
PythonでのPlotlyの使い方!色んなグラフを描画してみよう!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
この記事ではグラフをキレイに描画することのできるPlotlyの使い方について解説していきたいと思います!
Pythonでの描画と言えば、MatplotlibやSeabornなどが有名ですがPlotlyも非常に使いやすく人気です。
Plotlyを使うことでインタラクティブにグラフを表現することもできるんです!
Plotlyについて詳しく学びたい方は当メディアが運営するスタビジアカデミーの「株価のテクニカル指標可視化」コースをチェックしてみてください!

目次
Plotlyを使う準備
物は試し!それでは早速Plotlyを使っていきましょう!
ここではPythonの実行環境として「Google Colab」を使っていきます。
Google Colabでは基本的なライブラリがあらかじめ使えるようになっていますが、以下のライブラリはインストールしないと使えませんのでインストールしていきます。
# Plotlyのインストール
!pip install plotly==5.18.0続いて必要なライブラリをインポート。
import numpy as np # 数値計算を効率的に行うためのライブラリ (Numpy) をインポートします。
import pandas as pd # データ操作と分析のためのライブラリ (Pandas) をインポートします。
import plotly.express as px # 高レベルなグラフ作成APIを提供するPlotly Expressをインポートします。
from plotly.subplots import make_subplots # 複数のサブプロットを作成するための機能をインポートします。
