【初心者向け】PythonのBeautiful Soupでスクレイピングを実装してみよう!


こんにちは!
消費財メーカーでのデータサイエンティスト・デジタルマーケターを経て現在は独立し会社を経営しているウマたん(@statistics1012)です。
Webサイトのテキスト情報を抽出したい時に非常に便利なのがスクレイピングという技術。

いやいや、実はPythonを使えばスクレイピングが簡単に実装できるんです。
Python初心者でも簡単に実装できるのでおすすめ!
この記事では、
・スクレイピングとは何なのか
・Pythonでの実装
を見ていきたいと思います。
ここでのPython実装では初心者向けに本当に簡易的な実装しか行いませんが、ここで学んだことを土台にして実際に色々なスクレイピングを行ってみてくださいね。
以下の動画でも詳しく解説していますよ!
ちなみに以下の僕のUdemy講座でBeautifulSoupを使った様々なスクレイピングプログラムを作っていきますので興味のある方はぜひ受講してみてください!
【初心者向け】Webスクレイピングを学ぼう!PythonのBeautifulSoupで様々な応用プログラムを作ろう!
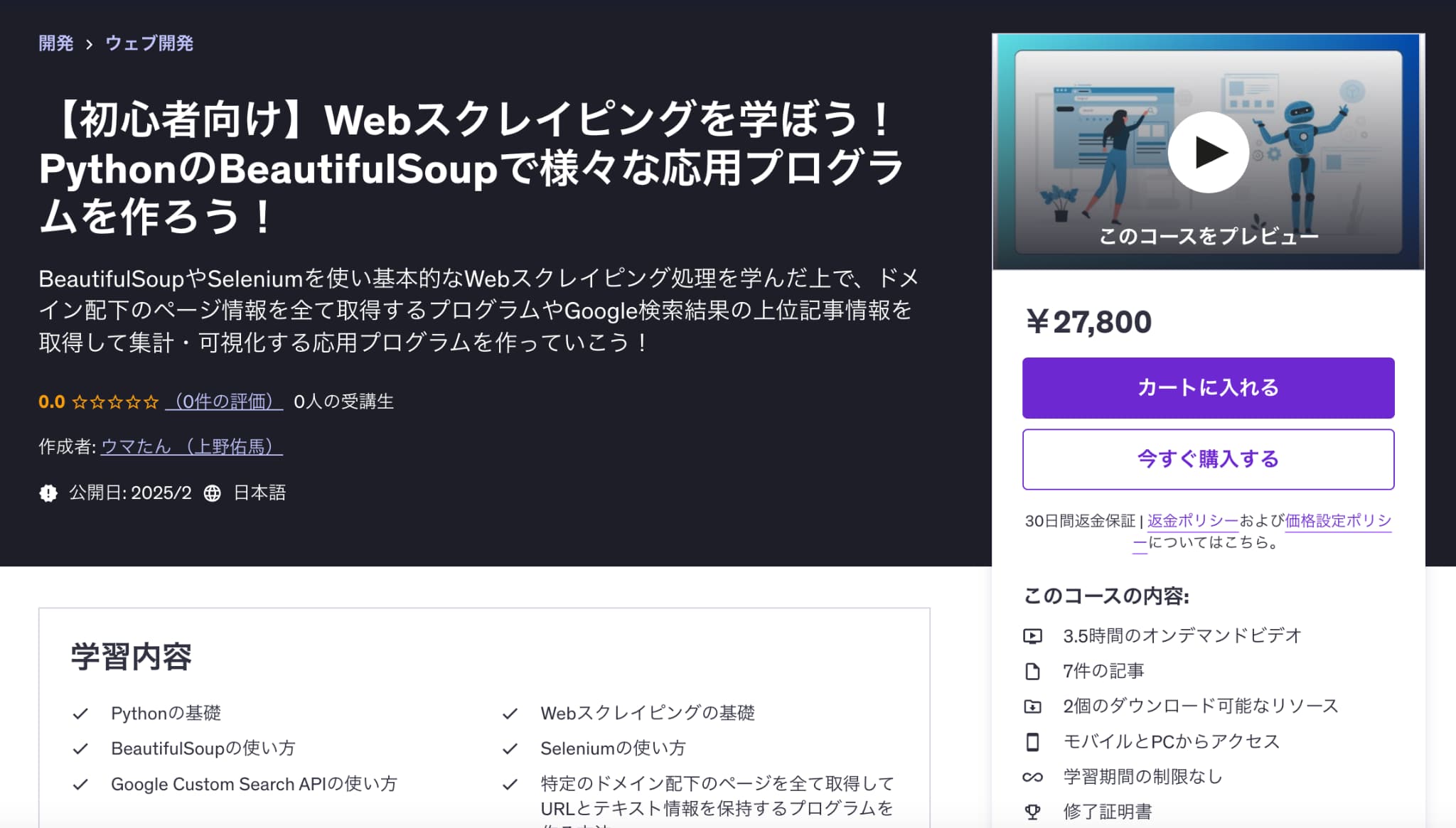
| 【時間】 | 3.5時間 |
|---|---|
| 【レベル】 | 初級 |
Webスクレイピングを学んで色んな実務で使える有用なプログラムを作ってみたいならこれ!
今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
スクレイピングとは

