
Transformer(トランスフォーマー)をAI進化の流れと共にわかりやすく解説!Attention層に至るまで

こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では、昨今話題のAIの進化のきっかけになったTransformer(トランスフォーマー)という手法について解説していきます。
主要なAI用語について一挙にまとめた以下の記事も合わせて要チェックです!

2017年にこのTransformerが登場し大きくAIの精度が向上し、その後の研究に多大な影響を与えました!
昨今のAIの流れの土台になっている手法ですので、ぜひおさえておきましょう!
以下の動画でも分かりやすく解説しているのであわせてご覧ください!
目次
「Transformer(トランスフォーマー)」の概要をザックリ解説

Transformerとは、「Attention Is All You Need」という論文で2017年に発表されたディープラーニングのモデルです。
以下、「Attention Is All You Need」の引用になります。
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
引用元:Google- “Attention Is All You Need”
どんなことを言っているかというと従来のリカレントニューラルネットワークや畳込みニューラルネットワークで利用されていたリカレント層や畳み込み層を使わずにAttention層だけを使うようにしたらなんか精度がめっちゃ良くなったよ!ということです。
「Attention Is All You Need」とは、その言葉通りAttention層だけでいいんだよ!ってことです。
そう、Transformerのすごいところは、今までのRNNやCNNなどの従来のディープラーニングで当たり前に考えられていたReccurent層や畳み込み層を使わずにAttention層だけを使うようにしたということなんです!
