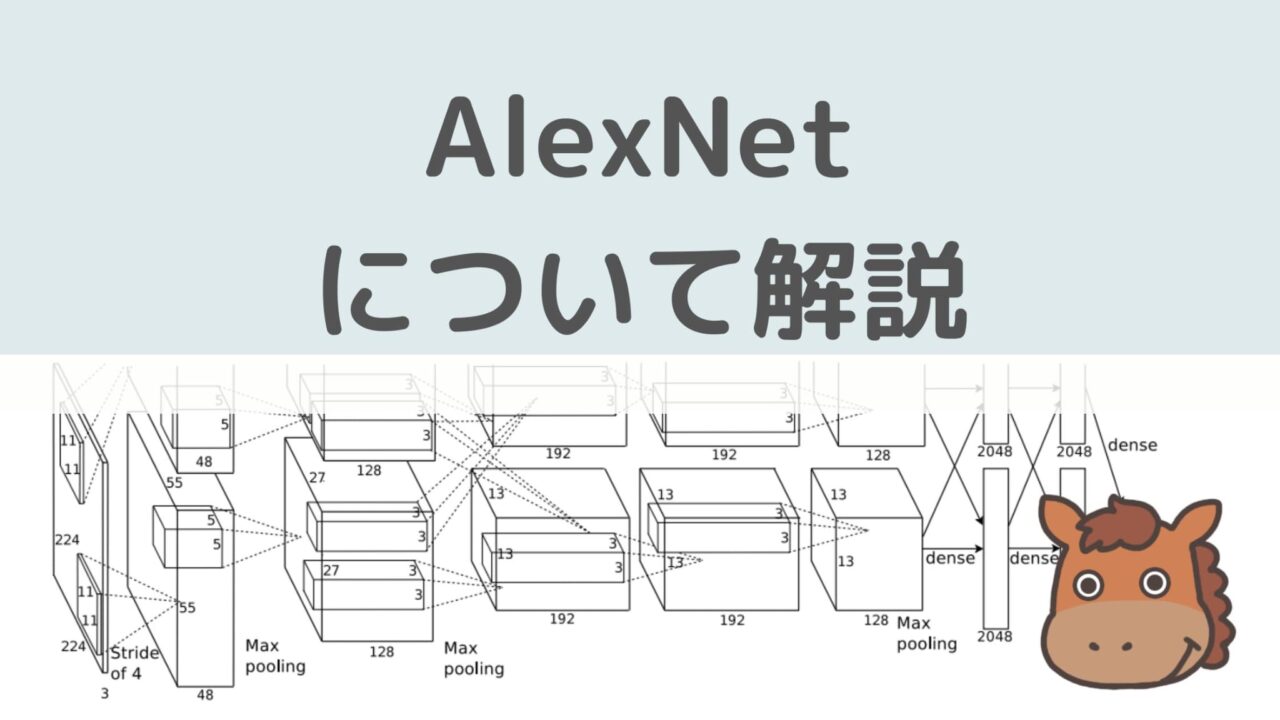
論文に掲載されているアーキテクチャは以下です。
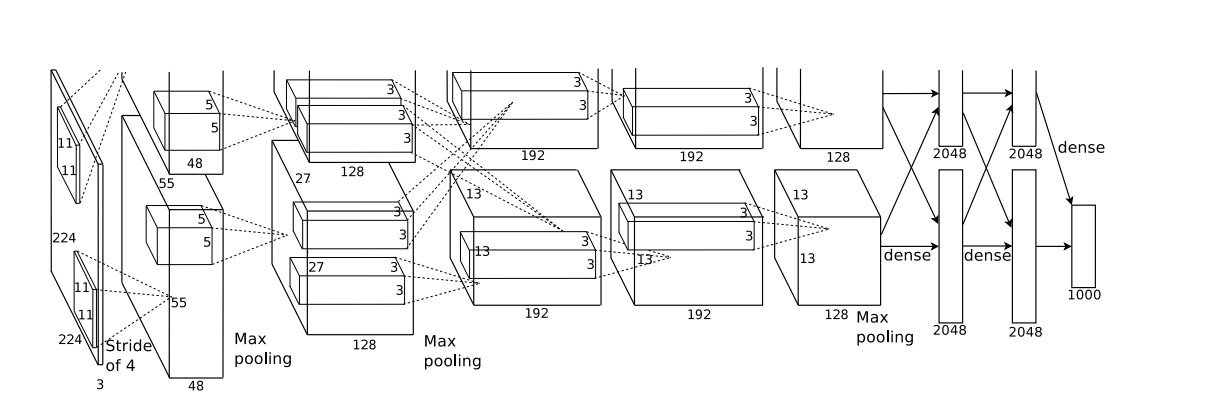
わかりにくいですが、畳み込み層とプーリング層、全結合層が組み合わさった巨大なニューラルネットワークになっています。
畳み込みニューラルネットワークについては以下の記事をチェックしてみてください!