スクレイピングは、Webサイトから自動的にテキスト情報を抽出する技術。
毎回手動でデータを引っ張ってくるのは非常に面倒であるため、スクレイピングを使って自動でデータを引っ張ってくることが多いです。
非常に応用の範囲が広い技術で、様々な場面で用いられています。
例えば、スクレイピングを使うことで株価の情報などを自動的に日々抽出して自動売買するなど応用が可能です。

スクレイピングに必要な知識・技術

さて、そんなスクレイピングですがどのような技術があれば実装が可能なのでしょうか?
Pythonの技術
スクレイピングはPythonの「Requests」「beautifulsoup」「selenium」というライブラリを使えば簡単に実装可能です。
スクレイピング後のデータに関してもPythonを用いて、解析を行うことが多いでしょう。
例えば、スクレイピングしたテキストデータを自然言語処理にかけて文書一致度を計算するなどができます。

簡単に実装可能ですが、Pythonの技術はある程度必要です。
HTMLにおけるDOMの知識
実装はPythonを用いて行いますが、HTMLの構造そしてDOMについて理解しておくことが必要です。
DOMはドキュメントオブジェクトモデルの略で、HTMLを外部から操作するような仕組み・Webサイトの構造のことを表します。
HTMLでは、bodyタグやheadタグなど様々なタグを用いて階層構造を取ります。
そのタグの中にidやclassを記述することで、様々な表現が可能。そのidやclass、そしてタグを指定してスクレイピングを行うためHTML・DOMの知識が必要なのです。
コーディングするわけではないため、技術は必要ありませんがソースを読んで理解できるレベルの知識は必要になってきます。
スクレイピングの注意点

スクレイピングを行う際はいくつか注意点があるので確認しておきましょう!
スクレイピングが禁止されていないかどうか確認する
スクレイピングは、非常に便利な技術だけに悪用される可能性もあります。
そのためWebサイトによってはスクレイピングを禁止している場合があります。
スクレイピングが禁止されていないかどうか確認して行うようにしましょう!
スクレイピングによって負荷をかけないようにする
スクレイピングを頻繁に行うとサーバーに負荷をかけることになります。
そのため頻繁にリクエストを送らないようにsleepメソッドを使用してリクエストの時間を空けるようにしましょう!
スクレイピングをPythonで実装