そこからBERTやGPTなどの新しい手法の登場、これらの大規模言語モデルの戦いへとつながっています。
ザックリ理解できたところで、具体的な仕組みについて見ていきましょう!
Transformer(トランスフォーマー)の仕組みとアルゴリズム解説
それでは具体的にTransformerがどんな仕組みなのか見ていきましょう!
そのためにまずは、先ほど登場した従来のニューラルネットワークに使用されていた畳み込み層やリカレント層などがどんな層なのか解説していきます。
その後にTransformer(トランスフォーマー)の構造やそこで使われているAttention層について見ていきましょう!
畳み込みニューラルネットワークとは?畳み込み層とは?
従来の画像認識を解くタスクでは畳み込み層という特殊な層を用いた畳み込みニューラルネットワークという手法が主要でした。
畳み込み層とは3次元の画像情報を1次元に直すことなく位置情報を保持して次の層に渡すアプローチです。
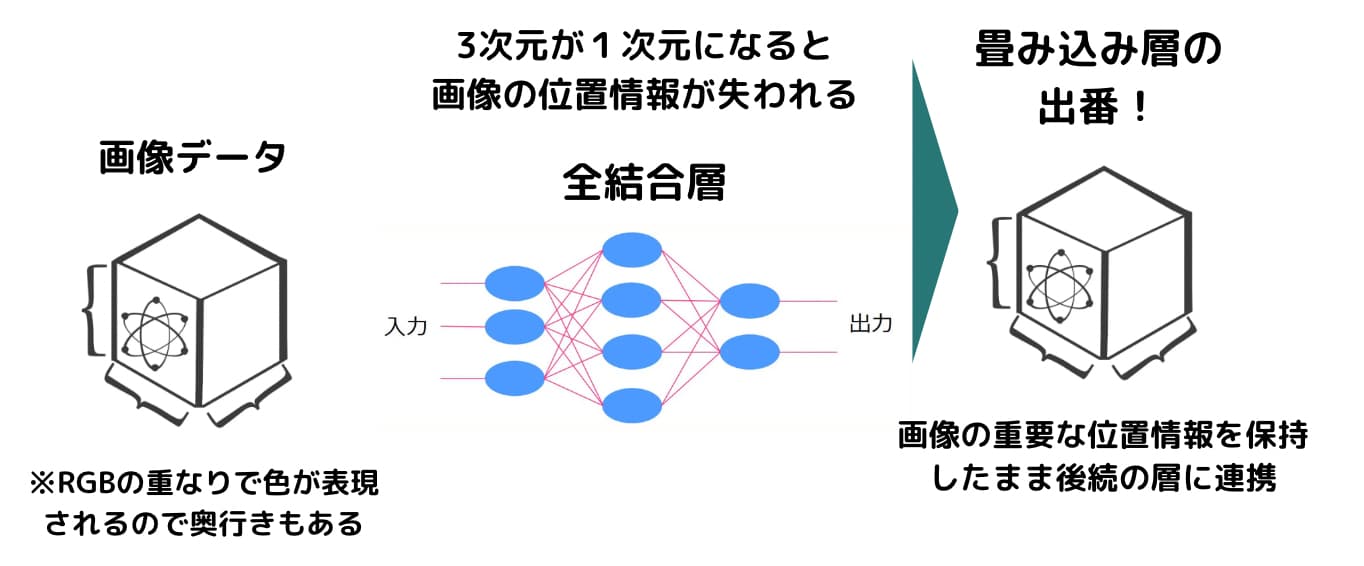
以下のように特定のフィルタを通して計算していきます。
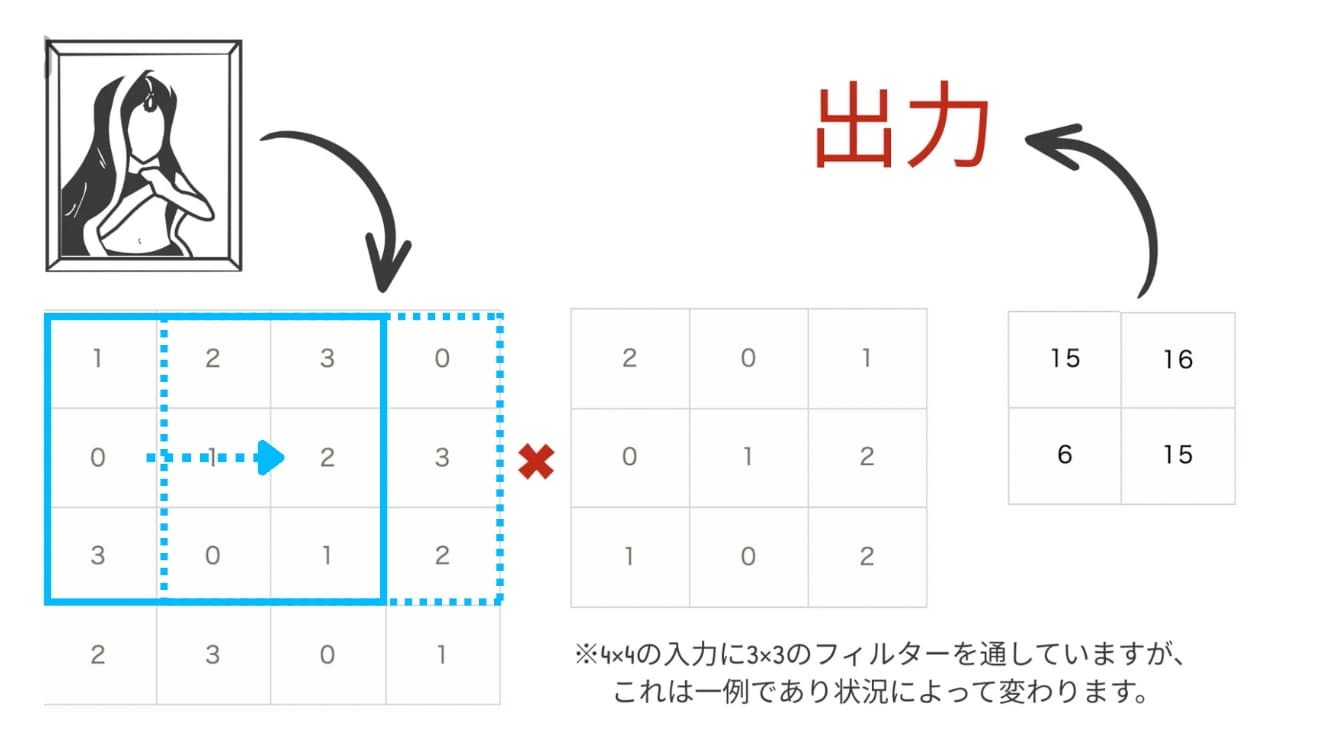
この場合、4×4の入力画像データに対して、3×3のフィルターをかけあわせていっています。
1番右の2×2のデータの左上には、4×4の入力と3×3のフィルターをかけあわせて1×2+2×0+・・・1×2=15で入ります。
畳み込みニューラルネットワークに関しては当メディアが運営しているスタアカの「ディープラーニングコース」で詳しく解説しています!
リカレント層とは?
リカレント層とは、従来のリカレントニューラルネットワークという手法に使われていた層構造になります。
自然言語処理の分野において使われていて、文脈を読むのに利用されていました。
例えば以下のような文があったとしましょう!
Tom came home, and he said “I’m () “.
