【5分で分かる】実データで学ぶPythonのSeabornの使い方まとめ!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では、Pythonで頻出するデータ可視化のためのライブラリSeabornの使い方についてまとめていきたいと思います!

ぜひSeabornの基本についてしっかりおさえて扱えるようになっておきましょう!
以下のYoutube動画でも詳しく解説していますよ!
より実践的な内容に関しては当メディアが運営するオンラインスクール「スタアカ」で学べますのであわせてチェックしてみてください!

目次
Seabornとは

まずは、Seabornとは何なのか見ていきましょう!
Seabornの内部ではMatplotlibが動いているのですが、Seabornを使うことでよりきれいなグラフを簡単に描画することが可能なんです!
ただグラフの調整の仕方やルールはMatplotlibと一緒なので、Matplotlibと同時にSeabornを使えるようになりデータの可視化をおこなっていきましょう!
Seabornを使うにはMatplotlibとあわせて以下のようにSeabornのライブラリをインポートしていきます。
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()この時、sns.set()と記載しないとSeabornの描画が反映されないので注意しましょう!
MatplotlibとSeabornの違いについては以下の記事でまとめていますのでチェックしてみてください!

タイタニックのデータセットを題材にSeabornを使って可視化!

まずはタイタニックのデータセットを題材にMatplotlibを使っていきましょう!
まずは各種ライブラリをインポートしていきます。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()今回Pandasも一緒にインポートしています。
Pandasはデータフレームの処理に非常に長けているのでPythonにおいて必ず使うと言っても過言ではありません。
Seabornを使ってタイタニックのデータをインポートしていきましょう!
df = sns.load_dataset("titanic")タイタニックのデータはタイタニック号事件の乗客の生死が様々な特徴量と共に入っている有名なデータセットです。
Seabornでヒストグラムを描画
まずは、Seabornでヒストグラムを描画していきます!
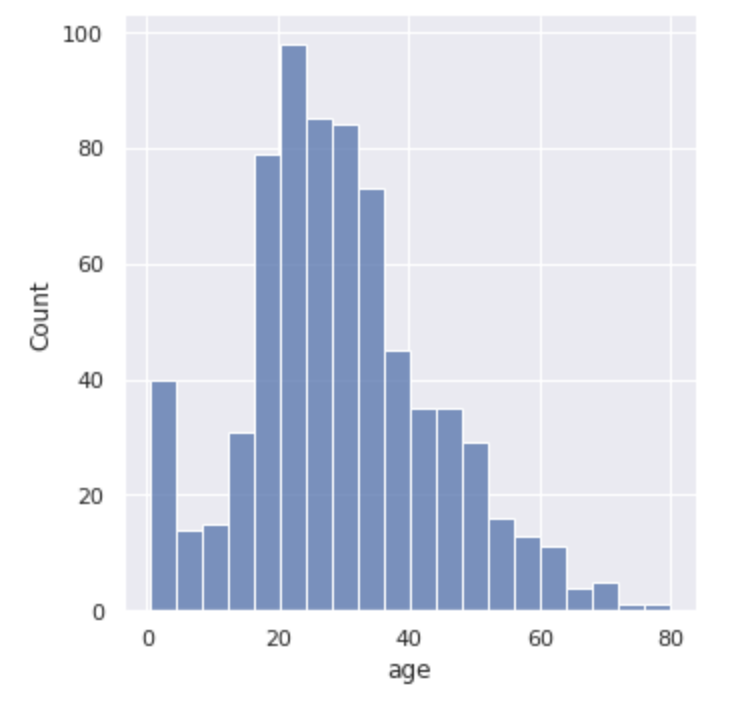
sns.displot(df["age"])
plt.show()このように記述するだけで以下のように綺麗なヒストグラムを描画することが出来ちゃうんです!
Seabornで棒グラフを描画
続いて棒グラフを描画していきます!
