
OpenAIが開発したDALL・E2(ダリ2)の使い方と仕組みを解説!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
AIの進化が凄まじいですが、その中でもテキストから画像を生み出す技術が多く登場しています。
この記事では、そのtext to imageの領域の中でも時代の最先端を走るOpenAIが開発したDALL・E(ダリ)2に焦点を当てて使い方や仕組みを解説していきたいと思います。
以下のYoutube動画でも分かりやすく解説しているので興味のある方はあわせてチェックしてみてください!
DALL・E(ダリ)って何ができるの?使い方
まずは、簡単にDALL・Eを用いて何ができるのか解説していきたいと思います。
DALL・Eは、まさに有名な画家であるサルバドール・ダリとピクサーのWALL・E(ウォーリー)から来ています。

DALL・Eを使うことで特定の文章インプットに対して画像のアウトプットを得ることができます。
そう、たとえ絵が描けなくてもあなたはダリのような素晴らしい画家になったも同然なのです!
DALL・Eは、OpenAIのサービスサイトから誰でも利用することができます。
利用に際して無料クレジットが付与されますが、無料クレジットを消化すると有料でクレジットを購入する必要があります。
実際にダリ本人の画像自体もDALL・Eに作らせました。
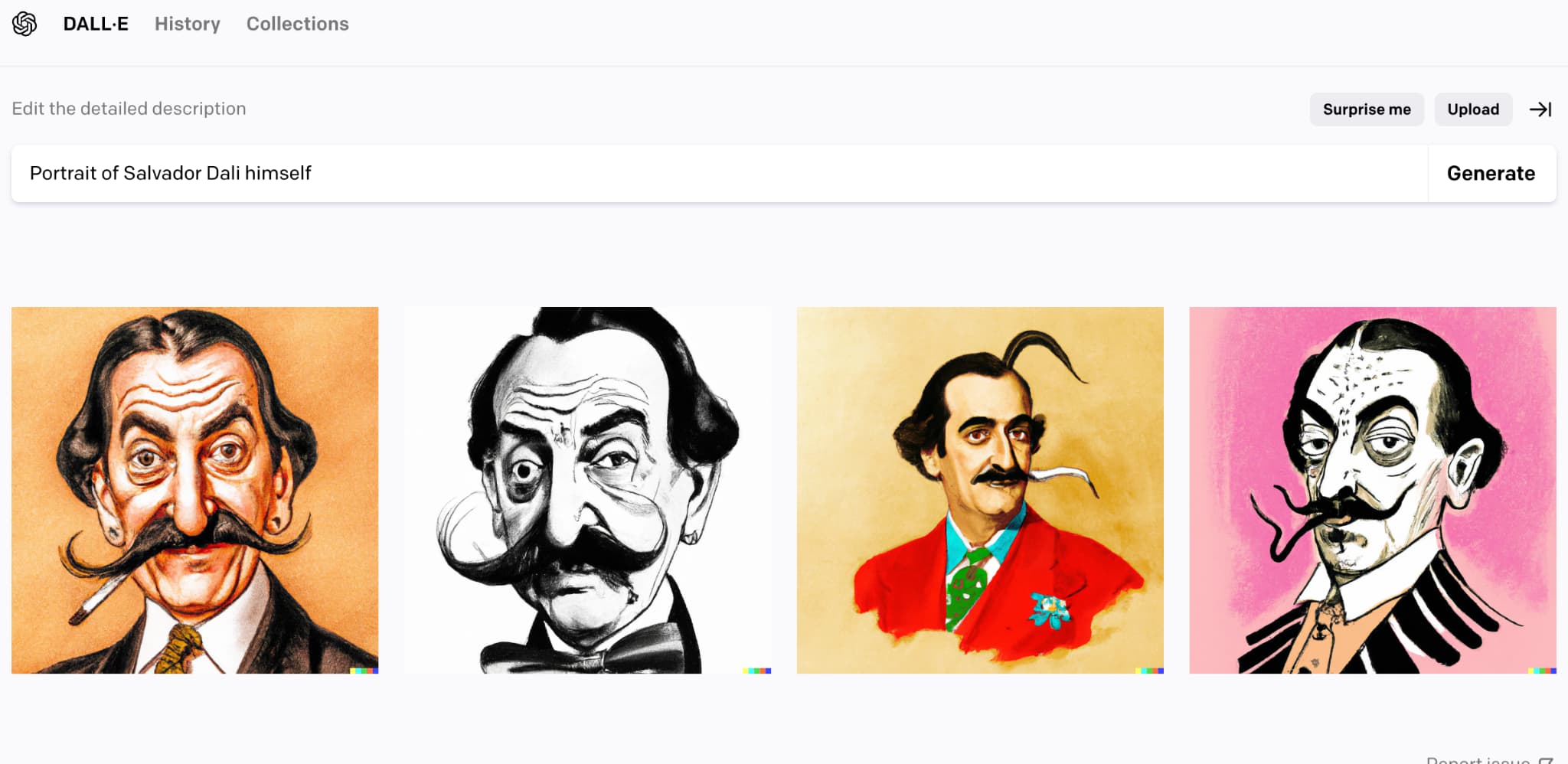
「Portrait of Salvador Dali himself」を入れたらそれっぽいサルバドール・ダリの画像を4枚出力してくれました。

DALL・E(ダリ)2のベースとなっている技術
さて、DALL・Eでどんなことができるのか分かったところで、DALL・E2が内部的にどんな仕組みになっているのか簡単に見ていきましょう!