()の中にどのような文章が入るかほとんどの人が分かると思います。
おそらく
Tom came home, and he said “I’m home ”
でしょう。
このようにテキストの文脈からワードを推論するのは周りの文脈が非常に重要なんです。
それを実現できるのがRNNと考えてください。
通常のディープラーニングではそれぞれのインプットがそれぞれの中間層に与えられていました。
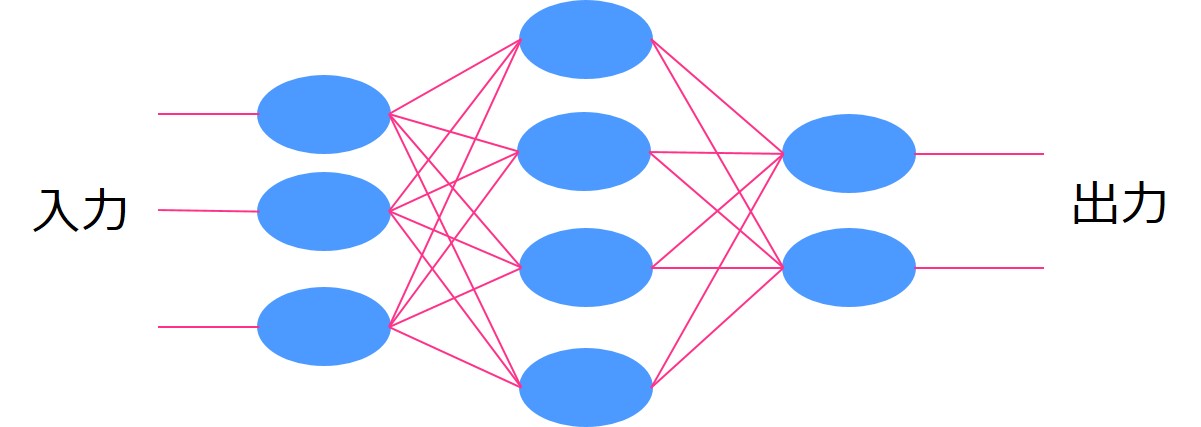
しかし、RNNでは同一の中間層を用いて再帰的にインプットが行われます。
再帰的という部分がReccurentと言われるゆえんです。
こんなイメージ
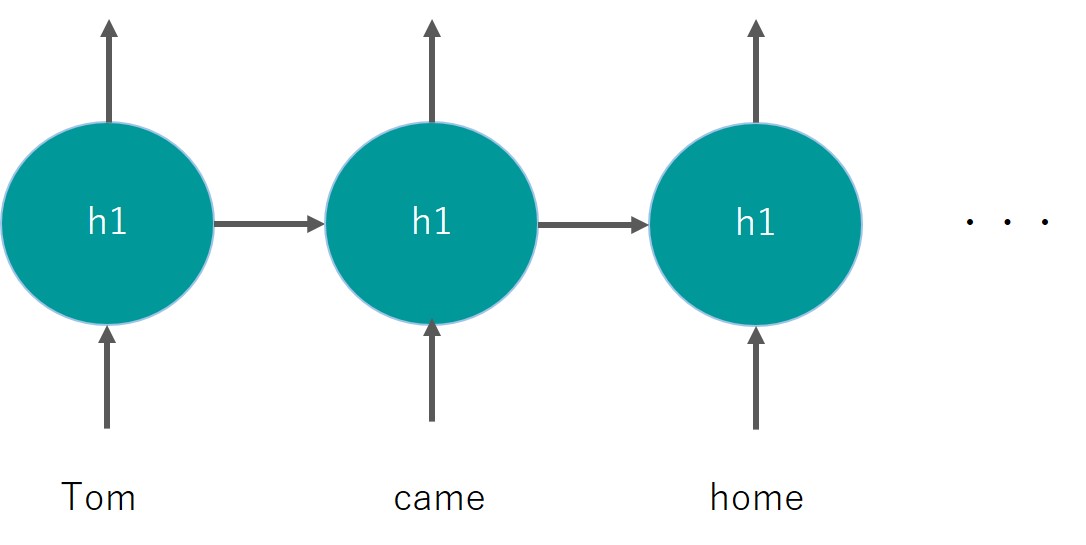
同じレイヤーh1を用いているのがミソです。
これにより前のワードの情報をレイヤに記憶させ後続へとつなぐことができます。
詳しく知りたい場合、「RNN」の論文を読んでみるとよいでしょう!
Time underlies many interesting human behavior. Thus, the question of how to represent time in connectoinist models is very important. In this approach, hidden unit patterns are fed back to themselves; the internal representations which deveolp thus reflect task demands in the context of prior internal states.
リカレントニューラルネットワークは後ろの単語を記憶して後続につないでいくので文脈を読み解くのに便利でしたが、あまりにも長文になると精度が下がってしまう点や時系列での学習になるので並列学習に向かず大規模データを学習するのには多大な時間がかかってしまうという課題がありました。。
それらを解決したのがAttention層なのです!
Attention層とは?
