
【サンプルコード付き】画像認識をPython×機械学習で実装していこう!


こんにちは!
消費財メーカーでデータ分析&デジタルマーケのお仕事をしているウマたん(@statistics1012)です。
ディープラーニングの登場で画像認識の世界には大きなブレイクスルーがおきました。

この記事では画像認識について、Pythonでの実装をおこないつつ簡単に解説していきます!
目次
画像認識の基礎をPython×OpenCVで理解
まずは、画像認識の領域の基礎知識について見ていきましょう!
画像認識の領域で非常によく使われるライブラリにOpenCVというものがあります。
正式名称は「Open Source Computer Vision Library」と言い、コンピュータービジョン・画像認識の領域でよく使われるライブラリです。
Pythonで利用されることが多いですが、Python以外のプログラミング言語でも利用することが可能です。
OpenCVを使って画像を読み取ろう!
まずは、このOpenCVを使って簡単に画像を表示させたり加工したりしていきましょう!
今回題材として使うデータは![]() Nishikaというデータ分析コンペの絵画データです。
Nishikaというデータ分析コンペの絵画データです。
![]() Nishikaのトレーニングコンペ「日本絵画に描かれた人物の顔分類に機械学習で挑戦!」のデータをダウンロードしてください!(※会員登録しないとデータをダウンロードできないので注意してください)
Nishikaのトレーニングコンペ「日本絵画に描かれた人物の顔分類に機械学習で挑戦!」のデータをダウンロードしてください!(※会員登録しないとデータをダウンロードできないので注意してください)
教師データには4238枚の様々な日本絵画の人物が描かれた画像データが入っています。
性別と身分によって8種類のラベルが振られていて、画像からその人物がどのラベルに該当するかを当てるという面白いデータコンペです。
Google colaboratoryを前提に実装していきますが、ローカルのJupyter環境でも問題ないです。
GPUが無料で使えるのでディープラーニングなどを利用する際はGoogle colaboratoryを使うことが多いです。
まずは、必要なライブラリをインポートしておきます。
import matplotlib.pyplot as plt
import glob
import cv2globは特定のファイルパスを抽出してくるのによく使います。
この場合は、4238枚の画像パスを抽出するのに使います。
files = glob.glob("ご自身のパス/*.jpg")このようにglobを使ってあげることで特定のディレクトリ配下にあるjpgファイルのパスを全て抽出してくることができます。

