
【徹底解説】PyCaret(パイカレット)とは?使い方を解説!


こんにちは!
消費財メーカーでデータサイエンティスト・デジタルマーケターをやっているウマたん(@statistics1012)です!
機械学習を簡易的に実装できる素晴らしいライブラリ「PyCaret」!!
PyCaretを使えば
・今まで複数ある機械学習手法のうちどれを使えばよいのか分からなかった
・手法をいくつか実装して比較することに時間をかけていた
みたいなことはほとんどなくなります!

PyCaretの威力を知って、いくつかの機械学習を実装してみましょう!
PyCaretに関しては以下のYoutube動画でも解説していますので是非チェックしてみてください!
目次
PyCaretとは
PyCaretとは機械学習をいとも簡単に扱える超絶優秀なライブラリです。
2020年4月にリリースされました。
We are excited to announce PyCaret, an open source machine learning library in Python to train and deploy supervised and unsupervised machine learning models in a low-code environment. PyCaret allows you to go from preparing data to deploying models within seconds from your choice of notebook environment.
(引用元:Announcing PyCaret 1.0.0)
普段使用しているPython環境で、いとも簡単に数行だけのコードで様々な機械学習モデルを比較して精度比較することが出来ます。
In comparison with the other open source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with few words only. This makes experiments exponentially fast and efficient. PyCaret is essentially a Python wrapper around several machine learning libraries and frameworks such as scikit-learn, XGBoost, Microsoft LightGBM, spaCy, and many more.
(引用元:Announcing PyCaret 1.0.0)
一般的な機械学習手法から勾配ブースティング手法、自然言語処理手法まで幅広く網羅しているんです!