Attention層自体はTransformer登場以前から存在しました(Attention層は2015年に発表)。
RNNのあまりにも長文になると精度が下がってしまう課題を解決するためにAttention層が使われていたのです。
しかし過去から脈々と受け継がれてきた研究成果を引きずり、リカレント層をなくしてAttention層だけで構築するという発想にはならなかった。
そこに終止符を打ったのがTransformer、リカレント層なんていらずAttention層だけでよいのです!
Attention層とは簡単に言うと、「文の中で重要な単語には重み付けをして渡す」というもの。
たとえば先ほどの簡単な文を以下のように長文にしてみましょう!
Tom had a number of incidents before returning to his final destination home. He sent his cat to the hospital because it was injured, found a purse snatcher, caught it, and took it to the police station. When it was all over and he finally reached his destination, and he said “I’m () “.
トムは災難なことに最終目的の家に着く前に猫を助けたり泥棒を捕まえたり色んなことが起きます。そのため、文脈を読み取るのが難しくなっています。
これを通常のRNNで実行しても、そもそも目的地ってどこだっけとなり精度が悪くなる可能性があります。
しかしAttention層を使えば、単語の重要度に重み付けをしてどこに注目すべきかを理解してくれるので「目的地は家だったな。じゃあ”I’m home. “かな!?」それっぽい出力を出してくれる可能性が高くなるわけです。

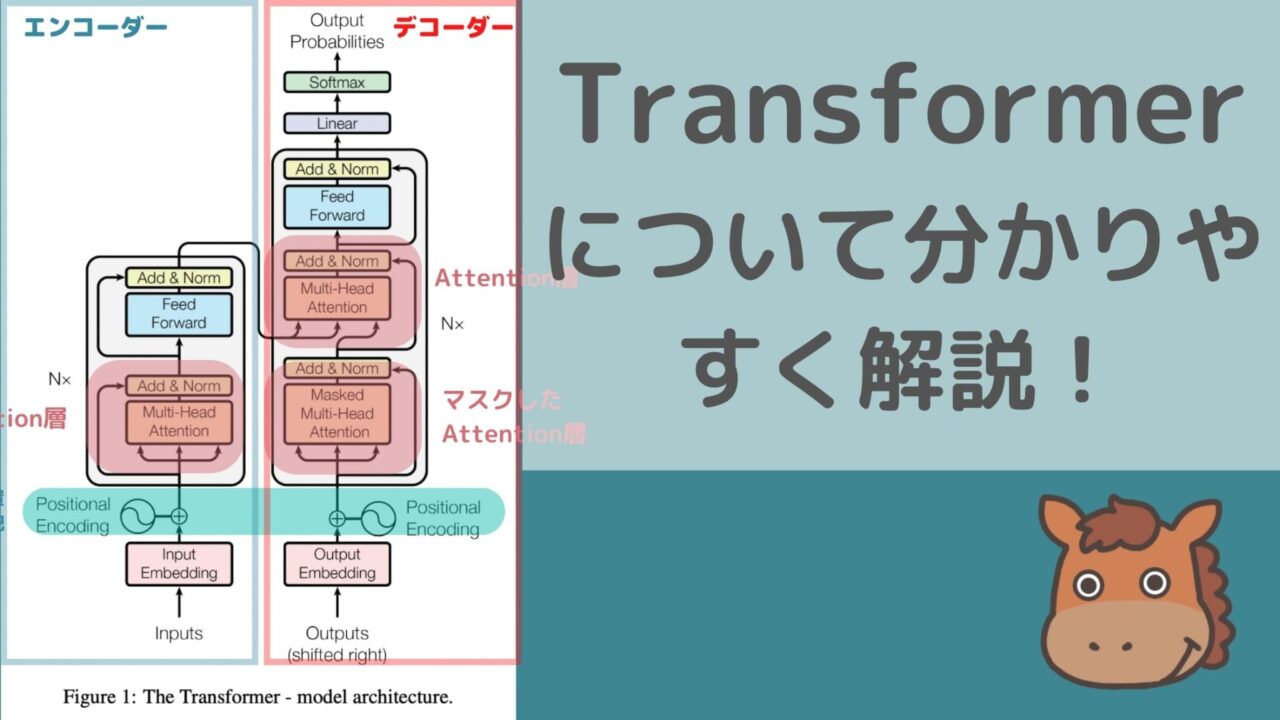
Transoformerの構成とは?
それでは、そんなAttention層を使って構築されたTransformerの構成を論文「Attention Is All You Need」から図を拝借してみてみましょう!
