
実データで学ぶMatplotlibとSeabornの違いと描画方法!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では、Pythonで頻出するデータ可視化のためのライブラリMatplotlibとSeabornの違いについてまとめていきたいと思います!

ぜひMatplotlibとSeabornの基本についてしっかりおさえて扱えるようになっておきましょう!
目次
MatplotlibとSeabornの違い

まずは、MatplotlibとSeabornの違いについて見ていきましょう!
端的に言うと、SeabornはMatplotlibの使い勝手を良くしたライブラリです。
Pythonでよく使うライブラリの中でも必ず名前があがるMatplotlib!
Pandas、Numpy、MatplotlibあたりはPythonを扱う上で必須なライブラリですよねー。
Matplotlibは2003年にリリースされ現在も開発がされているデータ分析の可視化に必須のライブラリ。
データ分析においては探索的データ分析(EDA)と呼ばれる工程が非常に重要で、その工程においてMatplotlibによる可視化は非常に便利です。
Jupyter labやJupyter notebookには最初から入っているので、そのままImportすることで利用することができます。
以下のように記述してあげましょう!
import matplotlib.pyplot as plt
%matplotlib inline2行目はJupyter環境でグラフを描画する上で必要なおまじないであるとおぼえておきましょう。
ただMatplotlibは若干描画がダサいという弱点があります。
R言語のggplot2などと比べるとどうしても見劣りしてしまうんですね。
そこで登場するのがSeaborn!

Seabornの内部ではMatplotlibが動いているのですが、Seabornを使うことでよりきれいなグラフを描画することが可能なんです!
ただグラフの調整の仕方やルールはMatplotlibと一緒なので、Matplotlibと同時にSeabornを使えるようになりデータの可視化をおこなっていきましょう!
Seabornを使うにはMatplotlibとあわせて以下のようにSeabornのライブラリをインポートしていきます。
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
%matplotlib inlineこの時、sns.set()と記載しないとSeabornの描画が反映されないので注意しましょう!
Matplotlib&Seabornで可視化をする上でのデータ準備

それでは早速MatplotlibやSeabornを使って可視化をおこなっていくための実データの準備をおこなっていきましょう!
![]()
![]() Nishikaというデータコンペプラットフォームの中の「中古マンション価格」データを使います。
Nishikaというデータコンペプラットフォームの中の「中古マンション価格」データを使います。
![]()
![]() Nishikaに会員登録をして「中古マンション価格」データからtrain.zipをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
Nishikaに会員登録をして「中古マンション価格」データからtrain.zipをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
train.zipを開くと中には以下のように複数のCSVファイルが入っています。
今回はこれらをデータフレームとして結合させるところからデータの確認・可視化をおこなっていきます。
そのためにMatplotlibやSeaborn以外のライブラリも必要になるのでImportしてあげましょう!
import glob
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlineglobはディレクトリに格納されたファイル名を抽出するのに便利なライブラリで、今回は複数のファイルがtrainフォルダ内にデータとして格納されているのでそれらのファイル名を抽出するのに必要になります。

現在trainというフォルダにファイルが入っているとすると、以下のように記述することでtrain内のファイル名を全て抽出することができます。
