
【5分で分かる】Jupyter notebookの使い方!インストール方法からPython基礎構文


Pythonは無料で使えるオープンソースの言語である他、様々なライブラリを利用することでデータサイエンス分野や、アプリ開発やゲーム開発など様々な分野で使用することのできる言語です。
特にPythonといえばデータ分析というイメージが強く、機械学習導入やデータサイエンス分野において非常に強力なプログラミング言語になります。
データ分析に特化したSASやStataなどの言語は高品質で使いやすいですが、高額な利用料がかかってしまうケースが多く、個人や中小企業では導入しにくいというデメリットがあるんです。
今回はそんなPythonの使い方をインストールの方法、そして簡単な分析も併せて紹介していきます!
目次
Pythonを活用するメリット

まずはPythonを活用するメリットについて見ていきましょう!
構文が簡単で初学者でも学習しやすい
Pythonはプログラミング言語の中でも比較的に構文が簡単だと言われています。
そのため、初めてPythonを学ぶようなプログラミング初学者の人でもPythonの操作をすぐに学ぶことができます。
特にデータ分析によく使われるプログラミング言語であるRと比較するとかなり簡単な構文であることがわかります。
また無料で使えるオープンソースの言語であるため、お金をかけずに学習することが可能です。

豊富な公式ライブラリや外部ライブラリを利用することができる
Pythonでは、数多くにライブラリを利用することができます。
このライブラリにはデータ分析に特化したライブラリや機械学習のライブラリなど、データサイエンス領域で役立つライブラリが数多くあります。
例えば、Pandas、StatsModels、NumPy、SciPy、Scikit-Learn、Matplotlib、Seabornなどがデータサイエンスの分野でよく使われているライブラリとなります。
Pythonを利用している人が多い
PythonはGoogleなどの大企業でも注目されている言語であるため、世界中に数多くの利用者がいます。
Pythonをしようしていて何か分からないことができたときに、インターネットで検索することで解決ができるケースが多いです。
プログラミング学習者向けの掲示板サイトを利用することで、他のユーザーが質問に対する回答を提案してくれることもあります。

データの視覚化に優れている
Pythonではデータなどの視覚化が比較的簡単にできるようになっています。
MatplotlibやSeabornのようなビジュアライゼーションのパッケージでは、基本的なチャートの作成、グラフィカルプロットを簡単にしてくれます。
地図上へのプロットやアニメーションを伴ったグラフなども簡単に実行することもできます。


Pythonは機械学習でも使用できる
機械学習はデータから最大限の価値を引き出すことができるため、近年注目されている手法の1つです。
Pythonでは、機械学習のライブラリを使用することで簡単に実行が可能になります。

Python(Jupyter Notebook)のインストール方法

今回はデータ分析でよく使われるPythonの開発環境であるJupyter notebook のインストールの方法を紹介します。
※現在はJupyter labというJupyter notebookの進化版が一般的になりつつあります
Jupyter notebookとはブラウザ上でインタラクティブにPythonのプログラムを実行するためのものです。
Pythonの他にもJulia、R、Ruby、Haskell、Scala、node.js、Go、Luaなどの言語にも対応しています。
Jupyter notebookを立ち上げるとブラウザから上の画像のような操作画面を開くことができます。
セル毎にプログラムを記述していき、実行すると結果はセルのすぐ下に表示されます。
セル内には任意の長さのプログラムをかけますし、自由に改行をすることも可能です。
一度実行したものを後から変更することも可能です。
今回はWindows環境でのインストール方法を紹介していきます。
Jupyter notebookのみをインストールする方法
まずは、Jupter notebookのみをインストールする方法を見ていきます!
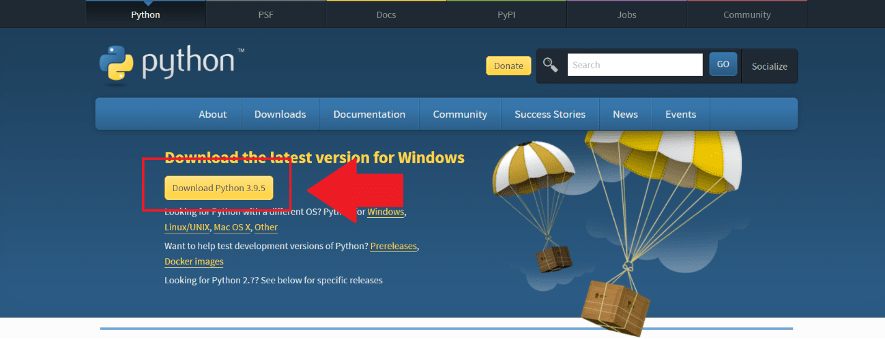
1.Pythonのダウンロードページにアクセスする
Pythonのダウンロードページに行き、「Download Python3.9.5」をクリックすると自動的にダウンロードが始まります。
2. ダウンロードしたインストーラーを開いて、Pythonをインストールする
インストーラーを開くとこのような画面になるので、Install Nowをクリックします。
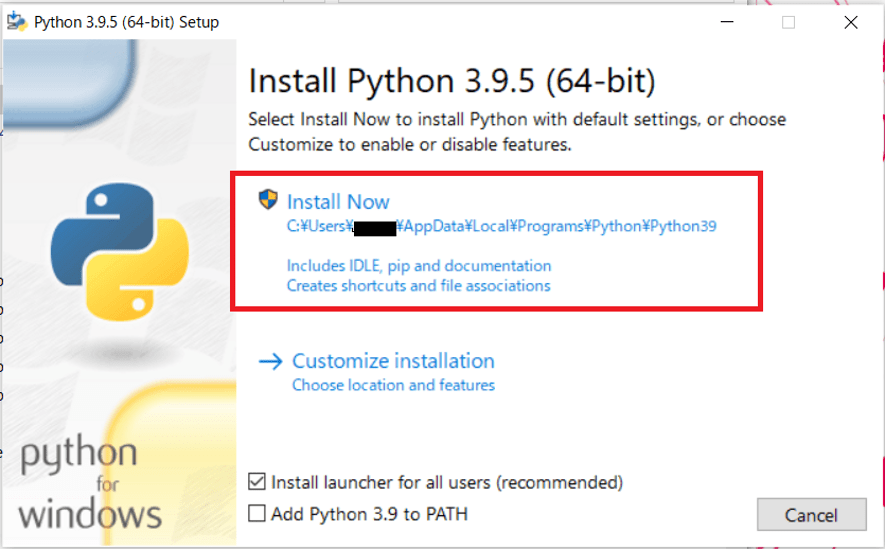
特にこだわりがなければ、「Add Python 3.9 to PATH」にチェックを入れておくこともおススメします。
インストールが終了するまで、待ちます。
インストールが終わったらクローズを閉じて終わりです。
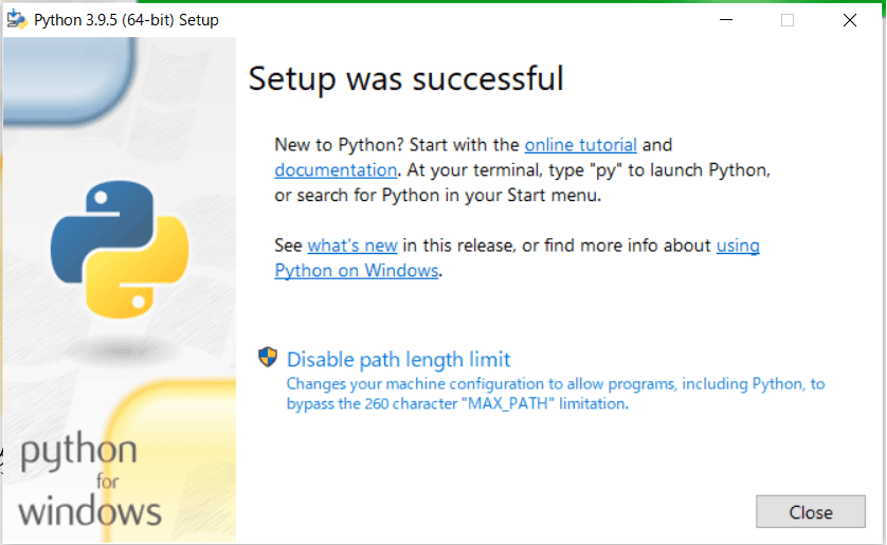
この状態でも、コマンドプロンプトからPythonを利用することができるので、簡単なPythonコードだけ使いたい場合はこのままPythonを利用しても良いでしょう。
3.Windowsでコマンドプロンプトを開いて、pip のアップグレードを行う
コマンドプロンプトで、
pip install --upgrade pip
と入力して実行します。
今回は表示されていませんが、pipをアップデートした際に、
「‘pip’は内部コマンドまたは外部コマンド、操作可能なプログラムまたはバッチファイルとして認識されていません。」
と出た場合は以下のコマンドを入力して、pipをPATHに設定します。
python -m pip install --upgrade pip
ここでは既にPathが通っているため、そのことを指摘されています。
4. Jupyter notebookをインストールする
コマンドプロンプトから、
pip install notebook
と実行します。
これでJupyter notebookのインストールは終わりです。
Anacondaを使ってインストールする方法
Python Anacondaは、設定してあるコンパイル済みのPythonソフトウェアの集合体のことです。
Pythonに関連する数多くのソフトを一括でダウンロードすることができ、その中にJupyter notebookも含まれています。
Anacondaをインストールする前にPythonをインストールする必要もありません。
Anacondaを通じてJupyter notebookを利用できるようにする方法を見ていきましょう!
1. Anacondaインストーラーをダウンロードする
Anacondaのサイトにアクセスし、「Get start」をクリックします。
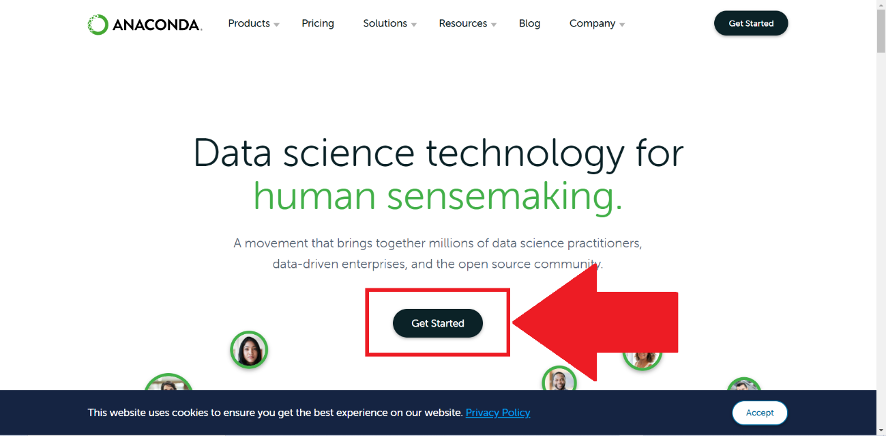
その後、「Download Anaconda Installers」をクリックします。