具体的にどんな部分が画期的だったのか論文から拾って見ていきましょう!
活性化関数にReLU関数の導入
ディープラーニングでは、入力と重みによる計算を出力に変換する際に活性化関数という関数をかませます。
色んな活性化関数の種類があるのですが、長い間シグモイド関数やtan関数などが使われるのが一般的でした。
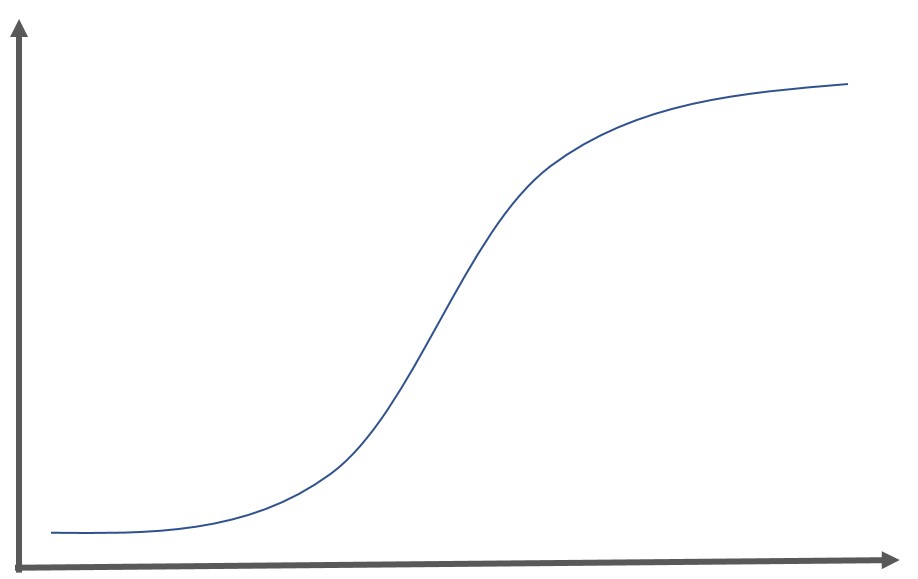
古くから使われているシグモイド関数はロジスティック回帰分析に登場する関数であり出力を線形的に捉えることが可能です。以下のような関数になります。
$$ y= \frac{1}{1+exp(-x)} $$
シグモイド関数は、ある入力に対する出力を0~1の範囲に抑えることができ、グラフは以下のようになります。
しかしシグモイド関数を利用すると最適解を求める際に勾配消失という事象が起きてしまう問題がありました。
勾配消失問題とは、ディープラーニングの最適解を求める上で微分を行い勾配を計算して重みを更新していくのですが、この勾配が0に近くなってしまうと更新幅が小さくなり最適解にたどり着かなくなる問題です。
この勾配を計算する上で複数回微分を重ねて行うのですが、シグモイド関数は微分値の最大値が0.25になるため、シグモイド関数を中間層にたくさん用いてしまうと層が重なるほど勾配が小さくなり勾配消失問題が起きてしまうのです!