files = glob.glob("train/*.csv")この時、*はワイルドカードと呼ばれ、このようにワイルドカードを指定することで全てのファイル名を該当させることができます。
filesを見てみると以下のようになっていることが分かります。
[‘train/40.csv’,
‘train/41.csv’,
‘train/43.csv’,
‘train/42.csv’,
‘train/46.csv’,
‘train/47.csv’,
‘train/45.csv’,
‘train/44.csv’,
‘train/37.csv’,
‘train/23.csv’,
‘train/22.csv’,
・・・
各ファイル名がリスト形式で格納されていることが分かります。
このデータフレームの中身を見てみると・・・
pd.read_csv(files[0])以下のようになっていることが分かります。
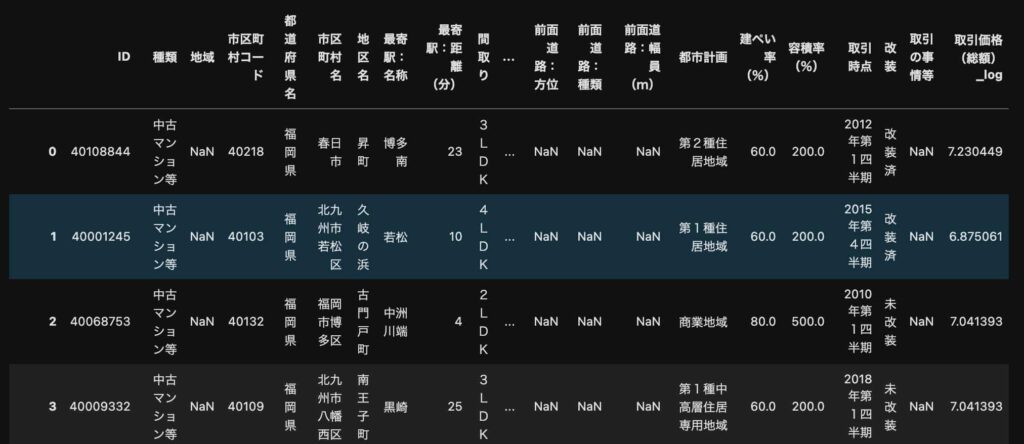
各ファイルそれぞれの格納されているサンプル数は違いますが、全て同じカラムになっています。
そのため、これらのデータをfor文で回して結合させ1つのデータフレームにしていきましょう!
data_list = []
for file in files:
data_list.append(pd.read_csv(file, index_col=0))
df = pd.concat(data_list)これにて使うデータの準備が完了です。
データが結構汚いので詳細は割愛しますが、前処理をおこなっていきます。

全てが欠損値になっているカラムを削除して、「最寄り駅・面積・建築年・取引時点」に関して変換をおこなっています。
def data_pre(df):
nonnull_list = []
for col in df.columns:
nonnull = df[col].count()
if nonnull == 0:
nonnull_list.append(col)
df = df.drop(nonnull_list, axis=1)
df = df.drop("市区町村名", axis=1)
df = df.drop("種類", axis=1)
dis = {
"30分?60分":45,
"1H?1H30":75,
"2H?":120,
"1H30?2H":105
}
df["最寄駅:距離(分)"] = df["最寄駅:距離(分)"].replace(dis).astype(float)
df["面積(㎡)"] = df["面積(㎡)"].replace("2000㎡以上", 2000).astype(float)
y_list = {}
for i in df["建築年"].value_counts().keys():
if "平成" in i:
num = float(i.split("平成")[1].split("年")[0])
year = 33 - num
if "令和" in i:
num = float(i.split("令和")[1].split("年")[0])
year = 3 - num
if "昭和" in i:
num = float(i.split("昭和")[1].split("年")[0])
year = 96 - num
y_list[i] = year
y_list["戦前"] = 76
df["建築年"] = df["建築年"].replace(y_list)
year = {
"年第1四半期": ".25",
"年第2四半期": ".50",
"年第3四半期": ".75",
"年第4四半期": ".99"
}
year_list = {}
for i in df["取引時点"].value_counts().keys():
for k, j in year.items():
if k in i:
year_rep = i.replace(k, j)
year_list[i] = year_rep
df["取引時点"] = df["取引時点"].replace(year_list).astype(float)
for col in ["都道府県名", "地区名", "最寄駅:名称", "間取り", "建物の構造", "用途", "今後の利用目的", "都市計画", "改装", "取引の事情等"]:
df[col] = df[col].astype("category")
return df
df = data_pre(df)
これでデータがだいぶ綺麗になりました!