その後、自分のデバイスにあったインストーラーをダウンロードします。

2. Anacondaインストーラーを起動してインストールする
ダウンロードしたインストーラーをダブルクリックして、起動して「Next」を選択します。
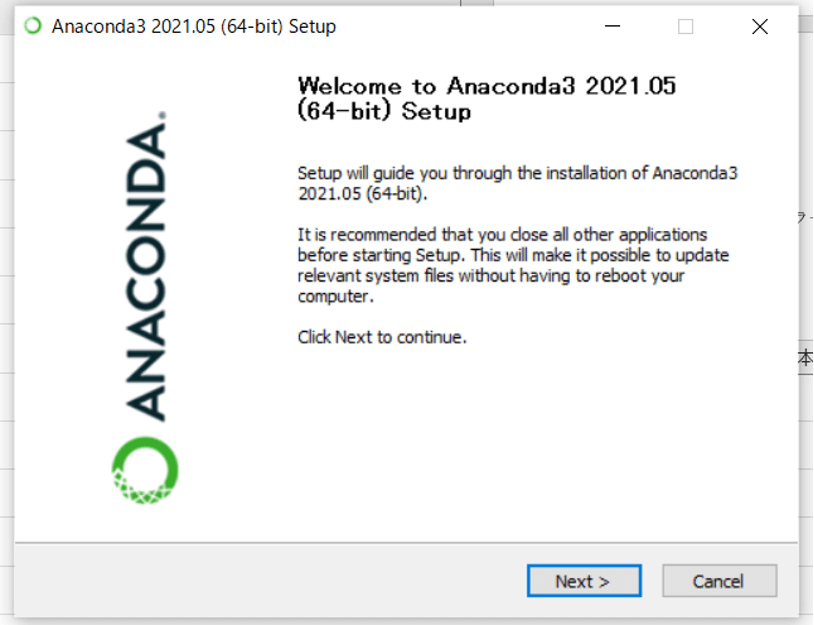
特に問題がなければ、そのまま進んでいくとインストールが終了します。
これで完了です!
Jupyter notebookの使い方
ここでは、Jupyter notebookの使い方について見ていきましょう!
Jupyter notebookは簡単に使うことの出来るインターフェースです。
ここでは、基本的な使い方を紹介していきます。
Jupyter Notebookを起動します。
起動すると、Internet ExploreまたはGoogle ChromeなどでJupyter notebookが立ち上がります。
今回は新しくコードを書いていくので、右上の「New」をクリックします。
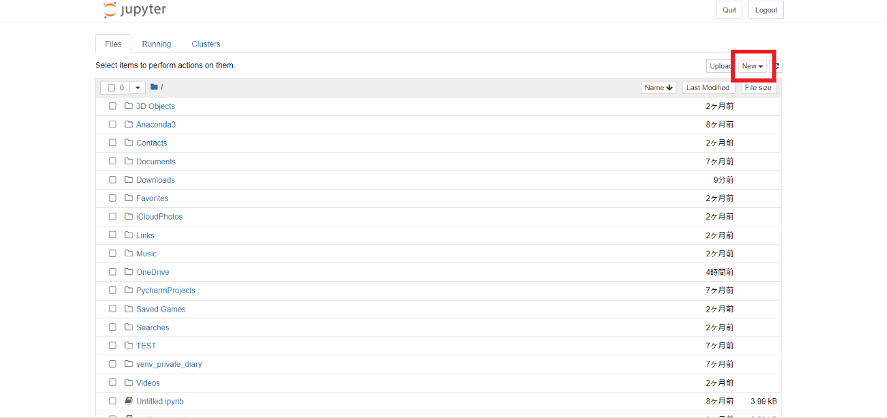
「New」をクリックするとこのような画面が立ち上がります。
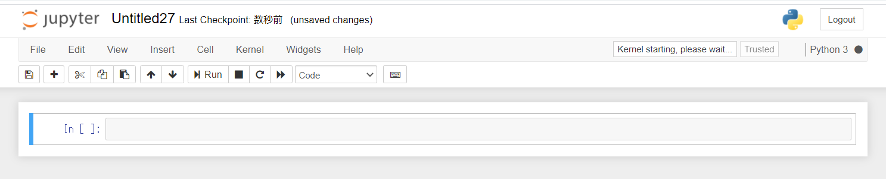
In[ ]: で始まるセルにコードを入力して実行(Enter+Shift)を押すとすぐ下に結果が表示されます。
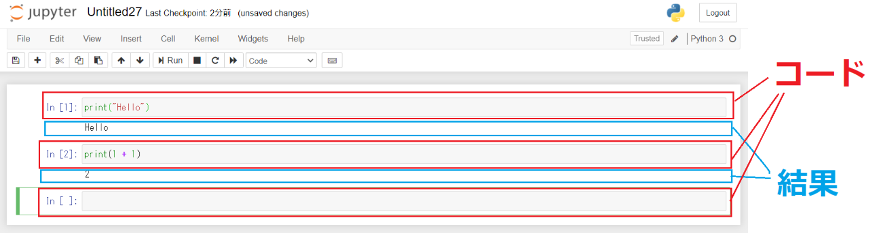
セルに中のコードは一行である必要はなく、何行でも実行することが可能です。
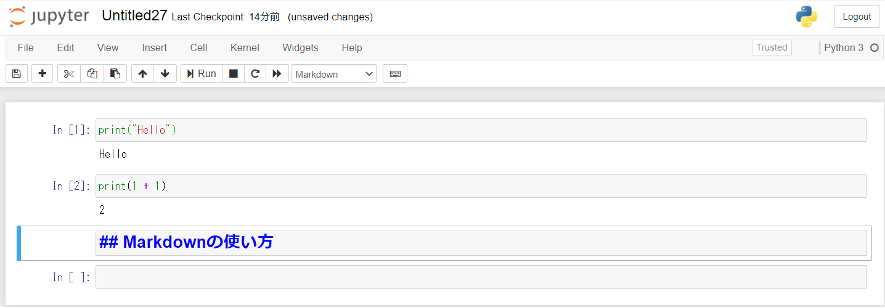
Markdownを利用することで、コメントやタイトルを表示することも可能です。
上のセルの書式を選ぶタブから「Markdown」を選択します。
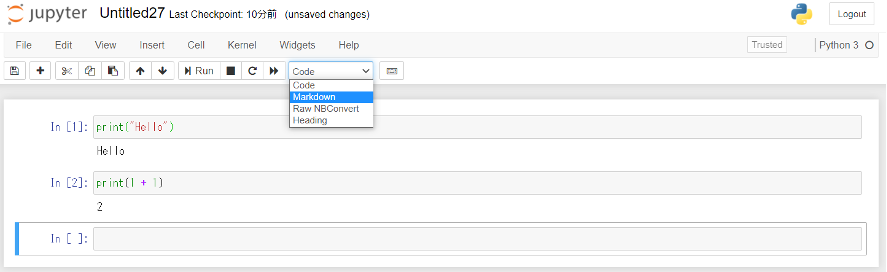
そして、セルに「##Markdownの使い方」と記入すると、「Markdownの使い方」が見出し2として認識されます。
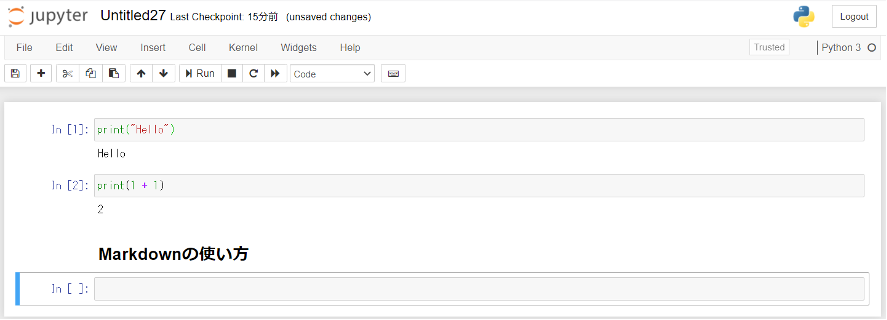
Markdownを使うことで、他の人にNotebookを共有する時など見やすく理解しやすいページを作ることができます。
Jupyter notebook を使うメリット
それではJupyter notebookを利用するメリットについて見ていきましょう!
プログラムの保存・共有・再現が得意
プログラムの保存とは「プログラムと関連するメモや出力をまとめて保存する」ことです。
プログラムの共有は「プログラミングコードやコメント、整形された出力を対応付けた形で共有する」こと。
プログラムの再現は「作成・共有したプログラムと関連する情報から、同じプロセスを再現すること」を指します。
この保存・共有・再現を実現するために、いくつかの特徴的な機能があります。
先ほど紹介したセルの書式を変更するセルコーディングや、アニメーションを伴うようなグラフや図の可視化のなどが特に代表的な機能です。
またデータセットも表形式を扱うライブラリを用いることで、Notebook上に表を出力することができます。
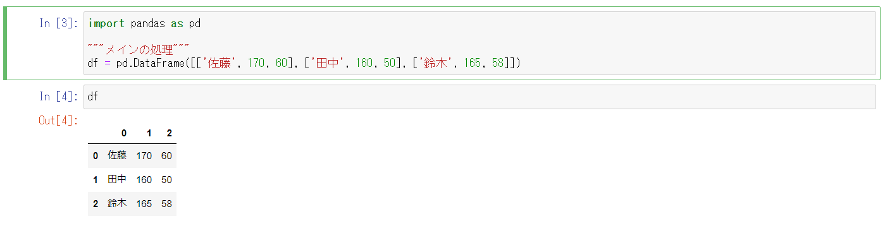
セルの編集と再実行ができる
Jupyter notebook ではセル単位でプログラムやメモを記述し、実行結果をすぐに可視化することができます。
一度実行したセルも途中から自由に追加・編集・再実行することができます。
例えば先ほど表を作成するために書いたコードで名前を変更したいと思った時も簡単に再実行することができます。
【変更前】
【変更後】