files = sorted(files)
print(files)抽出したファイルパスを表示してみると、ちゃんとパスがリスト形式で格納されていることが分かります。
さて続いてはファイルのパスから画像を読み込む作業!
ここでOpenCVの出番です。
image = cv2.imread(files[0])ファイルパスの中で最初のパスの画像情報をOpenCVを使って抽出してあげます。
そうすると以下のように配列形式で画像の情報が得られます。
array([[[ 83, 109, 109], [ 82, 108, 108], [ 85, 109, 107], …, [100, 141, 104], [100, 143, 106], [100, 144, 105]],・・・
この画像を表示させてみましょう!
plt.imshow(image)以下のように表示されたと思います。
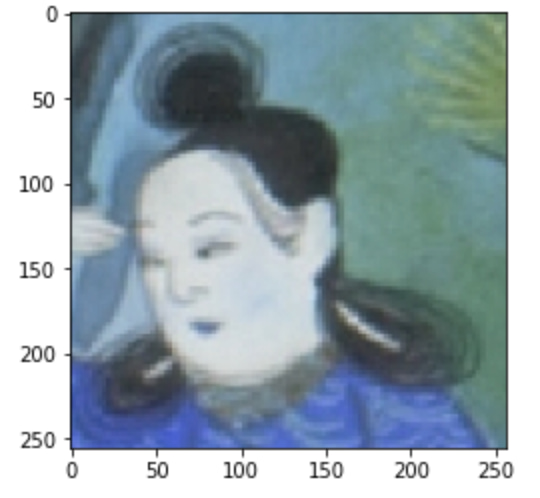
さて改めて先程の画像情報がどんな形になっているか見てみましょう!
image.shape(256, 256, 3)
これは256×256のピクセルの面がRGB(赤緑青)の3次元で重なっていることを表します。
通常、どんな画像もこのようにRGBの3次元で色を重ねて様々なカラーを表現しているのです。
そしてそれぞれのRGBの画素値が0~255で表現されます。
それが先程の配列で表示された各要素になります。
array([[[ 83, 109, 109], [ 82, 108, 108], [ 85, 109, 107], …, [100, 141, 104], [100, 143, 106], [100, 144, 105]],・・・
この時、[R255, G0, B0]であれば完全な赤になります。
それぞれRGBの3次元が重なったピクセルの集合体が画像となるのです。
OpenCVで画像を加工してみよう!
それでは先程表示した画像をOpenCVを使って加工してみましょう!
実は通常は画像はRGBの順番で重ね合わされるのですが、OpenCVで読み込んだ場合はBGRの順番で格納します。
そのため、実際の画像と色合いが変わってしまうのです。
そこで、Matplotlibで描画する前にBGRをRGBの順番に変換してあげる必要があるのです。
image = cv2.imread(files[0])
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(image_gray)このように変換してあげると・・・
以下のように先程の画像よりも日本絵画っぽくなったことが分かります。
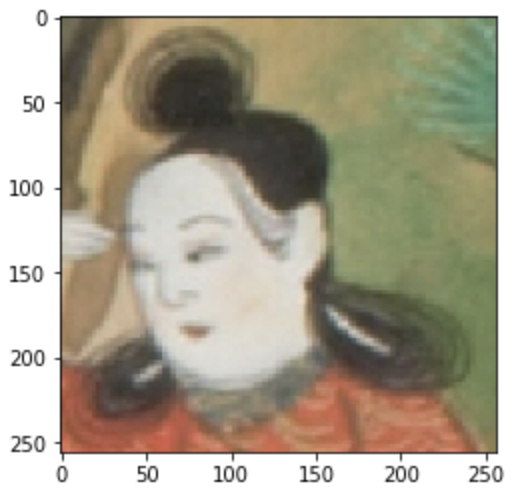
続いて画像のトリミングをおこなってみましょうー!
以下のように画像の要素を一部抽出してあげるだけで顔だけをトリミングして表示することができます。
mage_gray2 = image_gray[50 : 200, 40: 160]
plt.imshow(mage_gray2)
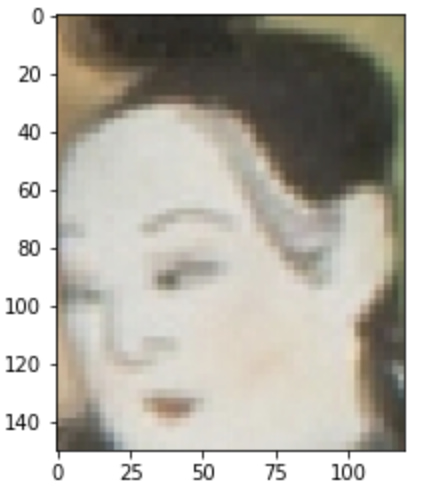
絵画の画像認識をPython×機械学習で実装する