Matplotlibでヒストグラムを描画

さてここからMatplotlibやSeabornを使ったデータの可視化をおこなっていきます。
まずはヒストグラムを描画してみましょう!
plt.hist(df["最寄駅:距離(分)"], bins=20)このように1行記述するだけで以下のようにヒストグラムを描画することができます。
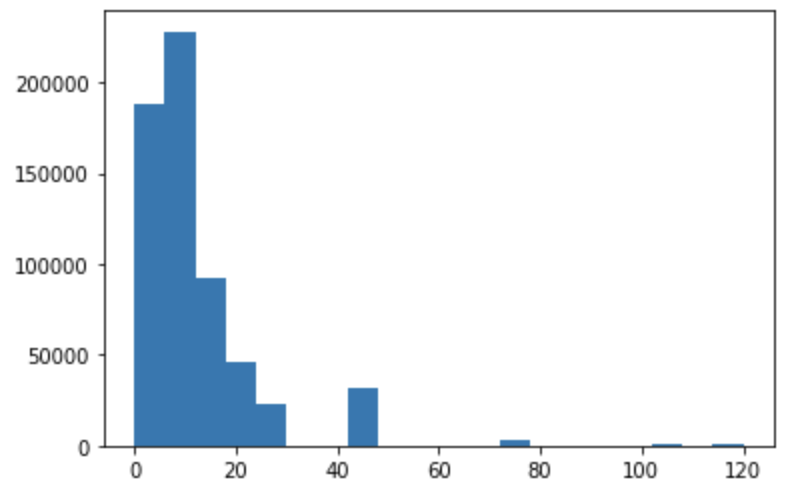
この時、グラフの上にデータが表示されてしまうので以下のように1行追加してあげることでグラフだけを描画させることが出来ます。
plt.hist(df["最寄駅:距離(分)"], bins=20)
plt.show()また、binsのパラメータで階級の数を調整することができ、ここを増やすことで細かいヒストグラムを作成することができます。
例えば、binsを100にすると・・・
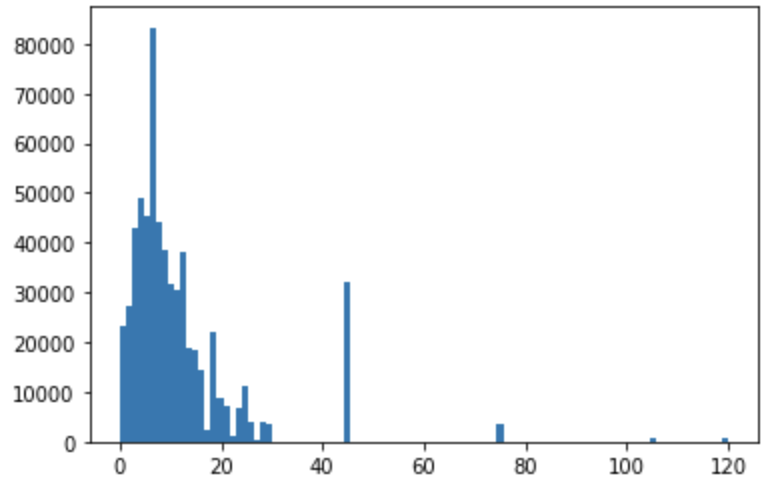
こんな感じで階級数が増えて細かいヒストグラムになっていることが分かります。
この時、rangeというパラメータでデータの範囲を指定してあげることができます。
plt.hist(df["最寄駅:距離(分)"], bins=20, range=(0,30))
plt.show()x軸が0~30の範囲に絞られていることが分かります。
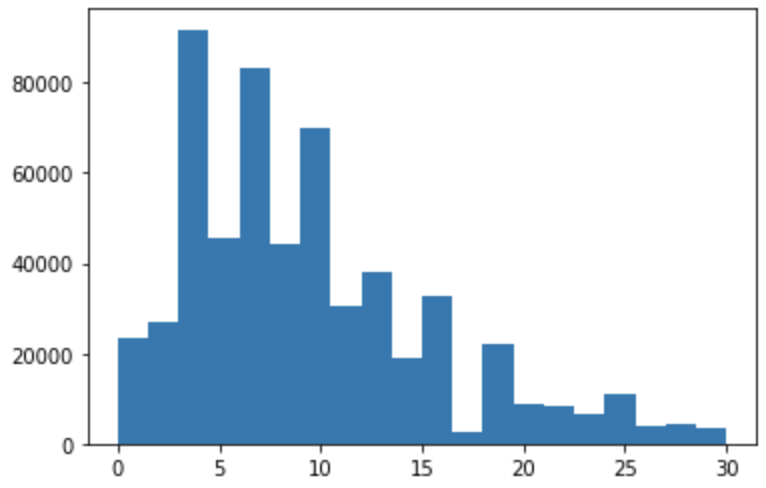
また、描画されるグラフの大きさを調節したい時は以下のようにあげます。
plt.figure(figsize = (20,10))
plt.hist(df["最寄駅:距離(分)"], bins=20, range=(0,30))
plt.show()
見づらい場合はこちらでグラフを調節してあげましょう!