名前を簡単に変更することができました。
変更して実行すると、In[ ]:の中の数字が変わります。
このようにセルを簡単に再利用できるため、修正や差し替えを非常に簡単に行うことができます。
Notebookの共有が簡単
作成したNotebookは「File → Download as」から様々なファイル形式で保存することができます。
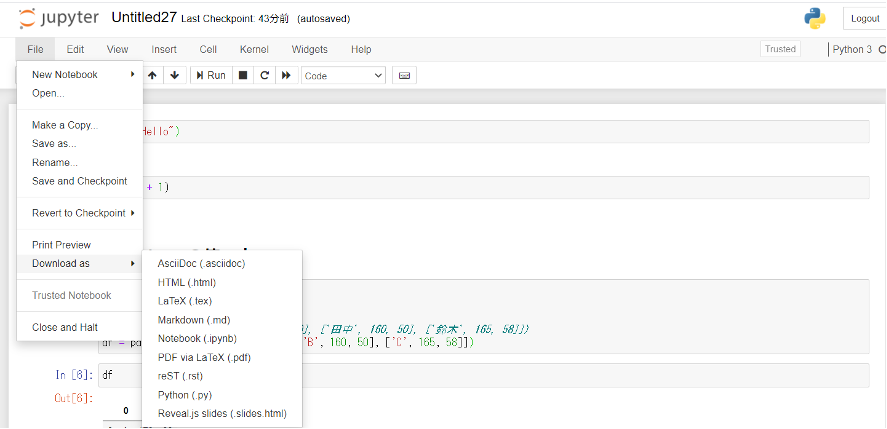
特にNotebook独自の.ipynbという形式は、他の人への共有が便利なため人気があります。
.ipynb形式で保存したNotebookは、Jupyter Notebookの環境があるPCであれば作成した環境以外の環境でも同じプログラムを簡単に再現することが可能です。
.ipynb形式はGithub上でも閲覧することができるため、Jupyter notebook の環境がないユーザーでも、ブラウザ上で簡単に内容を閲覧することができます。
スライドによる共有
ミーテイングやオンライン会議などで複数人に情報を共有する手段としてはパワーポイントによるスライドが一般的です。
Jupyter Notebookでは、プレゼン形式でNotebookを表示することも可能です。
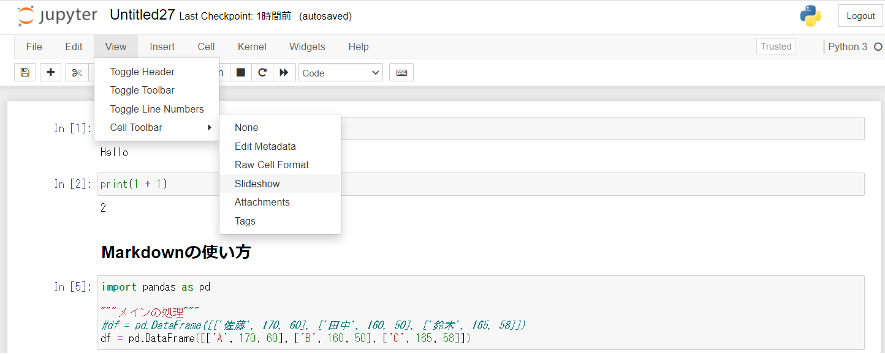
「View > Cell Toolber > Slideshow」からスライドの構成を設定することができます。
Pythonの使い方:データ加工
それではPythonを実行する準備が出来たところで、Jupyter notebook(Jupyter lab)を使ってPythonの使い方について学んでいきましょう!
Pandasのインポート
PythonのPandasというデータ集計や加工に優れたライブラリを用いて実装していきます。
当たり前ですが、Pandasはインポートしないと使えません。
import pandas as pdほぼpdで定義されることがほとんどなので以下pdと定義してpdで呼びます。
データセットをインポート
ここでは実際にデータがあった方が分かりやすいので、Kaggleで有名なタイタニックのデータセットを使用します。
ちなみにpandasには既存のサンプルデータセットは入っていないのですが、seabornというライブラリを使えばサンプルデータセットを読み込むことが可能です。
タイタニックのデータであれば以下のように記述することで読み込みが可能。
import seaborn as sns
df = sns.load_dataset('titanic')これで準備万端!実際にデータを確認してみましょう!
df.head()
ざっとデータ構造を確認する時に使います。
df.head()デフォルトだと最初の5行を表示するようになっています。