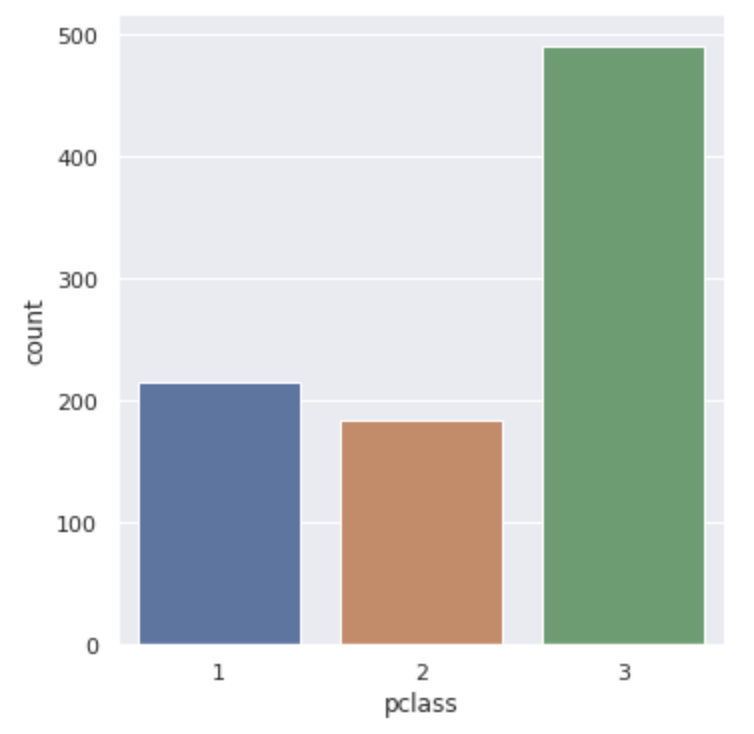
sns.catplot(x="pclass", data=df, kind="count")
# sns.countplot(x="pclass", data=df)
plt.show()pclassという乗船クラス別にどのくらいの乗客がいたのかが分かります。
この時、catplotとやってkindの引数にcountとしてあげてもいいですし、countplotを使ってあげても問題ありません。
以下のように3つのクラス別の集計値が表示されます!
続いてbarplotという棒グラフの作成方法を見ていきます。
sns.barplot(x="survived", y="age", hue="sex", data=df)
sns.catplot(x="survived", y="age", hue="sex", data=df, kind="bar")
plt.show()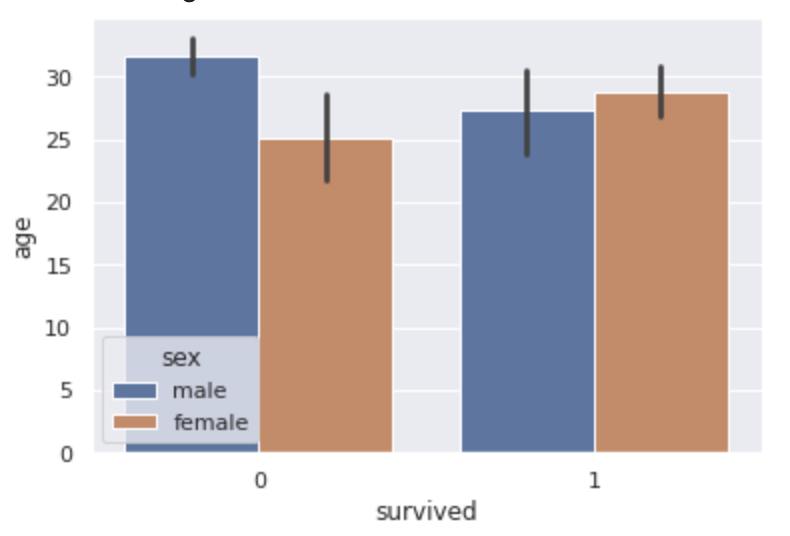
この場合は生死のデータで分けた上で年齢の平均値を棒グラフで算出しています。
さらにそれを性別で層別しています。
黒い線は95%の信頼区間を表しています。
Seabornで箱ひげ図を描画
続いて箱ひげ図を描画していきます!
箱ひげ図とは統計量をざっくり把握することの出来る便利なグラフです。

boxplotとするだけで描画を行うことが出来るんです!
sns.boxplot(x="survived", y="age", hue="sex", data=df)
sns.catplot(x="survived", y="age", hue="sex", data=df, kind="box")
plt.show()ここでは、生死別の性別別の年齢の箱ひげ図を見ていきます!
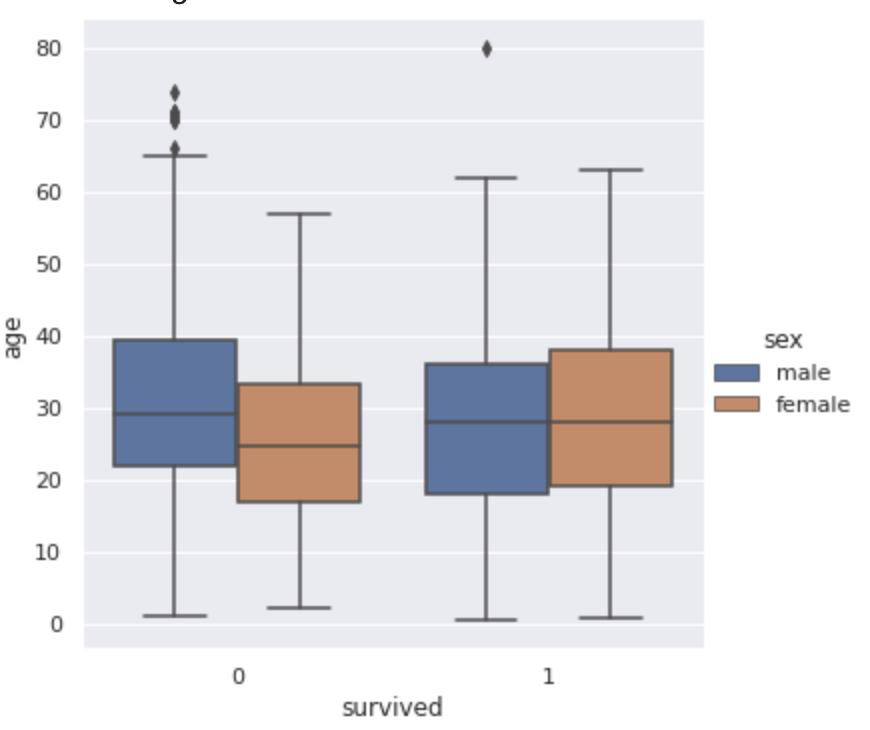
棒の一番下が最小値、一番上が最大値、そして箱の一番上が75%点、箱の真ん中の線が50%点、箱の一番下が25%点となっています!