Matplotlibで複数のグラフを描画してみよう!

続いて、複数のグラフを描画してみましょう!
複数のグラフを描画する方法はいくつかあるのですが、ここではsubplotsを使います。
まずは、以下のようにグラフを描画する箱を作ってあげます。
fig, axes = plt.subplots(2, 2, figsize=(20,10))この場合、最初の引数に2 , 2を指定しているので、2行×2列の箱が出来上がります。
そして、それぞれの箱に対してグラフを描画していきます。
fig, axes = plt.subplots(2, 2, figsize=(20,10))
axes[0][0].hist(df["最寄駅:距離(分)"], bins=20)
axes[0][1].hist(df["面積(㎡)"], bins=200)
axes[1][0].hist(df["建築年"], bins=20)
axes[1][1].hist(df["取引価格(総額)_log"], bins=20)
plt.show()このように4つの箱に対してそれぞれのヒストグラムを表示させることが出来ます。
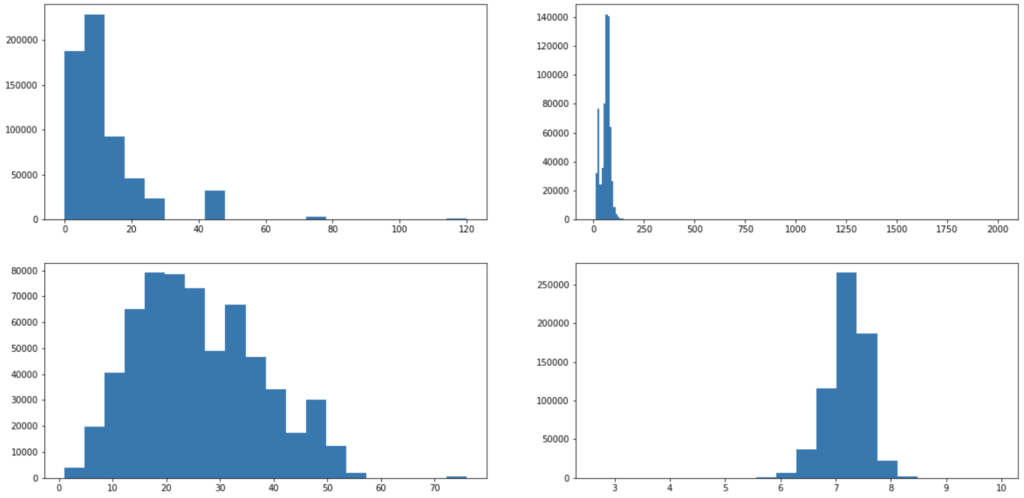
axes[0][0]であれば1行目1列目の左上の箱を指定しています。
この時、右上の面積のグラフが見づらくなっているので、X軸の範囲を指定してあげましょう!