それでは、Pythonを用いてスクレイピングを実装していきましょう!
この記事では、特定URLのpタグに囲まれた本文テキストを抽出する簡易的なコードを実装していきます。
まずは、ライブラリをインポートしていきましょう!
#ライブラリーインポート
import requests
from bs4 import BeautifulSoup
from time import sleepsleepはスクレイピングのタイミングを制御します。
Webスクレイピングはサーバーに負荷をかけるため、処理を制御する配慮が暗黙のルールとなっています。
#スクレイピング
class Scr():
def __init__(self, urls):
self.urls=urls
def geturl(self):
all_text=[]
for url in self.urls:
r=requests.get(url)
c=r.content
soup=BeautifulSoup(c,"html.parser")
article1_content=soup.find_all("p")
temp=[]
for con in article1_content:
out=con.text
temp.append(out)
text=''.join(temp)
all_text.append(text)
sleep(1)
return all_textここがスクレイピングの本体です。
クラスで定義しています。
URLを配列に格納して渡すと、pタグに囲まれたテキスト情報を配列に格納して返してくれるクラスScrを作りました。
URLを複数入れても複数データで返してくれます。
requestsはURLにアクセスして引っ張ってくるライブラリ。
そこからBeautifulsoupでタグを指定してテキストを取得します。
soup.find_all(“p”)の部分でタグを指定しており、今回はpタグを全て引っ張ってくる指定をしています。
ここの部分を変更することで抽出するタグを変更することができます。
sc=Scr(["https://toukei-lab.com/conjoint","https://toukei-lab.com/correspondence"])
print(sc.geturl())最後に当サイトのコレスポンデンス分析の記事をスクレイピングしていきます。
・・・

だいぶ雑ですが、テキストがリストに格納されていることが分かります。
これでスクレイピングは終了!
最後にコードをまとめておきます!
初心向けのPythonスクレイピング勉強法
スクレイピングはPythonで行えることの中でも比較的分かりやすく実装がカンタンな領域です。