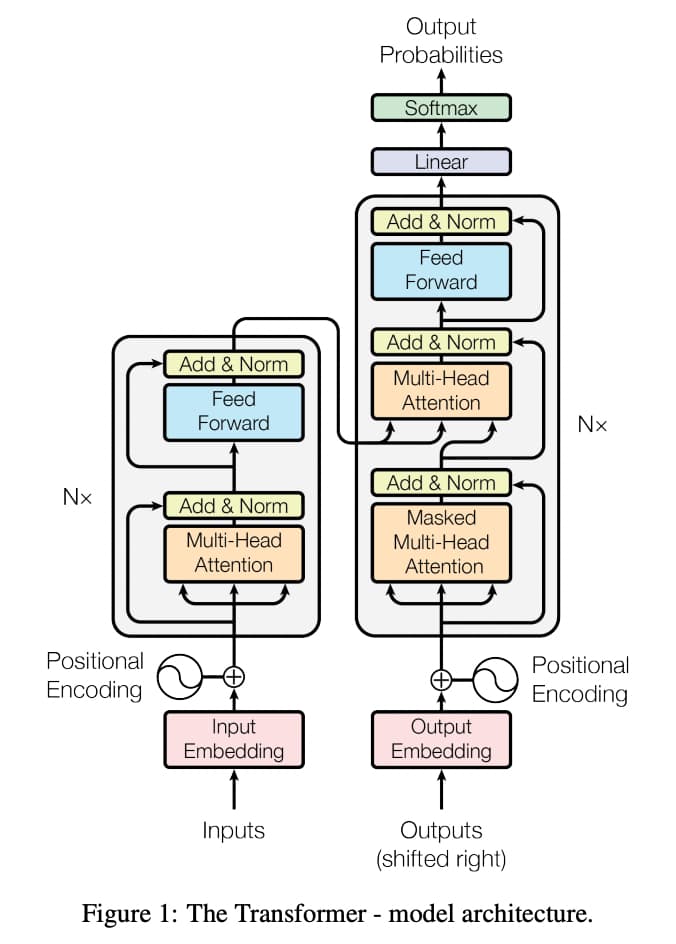
複雑に見えますが、簡単に分解すると以下のようになります。
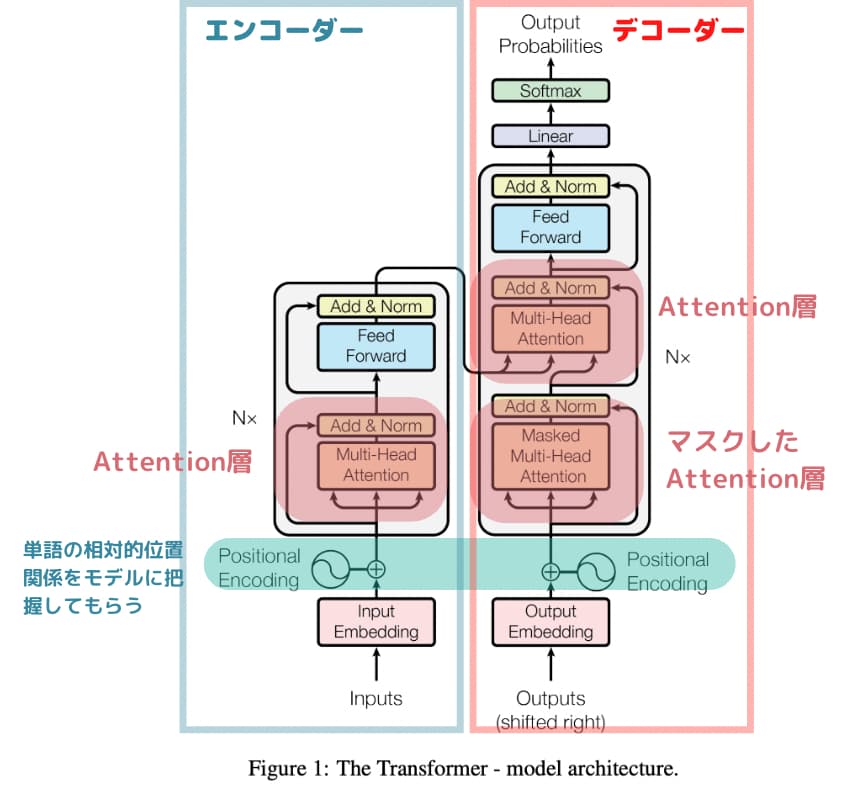
順番に見ていきましょう!