今までPythonで実装できる機械学習ライブラリとしてはScikit-learnが一般的でした。
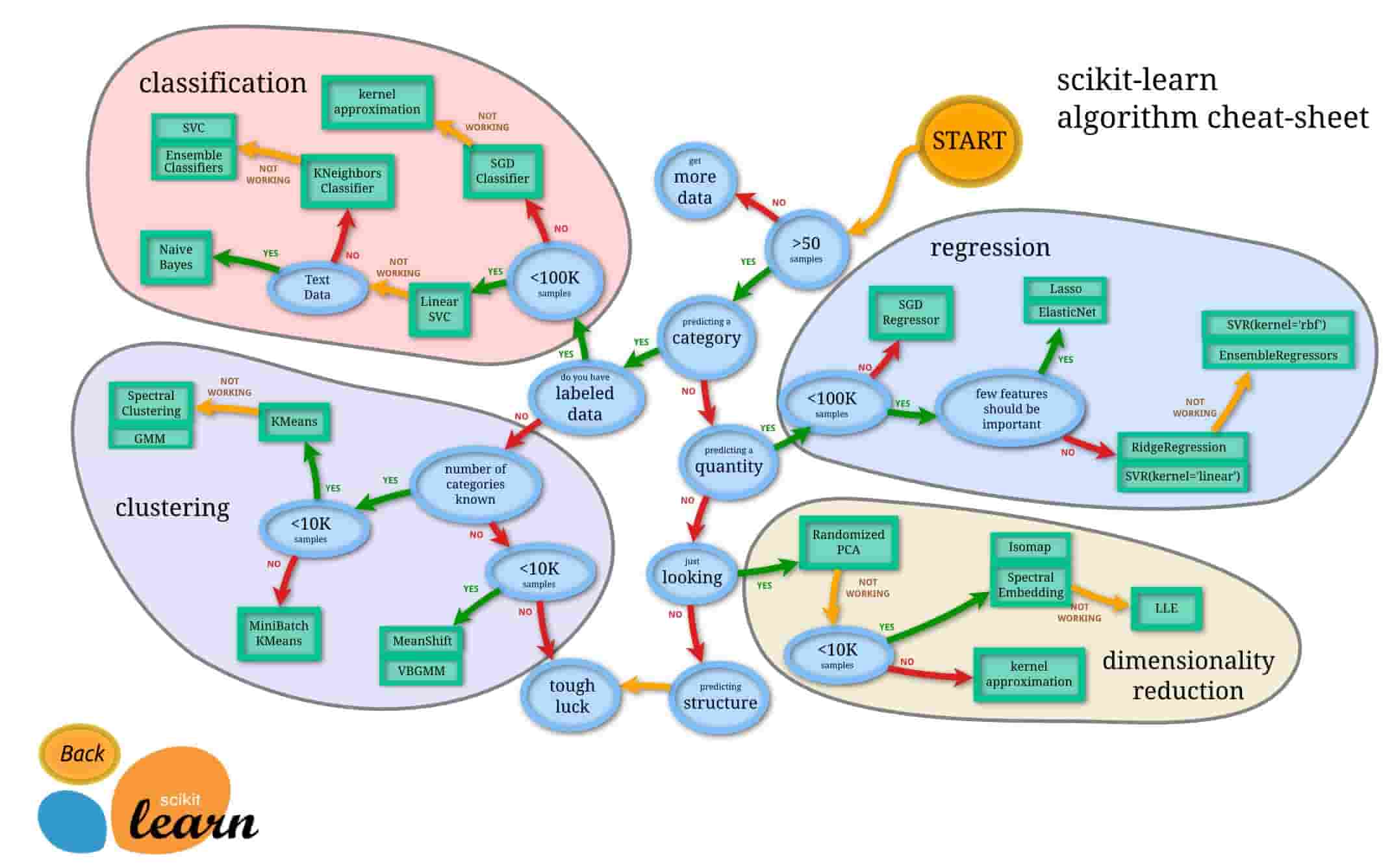 出展:https://scikit-learn.org/stable/tutorial/machine_learning_map/
出展:https://scikit-learn.org/stable/tutorial/machine_learning_map/
しかしScikit-learnは最新の勾配ブースティング手法をカバーしておらず、あくまで使いたい手法を呼んできて使うという方法を取らなくてはいけませんでした。
そんな中、なんとPyCaretでは、たった一行で様々な手法での精度を比較することが出来るのです。
それでは実際にどのようにPyCaretを実装することができるのか見ていきましょう!
PyCaretを実装してみよう

ここではGoogle Colaboratoryという実行環境を使っていきます。
Google ColaboratoryとはGoogleが無料で提供してくれているクラウド実行型のJupyter notebook実行環境です。
Googleのアカウントを持ってさえいれば誰でも使用することができ、開発環境を整える必要もなくPythonによる機械学習実装が可能です。
Googleのプラットフォームにのっかっているからこそのメリットと大量のデータセットと高度な処理を回すためのマシーンパワーが用意されているのが魅力。
Google Colaboratoryの使い方に関しては以下の記事をご覧ください。
また、PyCaret開発者の記事を参考にして実装していきます。
PyCaretを使う下準備
まずは、PyCaretをインストールしていきます。
!pip install pycaretターミナルからインストールするのではなくGoogle Colaboratoryの環境に直接記載するため行頭に!を付けるのを忘れないようにしてください。
PyCaretでデータをインポート
PyCaretでは多数のデータセットを用意しています。
from pycaret.datasets import get_data
boston = get_data('boston')この記事では、回帰タスクで定番のデータセットである「ボストンの住宅価格」のデータを使っていきます。
他のデータセットに関しては以下のGithubにまとまっています。
データの前処理
続いてデータの前処理をおこなっていきます。
from pycaret.regression import *
exp1 = setup(boston_data, target = 'medv')今回は回帰タスクを実装していくのでPyCaretのregressionを指定してインポートしていきます。
targetには目的変数を指定しましょう!