DALL・Eが2021年に発表されて、2022年にDALL・E2が発表されました。
DALL・E2の論文は以下になりますので詳しく知りたい方は論文を見てみてください。
DALL・E2を簡単に理解するには、まずCLIPと拡散モデルという技術について理解しておく必要があります。
CLIP
CLIPとは2021年にOpenAIが発表した技術で、「Contrastive Language-Image Pretraining」の略です。
論文は以下。
CLIPとは、簡単に言うと、「大量の画像とテキストの組み合わせを学習し、画像とテキストの類似度を算出した上で、特定の画像に対して適切なテキストを選択してくれるようにするアプローチ」です。
以下の画像が論文に記載されている処理イメージです。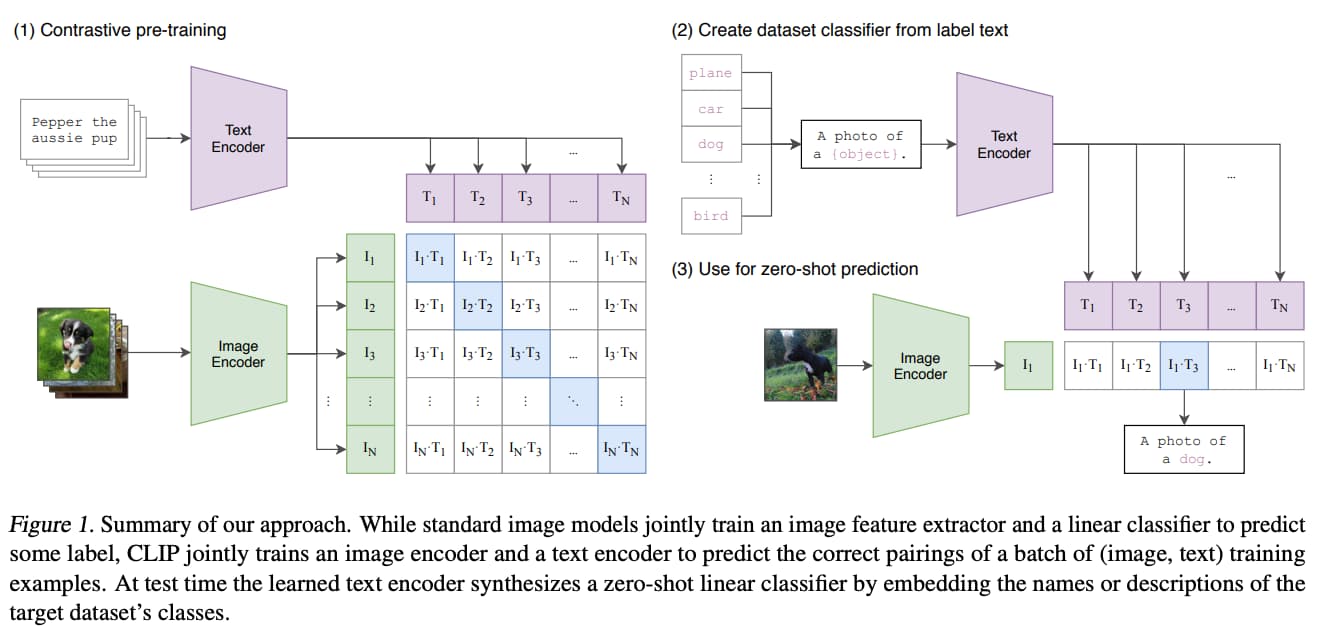
まず、左の工程でテキストと画像をぞれぞれベクトル化しそれらの情報から類似度を算出しています。