続いて画像認識をPythonで実装していきましょう!
ここまでで画像の表示や画像加工についてOpenCVを使って見てきましたが、ここからは機械学習手法を使って画像認識をおこなってきます。
データの準備
まずは必要なライブラリをインポートします。
import matplotlib.pyplot as plt
import glob
import cv2
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models
from tensorflow.keras.utils import to_categorical
Kerasとはディープラーニングを簡単に実装できるライブラリです。
Kerasを使うと簡単な記述で、いとも簡単にディープラーニングを実装できるのです!
先程と同様にまずは、画像のファイルパスを抽出しそれらを昇順で並び替えます。
files = glob.glob("ご自身のパス/*.jpg")
files = sorted(files)その上でそれぞれのファイルの画像情報をOpenCVで読み込みリストに格納していきます。
file_list = []
for file in files:
file = cv2.imread(file)
file_list.append(file)画像データだけではなくラベルデータも同時に読み込んでおきましょう!
df_label = pd.read_csv("/content/drive/MyDrive/Stabiz/python/data-science/nishika_picture/train.csv")続いて得られた画像の画素値を255で割返して正規化していきます。
file_list = [file.astype(float)/255 for file in file_list] 画像データとラベルデータの塊を学習データと検証データに分けていきます。
train_x, valid_x, train_y, valid_y = train_test_split(file_list, df_label, test_size=0.2)学習データに全てのデータを使ってしまうと過学習という問題が起きてしまうためです。
過学習とは手元の学習データだけにフィッティングしすぎて未知のデータを上手く分類できないモデルを作ってしまうことです。
続いてラベルデータをダミー変数化していきます。
# train_y, valid_y をダミー変数化
train_y = to_categorical(train_y["gender_status"])
valid_y = to_categorical(valid_y["gender_status"])続いて、リスト型になっている画像データを配列型に直してあげます。
train_x = np.array(train_x)
valid_x = np.array(valid_x)ディープラーニングのモデル定義
ここからディープラーニングの層を作っていきます。
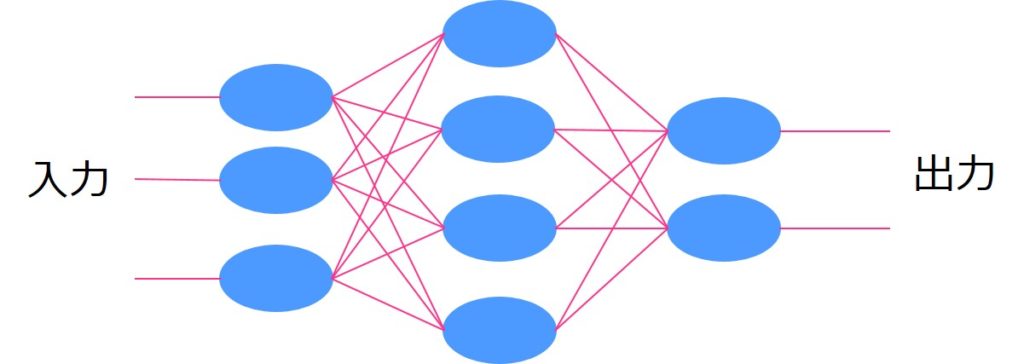
ディープラーニングでは入力データに対して出力データを返すためにいくつかの層を設けて重み付けを調整し最適な出力結果を出していくんです。
この層には様々なものがあるのですが、Kerasでは簡単に層構造を記述することが可能です。
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(256, 256, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(8, activation='softmax'))
model = models.Sequential()
層の種類は以下のようになっています。
- Sequential: モデルを生成するためのモジュール
- Conv2d: 2次元畳み込み層のモジュール
- MaxPool2D: 2次元最大プーリング層のモジュール
- Dense: 全結合層のレイヤモジュール
- Activation: 活性化関数モジュール
- Dropout: ドロップアウトモジュール
- Flatten: 入力を平滑化するモジュール
(出典:https://qiita.com/sasayabaku/items/9e376ba8e38efe3bcf79)
Sequentialでモデルを生成し、Conv2dで2次元の畳み込み層を生成します。
この畳込み層が画像認識において非常に協力な効果を発揮します。
通常機械学習モデルに組み込む時は、それぞれの画像の次元を1次元に落として特徴量としてインプットしますがそうするとどうしても位置関係などの重要な情報が損失してしまいます。
畳み込み層を使うことで2次元データの画像のまま特徴量としてインプットして精度の高い画像認識モデルを作成することが可能です。
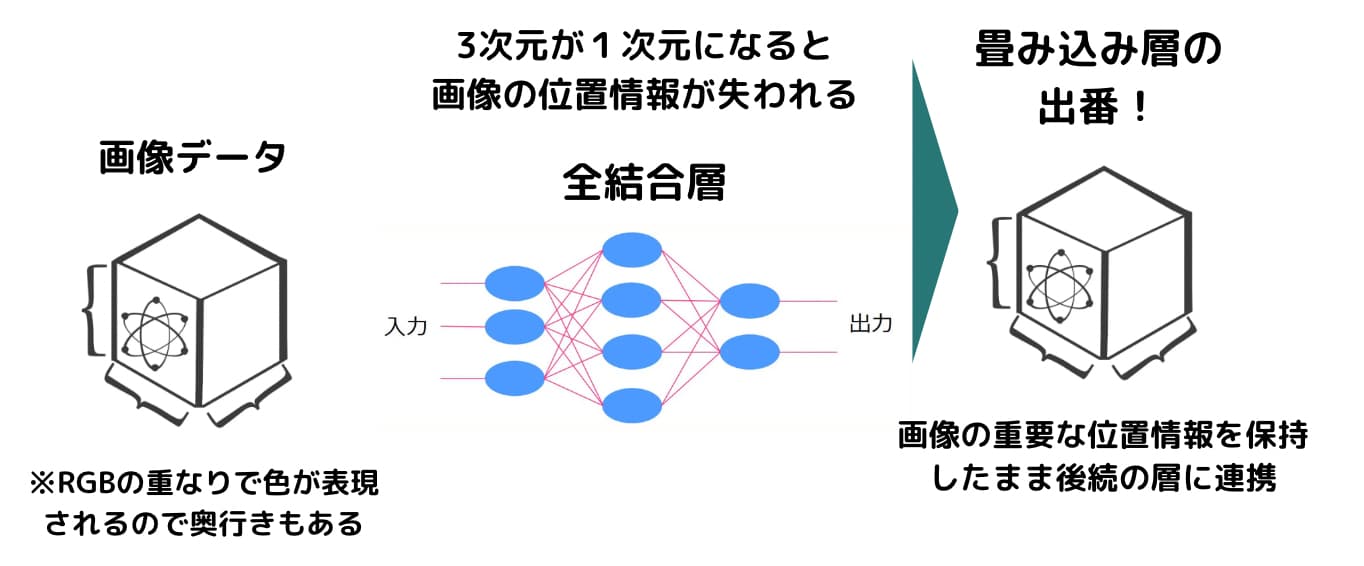
畳み込み層を使う場合は出力する前にFlatternでデータを平滑化し1次元に変換します。
モデル構築し画像認識
さて最後にKerasで定義した層に対して画像認識モデルを構築していきます。
# モデルを構築
model.compile(optimizer=tf.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy'])
# Early stoppingを適用してフィッティング
log = model.fit(train_x, train_y, epochs=100, batch_size=10, verbose=True,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0, patience=10,
verbose=1)],
validation_data=(valid_x, valid_y))これで簡単にモデルを構築することができました。
以下が全コードです。
ぜひ層構造を変えてみて色々試してみてください!
おまけ:文字の画像認識をPythonで実装する