エンコーダー・デコーダー
まず、左側がエンコーダーと右側がデコーダーとなっています。
エンコーダーで処理しやすいベクトル形式にしてからそれをデコーダーでアウトプットに変換しています。
例えば、和英翻訳ではエンコーダーで日本語をベクトル化してそれを元にデコーダーで英語に出力します。
Positional Encoding
Transformerの図を見ると、最初に「Positional Encoding」があります。
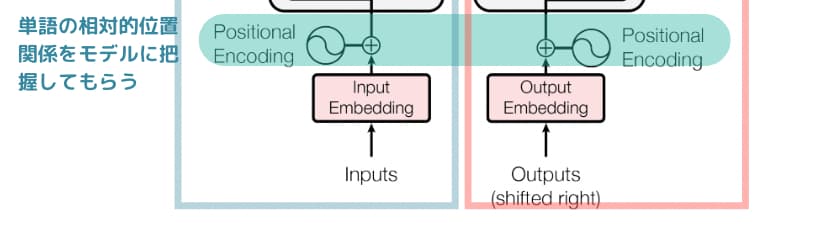
これは単語の位置関係を絶対/相対的な観点でモデルに認識してもらうための処理です。
RNNでは時系列的に学習していくので位置関係が理解できましたが、リカレント層がなくなった構成だと理解できません。
そこで「Positional Encoding」が用いられています。
ザックリ位置関係理解のために使われているのだなと思っておけば大丈夫です。
マスクしたAttention層とAttention層
先ほどAttention層については学びましたが、TransoformerではMulti-Head Attention層というものを使っています。
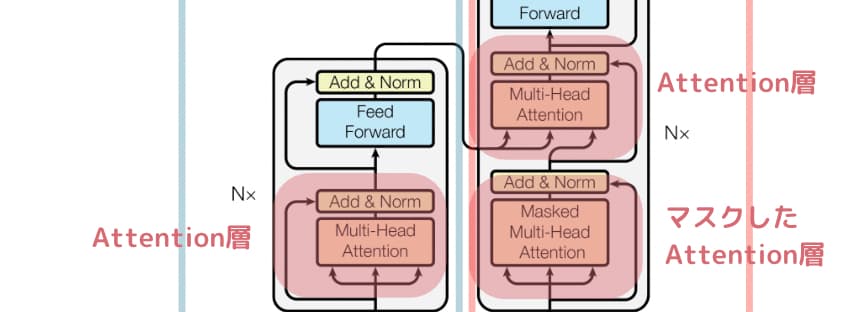
これはザックリ言うと、同時に複数のAttention層の機能を有した層のことです。
Attention層では単一の単語に注目していましたが、Multi-Head Attention層では複数の単語に注目して学習することが可能です。
そしてマスクしたAttention層では、特定の単語をマスクして(隠して)学習します。
ザックリ言うと、
エンコーダーで入力された重み付け単語ベクトルに対して、デコーダーでは特定の単語が隠された状態でそれより前の文章の重み付けベクトルが入力され、これらの情報から隠された単語には何が入りそうか確率値を出力するのが、このTransformerの構成です。
Transformer(トランスフォーマー)の派生モデル
さてザックリTransformerについて理解したところで、派生モデルについても簡単に見ておきましょう!
BERT
BERTはTransformerをベースにしている手法で2018年にGoogleが発表し、2019年に英語版のGoogle検索エンジンに搭載されました。
そもそもTransformerはGoogleが発表した手法であり、それを改良したのがBERTということになります。
BERTの実装については以下の記事でまとめています!

GPT
昨今のAIの進化はめまぐるしく、OpenAIが発表したChatGPTは世界に衝撃を与えました。
2023年3月現在、GPT-4まで発表されており、その精度の高さは衝撃です。
まだ触ったことがないのであればぜひOpenAIのサイトから体感してみましょう!
GPTシリーズの進化の軌跡については以下の記事でまとめていますので是非チェックしてみてください!