実はこれだけで勝手に最適なデータの前処理を行ってくれるんです。
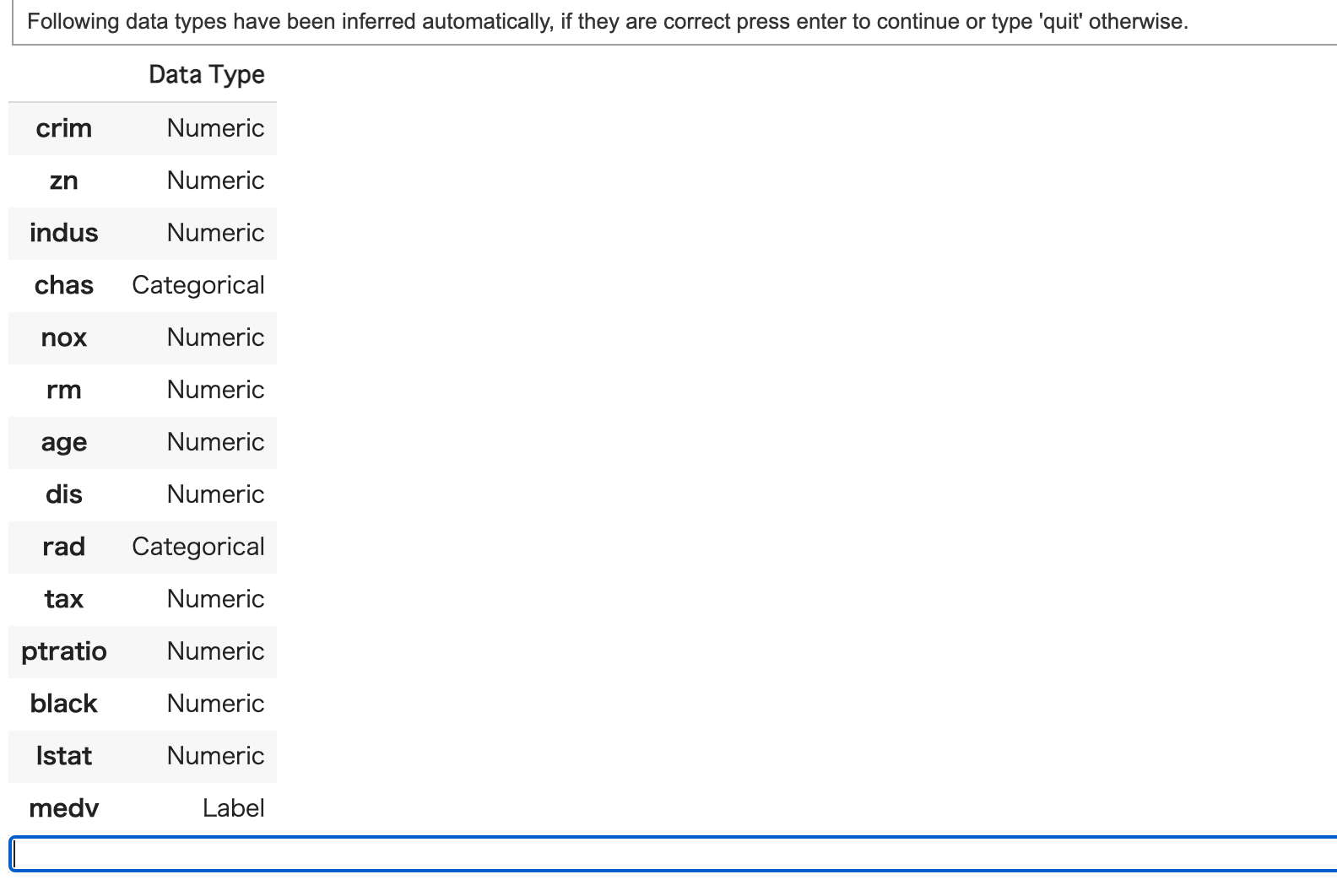
変数の型に対する確認がされるので問題なければ空欄でEnterを押しましょう!
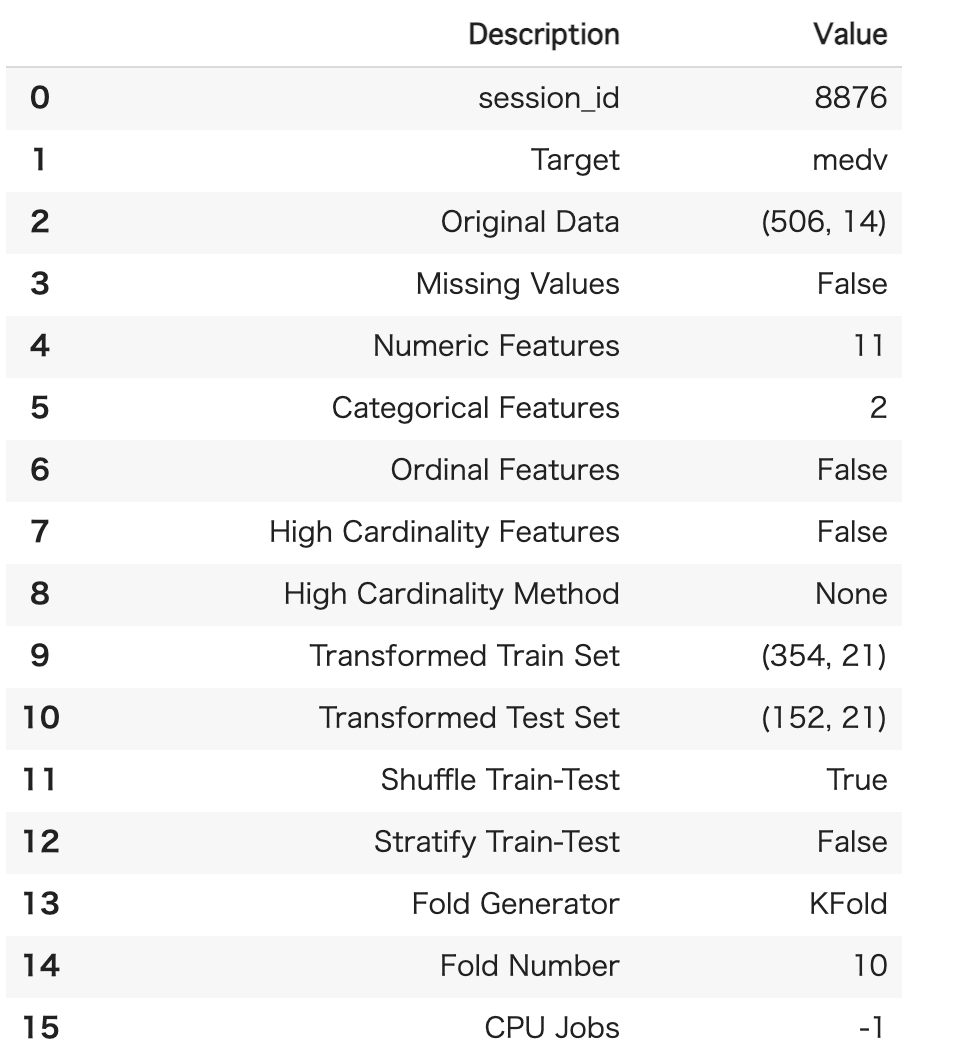
これで前処理完了!
All the preprocessing steps are applied within setup(). With over 20 features to prepare data for machine learning, PyCaret creates a transformation pipeline based on the parameters defined in setup function. It automatically orchestrates all dependencies in a pipeline so that you don’t have to manually manage the sequential execution of transformations on test or unseen dataset. PyCaret’s pipeline can easily be transferred across environments to run at scale or be deployed in production with ease. Below are preprocessing features available in PyCaret as of its first release.