ちなみにテキストをベクトル化する際にはTransformerを利用しています。TransformerはGPTシリーズにベースにもなっている技術で非常にAI分野の発展に貢献した技術です。
画像のベクトル化にはCNNを利用しています。
簡略化して書くとこんなイメージ
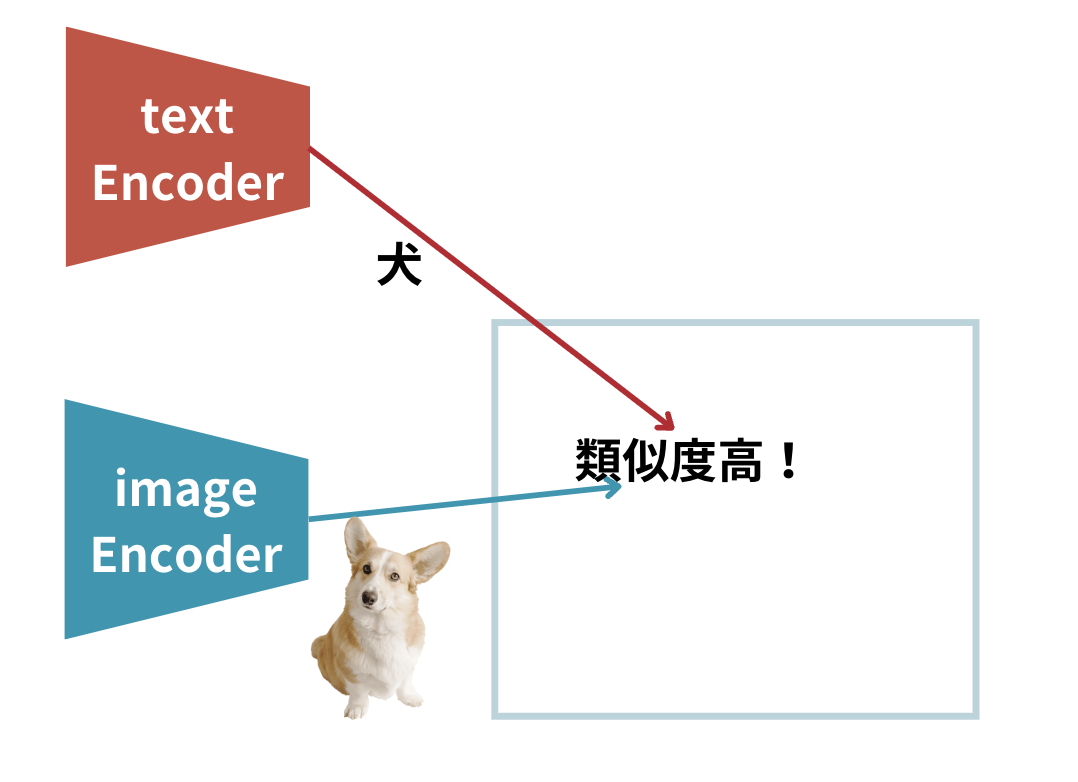
犬の画像と犬というテキストの類似度を算出しています。
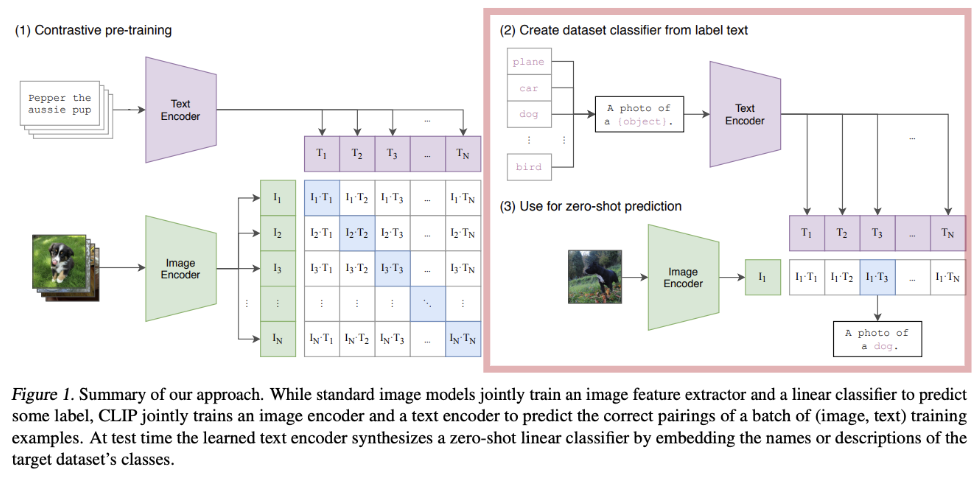
続いて右の工程で犬の画像をインプットしてテキストの中から最も類似度が高いと考えられるdogが選択されています。
DALL・E2はこのCLIPという技術を利用しながら、逆にテキストから画像を生成しようとするアプローチが取られています。
拡散モデル