亡くなってしまった場合と生き残った場合で男女の年齢分布がひっくり返っていることが分かりますねー!
Seabornでバイオリンプロットを描画
続いて箱ひげ図を進化させたバイオリンプロットというグラフを見ていきましょう!
violinplotとするだけで簡単にキレイなグラフが描画されます。
sns.violinplot(x="survived", y="age", hue="sex", data=df)
sns.catplot(x="survived", y="age", hue="sex", data=df, kind="violin")
plt.show()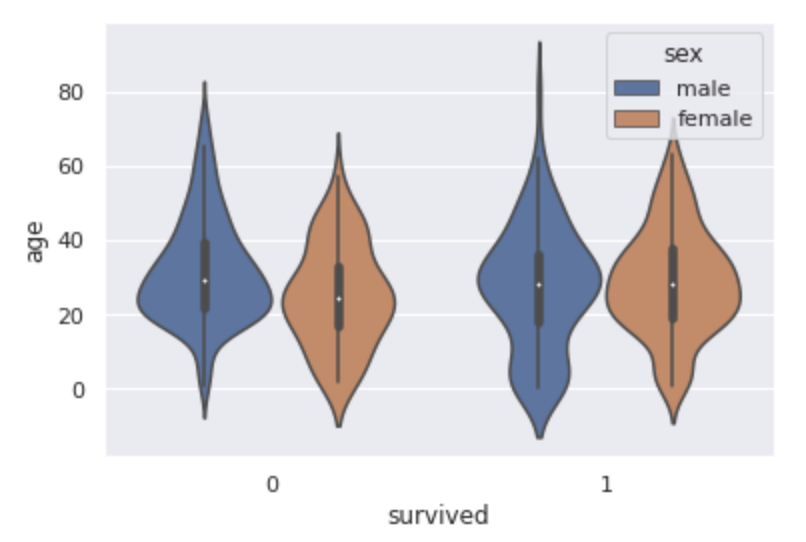
バイオリンプロットでは箱ひげ図にプラスしてサンプルの分布を表した密度関数が表示されます。
Seabornでヒストグラムと散布図を合わせたjointplot
続いてjointpotについて見ていきましょう!
sns.jointplot(x="age", y="fare", data=df)
plt.show()jointplotを使えば散布図とヒストグラムを同時に見ることができるんです!
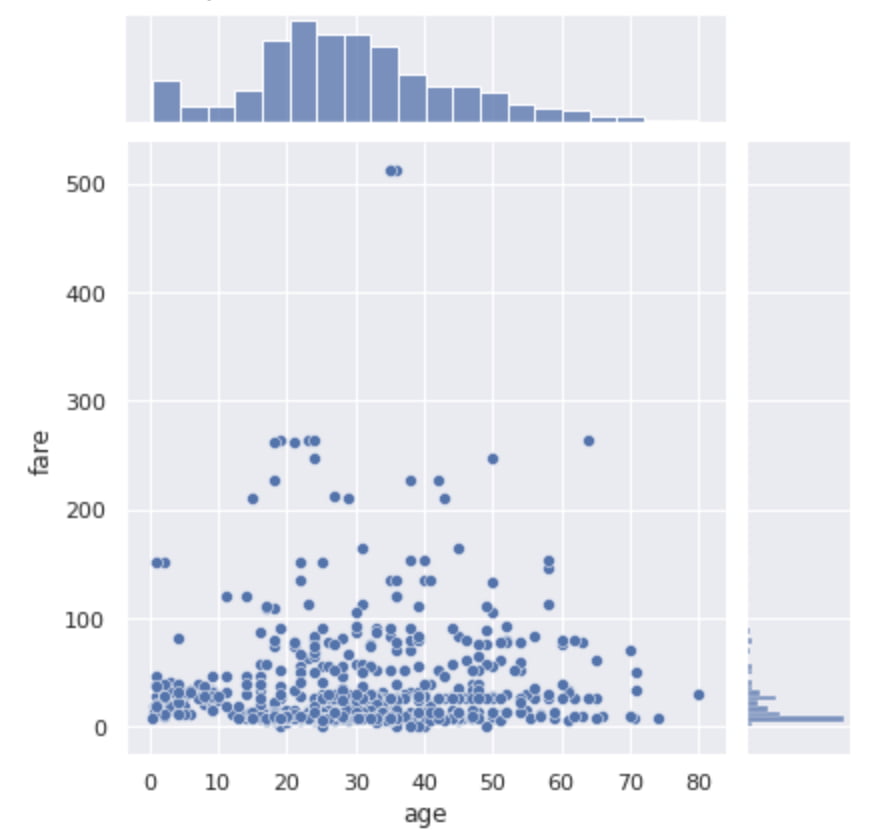
Seabornで各種変数のpairplot
続いてpairpotについて見ていきましょう!