import plotly.graph_objects as go # 複雑なグラフやチャートを作成するためのライブラリをインポートします。続いて必要なデータを取得していきます。
Plotly Expressで利用可能な組み込みのサンプルデータセットには以下のものがあります。
・carshare: カーシェアリングのデータセット
・election: 選挙データ
・election_geojson: 選挙の地理情報データ
・experiment: 実験データ
・gapminder: 国別の経済と人口統計データ
・iris: アヤメの測定データ
・medals_long: オリンピックのメダルデータ(ロングフォーマット)
・medals_wide: オリンピックのメダルデータ(ワイドフォーマット)
・stocks: 株価データ
・tips: レストランのチップデータ
・wind: 風向と風速のデータ
今回は、レストランのチップデータと株価データを読み込みます。
# レストランのチップデータの取得
tips_data_df = px.data.tips()
# 株価データの取得
stocks_data_df = px.data.stocks()
display(tips_data_df)
display(stocks_data_df)チップデータと株データは以下のようになっています。
・チップデータ
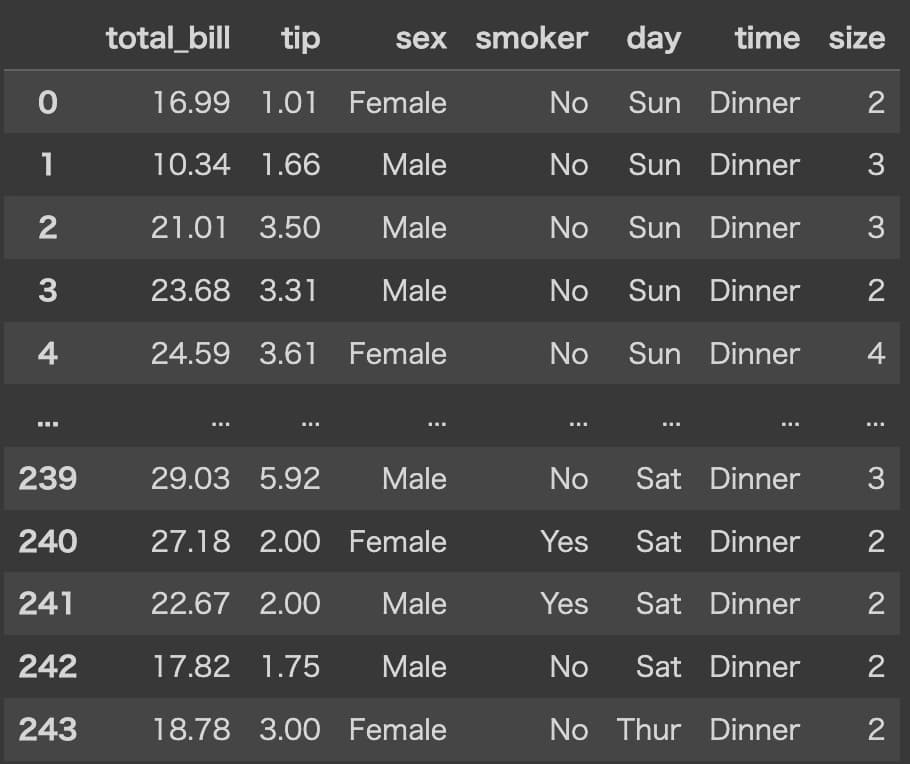
合計の請求額や性別など様々な情報と一緒にチップをどれだけ払ったが入っているデータ。
・株データ
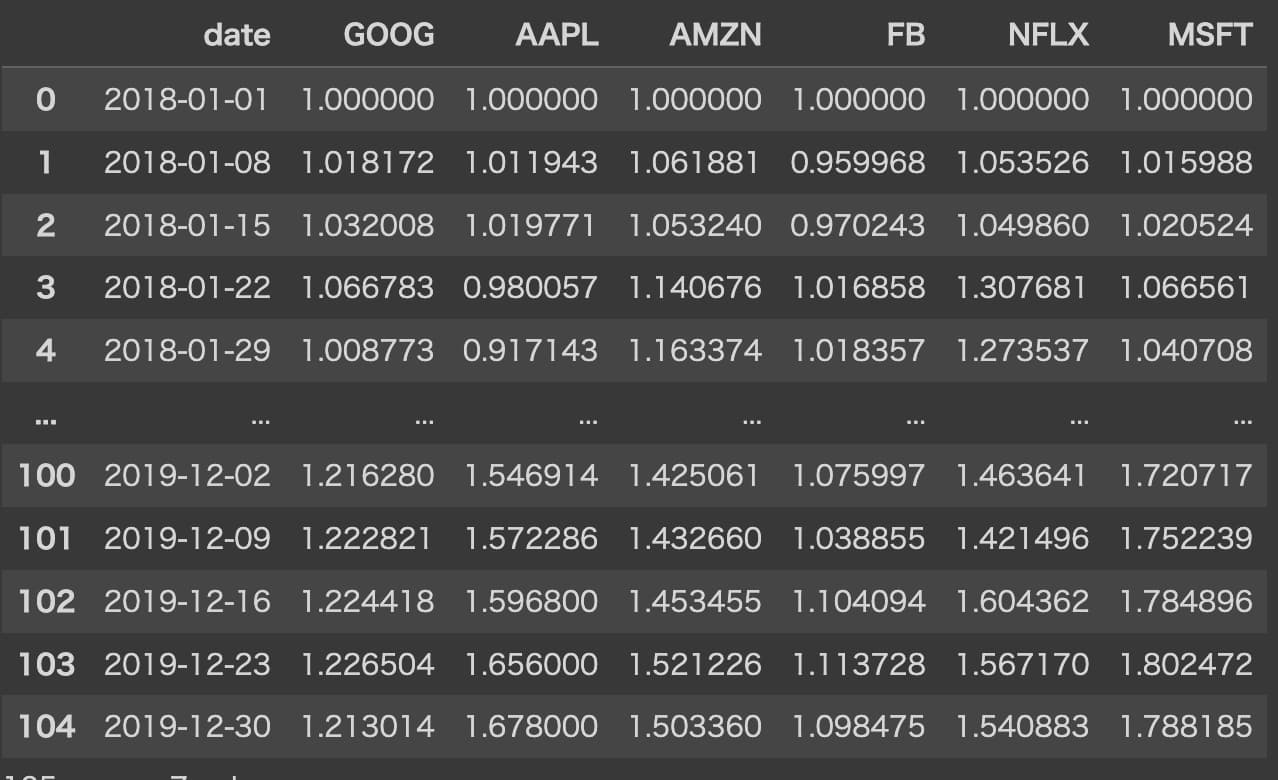
各銘柄の1週間ごとの株価が比率ベースで記載されているデータ。