(引用元:Announcing PyCaret 1.0.0)
控えめに言ってすごすぎます。
前処理でおこなってくれるのは以下。
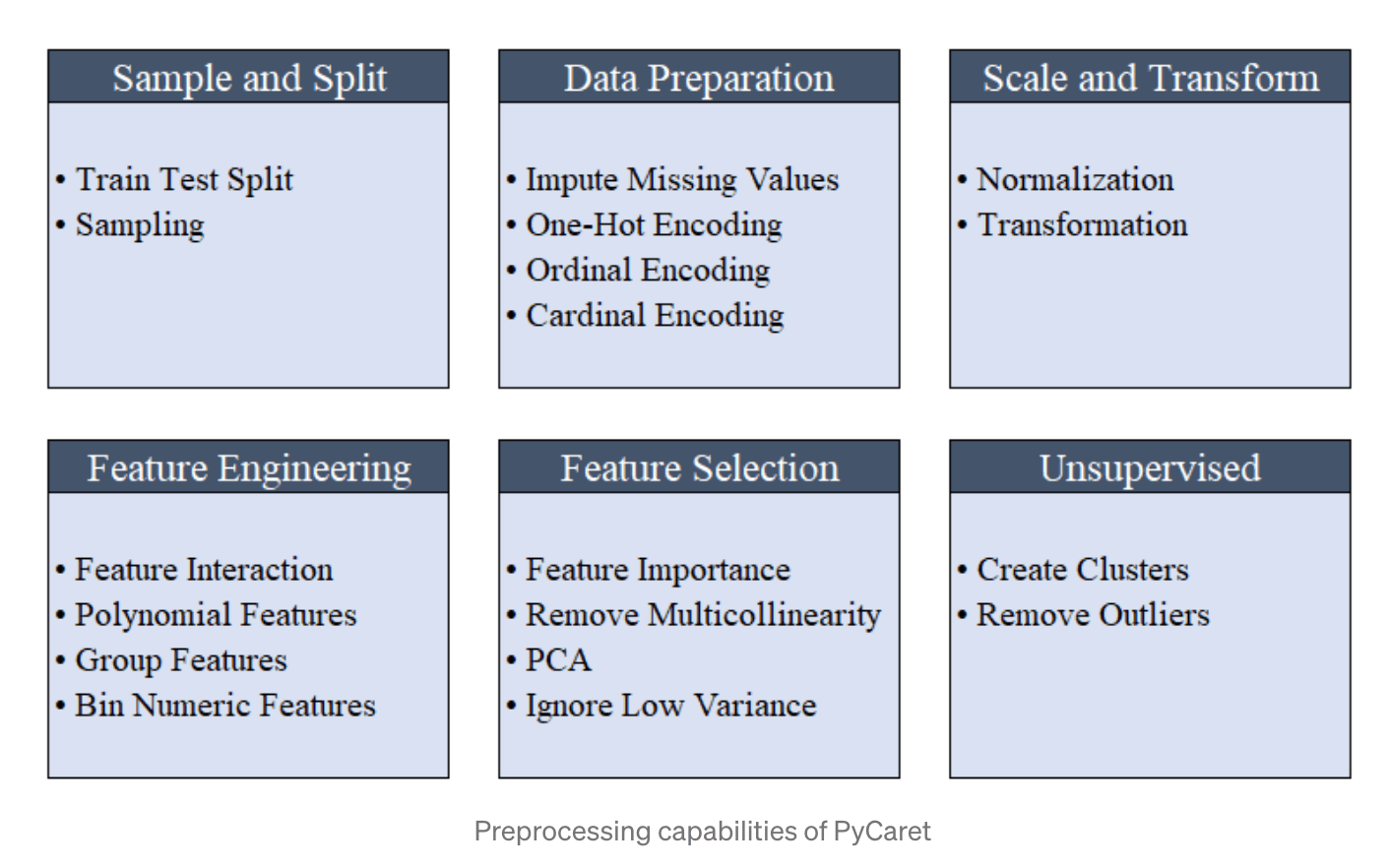
(引用元:Announcing PyCaret 1.0.0)
例えば、モデル構築の際に必ず行う学習データと予測データへの振り分けももちろんおこなっています。
デフォルトでは学習データ70%、予測データ30%となっているようです。
setupの際にtrain_sizeを指定してあげれば割合を変えることができます。
exp1 = setup(boston, target = 'medv', train_size=0.5)
実際に学習データと予測データの割合が50%ずつになったのが分かりますね!

より詳しく知りたい方は是非公式のリファレンスをチェックしてみてください!
PyCaretでモデリング
続いてPyCaretでモデリングをおこなっていきます。
モデリングもたった1行で終了!
compare_models()これだけでいくつかの手法の精度を比較して提示してくれるのです。
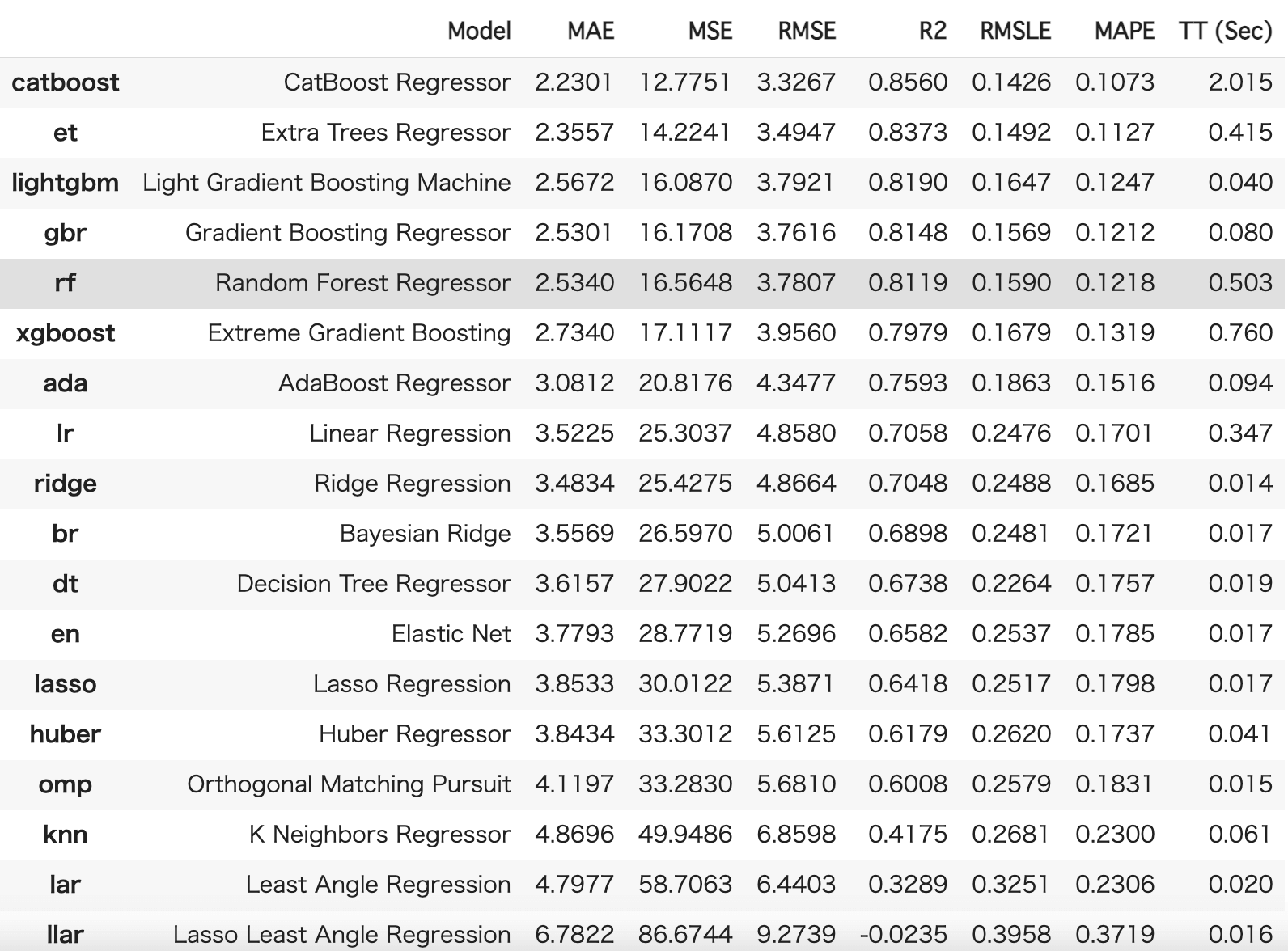
素晴らしい!
PyCaretで比較できる機械学習手法
PyCaretを実装するとよく分からない機械学習手法も簡単に扱えてしまうのである意味危険。
簡単にどんな機械学習手法があるのかここでまとめておきましょう!
回帰タスクで使える手法はザッと以下のようになっています。
‘lr’ – Linear Regression