テキストから画像を生成する上で用いられている重要な技術が拡散モデル(diffusion model)です。
こちらは2020年に発表された技術です。
論文は以下。
拡散モデルは、画像生成発展のベースになっている技術です。
簡単に言うと、「ある画像に対してランダムノイズを徐々に当てていき完全にノイズになったものを逆工程でノイズを除いていき、元の画像とノイズを除いた後の画像が近くなるように学習する技術」です。
イメージはこのような図です。
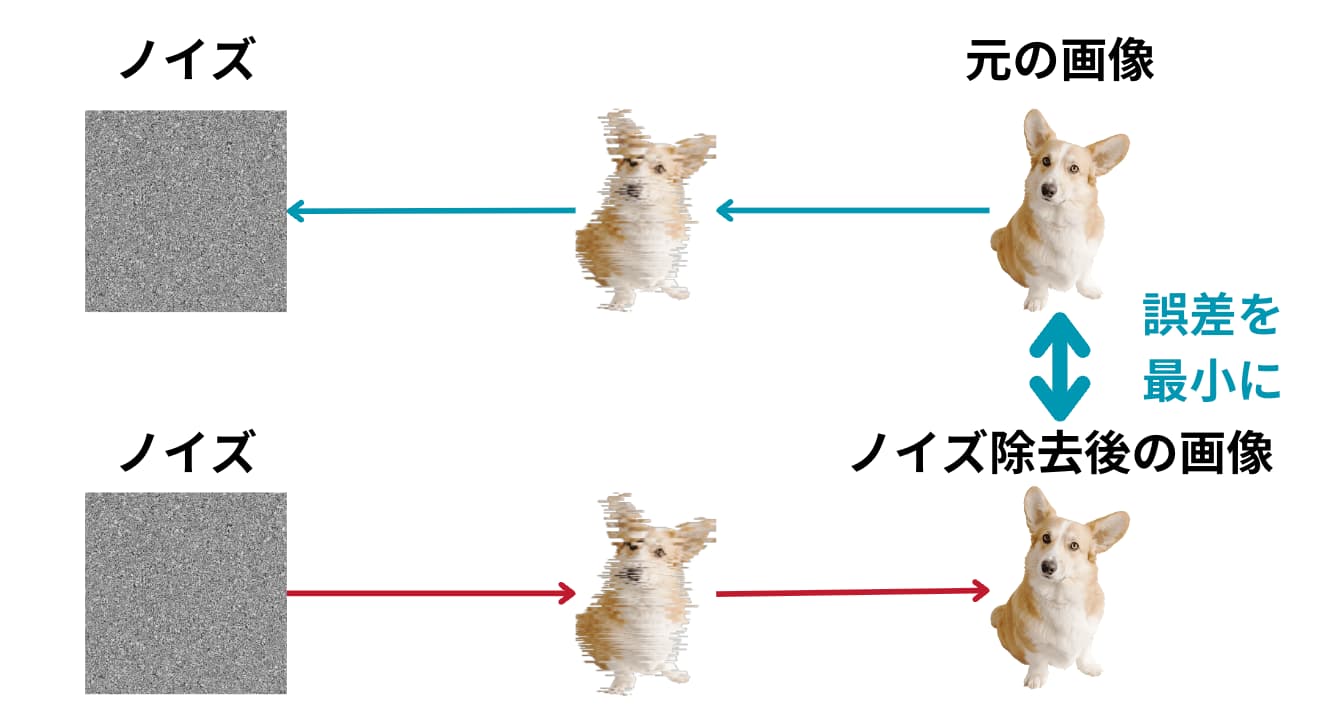
図のように犬の画像に対してノイズを乗せて、そのノイズを逆に取り除く際にノイズを取り除く部分は複数のパラメータを用いて定式化することが可能です。
ちなみに一般的にノイズには正規分布(ガウス分布)に従うノイズが当てられます。
この「ノイズ取り除く過程を定式化した部分のパラメータを調整して元の画像との差分を小さくする試み」が拡散モデルなのです!