ただ、奥が深くスクレイピングしたデータをどのように扱うかで色んな幅が広がります。
また、本記事で使用したライブラリはBeautifulsoupですが、Seleniumも有名です。
もしスクレイピングを勉強したいなら以下のUdemy講座がおすすめ!
【初心者向け】Webスクレイピングを学ぼう!PythonのBeautifulSoupで様々な応用プログラムを作ろう!
| 【時間】 | 3.5時間 |
|---|---|
| 【レベル】 | 初級 |
Webスクレイピングを学んで色んな実務で使える有用なプログラムを作ってみたいならこれ!
今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
実践】ビジネスケースとつなげてPythonで出来ること5つを学べる3日間集中コース
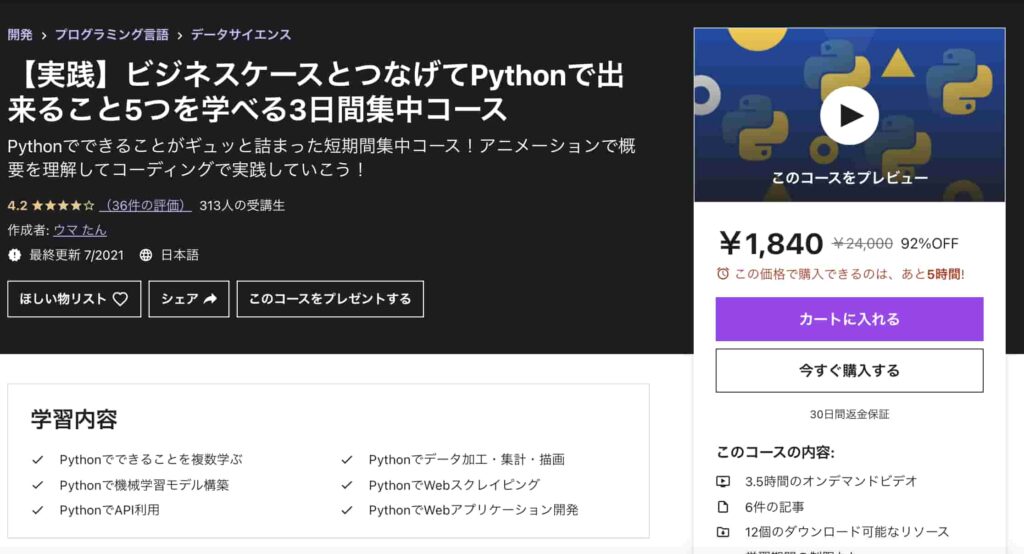
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 3.5時間 |
| 【レベル】 | 初級~中級 |
手前味噌ですが、僕自身が公開しているコースです。
Pythonで出来ることのうち以下の5つを網羅して学んでいきます。
・データ集計・加工・描画
・機械学習を使ったモデル構築
・Webスクレイピング
・APIの利用
・Webアプリケーション開発
データ集計・加工・描画と機械学習モデル構築に関してはKaggleというデータ分析コンペティションのWalmartの小売データを扱いながら学んでいきます。
WebスクレイピングとAPI利用とWebアプリケーション開発に関しては、楽天の在庫情報を取得してSlackに自動で通知するWebアプリケーションを作成して学んでいきます。
スクレイピングを組み込んだアプリケーションをしっかり開発していくので、スクレイピングを使って何かを作りたい!という人にはかなりオススメの講座になっています。
【入門から実践まで】Webマーケティングの全体像とデータ活用を短時間で学び実際にSEO集客ツールを作ってみよう!
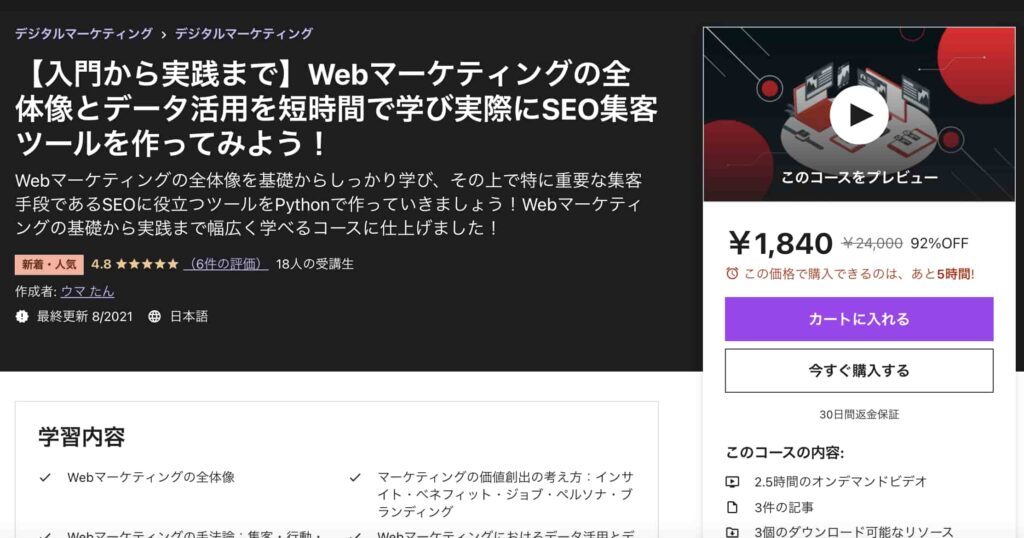
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 2.5時間 |
| 【レベル】 | 初級 |
こちらはWebマーケティングについて全体像を理解してもらえるように僕自身が作成した講座になります。
Webマーケティングについて幅広く学べると同時にデータ分析についても簡単に理解した上で、最終的には簡単なSEOツールを作成していきます。
Webマーケティングの概要を理解したい方にもオススメですし、実際にプログラミング言語を使ってWebマーケのツールを実装してみたい方にもオススメの講座になっています!
ここら辺を学んでおいて、後は自分で実際に手を動かして色々スクレイピングしてみるのがオススメです!
Pythonでスクレイピング まとめ
本記事では、スクレイピングについて見てきました。
スクレイピングは、様々な分野に応用が可能な非常に有用な技術です。
PythonのスキルとHTMLの知識で簡単に実装可能なので是非試してみてください!
Pythonでの実装が難しい方はOctoparseというサービスで簡単にスクレイピングが出来るので試してみてください!
Pythonはデータ解析やスクレイピングそしてWebアプリケーション作成まで出来る幅広いプログラミング言語!
以下の記事で初心者がPythonを習得する方法についてまとめていますのでよければご覧ください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!