GAN(敵対的生成ネットワーク)についてわかりやすく5分で解説!DALL-EやStable Diffusionとの違いは?


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では、GAN(敵対的生成ネットワーク)についてなるべく分かりやすく5分で解説していきます!
また、2022年後半からはじまった画像生成系AI(DALL・EやStable Diffusion)手法との関連性についても見ていきましょう!
以下のYoutube動画でも分かりやすく解説していますので合わせてチェックしてみてください!
目次
GAN(敵対的生成ネットワーク)とは
GANは英語発音的にはガンに近いのですが、日本ではガンともギャンとも呼ぶことがあります。
Generative Adversarial Networksの頭文字を取ってGANです。
そんなGANとはどんな手法なのでしょうか?
GAN(Generative Adversarial Networks)は2014年に発表された手法で、論文は以下です。詳しく知りたい方は論文を読んでみるとよいでしょう。
GANの仕組みは非常にシンプル。
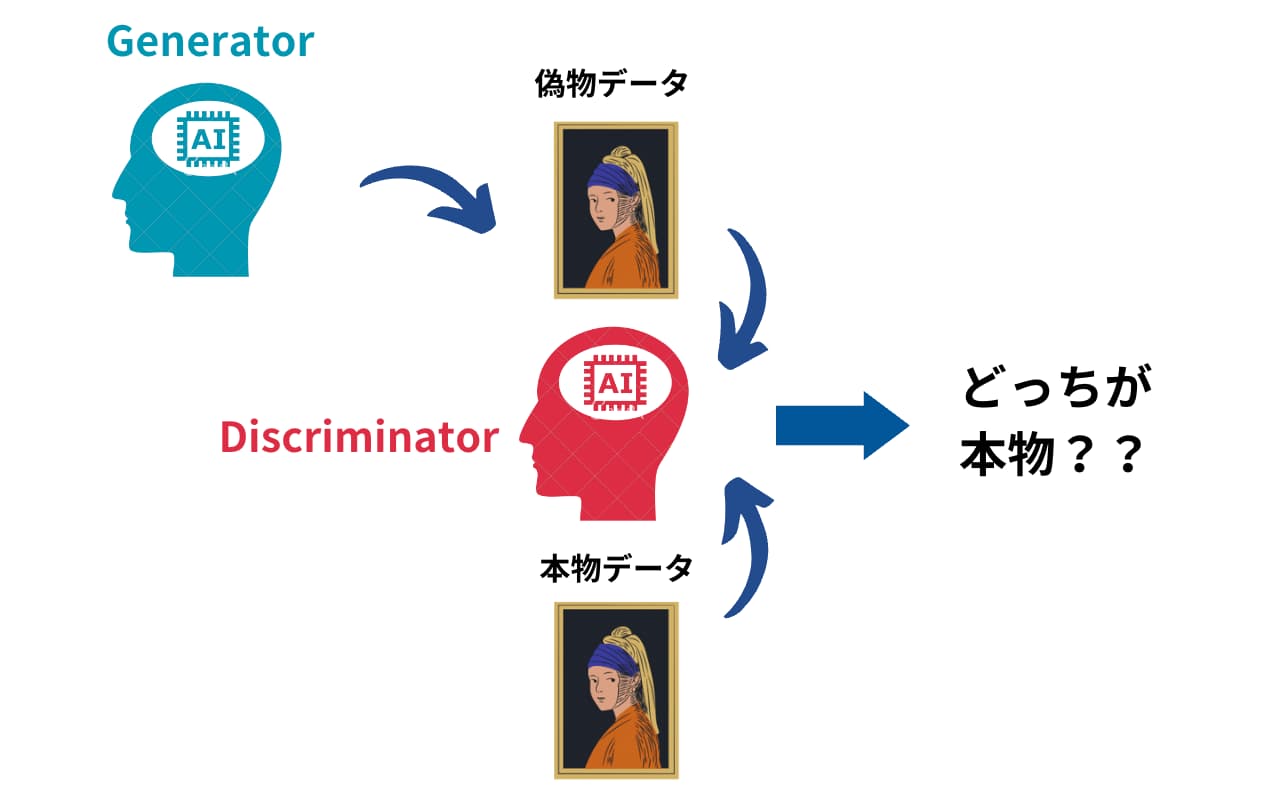
- 2つのGeneratorとDiscriminatorを用意します。
- Generatorは偽物のデータを生成します
- DiscriminatorはGeneratorが生み出した偽物のデータと本物のデータを判別しま
- これらを競い合わせ2・3を繰り返すことで、Generatorが生み出すデータが本物に限りなく近いものになっていきます。
これにより高精度の画像を生成できるモデルを構築できるのです。
両者を競い合わせることからこのアプローチはGAN(敵対的生成ネットワーク)と呼びます!
GeneratorとDiscriminatorはそれぞれニューラルネットワークのモデル。
GANを使って生成された部屋の画像が以下(正確にはDCGAN)。
 (出典:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS)
(出典:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS)
このホテルの画像、割と結構有名なのでいろんなところで引用されているのですが、これらの部屋の画像が全てフェイクだというのは驚きですよね。
GANのベースとなっているニューラルネットワークやディープラーニングについては当メディアが運営するスタアカにて詳しく解説しているのでより深く学びたい方はそちらもぜひチェックしてみてください。
GAN(敵対的生成ネットワーク)の派生手法
それでは続いてGANの派生手法について見ていきましょう!
GANには様々な派生手法が存在しますので有名な手法をいくつか紹介していきます。
CycleGAN
CycleGANは特定の画像を別の画像に変換するアプローチ。
論文は以下です。
リアルな画像を有名な画家の絵のタッチに変換したり、馬をシマウマに変換したりすることが可能です。