拡散モデルに関しては以下の記事でまとめています!
DALL・E(ダリ)2の仕組み
ベースとなるCLIPと拡散モデルを理解したところで、DALL・E2の仕組みについて簡単に見ていきましょう!
以下がDALL・E2のアーキテクチャになります。
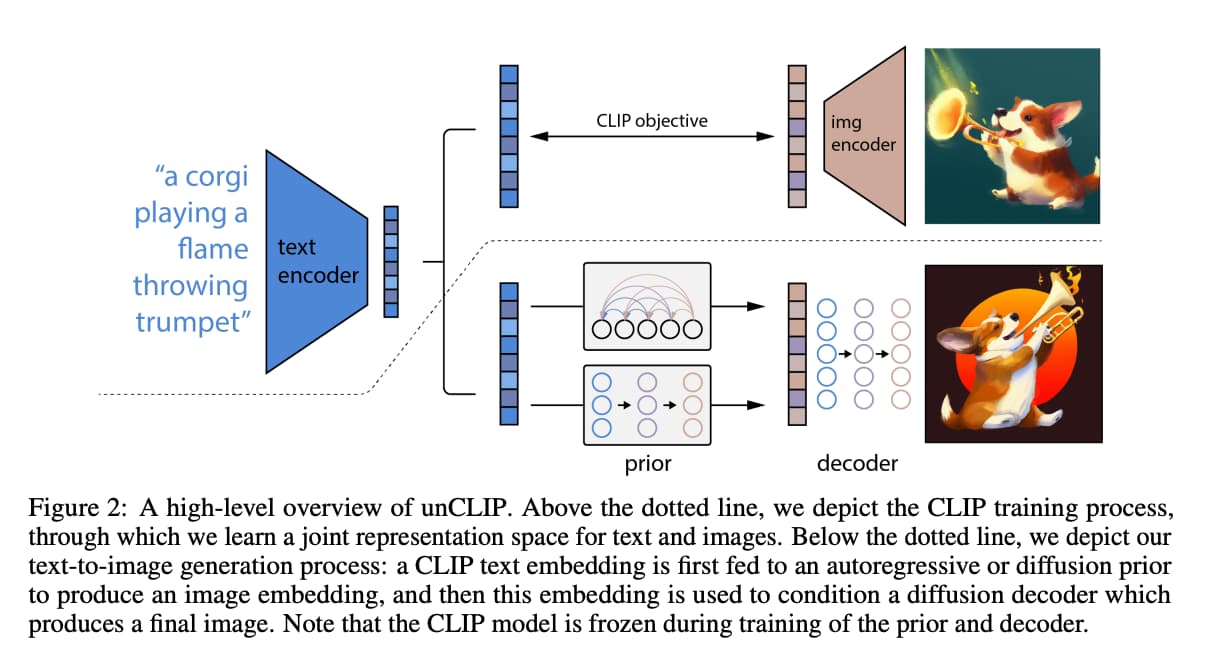
画像の上部では、CLIPの学習をしています。
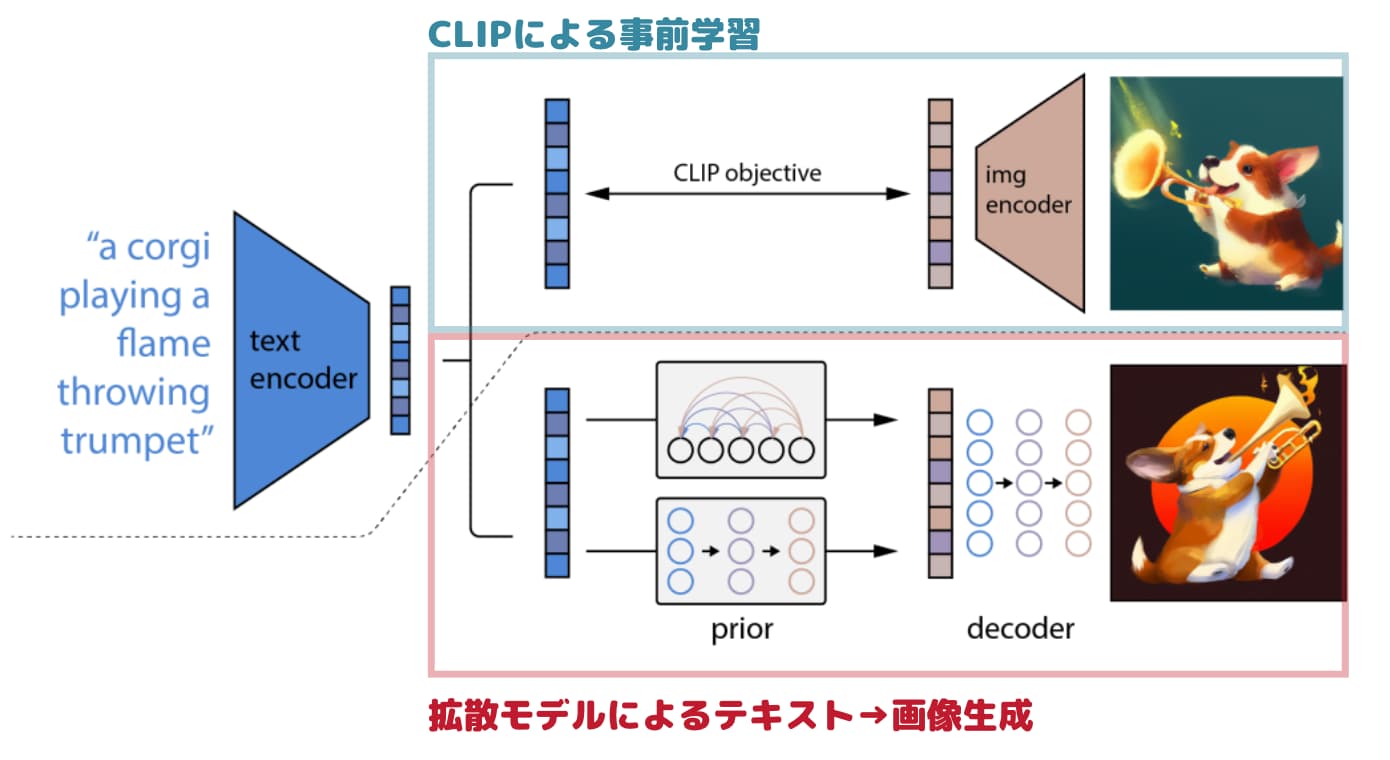
これによりテキストと画像の対応関係を学習した事前学習モデルが作成されます。
そして下部がテキストから画像を生成する工程であり、prior・decoderと呼ばれるフェーズがあります。
・prior(事前分布)は、テキストベクトルから画像ベクトルを出力する工程です
・decorder(デコーダー)は、画像ベクトルから画像を出力する工程です
この工程で前述の拡散モデルが用いられています。
前述の通り拡散モデルではノイズの乗った画像からノイズの無い画像を予測しますが、その工程の条件付けにテキスト情報を用いています。
ちなみにDALL・E2では、以下のように元々の画像をベースにバリエーションをもたせた複数画像を再生成することができます。

また、以下のように複数の画像を元に組みあわせて混合された状態で描画することもできます。

DALL・E2の課題
そんな非常に高精度な画像を生成できるDALL・E2ですが、いくつか課題が残っています。
たとえば以下の左側のように特定のオブジェクトの位置関係を上手く表現することができていません。

