OpenAIのEmbeddings APIを使って文章の類似度算出をPythonで実装!

こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事ではOpenAIのEmbeddings APIについてどんなことができるか実装例とともに見ていきたいと思います!
OpenAIのEmbeddings APIとは?
EmbeddingsAPIの概要について解説したOpenAIのページが以下です。
OpenAIのEmbeddings APIを使うと文章をベクトルに変換することができます。
Embeddingsは以下のようなイメージ
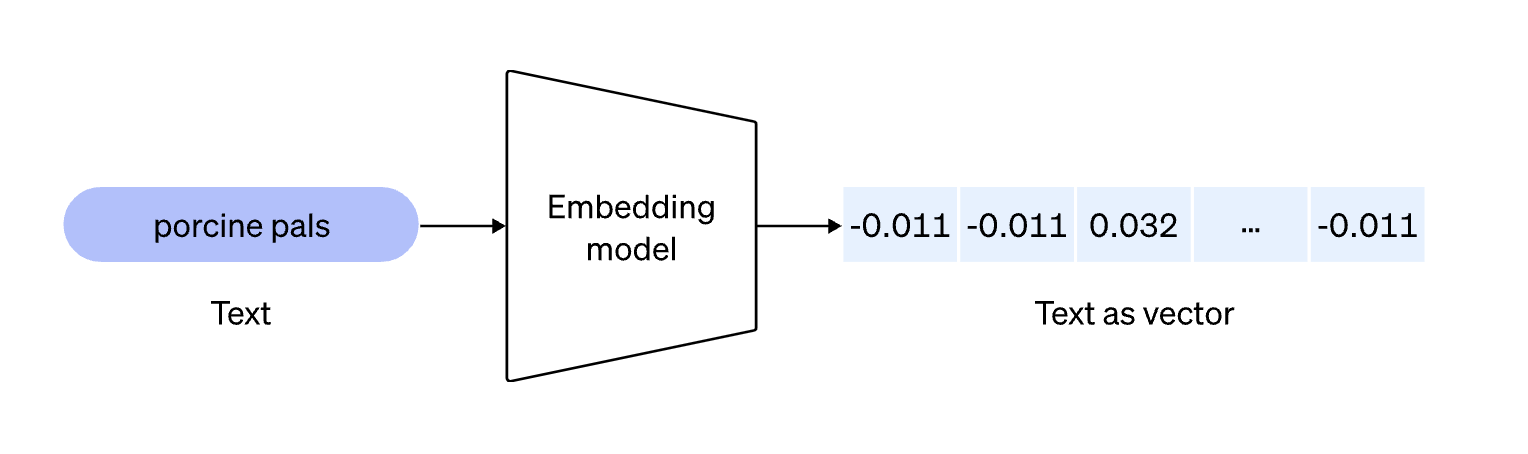
このベクトル化というのはOpenAIがEmbeddingsAPIを公開する前から存在し自然言語処理の分野では一般的な手法です。
ただそれを実装するには容量重めの辞書を用意しなくちゃいけなかったり色々面倒なのですが、OpenAIのEmbeddingsAPIを利用するだけで長文も簡単に安価にベクトル化できるのです!
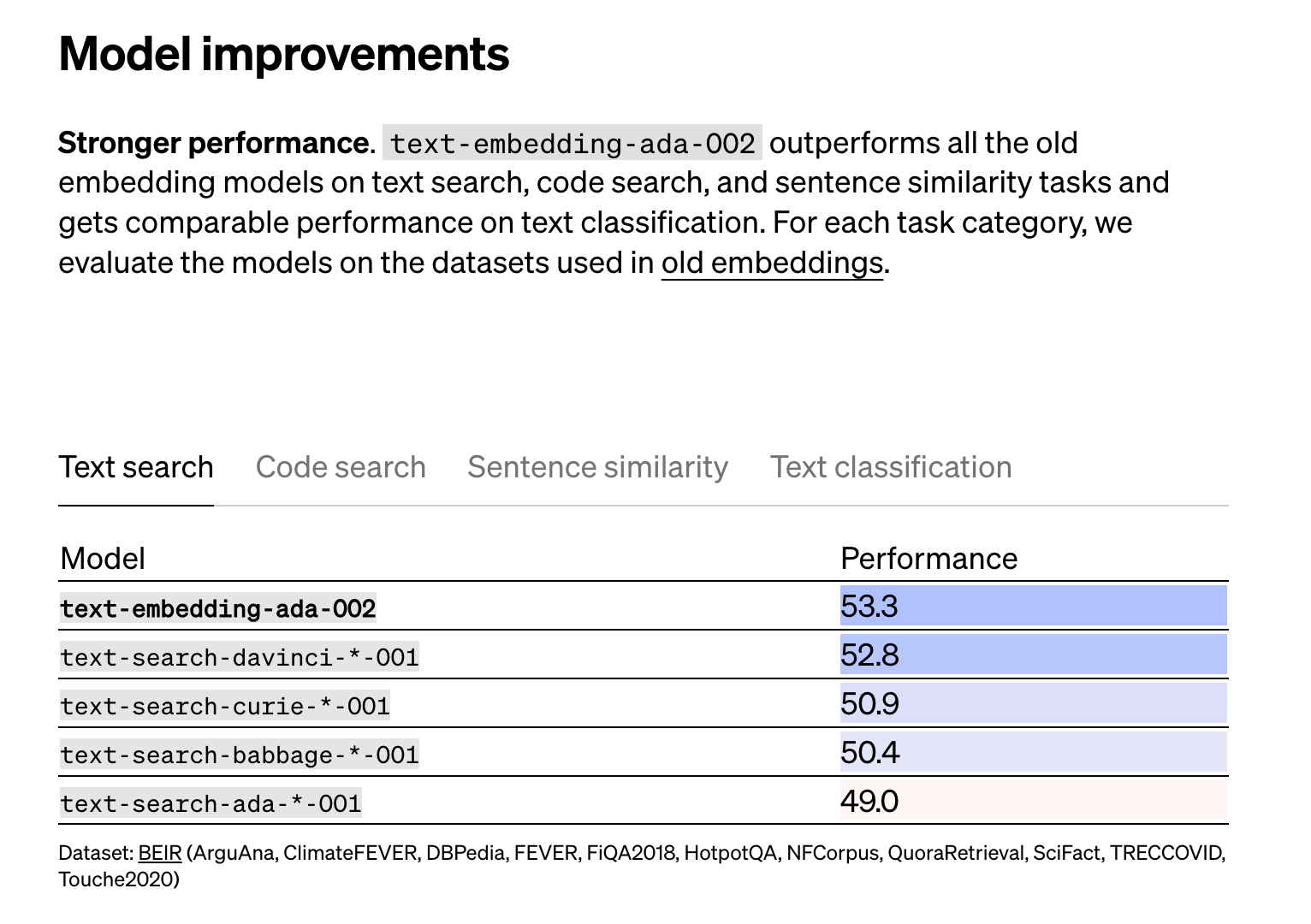
そして精度もOpenAIのEmbeddingsは高いと言われています。
実際に、いくつかの指標で検証した結果が先ほどの公式アナウンスに載っているので是非チェックしてみてください。
OpenAIのEmbeddings APIをPythonで使って類似度を算出してみよう!
それでは早速そんなOpenAIのEmbeddings APIを利用して類似度を算出してみましょう!
まず、必要なライブラリをインポートしてOpenAIのAPIキーを記述していきます。
OpenAIのAPIキーを取得していない人は公式サイトから取得しましょう。
import openai
from openai.embeddings_utils import cosine_similarity
import json
openai.api_key = "<OpenAIのAPIキー>"
続いて文章をベクトル化していきます!
以下のように記述してください。
def text_to_embedding(text):
response = openai.Embedding.create(
model= "text-embedding-ada-002",
input=[text]
)
return response["data"][0]["embedding"]ここでは、”text-embedding-ada-002″というモデルを指定して文章をベクトル化し返してくれる関数を定義しています。
それでは、文章をベクトル化していきましょう!
texts = ["吾輩は猫である", "私は猫です", "データサイエンスが好きです"]
embeddings = []
for text in texts:
embeddings.append(text_to_embedding(text))
これらの文章は何でも問題ありません。
1つ目と2つ目が類似度が高くなることを想定しています。
類似度はCos類似度という指標を使って計算していきます。
Cos類似度は簡単に言うと、それぞれのベクトルがどれくらい同じ方向を向いているかを表したもの。