sns.pairplot(df[["age", "fare"]])
plt.show()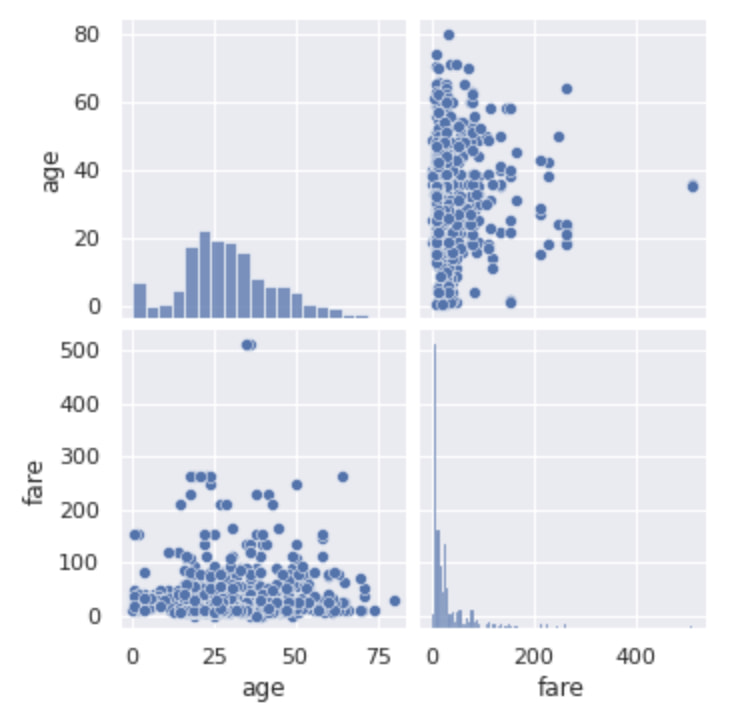
こんな感じでjointplotとほぼ同じように見えますが、これ実は変数が多くても問題ないんです。
タイタニックのデータだと量的変数が少ないのでirisのデータを利用して見てみましょう!
df = sns.load_dataset("iris")
sns.pairplot(df)
plt.show()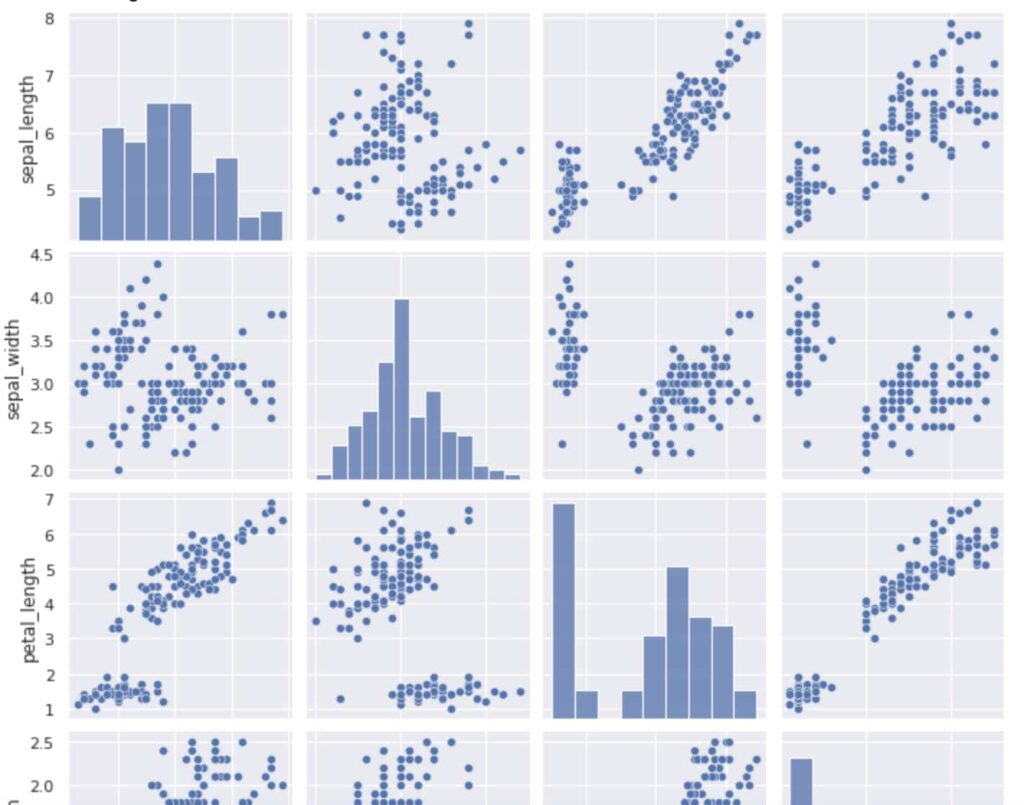
こんな感じになります!