複数プロットにおいて軸の範囲を指定する場合は以下のように記述してあげます。
fig, axes = plt.subplots(2, 2, figsize=(20,10))
axes[0][0].hist(df["最寄駅:距離(分)"], bins=20)
axes[0][1].hist(df["面積(㎡)"], bins=200)
axes[0][1].set_xlim(0,250)
axes[1][0].hist(df["建築年"], bins=20)
axes[1][1].hist(df["取引価格(総額)_log"], bins=20)
plt.show()
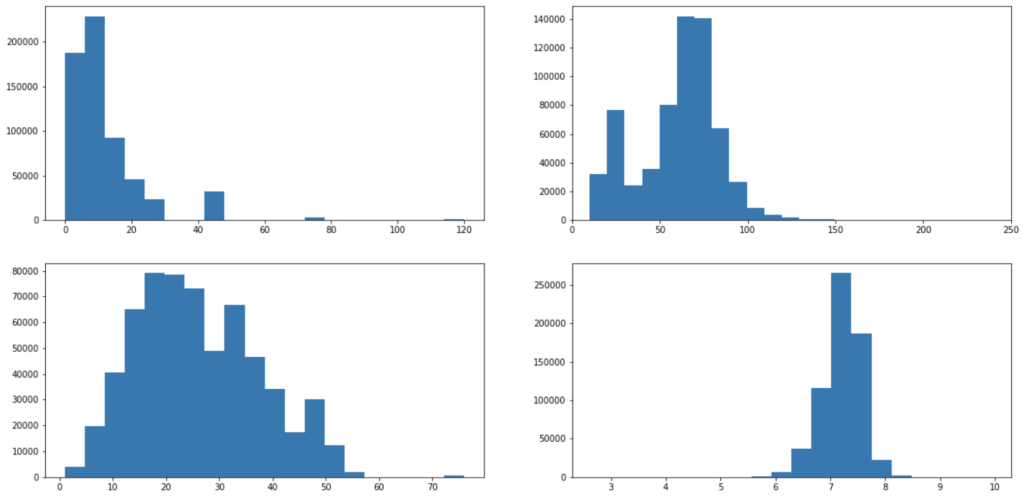
だいぶ見やすくなりました!axes[0][0].set_xlim(0,250)でx軸の範囲を指定しています。
Matplotlibで散布図を描画
続いて散布図を描画していきましょう!
散布図はある変数と変数の間の関係を見るのに非常に便利です。
例えば今回の例では中古マンションの価格に対して面積や最寄り駅からの距離は相関関係があるかどうかを見ることができます。
先程学んだ、複数プロットの方法を使って複数の散布図を描画してみましょう!