単語ベクトルにCos類似度を当てはめることで文書の類似度を算出することが出来るのです!
\(A=[a_1, a_2]\)、\(B=[b_1, b_2]\)の時、Cos類似度は以下のような式で求めます!
$$ Cos類似度 = \frac{a_1b_1+a_2b_2}{\sqrt{a_1^2+a_2^2}\sqrt{b_1^2+b_2^2}} $$
これは、高校数学で習うCosとベクトルの関係式そのままです。
先ほどの単語ベクトル
[A,B,B,C]→[A:1, B:0.5, C:0.5]
[B,B,C,C]→[B:0.5, C:1]
を当てはめて見ると計算してみると、0.5477となりました。
Pythonであれば以下のように計算できますし、
import math
0.75/(math.sqrt(1.5)*math.sqrt(1.25))
25.5/(math.sqrt(26.5)*math.sqrt(26))
関数を作って以下のように計算してもよしです。
import numpy as np
def cos_sim(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
v1 = [ 1 , 0.5, 0.5]
v2 = [0, 0.5, 1]
cos_sim(v1, v2)
ここでは、せっかくなのでOpenAIのライブラリが用意しているcosine_similarityという関数を呼び出して使用していきます!
まずは、1つ目と2つ目を比較してみましょう!
cosine_similarity(embeddings[0], embeddings[ 1 ])0.9514619587040718
結果は約0.95となりました。
続いて、2つ目と3つ目を比較してみましょう!
cosine_similarity(embeddings[ 1 ], embeddings[ 2 ])0.8207195033580368
結果は約0.82となりました。
想定どおり、1つ目と2つ目の類似度が非常に高い2つ目と3つ目の類似度はそれよりだいぶ低い結果になりました。
OpenAIの公式APIドキュメントは以下になりますので参考にしてみてください!
OpenAIのEmbeddings API まとめ
ここまでで、OpenAIのEmbeddings APIを利用して文章の類似度をベクトル化する方法についてまとめてきました!
最近話題の生成系AIやLLMの実装方法についてより詳しくは当メディアが運営するスタアカの以下のコースを是非チェックしてみてください!
GPTモデルをはじめとした大規模言語モデルの理論やPythonでの扱い方などを幅広く学んでいきます!
スタアカは業界最安級のAIデータサイエンススクールです。

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
AIデータサイエンスを学んで市場価値の高い人材になりましょう!
データサイエンスやAIの勉強方法は以下の記事でまとめています。


PythonでのAPIを開発にFastAPIを使った方法を以下の記事でまとめています。

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!