Seabornでヒートマップを描画
続いてヒートマップを描画していきます!
今回はirisデータよりもさらに量的変数の量が多いボストンの住宅価格のデータを扱っていきます!
from sklearn.datasets import load_boston
boston = load_boston()
df = boston.data
df = pd.DataFrame(df, columns = boston.feature_names)
sns.heatmap(df.corr())
plt.show()df.corr()で簡単に各変数の相関係数を表示することができ、それをSeabornで簡単にヒートマップとして表示することが出来るんです!
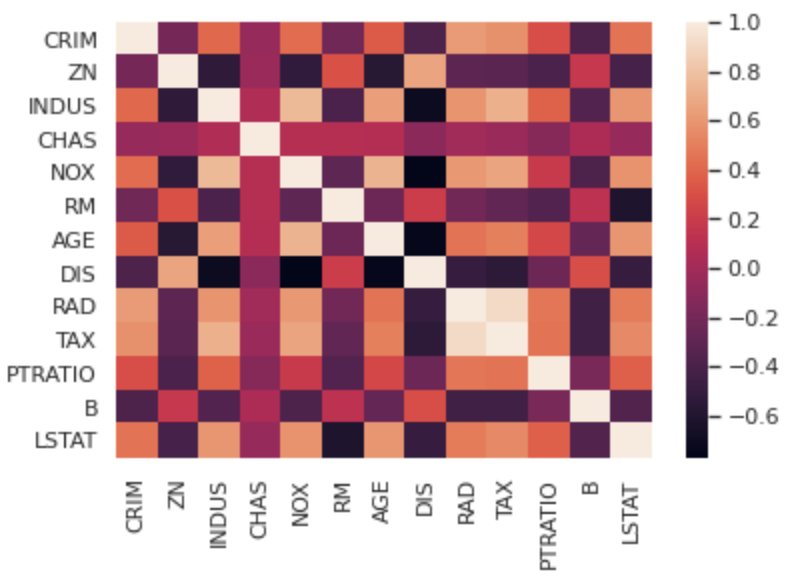
これで多変数の相関関係も一目瞭然ですね!
ヒートマップは相関関係だけでなく多変量時系列データなどの値の強弱を見るのに使ったりします!
データコンペのデータを題材にSeabornを使って可視化!

続いてより実践的なデータ分析コンペのデータを使ってSeabornによる可視化を行っていきます。
![]()
![]() Nishikaというデータコンペプラットフォームの中の「中古マンション価格」データを使います。
Nishikaというデータコンペプラットフォームの中の「中古マンション価格」データを使います。
![]()
![]() Nishikaに会員登録をして「中古マンション価格」データからtrain.zipをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
Nishikaに会員登録をして「中古マンション価格」データからtrain.zipをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
train.zipを開くと中には以下のように複数のCSVファイルが入っています。
今回はこれらをデータフレームとして結合させるところからデータの確認・可視化をおこなっていきます。
そのためにSeaborn以外のライブラリも必要になるのでImportしてあげましょう!