画像を色んな有名な画家の絵のタッチに変換できるのは画期的ですよね。

CycleGANの構造は以下のようになってます。
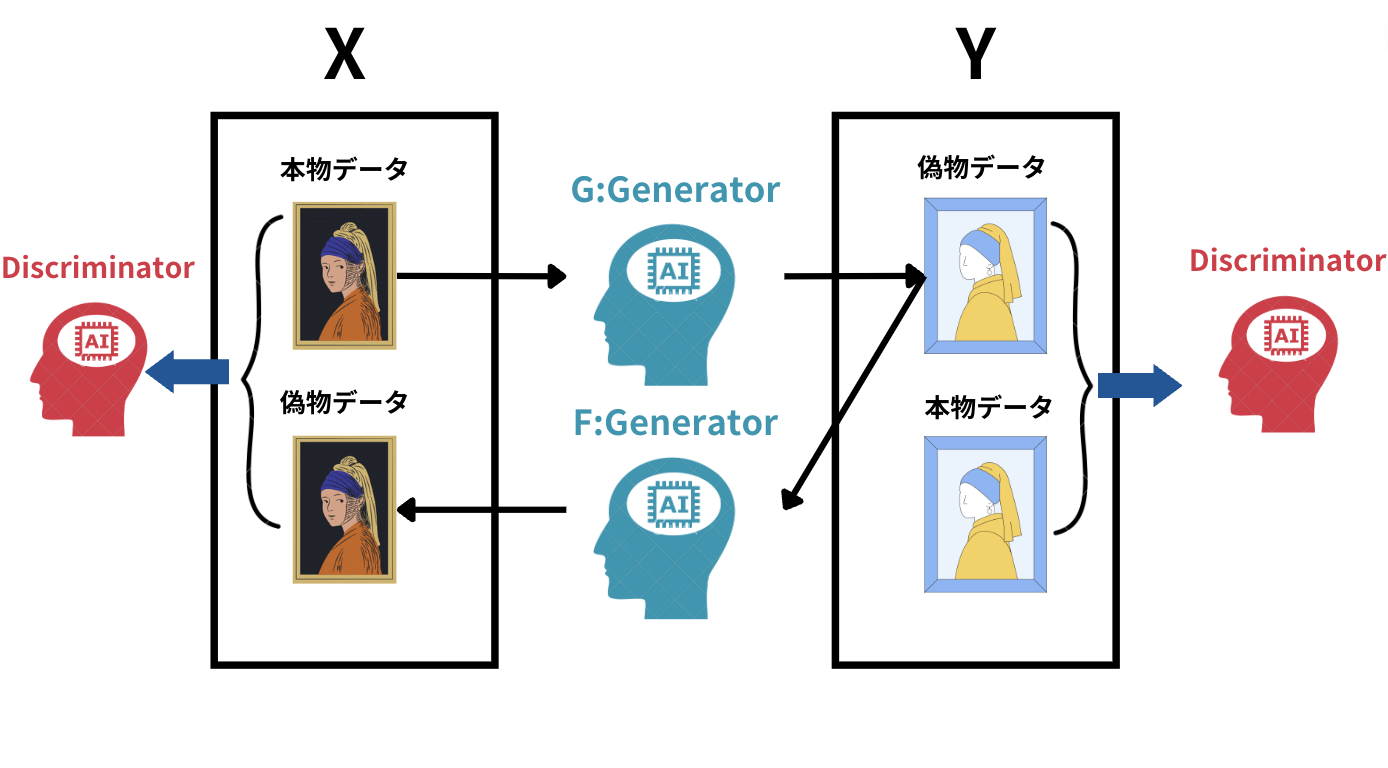
Xというデータセット(馬)とYというデータセット(シマウマ)のそれぞれをGeneratorで相互変換しDiscriminatorで真贋を判別するアプローチ。
GeneratorとDiscriminatorの2つの組み合わせを利用しています。
CycleGANに関しては以下の記事で解説していますのでチェックしてみてください!