Plotlyでヒストグラムを描画
それでは、まずレストランのチップデータを用いてチップの量(tip)をヒストグラムで描画します。
以下のように記載することで簡単にヒストグラムを描画することができるんです!
# ヒストグラムの作成
fig = go.Figure(data=[go.Histogram(x=tips_data_df['tip'])])
# ('tip' )列を基にヒストグラムを作成
# グラフのタイトルと軸のラベル設定
fig.update_layout(
title='チップデータのヒストグラム',# グラフのタイトル
xaxis_title='チップ',# X軸のタイトル
yaxis_title='カウント',# Y軸のタイトル
)
# ヒストグラムの表示
fig.show()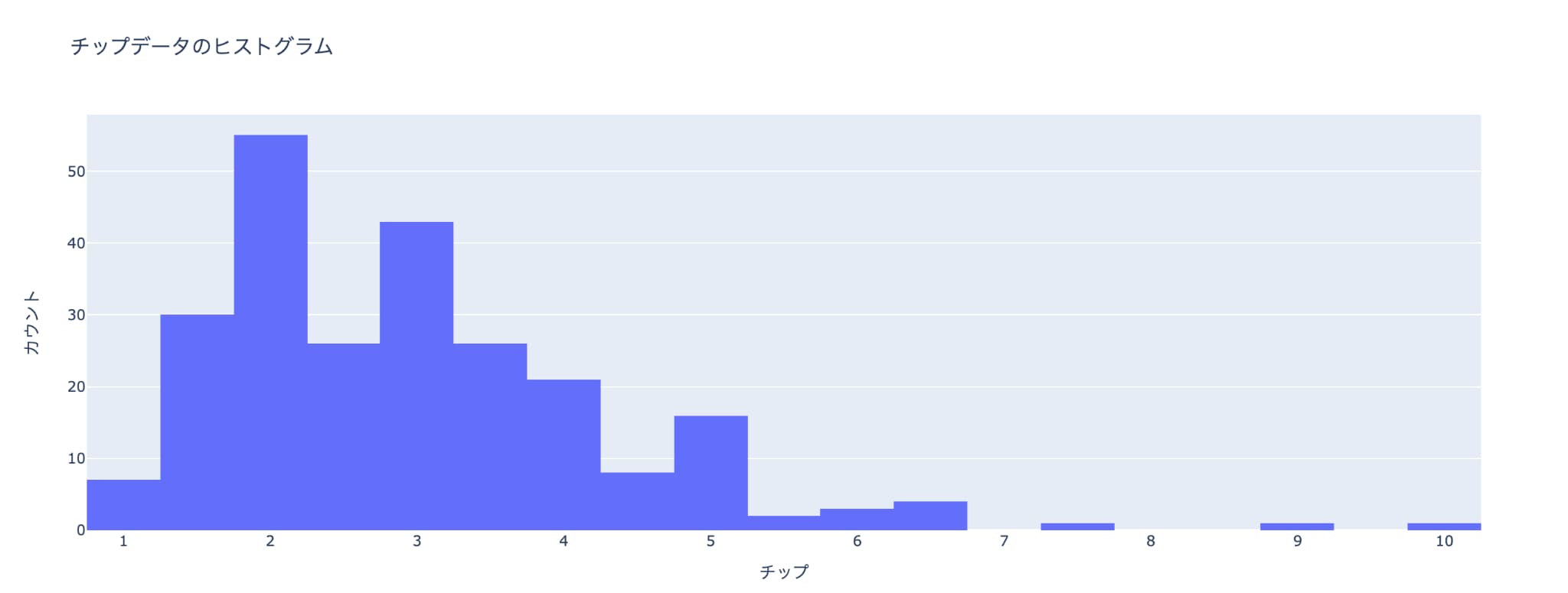
非常にシンプルに見やすいヒストグラムを描画できました。
Plotlyでは以下のようにグラフにマウスオーバーすることで情報を確認できるようになっています。
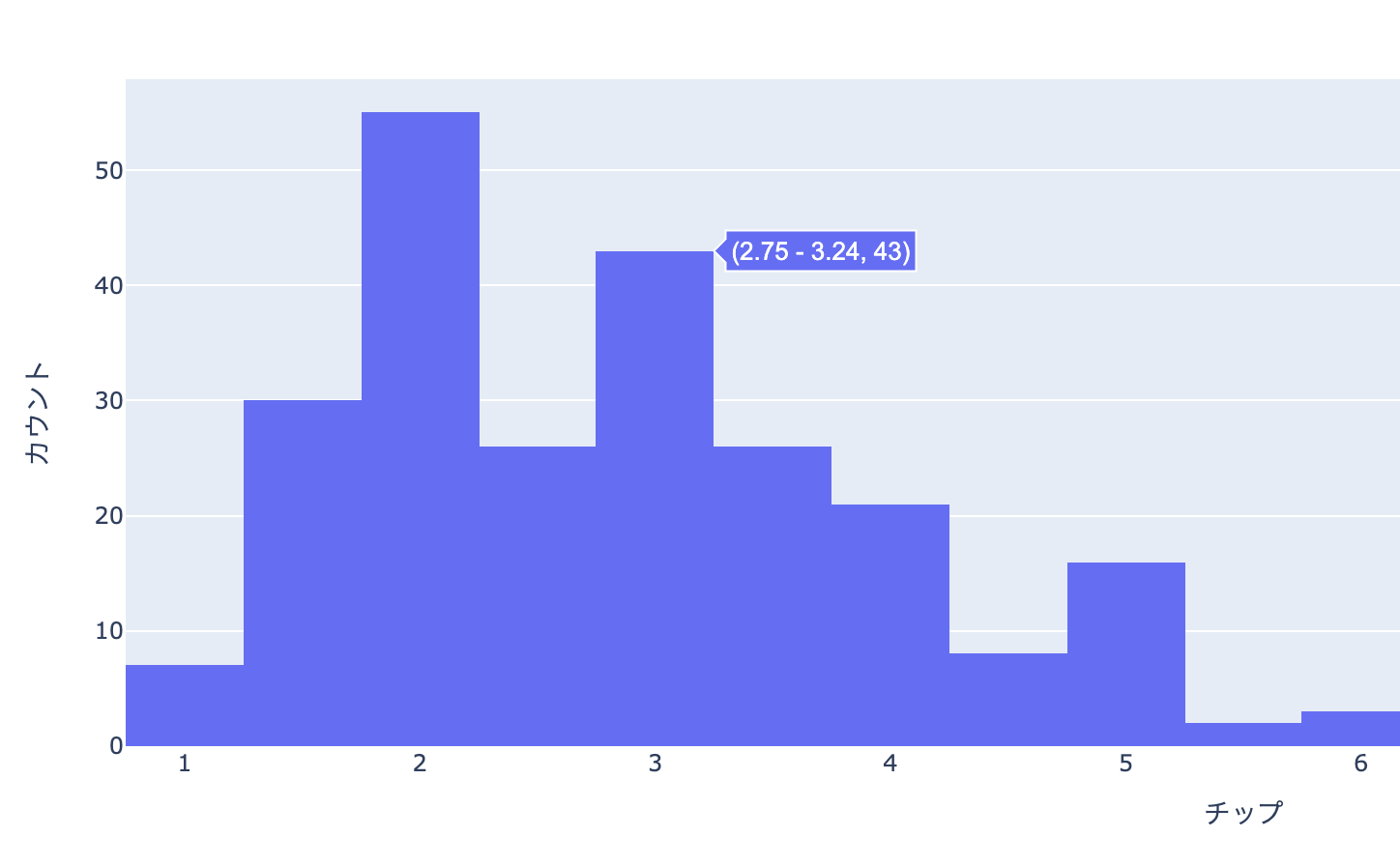
Plotlyで棒グラフの描画
続いて、レストランのチップデータを用いて、性別ごとにチップ金額の平均を計算して棒グラフを描画します。
# 性別ごとにチップの平均値を計算
grouped_data = tips_data_df.groupby('sex')['tip'].mean().reset_index()
# 'sex' 列でグループ化し、各グループにおける 'tip' の平均値を計算した後、reset_index() を用いてデータフレーム形式にリセット
# 棒グラフの作成
fig = go.Figure(
data=[