fig, axes = plt.subplots(3, 1, figsize=(10,10))
axes[0].scatter(df["最寄駅:距離(分)"], df["取引価格(総額)_log"], alpha=0.1)
axes[1].scatter(df["面積(㎡)"], df["取引価格(総額)_log"], alpha=0.1)
axes[2].scatter(df["建築年"], df["取引価格(総額)_log"], alpha=0.1)
plt.show()散布図を描画するのにはscatterという関数を使います。
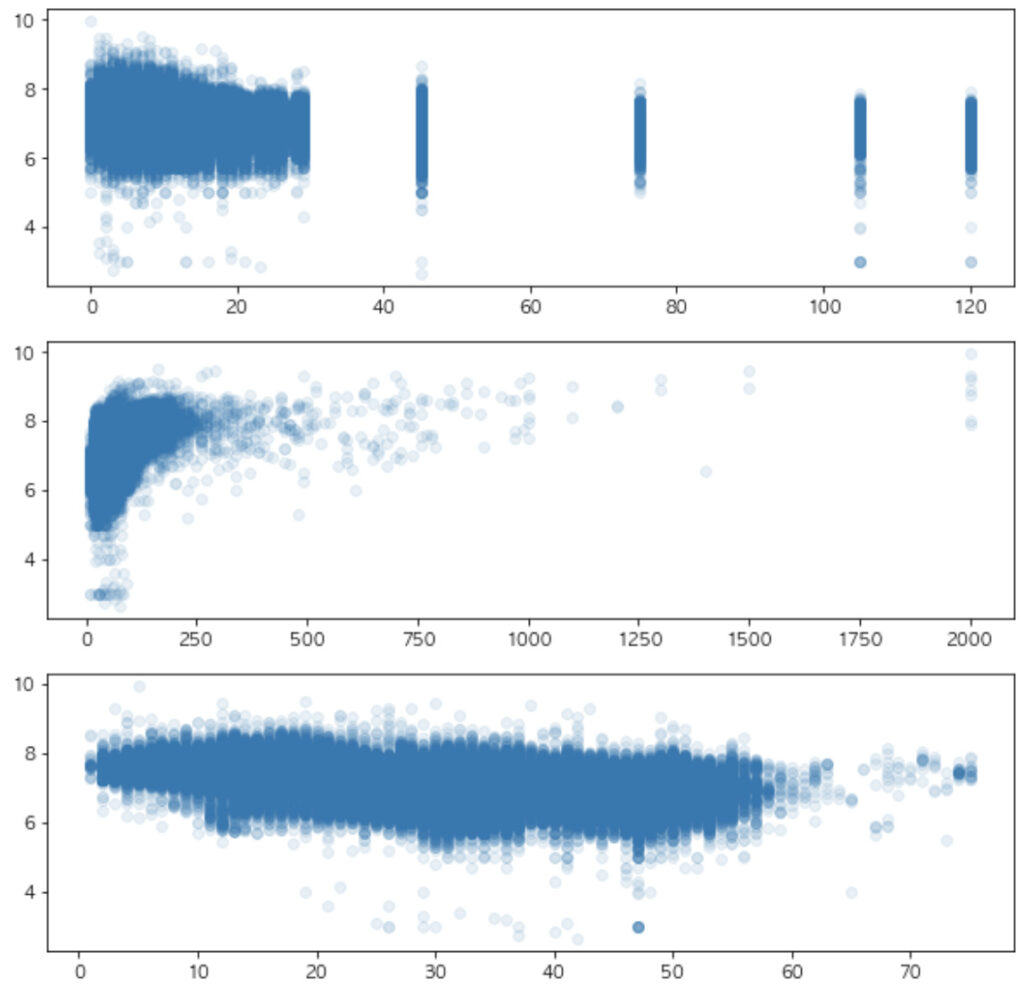
それぞれの変数間の関係を散布図によって見ることができました。
Seabornでヒートマップを描画
先程の散布図をながめてみると、なんとなくそれぞれ関係がありそうな気がします。
ただ、どれくらい関係があるのかは分からない。
実際にどのくらい関係があるかは相関係数を算出して見ることができます!
相関係数には負の相関と正の相関があり、-1から+1の範囲で見ることが出来ます。
以下のように記述することで各変数の相関係数を算出することが出来ます。
df[["取引価格(総額)_log", "最寄駅:距離(分)", "面積(㎡)", "建築年"]].corr()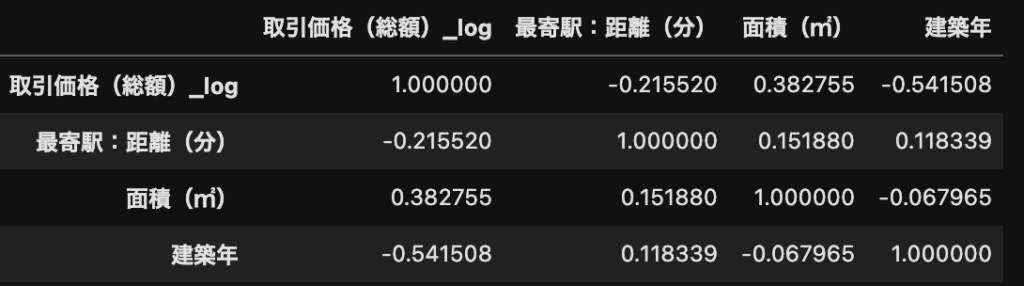