StyleGAN
続いてStyleGAN。
論文は以下です
2014年に発表されたGANから4年後にNvideaのチームが発表したのがこちらのStyleGAN。
StyleGANの登場により非常に高精度な画像が生成できるようになり人物の写真などが本物と見分けがつかないほど高精度になっています。
以下はStyleGANが生成した存在しない人物の画像。

めちゃくちゃリアルですよね。
その後もStyleGAN2、StyleGAN3とアップデート版が登場しています。
StyleGANと従来のGANのアーキテクチャの違いは以下の通り。
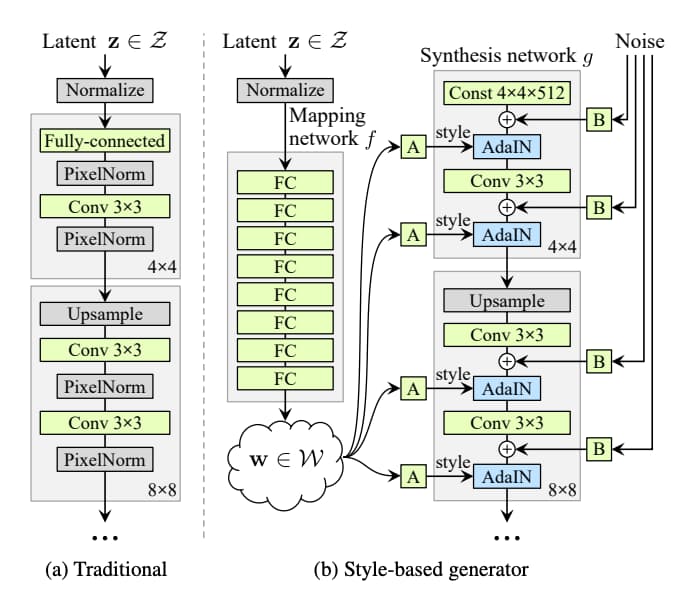
左側は従来のGeneratorで右側がStyleGANのGeneratorです。
正直細かい部分は覚える必要ないのですが、通常のGANでは潜在変数zから直接画像を生成していたのに対してStyleGANは潜在変数zを潜在変数wに変換してから画像を生成してます。
その過程でstyle処理(Aの部分)をしたりノイズ(Bの部分)を追加して微調整しています。
GAN(敵対的生成ネットワーク)とDALL・EやStable Diffusionとの違い
続いてそんなGANと2022年後半から盛り上がってきた画像生成系AI(DALL・EやStable Diffusion)との違いについて見ていきましょう!
実はDALL・EやStable Diffusionの元となっているのはGANではなく拡散モデル(diffusionモデル)と呼ばれるモデルです。
拡散モデルを発表した最初の論文は以下です。
DDPMと略されることもあり、そのまま直訳するとノイズ除去拡散確率モデルとなります。これを拡散モデルと呼びます。
一言で言うと、「ある画像に対してランダムノイズを徐々に当てていき完全にノイズになったものを逆向きに推定した際にノイズ除去後の画像と元の画像の差分を少なくするように学習した技術」です。
以下は論文から引用した図です。
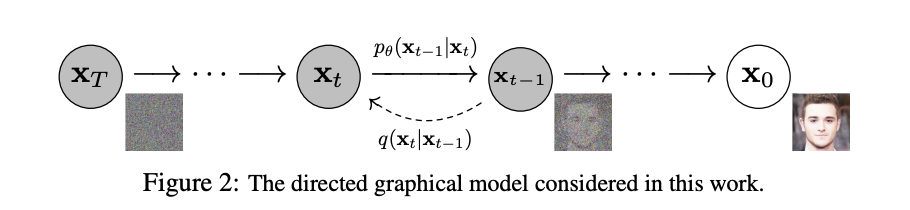
\(X_0\)の人間の顔画像に対してランダムノイズを当てていき、最終的に完全なノイズになっているのが\(X_T\)ですね。
このランダムノイズを与える過程を逆に遡った時に元の画像と近い画像が得られるようにパラメータを最適化するのが拡散モデルの考え方です。
詳しくは以下の記事にまとめていますのでチェックしてみてください。
以下の論文でまさに拡散モデルがGANを上回るよということが提案されています。
以下の画像は左側がGAN、真ん中が拡散モデル、右側がトレーニングデータのサンプルなのですが、GANよりも拡散モデルの方がバリエーションに富んだ画像を生成していることが分かりますね!

画像生成の評価をするのは非常に難しいのですが、1つに生成した画像の多様性が挙げられます。
単調な画像を生成してしまうモデルよりも多様性のある画像を生成するモデルの方が有用性が高いよねという判断です。
拡散モデルの登場により、画像生成の主戦場は拡散モデルベースに移りつつありますが、GANの改良モデルも出てきており、相互に影響を与え合いながら今後もさらなる高精度な画像生成AIが登場してくることでしょう!
GAN(敵対的生成ネットワーク)まとめ
ここまでご覧いただきありがとうございました!
本記事では、GANについて解説してきました!
画像生成系AIの進化には今後も期待ですね!
海外の動画ですが、概要を理解するには以下の動画が非常に分かりやすいです
より詳しくディープラーニングや最近の大規模言語モデルについて知りたい方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の講座をチェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!