数値を入れることでその行分を表示してくれますよー!
df.head(3)df.tail()
逆に下から表示したい時はこっち。
df.tail()
df.shape
データフレームの行×列数を知りたい時にこちらを使います。
df.shape(891, 15)
pd.columns
カラム名を確認したい時はこれ!
pd.columnsIndex([‘survived’, ‘pclass’, ‘sex’, ‘age’, ‘sibsp’, ‘parch’, ‘fare’,
‘embarked’, ‘class’, ‘who’, ‘adult_male’, ‘deck’, ‘embark_town’,
‘alive’, ‘alone’],
dtype=’object’)
df.unique()
ある項目のユニークな値の種類を確認することができます。
df['pclass'].unique()以下のように出力されます。
array([3, 1, 2], dtype=int64)
パッセンジャーズクラス(pclass)は1~3の3つあるということが分かりました。
df.loc[]
df.locは任意の名称を指定して行・列から好きなようにデータを抽出することができます。
df.loc[:3,:'pclass']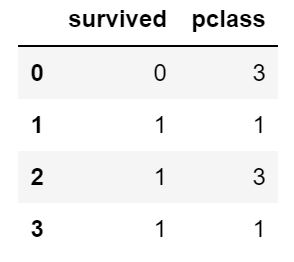
df.iloc[]
一方でdf.iloc[]では、インデックス番号で指定して抽出することができます。
iloc(index-location)です。
df.iloc[:3,:2]df.describe()
簡単に要約統計量を確認したい時はこれ!
df.describe()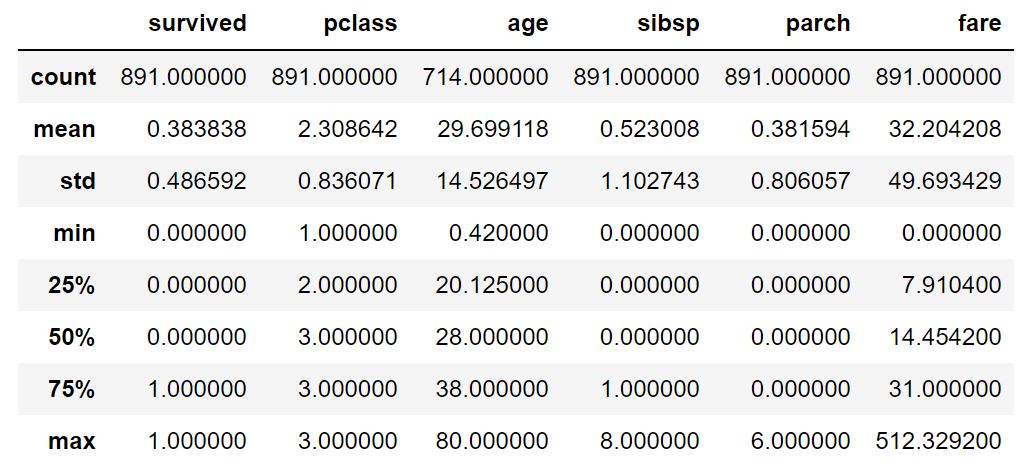
df.value_counts()
出現の回数を測ることができます。
例えばタイタニックのデータに対して以下のように記述すると、
df['survived'].value_counts()このように出力されます。
0 549
1 342
生死ラベルの出現回数が分かります。
df.groupby()
ある項目をキーにして集計することができます。
例えば以下のように記述すると生死でグルーピングした際の年齢の平均が集計できます。
df.groupby('survived')['age'].mean()0 30.626179
1 28.343690
df.sort_values()
ある値をキーにしてデータフレームをソートすることができます。
df.sort_values('age')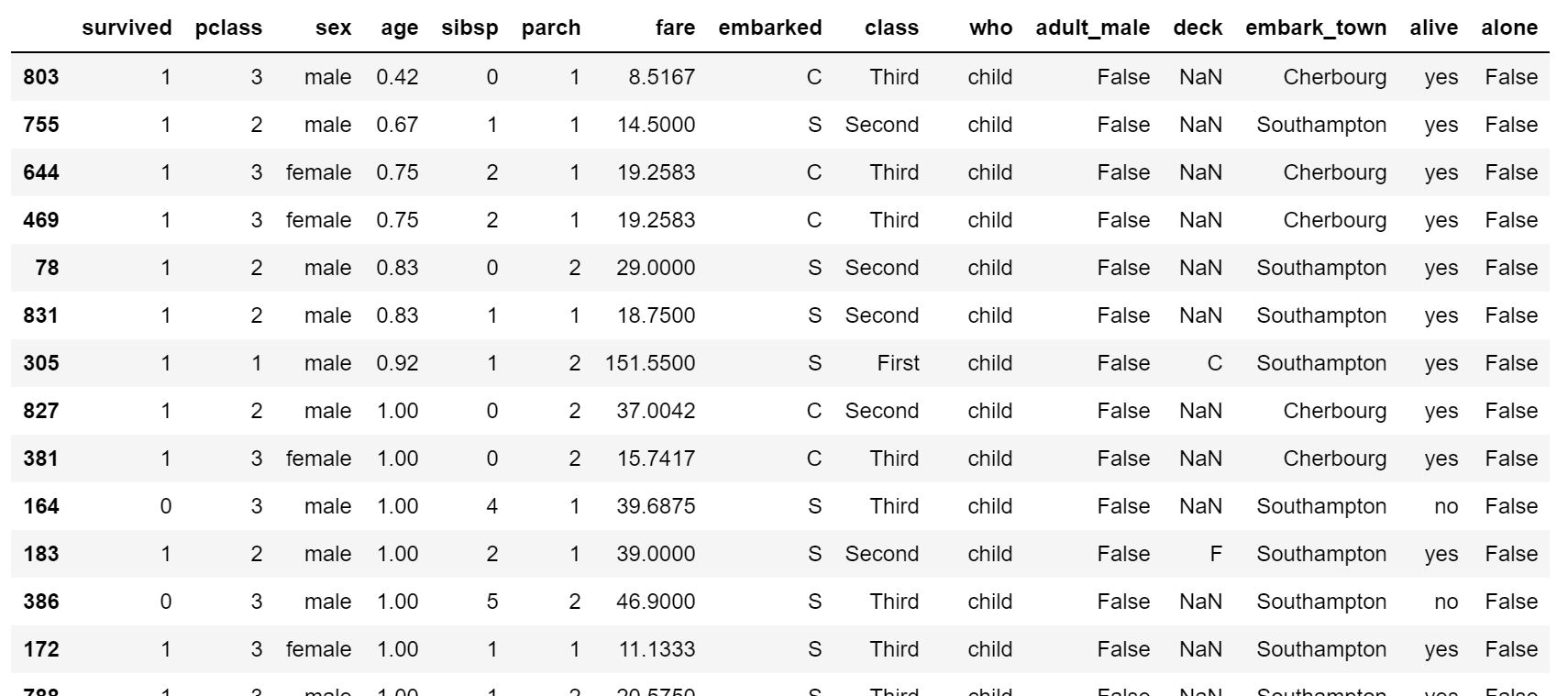
年齢で昇順にソートできているのが分かると思います。
降順にしたい場合は、以下のようにすれば大丈夫です。
df.sort_values('age',ascending=False)df.isnull()
欠損値処理はデータ分析において非常に重要な部分。
欠損値をどのように処理するのかによって明暗が分かれることも多々あります。
まずは、欠損値を確認しましょう!
df.isnull().sum()によって各カラムの欠損値の数を集計することができます。
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
df.dropna()
続いて欠損値を処理する方法について見ていきましょう!
df.dropna()dropnaを使うことで欠損値が1つでも入っている行を削除することができます。
処理後の行数を確認してみると、
df.dropna().shape(182, 15)
182行に減っていることが分かります。
df.fillna()
fillna()を使うことで欠損値を埋めることができます。
df['age'].head(10)0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
5 NaN
6 54.0
7 2.0
8 27.0
9 14.0
Name: age, dtype: float64
年齢の欠損値を埋めてみましょう!
df['age'].fillna(0).head(10)0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
5 0.0
6 54.0
7 2.0
8 27.0
9 14.0
Name: age, dtype: float64
pd.get_dummies()
ダミー変数化とは多クラスのカテゴリーを01ラベルで表す特徴量として展開すること。
例えば以下のようなケースだと、
| カテゴリ |
| A |
| B |
| A |
| C |
| ・・・ |
| A |
| B |
ダミー変数化をすることにより以下のようなデータ構造に変換されます。
| A | B |
| 1 | 0 |
| 0 | 1 |
| 1 | 0 |
| 0 | 0 |
| 1 | 0 |
| 0 | 1 |
この時、Aが0でBが0であればCということが明示的に分かるのでCのカラムは必要ありません。
逆にCのカラムを追加してしまうと変数同士の重複が起き「多重共線性」という問題が生じ推定精度が不安定になります。
pd.get_dummies()を用いることで簡単にダミー変数を生成することができます。
pd.get_dummies(df)
df.corr()
corr()で相関関係を簡単に確認することが可能です。
df.corr()
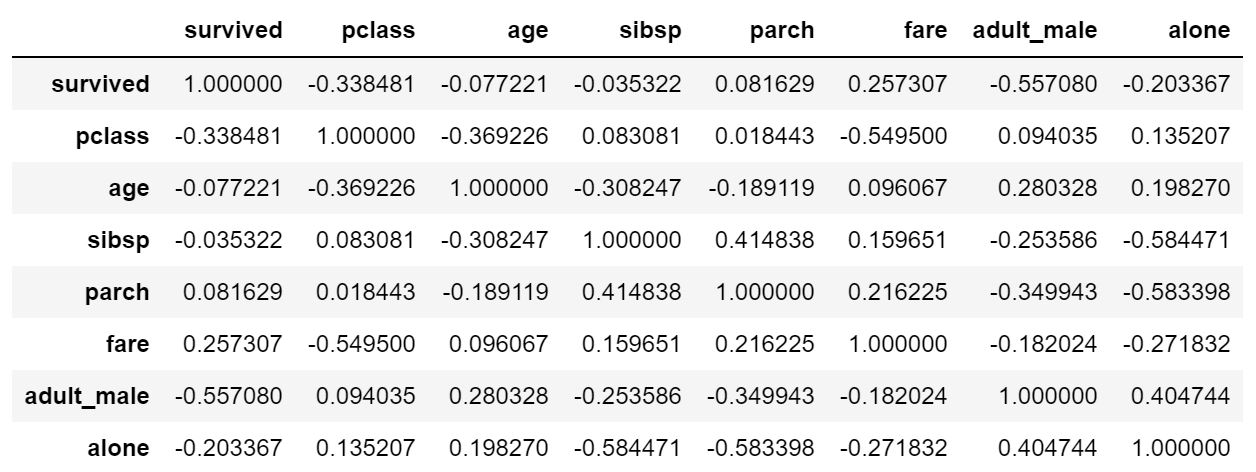
これで一通りのデータ集計や加工ができるようになったはずです!
Pandasについては以下の記事でより詳しく解説していますのでチェックしてみてください!