DALL・E
同じくOpenAIが開発した画像生成のDALL・Eというモデルも内部でTransformerのアーキテクチャーを用いています。
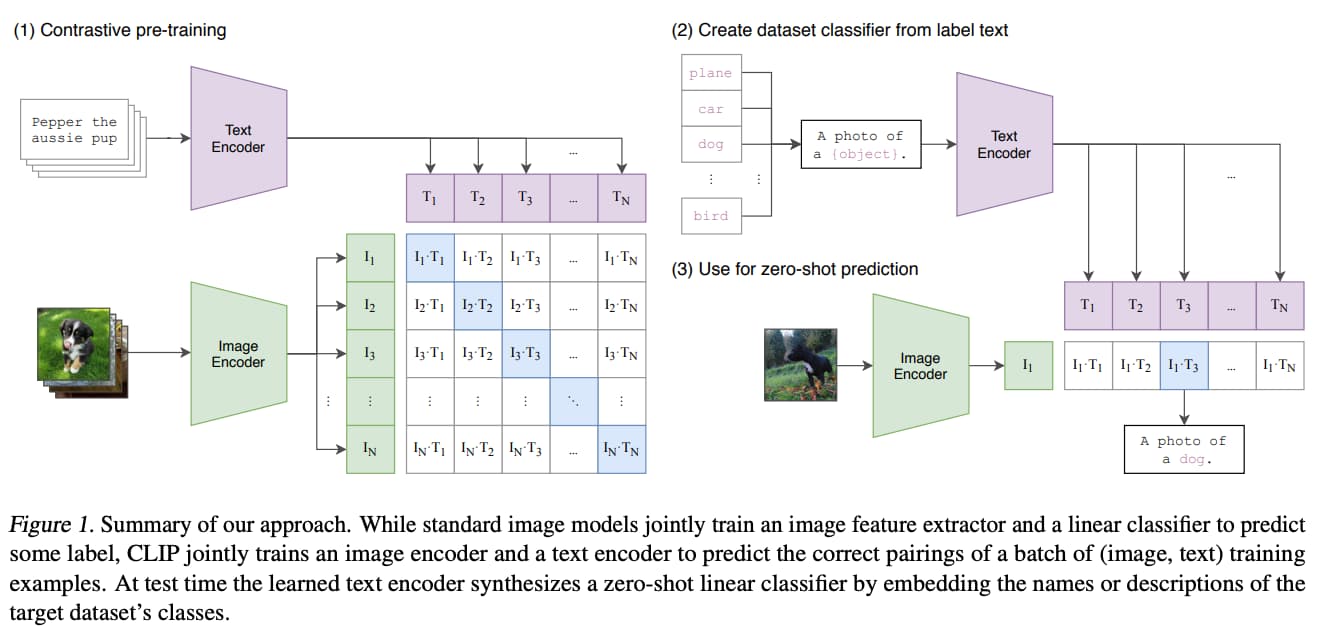 (出典:”Learning Transferable Visual Models From Natural Language Supervision“)
(出典:”Learning Transferable Visual Models From Natural Language Supervision“)
DALL・Eに関しては以下の記事で詳しく解説していますので興味のある方は参考にしてみてください!

Whisper
さらにOpenAIの開発している音声をテキストに変換するWhisperというモデルもTransformerのアーキテクチャーを用いています。
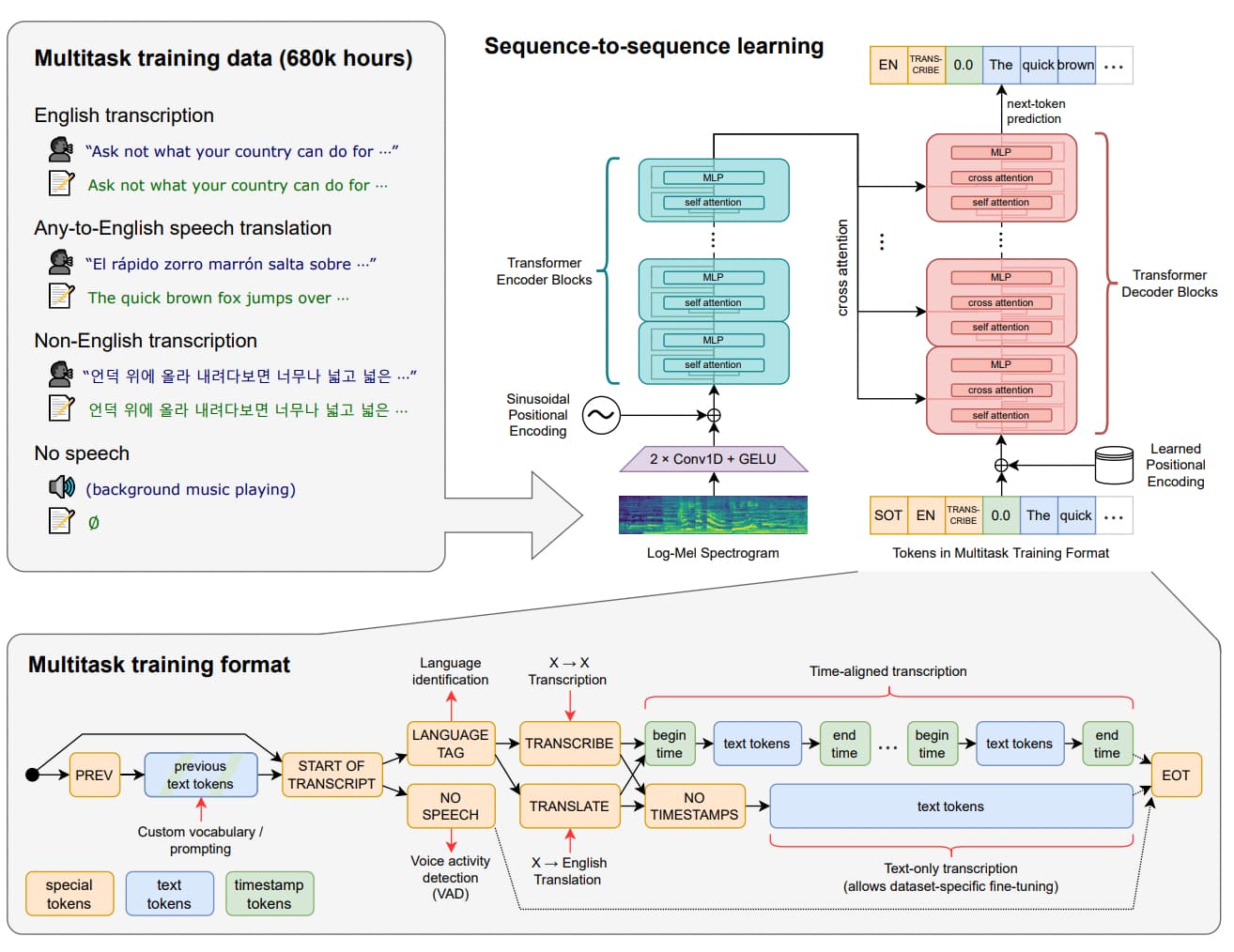 (出典:“Robust Speech Recognition via Large-Scale Weak Supervision”)
(出典:“Robust Speech Recognition via Large-Scale Weak Supervision”)
これだけTransformerは様々なタスクのAI進化のきっかけになったブレークスルーなのです!
Vision Transformer
Vision Transformer(ViT)とは2021年にGoogleから発表された画像認識用のtransformerです。
論文は以下です。
transformerのアーキテクチャを元に自然言語処理ではなく画像認識の領域に応用したのがVision Transformerなのです。