corrは相関(correlation)を表しています。
このそれぞれの相関関係をヒートマップで見てみましょう。
ここでSeabornの出番です。
sns.heatmap(df[["取引価格(総額)_log", "最寄駅:距離(分)", "面積(㎡)", "建築年"]].corr())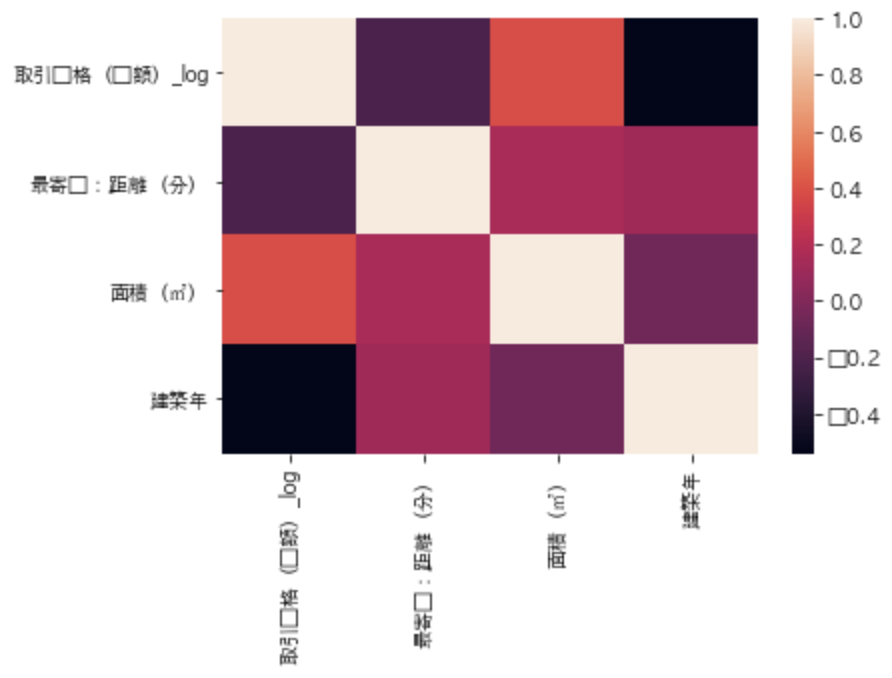
このように1行だけ記述してあげるだけでヒートマップを描画することが出来るんです!
このケースでは変数が少ないのでヒートマップにしなくても問題ないですが、変数がものすごい量になってくるとヒートマップを描画してあげることで見やすくなります。
また引数cmapを指定してあげることでカラーレイアウトを変更することも可能です。
sns.heatmap(df[["取引価格(総額)_log", "最寄駅:距離(分)", "面積(㎡)", "建築年"]].corr(), cmap="Reds")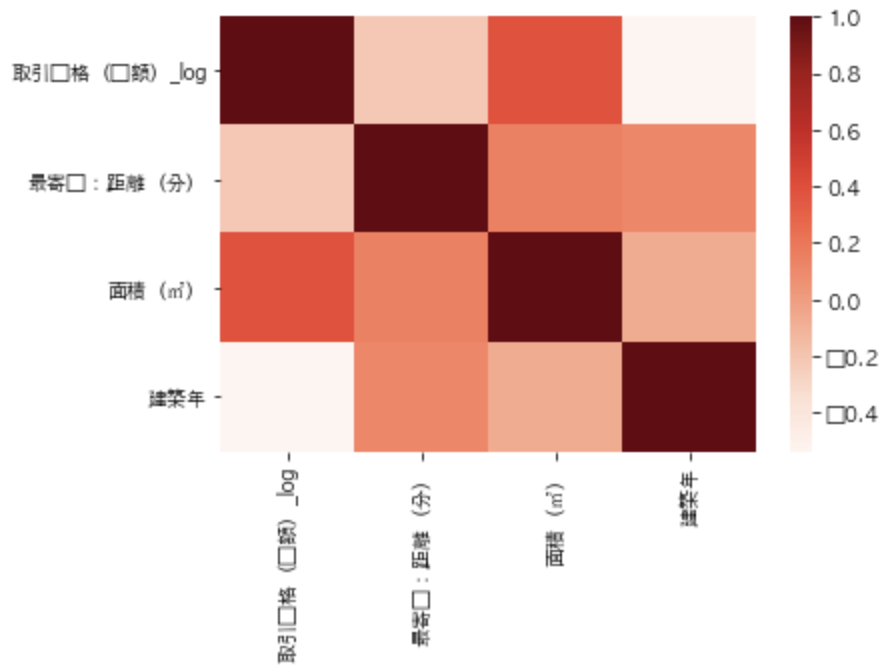
この場合、cmapにRedsを指定してあげています。
ぜひヒートマップを駆使していきましょう!