それを解決したのがReLU関数なのです。
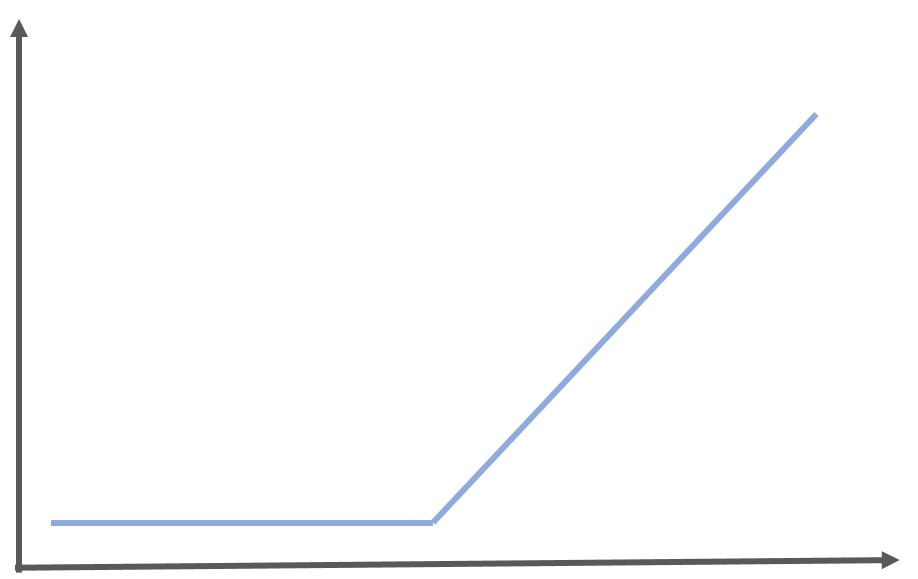
RELU関数は0より小さい場合は0を出力し、0より大きい場合はそのまま計算結果を出力するという特殊な関数です。
\begin{eqnarray} y= \left\{ \begin{array}{l} x ~~ (x>0) \\ 0~~ (x<=0) \end{array} \right.\end{eqnarray}
ReLU関数の微分値の最大値は1になるので勾配を消失させずに層を重ねることが可能なんです。
出力層の活性化関数としては非常に貧弱なので、出力層では用いられることはほぼありません。
グラフは以下のようになります。
過学習を抑えるためのデータ拡張(Data Augmentation)
AlexNetはこれまでのモデルの比ではないほど巨大なアーキテクチャで、その分パラメータが多いので過学習に注意しなくてはいけません。
そこで取られたアプローチが既存のデータセットを人為的に増幅させるデータ拡張というアプローチ。
具体的には、画像データの位置を動かしたり、RGBの色合いを変えたりして編集することで新たなデータセットを作るのです。
過学習を抑えるためのドロップアウト
過学習を抑えるアプローチとしてドロップアウトというアプローチを使うことがよくありますが、AlexNetでもご多分に漏れずドロップアウトを適用しています。
AlexNetでは、一部の全結合層で0.5の確率で出力が0になるドロップアウトを適用しています。
重なり合い最大値プーリング層
ディープラーニングでは、過学習を抑えるためにプーリング層という層が使われることが一般的です。
このプーリング層の役割は以下のように計算された各領域の要素の情報を圧縮すること。
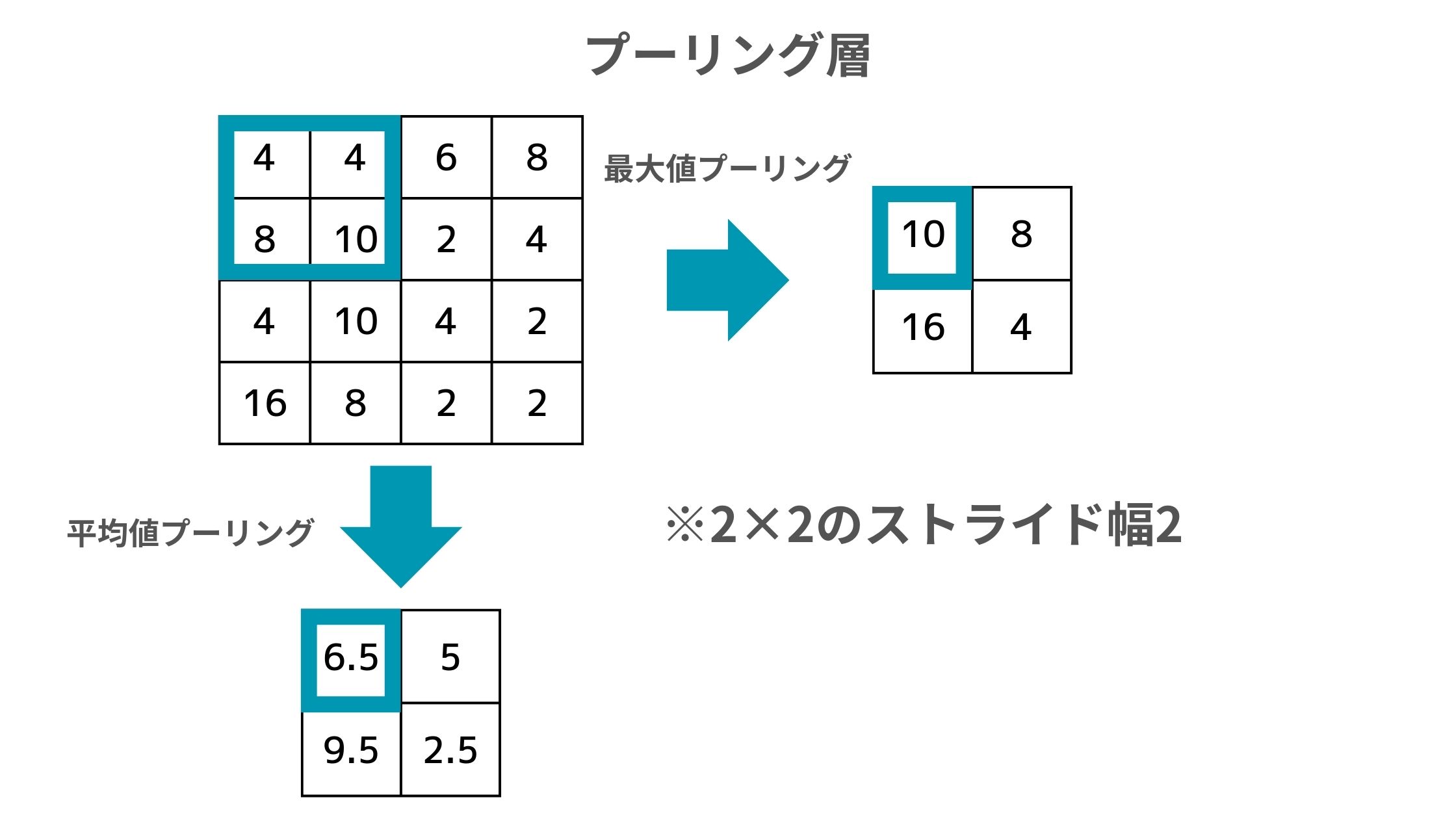
元のデータの左上4つをフィルタで囲っていて、そこから最大値プーリングであれば最大値の10が抽出され、平均値プーリングであれば4, 4, 8, 10の平均を取った6.5が抽出されます。
そして最大値を出力したり平均値を出力したりするアプローチがあるのですが、AlexNetでは最大値を出力するアプローチを採用しています。
図だと2×2のストライド幅が2なので各フィルタ内の要素が重ならないですが、AlexNetでは3×3のフィルタでストライド幅が2の重なり合いを許すプーリング層を採用しています。
AlexNetをPythonで実装してみよう!
それではAlexNetをPythonで動かしてみましょう!
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision import models
import torch.nn as nn
import torch.optim as optim
# データの前処理定義
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR-10データセットのダウンロードとロード