import glob
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlineglobはディレクトリに格納されたファイル名を抽出するのに便利なライブラリで、今回は複数のファイルがtrainフォルダ内にデータとして格納されているのでそれらのファイル名を抽出するのに必要になります。

現在trainというフォルダにファイルが入っているとすると、以下のように記述することでtrain内のファイル名を全て抽出することができます。
files = glob.glob("train/*.csv")この時、*はワイルドカードと呼ばれ、このようにワイルドカードを指定することで全てのファイル名を該当させることができます。
filesを見てみると以下のようになっていることが分かります。
[‘train/40.csv’,
‘train/41.csv’,
‘train/43.csv’,
‘train/42.csv’,
‘train/46.csv’,
‘train/47.csv’,
‘train/45.csv’,
‘train/44.csv’,
‘train/37.csv’,
‘train/23.csv’,
‘train/22.csv’,
・・・
各ファイル名がリスト形式で格納されていることが分かります。
このデータフレームの中身を見てみると・・・
pd.read_csv(files[0])以下のようになっていることが分かります。
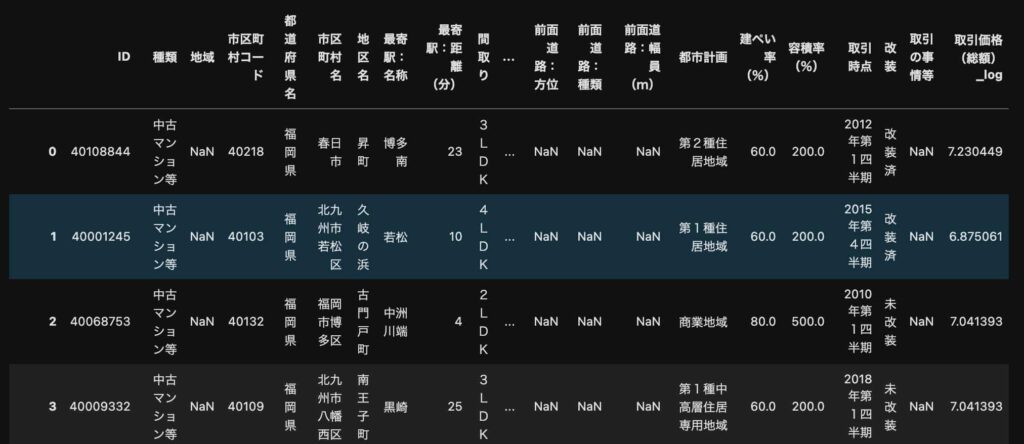
各ファイルそれぞれの格納されているサンプル数は違いますが、全て同じカラムになっています。
そのため、これらのデータをfor文で回して結合させ1つのデータフレームにしていきましょう!
data_list = []
for file in files:
data_list.append(pd.read_csv(file, index_col=0))
df = pd.concat(data_list)これにて使うデータの準備が完了です。

データが結構汚いので詳細は割愛しますが、前処理をおこなっていきます。

全てが欠損値になっているカラムを削除して、「最寄り駅・面積・建築年・取引時点」に関して変換をおこなっています。
def data_pre(df):
nonnull_list = []
for col in df.columns:
nonnull = df[col].count()
if nonnull == 0:
nonnull_list.append(col)
df = df.drop(nonnull_list, axis=1)
df = df.drop("市区町村名", axis=1)
df = df.drop("種類", axis=1)
dis = {
"30分?60分":45,
"1H?1H30":75,
"2H?":120,
"1H30?2H":105
}
df["最寄駅:距離(分)"] = df["最寄駅:距離(分)"].replace(dis).astype(float)
df["面積(㎡)"] = df["面積(㎡)"].replace("2000㎡以上", 2000).astype(float)
y_list = {}
for i in df["建築年"].value_counts().keys():
if "平成" in i:
num = float(i.split("平成")[1].split("年")[0])
year = 33 - num
if "令和" in i:
num = float(i.split("令和")[1].split("年")[0])
year = 3 - num
if "昭和" in i:
num = float(i.split("昭和")[1].split("年")[0])
year = 96 - num
y_list[i] = year
y_list["戦前"] = 76
df["建築年"] = df["建築年"].replace(y_list)
year = {
"年第1四半期": ".25",
"年第2四半期": ".50",
"年第3四半期": ".75",
"年第4四半期": ".99"
}
year_list = {}
for i in df["取引時点"].value_counts().keys():
for k, j in year.items():
if k in i:
year_rep = i.replace(k, j)
year_list[i] = year_rep
df["取引時点"] = df["取引時点"].replace(year_list).astype(float)
for col in ["都道府県名", "地区名", "最寄駅:名称", "間取り", "建物の構造", "用途", "今後の利用目的", "都市計画", "改装", "取引の事情等"]:
df[col] = df[col].astype("category")
return df
df = data_pre(df)
これでデータがだいぶ綺麗になりました!
時系列でcountplotして変化を見る
先ほどタイタニックのデータで扱った処理を一部おこなっていきましょう!
時系列でデータ数にどのくらいの変化があるのかcountplotで見ていきましょう!