go.Bar(x=grouped_data['sex'], y=grouped_data['tip'])
]
)
# go.Bar を使用して棒グラフを作成し、X軸には性別 ('sex')、Y軸にはチップの平均値 ('tip') を設定
# グラフのタイトルと軸のラベルの設定
fig.update_layout(
title='男女別の平均チップ', # グラフのタイトル
xaxis_title='性別', # X軸のタイトル
yaxis_title='平均チップ' # Y軸のタイトル
)
# 作成した棒グラフを表示
fig.show()
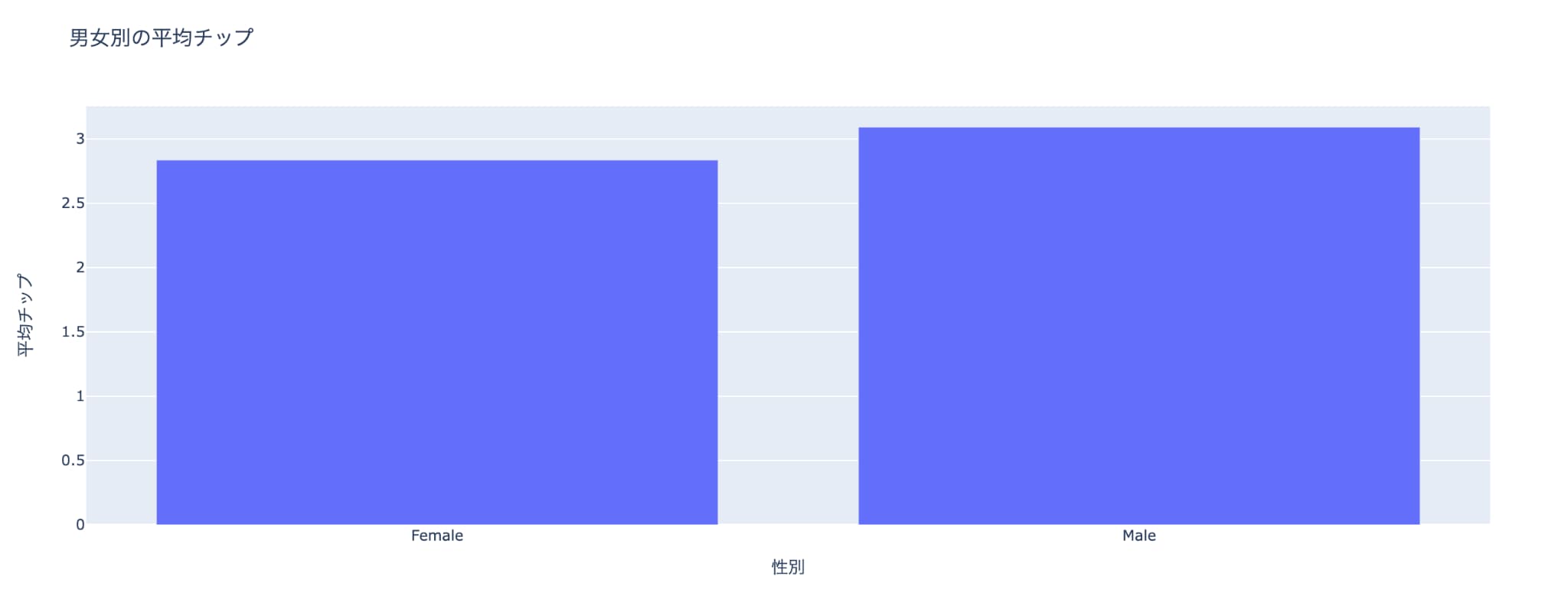
こちらの非常に簡単ですね!
Plotlyで円グラフの描画
続いてレストランのチップデータを用いて、データ全体の男女比を表す円グラフを描画します。
# 性別ごとの数を算出
grouped_data = tips_data_df.groupby('sex').count().reset_index()
# 'sex' 列でグループ化し、各グループごとの値をカウントした後、reset_index() を用いてデータフレーム形式にリセット
# 円グラフの作成
fig = go.Figure(
data=[
go.Pie(labels=grouped_data['sex'], values=grouped_data['tip'])
]
)
# go.Pie を使用して円グラフを作成し、labelsには性別 ('sex')、valuesには ('tip') を設定
# グラフのタイトルの設定
fig.update_layout(
title='男女比', # グラフのタイトル
)
# グラフの表示
fig.show()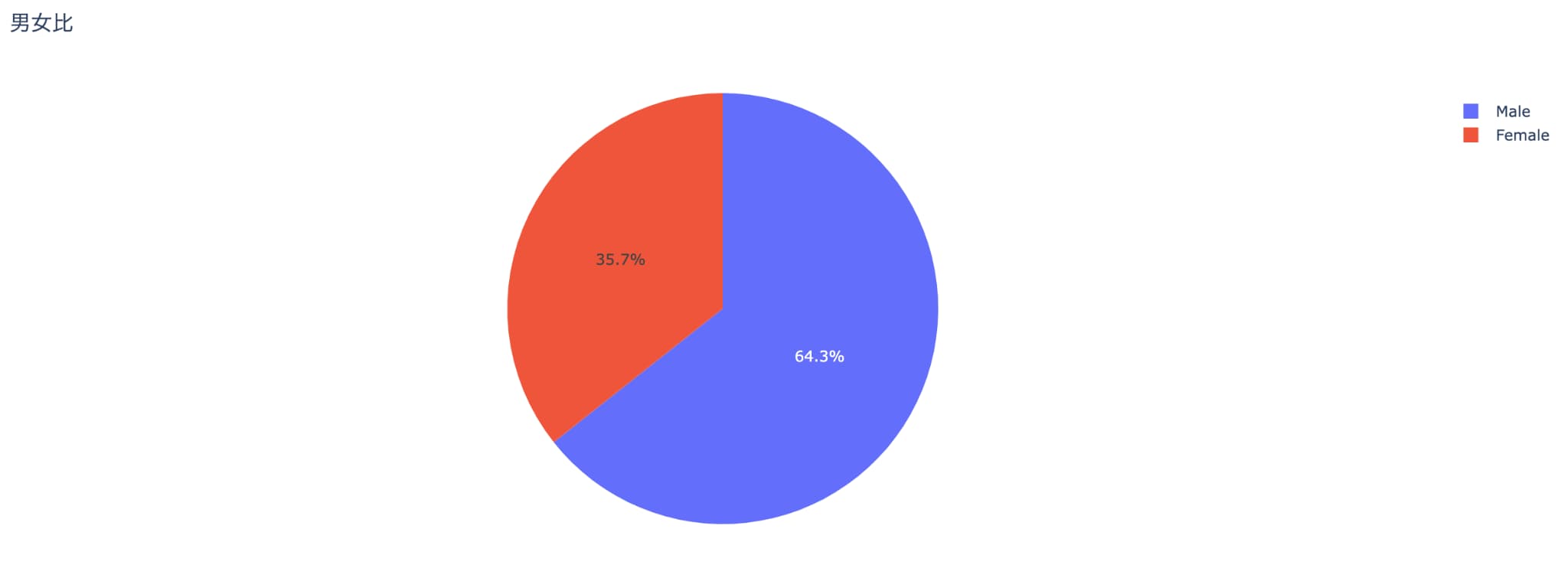