ちなみに日本語だと上手く表示されないので事前にMatplotlibの内部フォントを以下のように変更しておいてあげるとよいでしょう!
import matplotlib
matplotlib.rcParams["font.family"] = "AppleGothic"
seabornで時系列棒グラフを描画
続いて、Seabornのcountplotを使ってデータ量を綺麗に描画して見ていきます。
countplotを使うことで、棒グラフを見やすく描画することが出来るんです!
fig, axes = plt.subplots(2, 1, figsize=(20,10))
df["取引年"] = df["取引時点"].apply(lambda x:str(x)[:4])
sns.countplot(x="取引年", data=df.sort_values("取引年"), ax=axes[0])
sns.countplot(x="取引時点", data=df, ax=axes[1])
今まで同様に複数プロットの場合はsubplotsを使います。
そしてseabornで描画する場合は引数axを指定してあげて描画の箱を制御します。
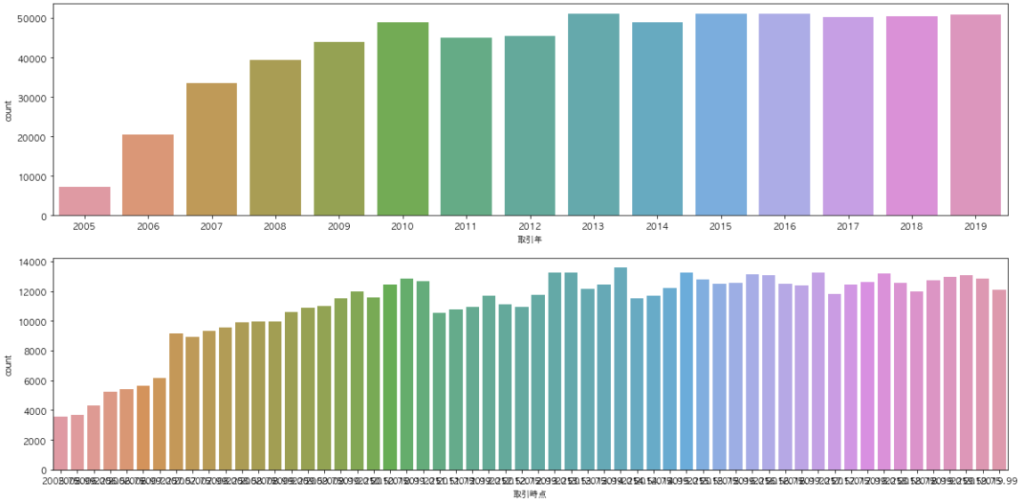
この時、取引時点をそのまま描画しているものと、取引時点の4半期データを年単位に丸めたデータを描画しています。
データが見やすく並んでいることが分かります。
2005年から2010年までは取引量が線形で伸びていて、それ以降は横ばいであることが分かります。
MatplotlibとSeabornの違いや描画方法 まとめ
本記事では、MatplotlibとSeabornの違いについてまとめてきました。
Seabornの方が綺麗に描画が出来るということが少しでも理解いただけたと思います。
データを可視化する際にはこの2つのライブラリをしっかりおさえておきましょう!
他にもPlotlyという優秀な描画ライブラリがあるので興味のある方はあわせてチェックしてみてください!

他にもPythonで出来ることはたくさんあります。
Pythonについて詳しく学びたい方は以下のUdemyの講座で僕自身が講師を務めていますので是非チェックしてみてください!
ちなみに当メディアが運営するAIデータサイエンス特化スクールの「スタアカ(スタビジアカデミー)」では、Pythonを中心に機械学習やデータサイエンスのエッセンスを学べます!
もちろんMatplotlibとSeabornもより実践的に学んでいきますよ!
 公式サイト:https://toukei-lab.com/achademy/
公式サイト:https://toukei-lab.com/achademy/
| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる1週間に1回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
また、Pythonで出来ることを知りたい場合は以下の記事でまとめていますので是非チェックしてみてください!

また、Pythonの勉強法については以下の記事で詳しくまとめています!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