Seabornのcountplotを使ってデータ量を綺麗に描画して見ていきます。
fig, axes = plt.subplots(2, 1, figsize=(20,10))
df["取引年"] = df["取引時点"].apply(lambda x:str(x)[:4])
sns.countplot(x="取引年", data=df.sort_values("取引年"), ax=axes[0])
sns.countplot(x="取引時点", data=df, ax=axes[1])
複数プロットの場合はsubplotsを使って描画することが可能です。
そしてseabornで描画する場合は引数axを指定してあげて描画の箱を制御します。
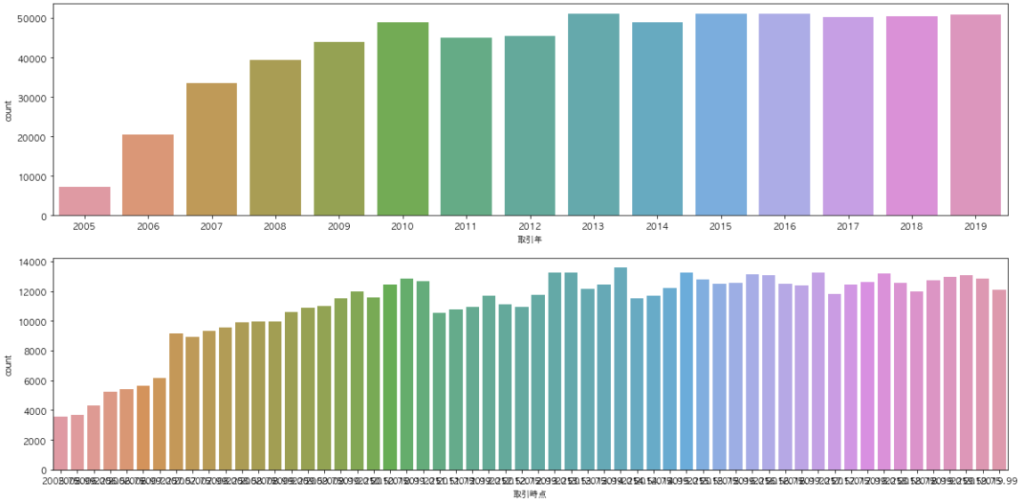
この時、取引時点をそのまま描画しているものと、取引時点の4半期データを年単位に丸めたデータを描画しています。
データが見やすく並んでいることが分かります。
2005年から2010年までは取引量が線形で伸びていて、それ以降は横ばいであることが分かります。
変数間の相関をヒートマップで見てみる
続いて先ほど使ったヒートマップを適用させてみましょう!
実際にどのくらい関係があるかは相関係数を算出して見ることができます!
相関係数には負の相関と正の相関があり、-1から+1の範囲で見ることが出来ます。
以下のように記述することで各変数の相関係数を算出することが出来ます。
df[["取引価格(総額)_log", "最寄駅:距離(分)", "面積(㎡)", "建築年"]].corr()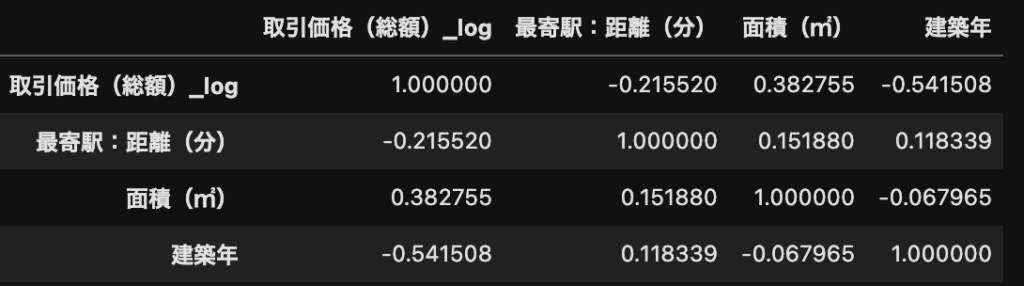
corrは相関(correlation)を表しています。
このそれぞれの相関関係をヒートマップで見てみましょう。
ここでSeabornの出番です。
sns.heatmap(df[["取引価格(総額)_log", "最寄駅:距離(分)", "面積(㎡)", "建築年"]].corr())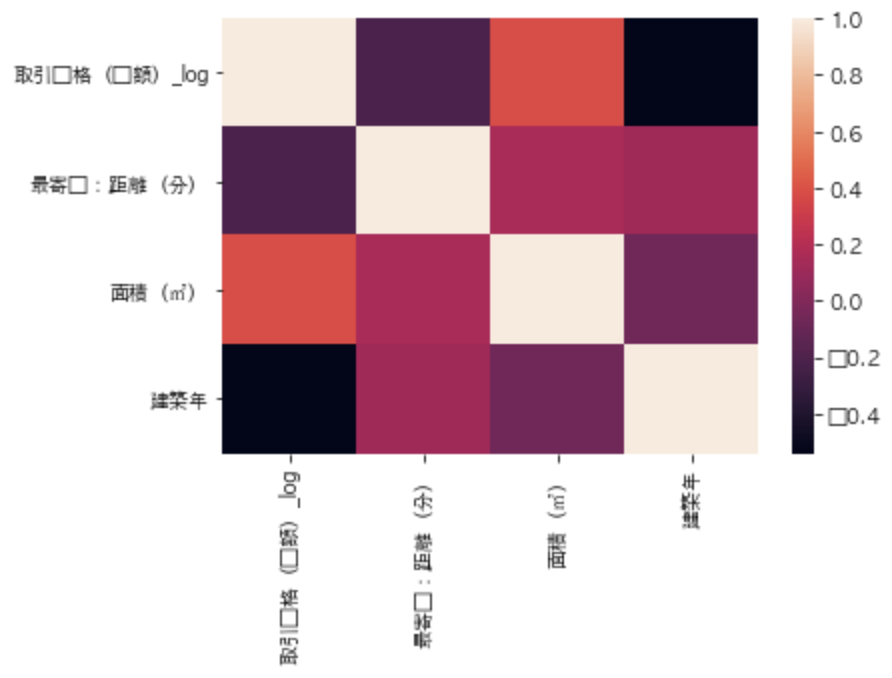
このケースでは変数が少ないのでヒートマップにしなくても問題ないですが、変数がものすごい量になってくるとヒートマップを描画してあげることで見やすくなります。
また引数cmapを指定してあげることでカラーレイアウトを変更することも可能です。
sns.heatmap(df[["取引価格(総額)_log", "最寄駅:距離(分)", "面積(㎡)", "建築年"]].corr(), cmap="Reds")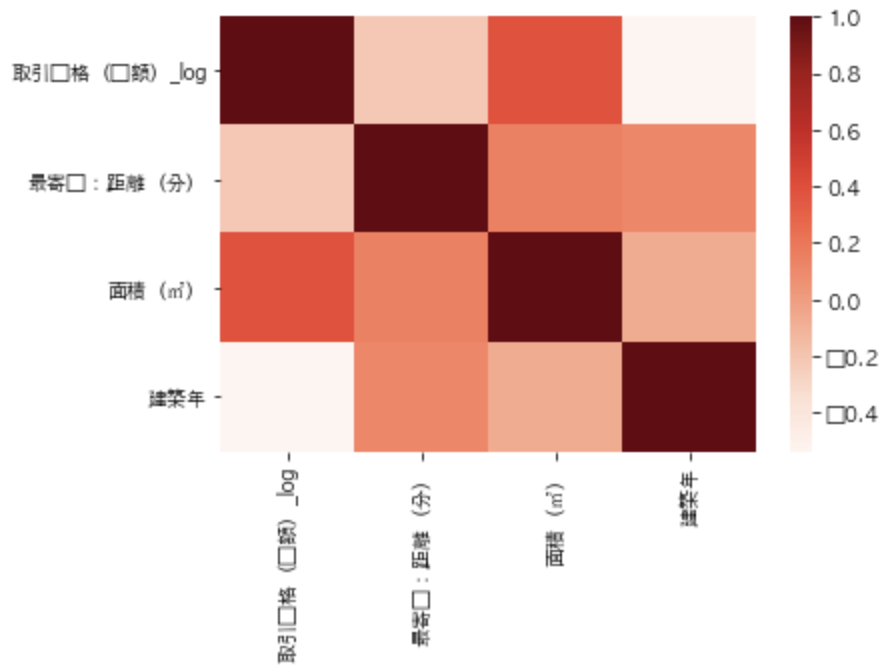
この場合、cmapにRedsを指定してあげています。
ぜひヒートマップを駆使していきましょう!