Pythonの使い方:データ可視化
続いてはデータの可視化をしていきます!
データの可視化に関してはMatplotlibとSeabornというライブラリが非常に有用です。
Matplotlibでヒストグラムを描画してみよう!
まずはヒストグラムを見ていきましょう!
plt.hist(df["fare"], bins=40, range=(0, 100))
plt.show()このように1行記述するだけで以下のようにヒストグラムを描画することができます。
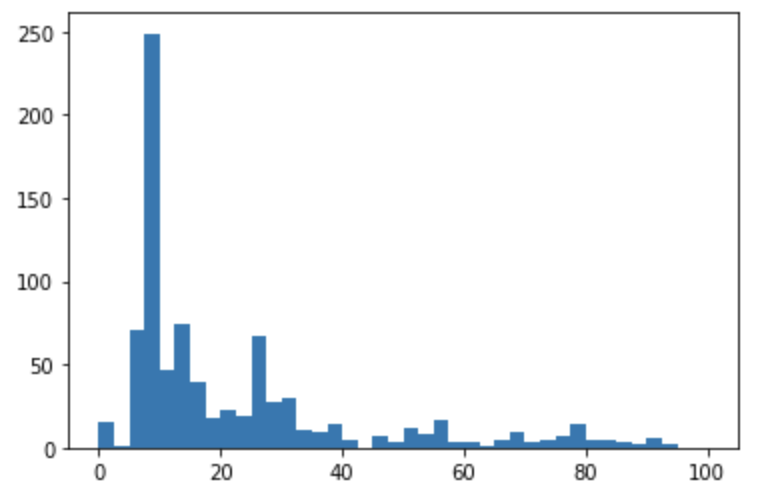
この時、binsで階級の細かさを調整することができます。またrangeでグラフの幅を調整することができます。
またMatplotlibではないのですが以下のように記述することでヒストグラムを描画することが可能で、さらに性別で層別して描画なんてこともできちゃいます。
df["fare"].hist(by=df["sex"])
plt.show()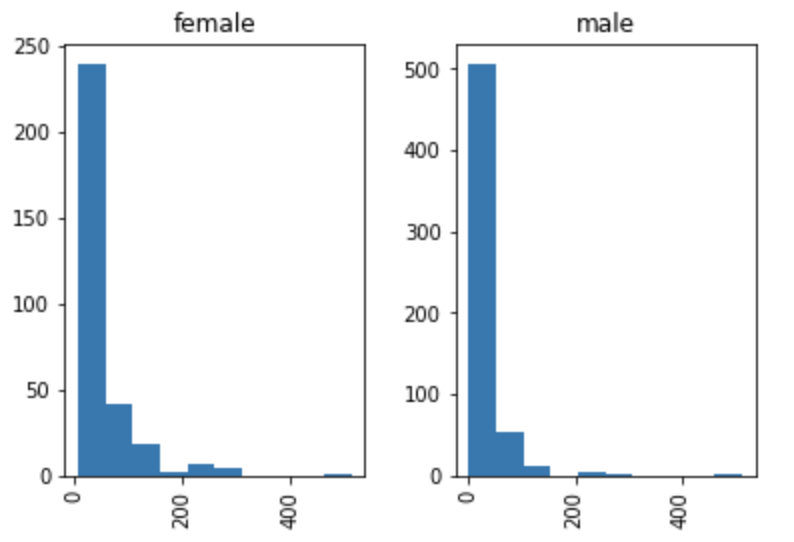
Matplotlibで折れ線グラフを描画してみよう!
続いて通常の折れ線グラフを描画していきましょう!
今回のタイタニックデータは時系列データではないので折れ線グラフは意味がないのですが、練習として描画してみます。
plt.figure(figsize= (20,5))
plt.plot(df["fare"])
plt.title("test")
plt.xlabel("data_index")
plt.ylabel("fare")
plt.show()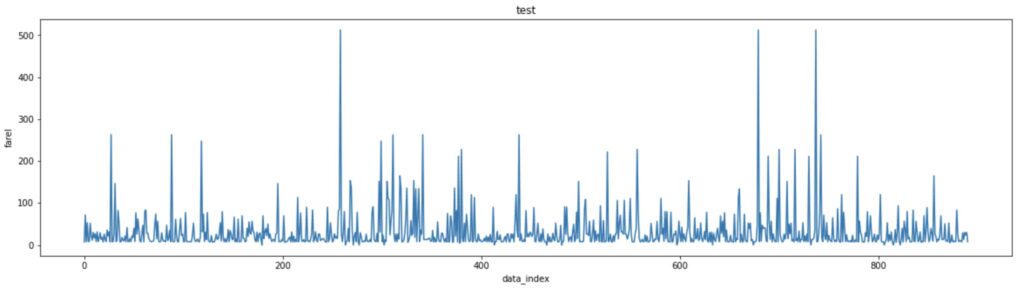
plt.plot(df[“fare”])と1行だけで折れ線グラフを書くことができました。
plt.figure(figsize = (20,5))でグラフの大きさを調整することが可能です。
またタイトルやX軸、そしてY軸も記載することが可能です。
Matplotlibで複数のグラフを描画してみよう!
続いて複数のグラフを描画してみましょう!
複数のグラフを描画する方法はいくつかあるのですが、ここではsubplotsを使います。
fig, axes = plt.subplots(2, 2, figsize=(20,10))このように記述してあげることで、2×2のグラフを描画する箱を作ってくれます。
その箱に対してそれぞれのグラフを描画していくことになります。
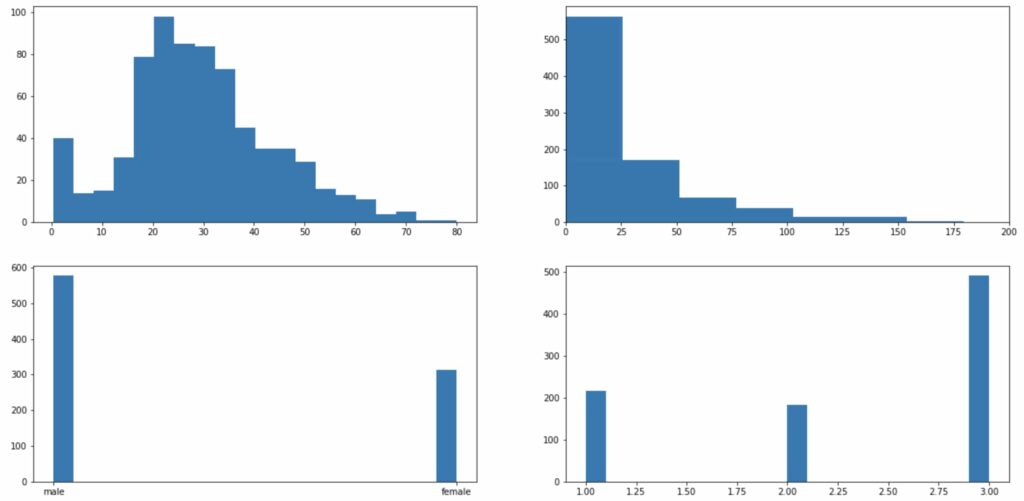
axes[0][0].hist(df["age"], bins=20)
axes[0][1].hist(df["fare"], bins=20)
axes[0][1].set_xlim(0,200)
axes[1][0].hist(df["sex"], bins=20)
axes[1][1].hist(df["pclass"], bins=20)
plt.show()このように記述することでそれぞれの箱にグラフを描画していくことができるんです!