また、以下のように特定の文字が書かれた画像を生成してと言っても上手く文字を反映してくれないことがあります。

このようにまだまだ課題の残るDALL・E2ですが、今後さらなる発展により改善されていくでしょう。
DALL・E(ダリ)2 まとめ
 (上記もダリによる作画です)
(上記もダリによる作画です)
今回はDALL・E2について簡単にまとめてきました!
ここまでは、DALL・E2がどんな仕組みなのか見てきましたが、ザックリ理解した後は実際に手を動かしながらガシガシ使ってみることが大事です。
DALL・E2をはじめとした生成系AIを利用する方法を知りたい方は当メディアが運営するスタアカの以下のコースを是非チェックしてみてください!
スタアカは業界最安級のAIデータサイエンススクールです。

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
・生成系AIの基礎や使い方を学ぶ
AIデータサイエンスを学んで市場価値の高い人材になりましょう!
データサイエンスやAIの勉強方法は以下の記事でまとめています。


また、以下はDALL・E2を分かりやすく解説されている記事や動画でこの記事を書く際も参考にさせていただきました。
・【論文メモ】DALL·E
・OpenAI の超高品質テキスト→画像生成モデル DALL·E 2 の技術詳細を解説
・【AI論文解説】DALL-E 2へ至るまでの道のり:文章に沿った画像を高品質かつ多様に生成 -詳細編-
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