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=32, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=32, shuffle=False, num_workers=2)
# クラスラベル
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# モデル、損失関数、最適化手法の定義
model = models.alexnet(pretrained=False, num_classes=10)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# トレーニングループ
num_epochs = 1 # エポック数を1にしていますが通常は複数回
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 200 == 199: # 200ミニバッチごとに出力
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
print('Finished Training')
# テストデータに対する精度計算
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
ここでは、CIFAR-10のデータセットを使用しています。
CIFAR-10は10個のクラスに分けられたカラー写真のデータセットで画像認識の評価によく利用されます。
「# モデル、損失関数、最適化手法の定義」の箇所で、使用するモデル(AlexNet)、損失関数(CrossEntropyLoss)、および最適化手法(SGD)を定義しています。
このコードではなるべく処理時間を抑えるためにパラメータを設定していますが、実際に使う際は学習率、エポック数、バッチサイズなどを適切に調整してください!
AlexNetまとめ
ここまででAlexNetについて簡単に解説してきました!
AlexNetの登場でそれまで下火だったAIに一気に火が付きAIブームが訪れ今に至ります。
AlexNetのあとはResNetを始めとするさらなる改良手法が登場し、AlexNet自体が使われることはなくなりましたが、それでもAlexNetの起こしたブレークスルーがベースとなっています。
さらにここでのブレークスルーが昨今の画像生成系AIへの流れに繋がっていることは間違いありません。
最近の画像生成系AIについては以下の記事でまとめていますので関連してぜひ理解しておきましょう!
より詳しくディープラーニングや最近の大規模言語モデルについて知りたい方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の講座をチェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!