Matplotlibで棒グラフを描画してみよう!
続いてMatplotlibで棒グラフを描画していきましょう!
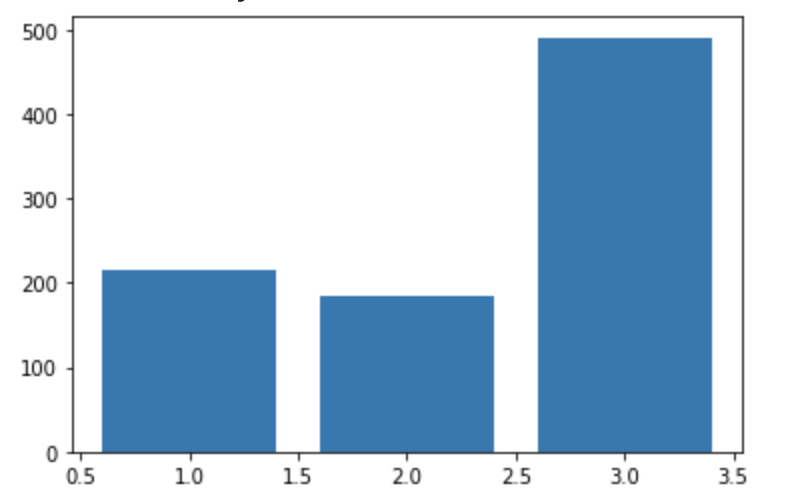
plt.bar(df.groupby("pclass").count().index, df.groupby("pclass").count()["survived"])
plt.show()ちょっと複雑なコードですが、X軸にはpclassの3種類の質的変数を設定していて、Y軸には生き残った乗客の数を設定しています。
すなわちpclass別に生き残った乗客の数に差があるのかを見ているということになります。
Matplotlibで散布図を描画してみよう!
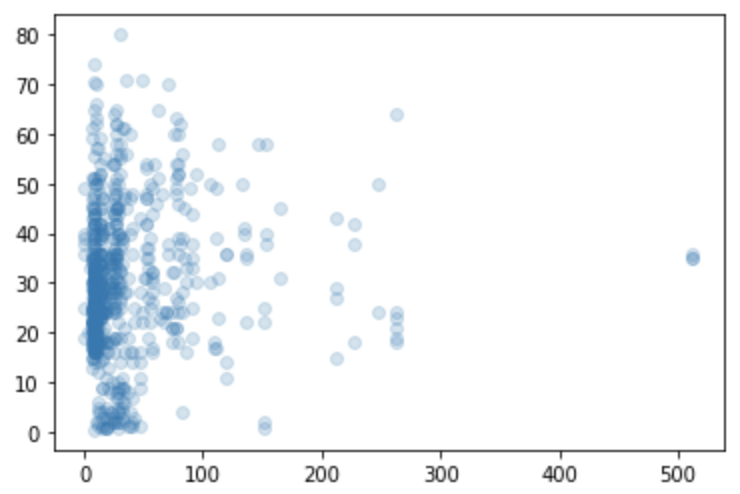
plt.scatter(df["fare"], df["age"], alpha=0.2)
plt.show()散布図を描画するのにはscatterという関数を使います。
これだけで簡単にfareとageの散布図を描画することが可能なんです!
Seabornでヒストグラムを描画
続いてSeabornでのデータ可視化を見ていきましょう!
まずは、Seabornでヒストグラムを描画していきます!
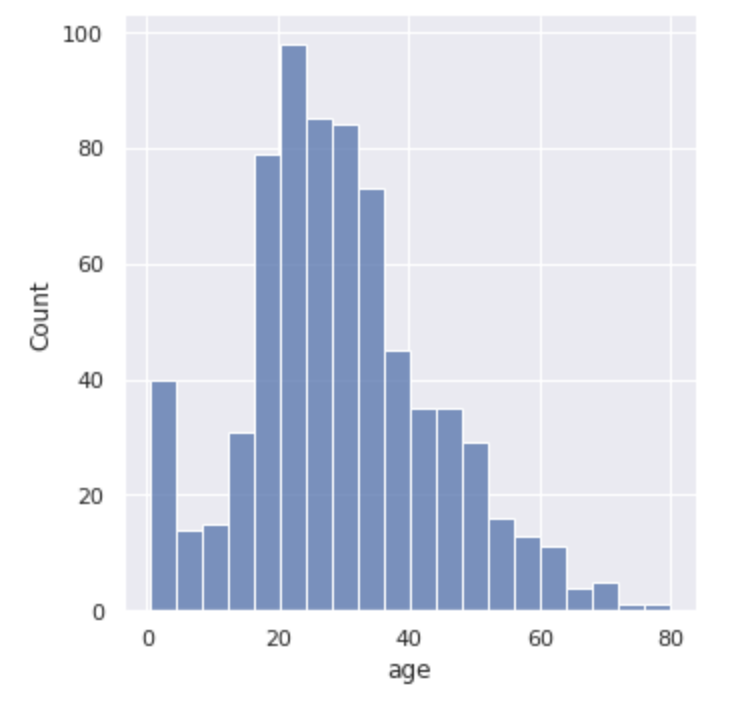
sns.displot(df["age"])
plt.show()このように記述するだけで以下のように綺麗なヒストグラムを描画することが出来ちゃうんです!
Seabornで棒グラフを描画
続いて棒グラフを描画していきます!
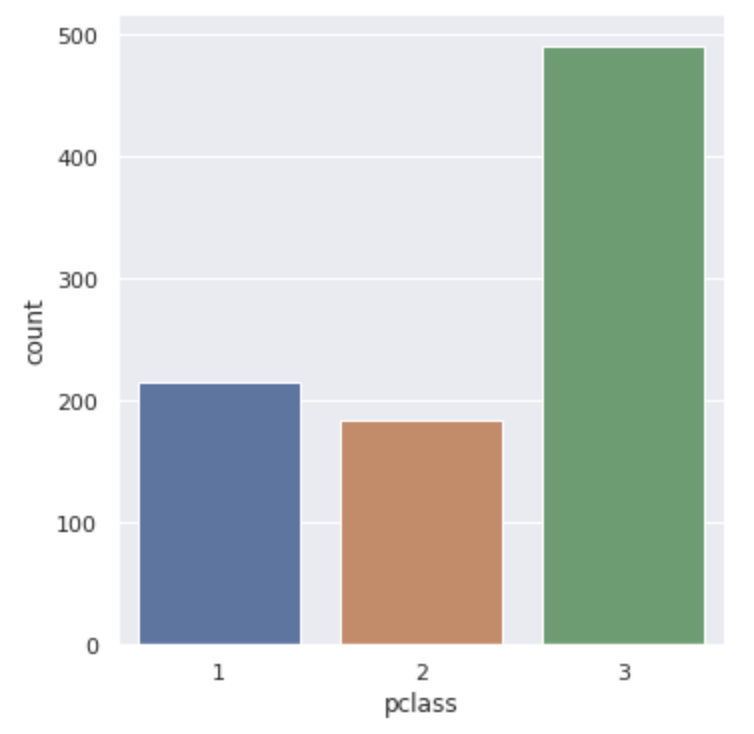
sns.catplot(x="pclass", data=df, kind="count")
# sns.countplot(x="pclass", data=df)
plt.show()pclassという乗船クラス別にどのくらいの乗客がいたのかが分かります。
この時、catplotとやってkindの引数にcountとしてあげてもいいですし、countplotを使ってあげても問題ありません。
以下のように3つのクラス別の集計値が表示されます!
続いてbarplotという棒グラフの作成方法を見ていきます。
sns.barplot(x="survived", y="age", hue="sex", data=df)
sns.catplot(x="survived", y="age", hue="sex", data=df, kind="bar")
plt.show()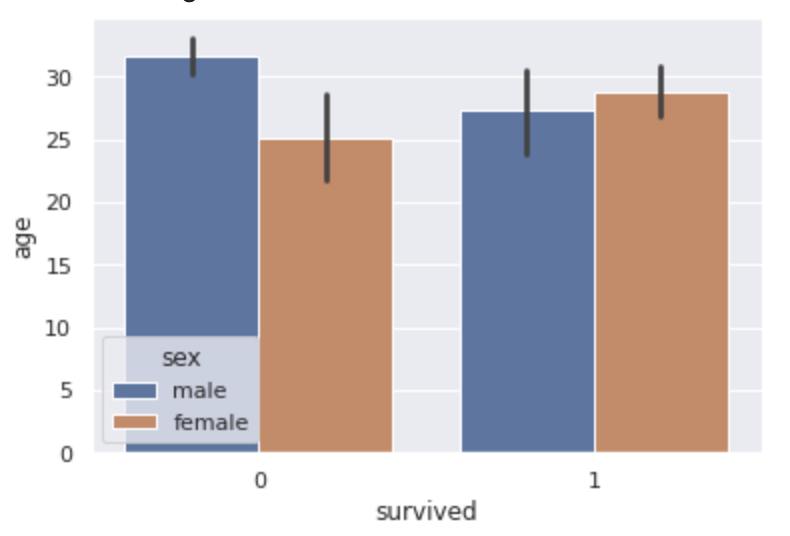
この場合は生死のデータで分けた上で年齢の平均値を棒グラフで算出しています。
さらにそれを性別で層別しています。
黒い線は95%の信頼区間を表しています。
Seabornで箱ひげ図を描画
続いて箱ひげ図を描画していきます!
箱ひげ図とは統計量をざっくり把握することの出来る便利なグラフです。