Plotlyで箱ひげ図の描画
続いて、レストランのチップデータを用いて箱ひげ図の描画します。
# 箱ひげ図の描画
fig = go.Figure(
data=[
go.Box(y=tips_data_df['tip'], name='チップ')
]
)
# go.Box を使用して箱ひげ図を作成し、y軸にはチップの平均値 ('tip') を設定
# グラフのタイトルと軸ラベルの設定
fig.update_layout(title='チップ配布の箱ひげ図',yaxis_title='チップ金額 ($)')
# グラフの表示
fig.show()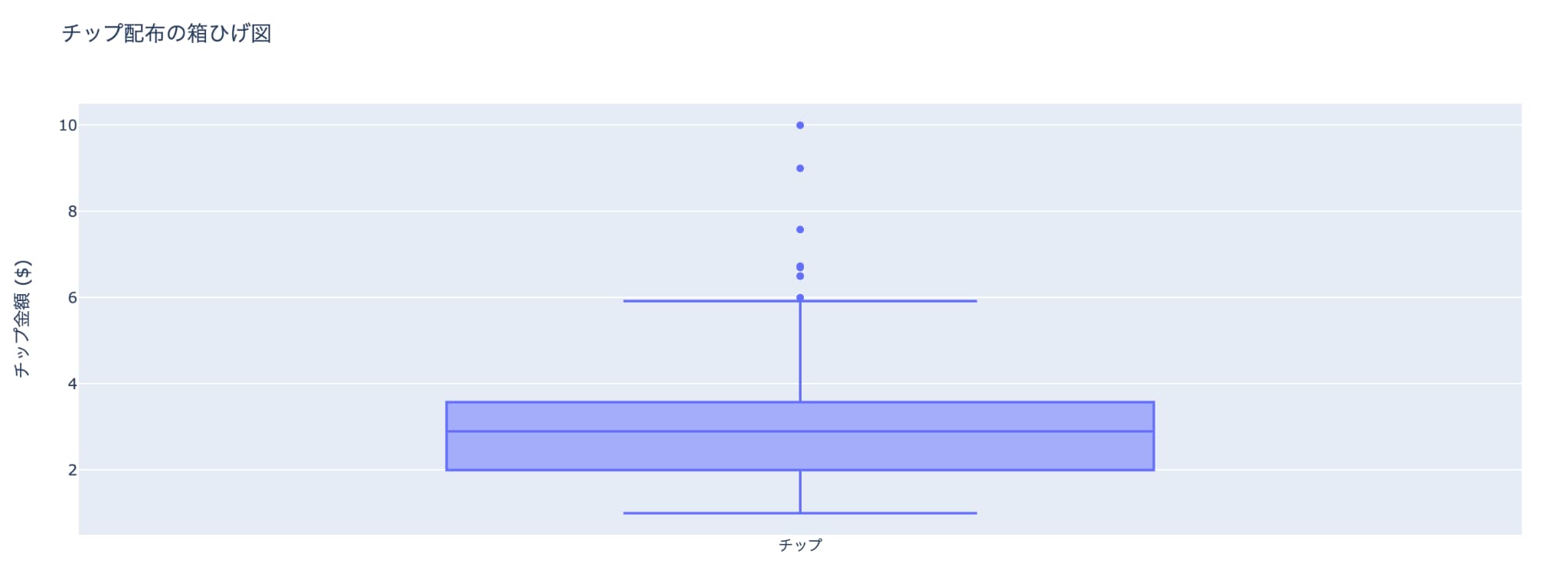
Plotlyで散布図の描画
続いて、レストランのチップデータをもとに合計金額とチップ金額の散布図を描画します。
# 散布図の作成
fig = go.Figure(
data=[
go.Scatter(x=tips_data_df['total_bill'], y=tips_data_df['tip'], mode='markers')
]
)
# go.Scatter を使用して散布図を作成し、X軸には性別 ('total_bill')、Y軸にはチップ ('tip') を設定
# グラフのタイトルと軸ラベルの設定
fig.update_layout(
title='合計請求額とチップの散布図', # グラフのタイトル
xaxis_title='合計請求額', # X軸のタイトル
yaxis_title='チップ' # Y軸のタイトル
)
# グラフの表示
fig.show()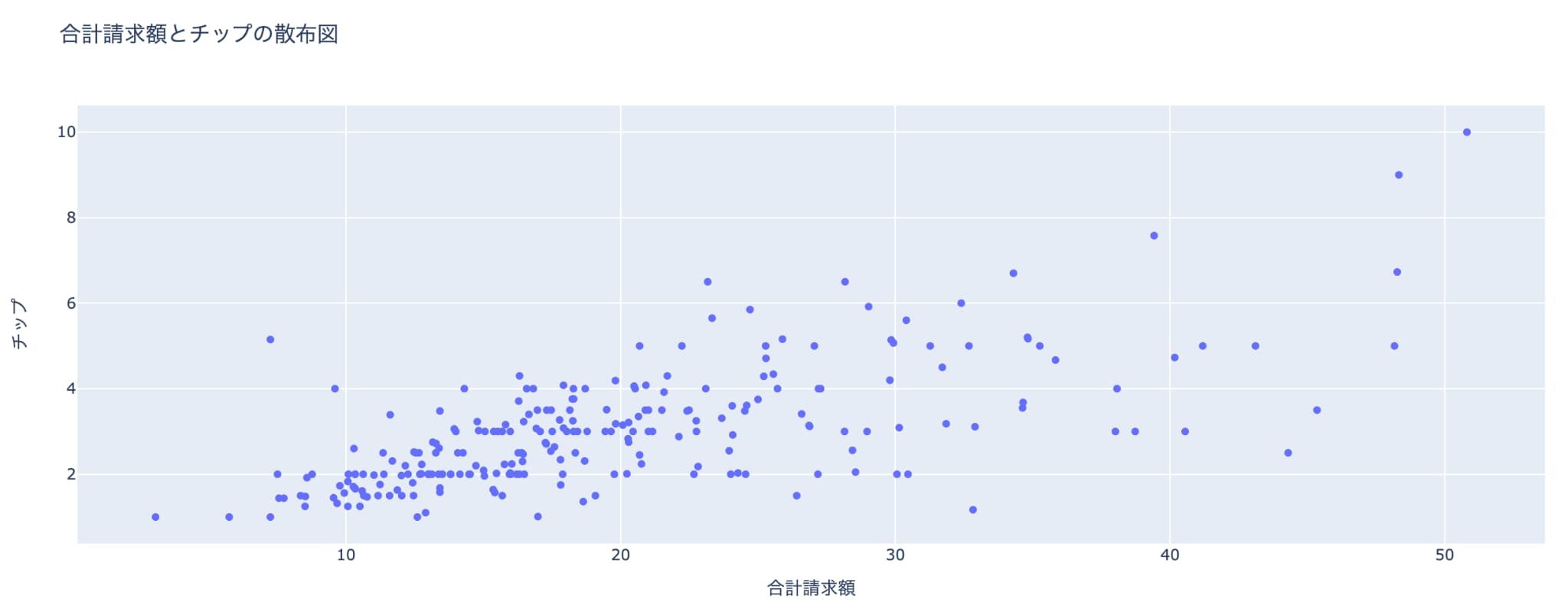