Vision Transformerは以下のようなアーキテクチャになっています。
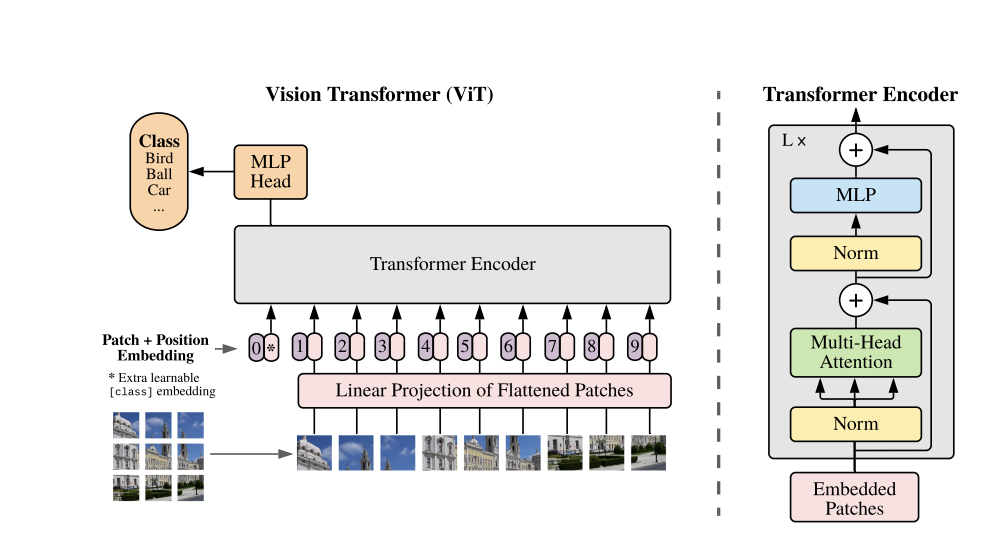
非常にシンプルでほぼTransformerのアーキテクチャと変わりません。
Vision Transformerについて詳しく知りたい方は以下をご覧ください!
Transformer まとめ
ここまでご覧いただきありがとうございました!
本記事でTransformerについて簡単に解説してきましたが、概要を理解していればそこまで深く踏み込まなくても問題ないと思っています。
それよりも、手を動かして天才が生み出した素晴らしいAIの技術を社会実装していくこと!
ここで紹介した技術はPythonのライブラリを使用して実装したり、公開されているAPIを使ってサービスに組み込んだりすることが可能です!

ぜひガンガン手を動かして実装していきましょう!
Transformerをから発展し最近のトレンドになっている様々なAIを利用する方法を知りたい方は当メディアが運営するスタアカの以下のコースを是非チェックしてみてください!
スタアカは業界最安級のAIデータサイエンススクールです。

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
・生成系AIの基礎や使い方を学ぶ
AIデータサイエンスを学んで市場価値の高い人材になりましょう!
データサイエンスやAIの勉強方法は以下の記事でまとめています。


 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