boxplotとするだけで描画を行うことが出来るんです!
sns.boxplot(x="survived", y="age", hue="sex", data=df)
sns.catplot(x="survived", y="age", hue="sex", data=df, kind="box")
plt.show()ここでは、生死別の性別別の年齢の箱ひげ図を見ていきます!
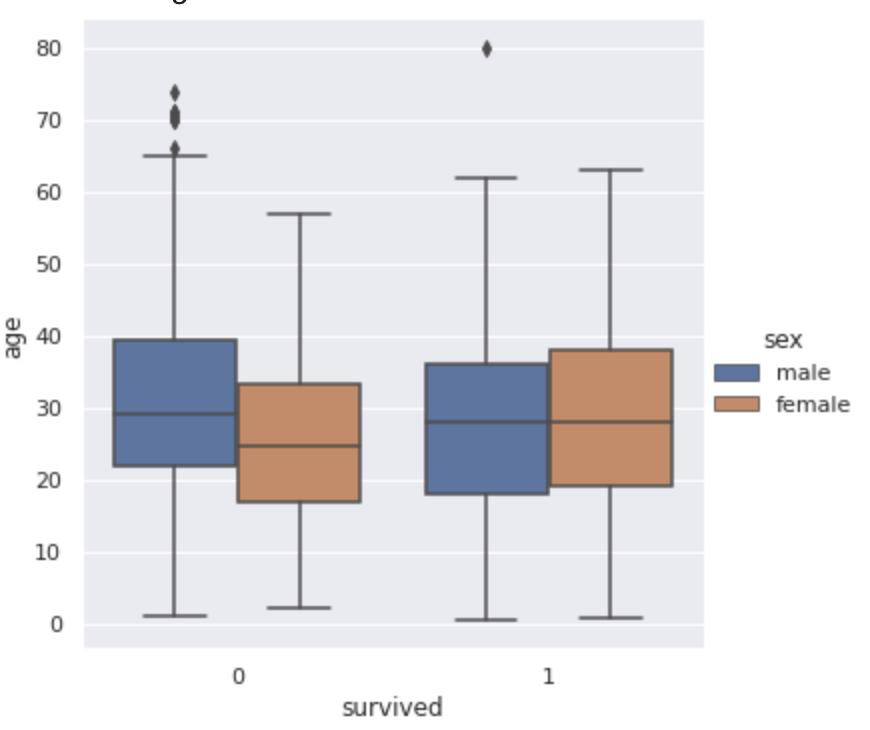
棒の一番下が最小値、一番上が最大値、そして箱の一番上が75%点、箱の真ん中の線が50%点、箱の一番下が25%点となっています!
亡くなってしまった場合と生き残った場合で男女の年齢分布がひっくり返っていることが分かりますねー!
Seabornでバイオリンプロットを描画
続いて箱ひげ図を進化させたバイオリンプロットというグラフを見ていきましょう!
violinplotとするだけで簡単にキレイなグラフが描画されます。
sns.violinplot(x="survived", y="age", hue="sex", data=df)
sns.catplot(x="survived", y="age", hue="sex", data=df, kind="violin")
plt.show()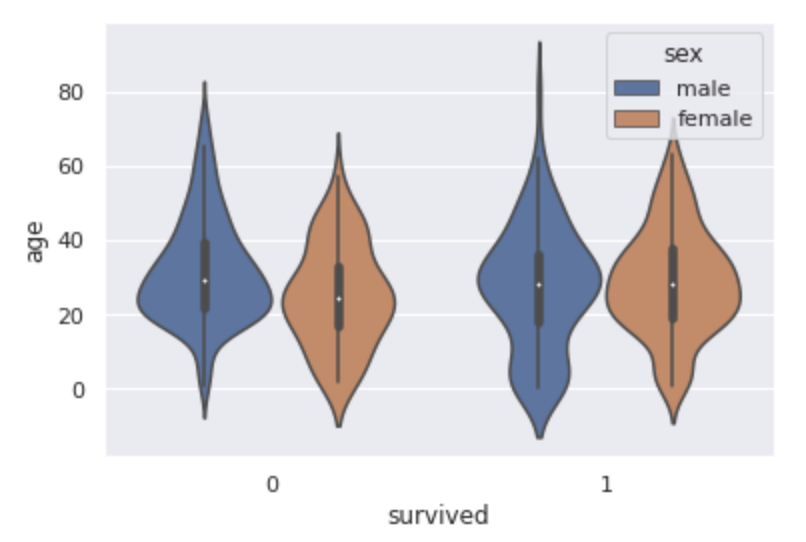
バイオリンプロットでは箱ひげ図にプラスしてサンプルの分布を表した密度関数が表示されます。
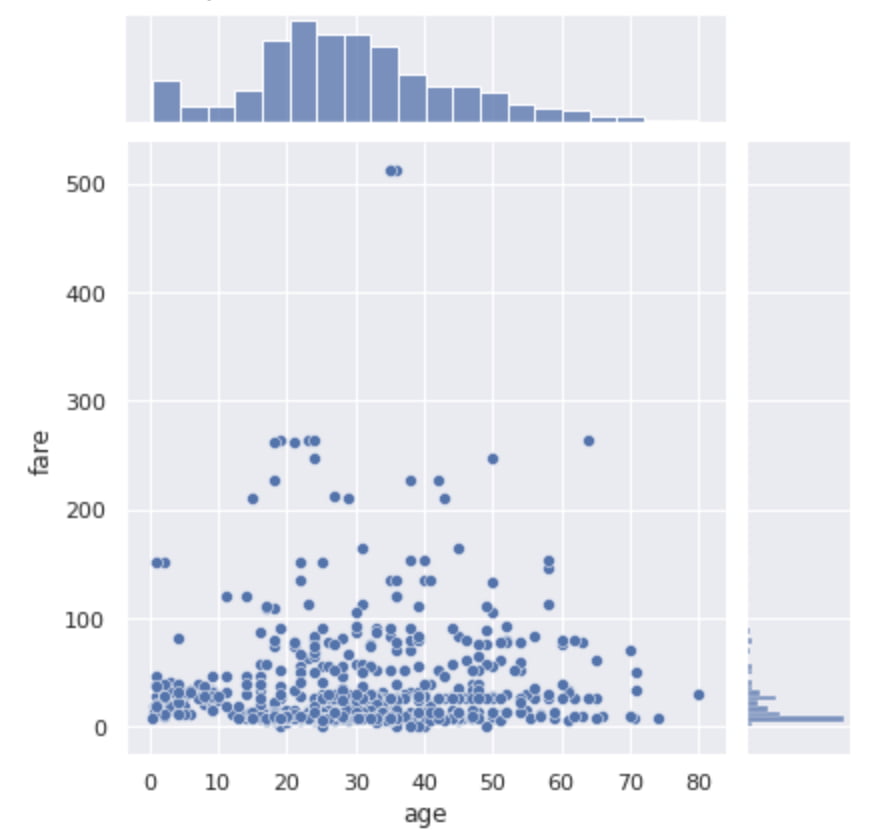
Seabornでヒストグラムと散布図を合わせたjointplot
続いてjointpotについて見ていきましょう!
sns.jointplot(x="age", y="fare", data=df)
plt.show()jointplotを使えば散布図とヒストグラムを同時に見ることができるんです!
Seabornで各種変数のpairplot
続いてpairpotについて見ていきましょう!
sns.pairplot(df[["age", "fare"]])
plt.show()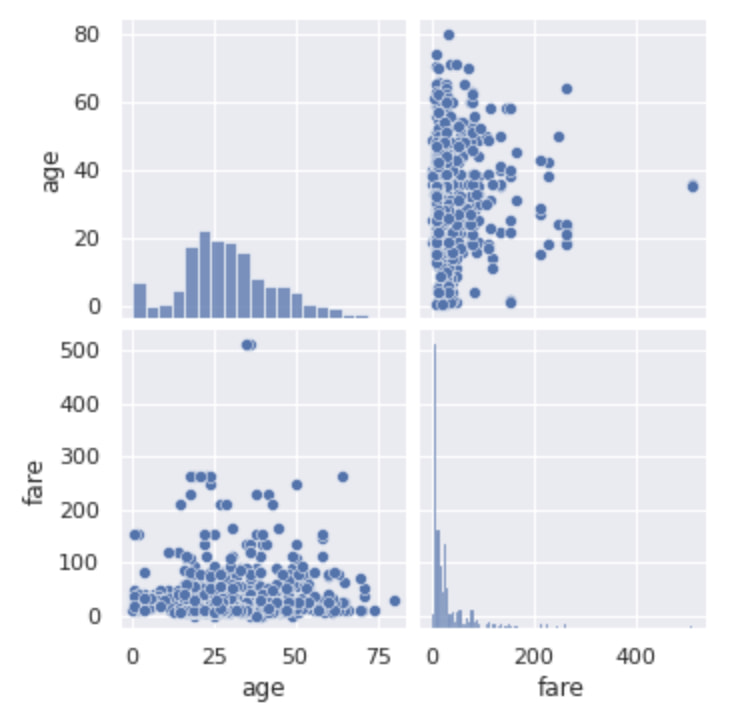
こんな感じでjointplotとほぼ同じように見えますが、これ実は変数が多くても問題ないんです。
タイタニックのデータだと量的変数が少ないのでirisのデータを利用して見てみましょう!
df = sns.load_dataset("iris")
sns.pairplot(df)
plt.show()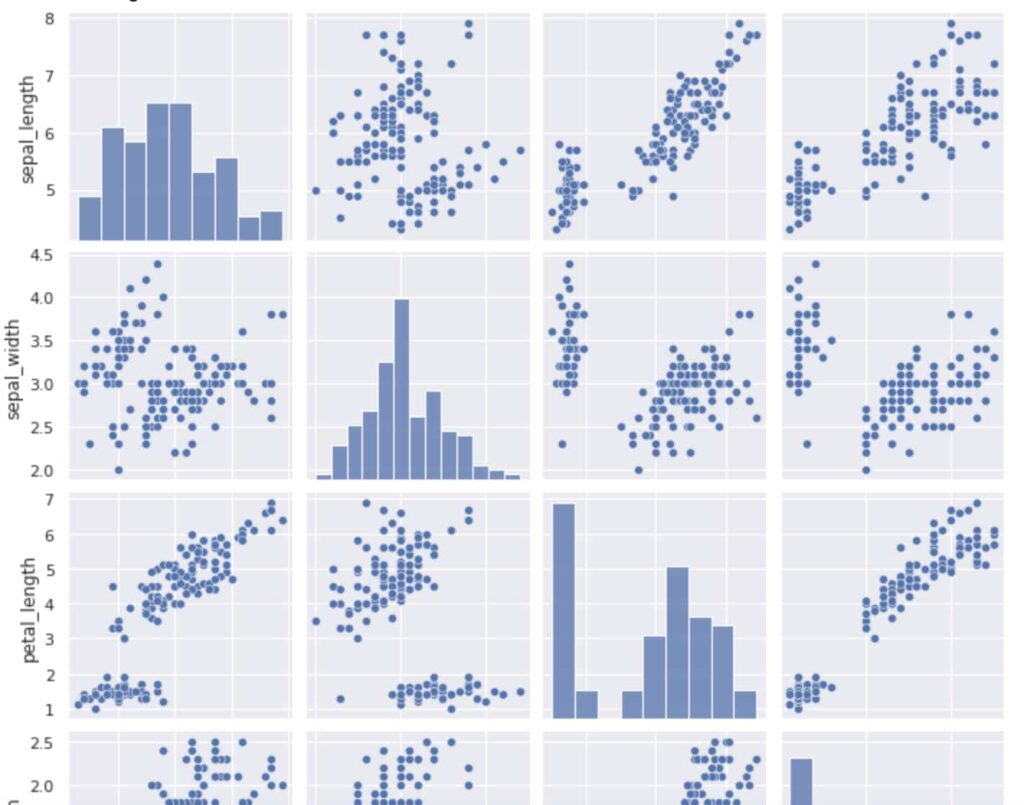
こんな感じになります!
Seabornでヒートマップを描画
続いてヒートマップを描画していきます!
今回はirisデータよりもさらに量的変数の量が多いボストンの住宅価格のデータを扱っていきます!
from sklearn.datasets import load_boston
boston = load_boston()
df = boston.data
df = pd.DataFrame(df, columns = boston.feature_names)
sns.heatmap(df.corr())
plt.show()df.corr()で簡単に各変数の相関係数を表示することができ、それをSeabornで簡単にヒートマップとして表示することが出来るんです!
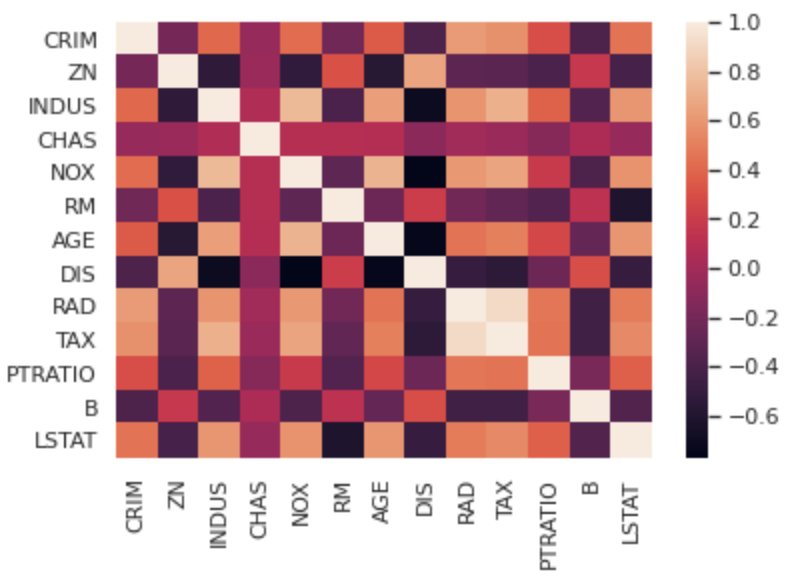
これで多変数の相関関係も一目瞭然ですね!
ヒートマップは相関関係だけでなく多変量時系列データなどの値の強弱を見るのに使ったりします!
MatplotlibとSeabornについては以下の記事で詳しくまとめていますので是非チェックしてみてください!