この時、散布図の引数としてmodeというものがありますが、これはデータポイントの表現方法を指定する引数です。
今回は、markersを指定していますが、他には以下のようなパターンがあります。
- markers: データポイントをマーカー(点)として表示します。
- lines: データポイントを線でつないで表示します。
- text: データポイントにテキストラベルを表示します。
- markers+lines: データポイントをマーカーと線の両方で表示します。マーカーがポイントを強調し、線がポイント間の接続を示します。
- markers+text: データポイントをマーカーとテキストラベルの両方で表示します。
- lines+text: データポイントを線とテキストラベルの両方で表示します。
- markers+lines+text: データポイントをマーカー、線、テキストラベルの全てで表示します。
シーンによって使い分けましょう!
Plotlyで折れ線グラフの描画
続いて最初に取得した株価データを用いてGoogleの株価を折れ線グラフで描画していきましょう!
# 折れ線グラフの作成
fig = go.Figure(
data=[
go.Scatter(x=stocks_data_df['date'], y=stocks_data_df['GOOG'], mode='lines+markers')
]
)
# go.Scatter を使用して折れ線グラフを作成し、X軸には性別 ('date')、Y軸にはGoogleの株価 ('GOOG') を設定
# グラフのタイトルと軸ラベルの設定
fig.update_layout(
title='Google 株価', # グラフのタイトル
xaxis_title='日付', # X軸のタイトル
yaxis_title='株価 (USD)' # Y軸のタイトル