ちなみに日本語だと上手く表示されないので事前にMatplotlibの内部フォントを以下のように変更しておいてあげるとよいでしょう!
import matplotlib
matplotlib.rcParams["font.family"] = "AppleGothic"
他にも色んなことができるので実際にデータコンペのデータを使って色々とSeabornを試してみてください!
Seabornの使い方 まとめ
本記事ではSeabornの使い方についてまとめてきました。
Seabornので様々なグラフが綺麗に描画が出来るということが少しでも理解いただけたと思います。
データを可視化する際にはMatplotlibも重要ですが、さらにSeabornも使えるようになっておきましょう!
他にもPythonで出来ることはたくさんあります。
Pythonについて詳しく学びたい方は以下のUdemyの講座で僕自身が講師を務めていますので是非チェックしてみてください!
【実践】ビジネスケースとつなげてPythonで出来ること5つを学べる3日間集中コース
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 3.5時間 |
| 【レベル】 | 初級~中級 |
手前味噌ですが、まずPythonについて理解してみるのにオススメなコースを僕自身が出しています!
Pythonで出来ることのうち以下の5つを網羅して学んでいきます。
・データ集計・加工・描画
・機械学習を使ったモデル構築
・Webスクレイピング
・APIの利用
・Webアプリケーション開発
データ集計・加工・描画と機械学習モデル構築に関してはKaggleというデータ分析コンペティションのWalmartの小売データを扱いながら学んでいきます。
WebスクレイピングとAPI利用とWebアプリケーション開発に関しては、楽天の在庫情報を取得してSlackに自動で通知するWebアプリケーションを作成して学んでいきます。
Pythonで何ができるのか知りたい!という方には一番はじめにまず受けていただきたいコースです!
Twitterアカウント(@statistics1012)にメンションいただければ1500円になる講師クーポンを発行いたします!
また、Pythonで出来ることを知りたい場合は以下の記事でまとめていますので是非チェックしてみてください!

また、Pythonの勉強法については以下の記事で詳しくまとめています!

またPythonを使ってデータサイエンス全般について学んで、強いデジタル人材になるためのスクール「スタアカ(スタビジアカデミー)」を当メディアで展開しておりますのでチェックしてみてください!
以下のような内容が主に学べます!!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!