Pythonの使い方:モデル構築
タイタニックのデータをメインで扱ってきましたが、最後に実践に即したデータコンペのデータを使ってモデル構築をおこなっていきましょう!
国産データコンペ Nishikaの「中古マンション価格予測」というトレーニングコンペのデータに対してLightGBMを実装してみたいと思います。
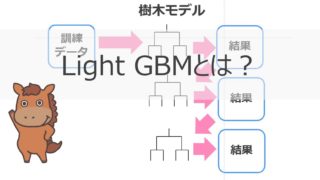
Light GBMとは非常に強力な機械学習手法で決定木を勾配ブースティングによりアンサンブル学習した手法になります。
詳しくは以下の記事でまとめていますので興味のある方は是非チェックしてみてください!
まず Nishikaに会員登録し中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
学習データには複数CSVが入っているので、それらをglobで結合させてデータフレーム化していきます。
globは、ディレクトリに格納されたファイル名を抽出するのに便利なライブラリです。

import glob
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as mae
files = glob.glob("train/*.csv")
data_list = []
for file in files:
data_list.append(pd.read_csv(file, index_col=0))
df = pd.concat(data_list)カラムを見てみると・・・

欠損値があったり、数値型で欲しいデータが文字列型になっていたりするので前処理を施していきます!
def data_pre(df):
nonnull_list = []
for col in df.columns:
nonnull = df[col].count()
if nonnull == 0:
nonnull_list.append(col)
df = df.drop(nonnull_list, axis=1)
df = df.drop("市区町村名", axis=1)
df = df.drop("種類", axis=1)
dis = {
"30分?60分":45,
"1H?1H30":75,
"2H?":120,
"1H30?2H":105
}
df["最寄駅:距離(分)"] = df["最寄駅:距離(分)"].replace(dis).astype(float)
df["面積(㎡)"] = df["面積(㎡)"].replace("2000㎡以上", 2000).astype(float)
y_list = {}
for i in df["建築年"].value_counts().keys():
if "平成" in i:
num = float(i.split("平成")[1].split("年")[0])
year = 33 - num
if "令和" in i:
num = float(i.split("令和")[1].split("年")[0])
year = 3 - num
if "昭和" in i:
num = float(i.split("昭和")[1].split("年")[0])
year = 96 - num
y_list[i] = year
y_list["戦前"] = 76
df["建築年"] = df["建築年"].replace(y_list)
year = {
"年第1四半期": ".25",
"年第2四半期": ".50",
"年第3四半期": ".75",
"年第4四半期": ".99"
}
year_list = {}
for i in df["取引時点"].value_counts().keys():
for k, j in year.items():
if k in i:
year_rep = i.replace(k, j)
year_list[i] = year_rep
df["取引時点"] = df["取引時点"].replace(year_list).astype(float)
for col in ["都道府県名", "地区名", "最寄駅:名称", "間取り", "建物の構造", "用途", "今後の利用目的", "都市計画", "改装", "取引の事情等"]:
df[col] = df[col].astype("category")
return df
df = data_pre(df)
この前処理に関してここでは詳細は省きますが、全てが欠損値になっているカラムを削除して、「最寄り駅・面積・建築年・取引時点」に関して変換をおこなっています。
そして前処理をおこなったデータに対してLightGBM を実装!
df_train, df_val =train_test_split(df, test_size=0.2)
col = "取引価格(総額)_log"
train_y = df_train[col]
train_x = df_train.drop(col, axis=1)
val_y = df_val[col]
val_x = df_val.drop(col, axis=1)
trains = lgb.Dataset(train_x, train_y)
valids = lgb.Dataset(val_x, val_y)
params = {
"objective": "regression",
"metrics": "mae"
}
model = lgb.train(params, trains, valid_sets=valids, num_boost_round=1000, early_stopping_rounds=100)簡単ですね!
このタスクでは評価指標がMAE(平均絶対誤差)であり、結果は
0.0764となりました!
パラメータチューニングや特徴量エンジニアリングによってさらに精度が上がりますので是非色々と手を動かしてみてください!
データコンペですのでテストデータで予測値を算出し提出するところまでやってみましょう!
df_test = pd.read_csv("test.csv", index_col=0)
df_test = data_pre(df_test)
predict = model.predict(df_test)
df_test["取引価格(総額)_log"] = predict
df_test[["取引価格(総額)_log"]].to_csv("submit_test.csv")簡単に実装できましたねー!
全コードは以下になります!
機械学習については以下の記事で詳しく解説していますので是非チェックしてみてください!
Pythonの使い方をさらに深堀りするために
ここまででPythonの使い方について基本的なところを見てきましたが、実は機械学習には他にもたくさんの手法がありますし、機械学習やデータ分析以外にも様々なことがPythonを通じて実装できるんです。
Pythonで出来ることについては以下の記事で詳しくまとめていますのでチェックしてみてください。

小説形式で分かりやすくまとめていますのでこちらもあわせてどうぞ!

(2026/07/02 12:26:49時点 Amazon調べ-詳細)
価格は300円ちょっとですし、Kindle unlimitedであれば無料で読めるのでぜひチェックしてみてくださいね!
その上で、さらにPythonでできることを手を動かしながら学びたいという方は以下のUdemyコースを僕自身が公開していますので是非受講してみてください!
【実践】ビジネスケースとつなげてPythonで出来ること5つを学べる3日間集中コース
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 3.5時間 |
| 【レベル】 | 初級~中級 |
手前味噌ですが、まずPythonについて理解してみるのにオススメなコースを僕自身が出しています!
Pythonで出来ることのうち以下の5つを網羅して学んでいきます。
・データ集計・加工・描画
・機械学習を使ったモデル構築
・Webスクレイピング
・APIの利用
・Webアプリケーション開発
データ集計・加工・描画と機械学習モデル構築に関してはKaggleというデータ分析コンペティションのWalmartの小売データを扱いながら学んでいきます。
WebスクレイピングとAPI利用とWebアプリケーション開発に関しては、楽天の在庫情報を取得してSlackに自動で通知するWebアプリケーションを作成して学んでいきます。
Pythonで何ができるのか知りたい!という方には一番はじめにまず受けていただきたいコースです!
Twitterアカウント(@statistics1012)にメンションいただければ1500円になる講師クーポンを発行いたします!
そしてその中でも機械学習やデータ分析領域を深堀りしたい!という方は以下の講座もチェックしてみてください!
【初学者向け】データ分析コンペで楽しみながら学べるPython×データ分析講座
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 4時間 |
| 【レベル】 | 初級~中級 |
僕自身がUdemyの色んなコースを受けてみた中で、他のコースにはないこんなコースあったらいいなみたいなコースを作ってみました。
このコースは、なかなか勉強する時間がないという方に向けてコンパクトに分かりやすく必要最低限の時間で重要なエッセンスを学び取れるように作成しています。
アニメーションを使った概要編とハンズオン形式で進む実践編に分かれており、概要編ではYoutubeの内容をより体系的にデータ分析・機械学習導入の文脈でまとめています。
データサイエンスの基礎について基本のキから学びつつ、なるべく堅苦しい説明は抜きにしてイメージを掴んでいきます。
統計学・機械学習の基本的な内容を学び各手法の詳細についてもなるべく概念的に分かりやすく理解できるように学んでいきます。
そしてデータ分析の流れについては実務に即したCRISP-DMというフレームワークに沿って体系的に学んでいきます!
データ分析というと機械学習でモデル構築する部分にスポットがあたりがちですが、それ以外の工程についてもしっかりおさえておきましょう!
続いて実践編ではデータコンペの中古マンションのデータを題材にして、実際に手を動かしながら機械学習手法を実装していきます。
ここでは、探索的にデータを見ていきながらデータを加工し、その上でLight gbm という機械学習手法を使ってモデル構築までおこなっていきます。
是非興味のある方は受講してみてください!
Twitterアカウント(@statistics1012)にメンションいただければ1500円になる講師クーポンを発行いたします!
Pythonの使い方まとめ
Pythonは比較的簡単な言語で、個人でも始めやすい言語になっています。
近年ではPythonを利用したデータサイエンスの案件も増えています。
今後もデータサイエンスの需要の増加に伴い、Pythonを使用したデータサイエンスに知見のあるデータサイエンティストの需要は増えることでしょう。
Jupyter Notebookにしかない機能もあるので、Pythonを始める際は是非導入を検討してみてください。
Pythonの勉強法については以下の記事でまとめていますのでチェックしてみてください!




 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!

