)
# グラフの表示
fig.show()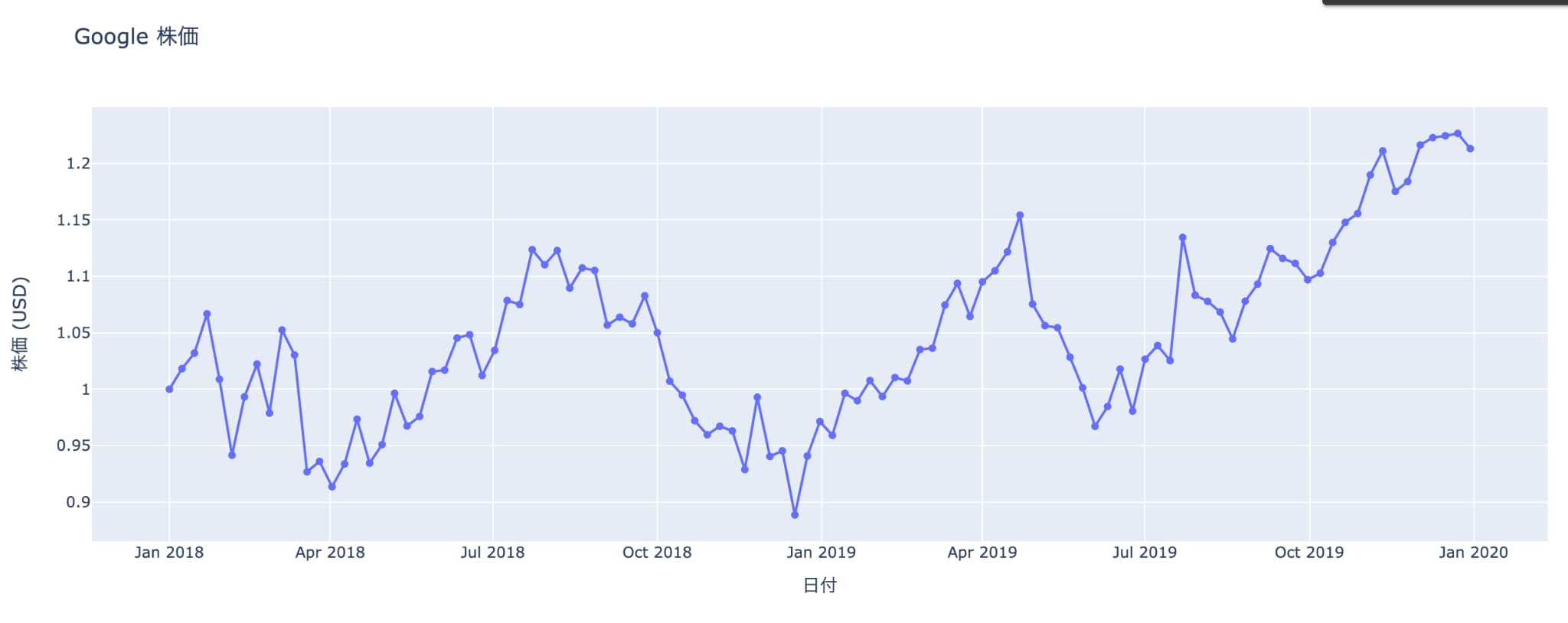
Plotlyで複数グラフの描画
Plotlyでは複数のグラフを同時に描画することも可能です!
この時、make_subplots(行数, 列数)とfig.add_trace(描画したいグラフ, 行, 列)を使って複数グラフを描画していきます。
まずmake_subplotsで全体の行列数を指定し、そこからfig.add_traceで指定した部分に描画したいグラフを差し込んでいくイメージです。
# 2x1のサブプロットを作成
fig = make_subplots(rows=2, cols=1)
# 1つ目のサブプロットにヒストグラムを追加(tipの分布)
fig.add_trace(go.Histogram(x=tips_data_df['tip'], name='チップデータのヒストグラム'), row=1, col=1)
# 2つ目のサブプロットに散布図を追加(total_billとtipの関係)
fig.add_trace(go.Scatter(x=tips_data_df['total_bill'], y=tips_data_df['tip'], mode='markers', name='合計請求額とチップの散布図'), row=2, col=1)
# レイアウトの更新
fig.update_layout(height=600, width=1000, title_text='チップと合計請求額の関係分析')
# サブプロットの表示
fig.show()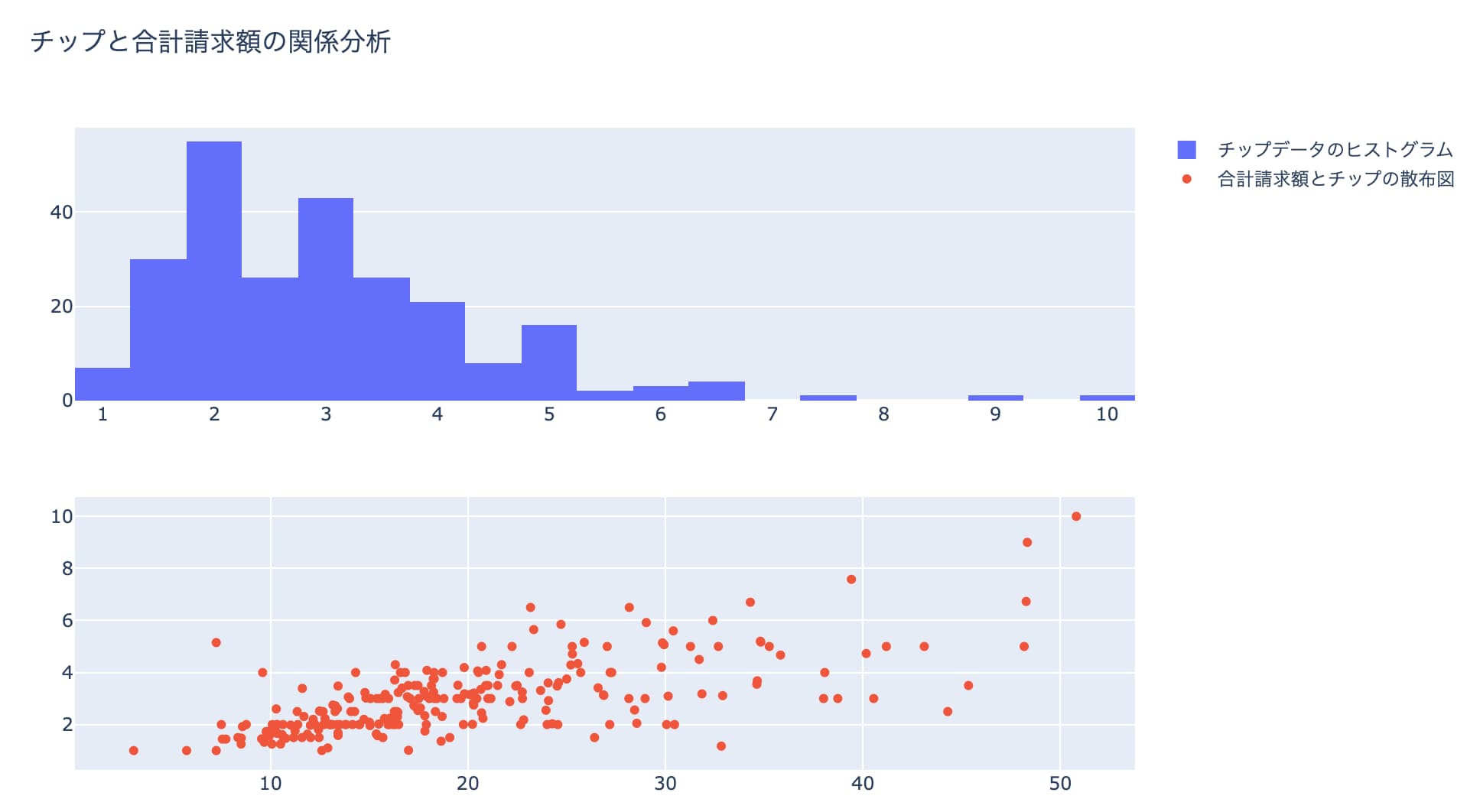
ちゃんと見やすく複数グラフを描画できているのが分かりますね!