さて続いては文字の画像認識に取り組んでみましょう!
先程は絵画だったのですが、文字の画像認識も出来ます。
画像認識タスクのチュートリアルによく用いられるMnistという手書きの画像データを使っていきます。
MnistはMixed National Institute of Standards and Technology databaseの略で、手書き数字画像60,000枚とテスト画像10,000枚を集めた、画像データセット。
0~9の手書き数字が教師ラベルとして各画像に与えられています。
1つ1つの画像は、文字画像をタテヨコ28×28のピクセルに分け、1つのピクセルあたり0~255の数値で白黒のスケールを表します。
先程はRGBの3次元だったのですが、Mnistのデータは白黒スケールの1次元になります。
以下のように実装していきます。
基本的な流れは先程と変わりません。
データを学習データと検証データに分けて、画素値を正規化してあげて、その上でKerasでモデル構築をおこなっていきます。
この手書き文字が28×28×1のデータなので、畳み込み層へのインプットの際に以下のようになっていることに注意しましょう!
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))また最後の出力層では、0~9の10種類の文字なので以下のように出力カテゴリが10になっていることに注意しましょう!
model.add(layers.Dense(10, activation='softmax'))
画像認識をPythonで実装 まとめ
ここまでで画像認識をPythonで実装しながら簡単に解説してきました!
ここで取り上げた内容は本当に一部の情報で、まだまだ画像認識の世界は非常に深いです。
ぜひご自身で色々調べてみてくださいね!

Pythonの勉強法やデータサイエンティストへの勉強法については以下の記事で解説していますのでぜひチェックしてみてください!


 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