Plotlyで3D散布図の描画
最後に3D散布図の描画方法を見ていきましょう!
ちょっと特殊なデータが必要なので取得したデータセットではなくて乱数を発生させてそれを3D散布図で描画していきます。
# データの準備
# 乱数生成のシード値を固定
np.random.seed(42)
# xyz各100個の標準正規分布に従う乱数を生成します。
x = np.random.normal(size=100)
y = np.random.normal(size=100)
z = np.random.normal(size=100)
# 各データポイントにラベルを付ける
text = [f'point {i}' for i in range(len(x))]
# 3D散布図の作成
fig = go.Figure(
data=[
go.Scatter3d(
x=x,
y=y,
z=z,
mode='markers+text',
marker=dict(
size=5, # 点のサイズ
color=z, # 色の設定
colorscale='Viridis', # 色のスケール
opacity=0.5, # 点の透明度
),
text=text, # 各データポイントに表示するテキスト
textposition='top center' # テキストの位置
)
]
)
# グラフのレイアウト設定
fig.update_layout(title='3D 散布図',# グラフのタイトル
scene=dict(
xaxis_title='X軸',# X軸のタイトル
yaxis_title='Y軸',# Y軸のタイトル
zaxis_title='Z軸',# Z軸のタイトル
))
# グラフの表示
fig.show()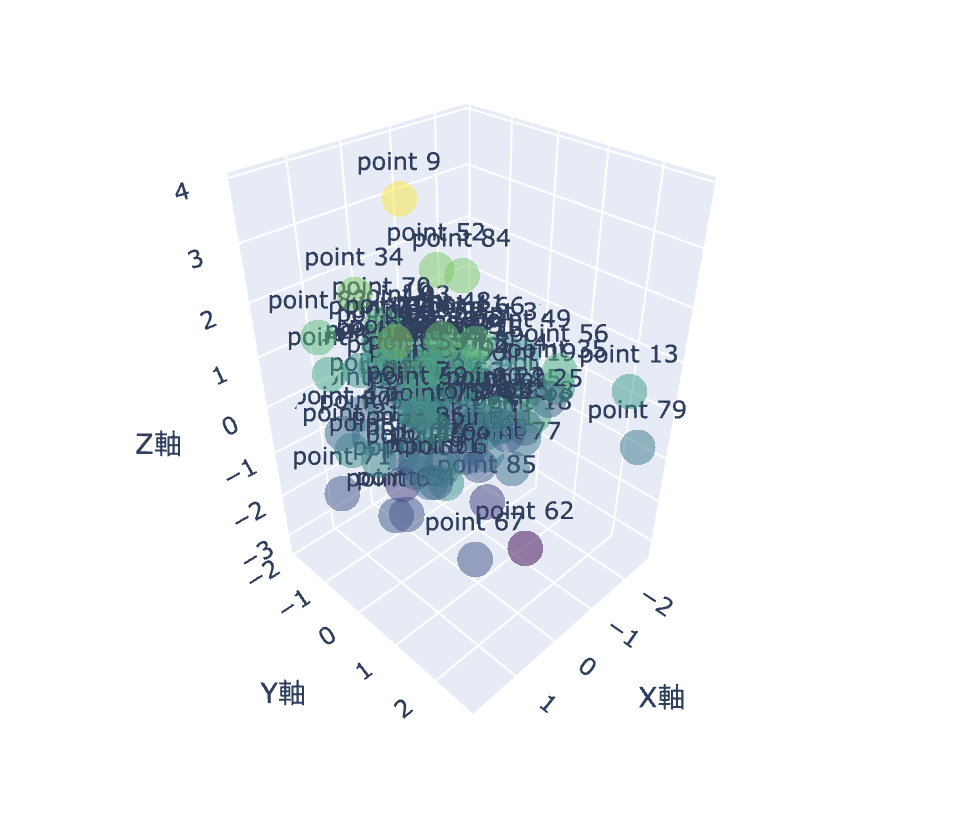
この3D散布図は、なんとマウス操作でインタラクティブに動かすことができるんです!
Plotly まとめ
ということでこの記事ではPlotlyの使い方について解説してきました。
MatplotlibやSeabornも使いやすいですが、Plotlyもぜひ使ってみてください!
以下がPlotlyの公式サイトなので興味のある方はこちらもあわせてチェックしてみましょう!
ちなみにPlotlyで作ったグラフをダッシュボードとしてWebアプリ化したい場合はPlotly社が提供するDashというライブラリを使うのが便利です。
以下で詳しくまとめていますので合わせてチェックしてみてください!

さらに詳しくPlotlyについて勉強したい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスの「株価のテクニカル指標可視化」コースでPlotlyを使った株価指標の可視化について学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