‘lasso’ – Lasso Regression
‘ridge’ – Ridge Regression
‘en’ – Elastic Net
‘lar’ – Least Angle Regression
‘llar’ – Lasso Least Angle Regression
‘omp’ – Orthogonal Matching Pursuit
‘br’ – Bayesian Ridge
‘ard’ – Automatic Relevance Determination
‘par’ – Passive Aggressive Regressor
‘ransac’ – Random Sample Consensus
‘tr’ – TheilSen Regressor
‘huber’ – Huber Regressor
‘kr’ – Kernel Ridge
‘svm’ – Support Vector Regression
‘knn’ – K Neighbors Regressor
‘dt’ – Decision Tree Regressor
‘rf’ – Random Forest Regressor
‘et’ – Extra Trees Regressor
‘ada’ – AdaBoost Regressor
‘gbr’ – Gradient Boosting Regressor
‘mlp’ – MLP Regressor
‘xgboost’ – Extreme Gradient Boosting
‘lightgbm’ – Light Gradient Boosting Machine
‘catboost’ – CatBoost Regressor
※ザッと説明していきますが、一部曖昧な理解のものもあり
・‘lr’ – Linear Regression
一番シンプルな線形回帰分析!
・‘lasso’ – Lasso Regression
・‘ridge’ – Ridge Regression
・‘en’ – Elastic Net
・‘lar’ – Least Angle Regression
・‘llar’ – Lasso Least Angle Regression
・‘omp’ – Orthogonal Matching Pursuit
・‘br’ – Bayesian Ridge
・‘ard’ – Automatic Relevance Determination
・‘kr’ – Kernel Ridge
ここら辺の手法はザックリ言うと変数選択を上手くおこなって次元を圧縮して推定精度を上げようという手法群。
ラッソ回帰・リッジ回帰が広く有名ですが、通常の回帰に罰則項を設けて正則化した分析手法になります。
高次元データによく用いられます。
以下の記事で通常の線形回帰分析とラッソ回帰とリッジ回帰を比較しているので是非参考にしてみてください!

・‘par’ – Passive Aggressive Regressor
いわゆるオンライン学習というやつで、学習データが更新されるたびにモデルを更新します。
以下のナイーブベイズのイメージに近いです。

・‘ransac’ – Random Sample Consensus
・‘tr’ – TheilSen Regressor
・‘huber’ – Huber Regressor
外れ値を除去して回帰を行う手法群
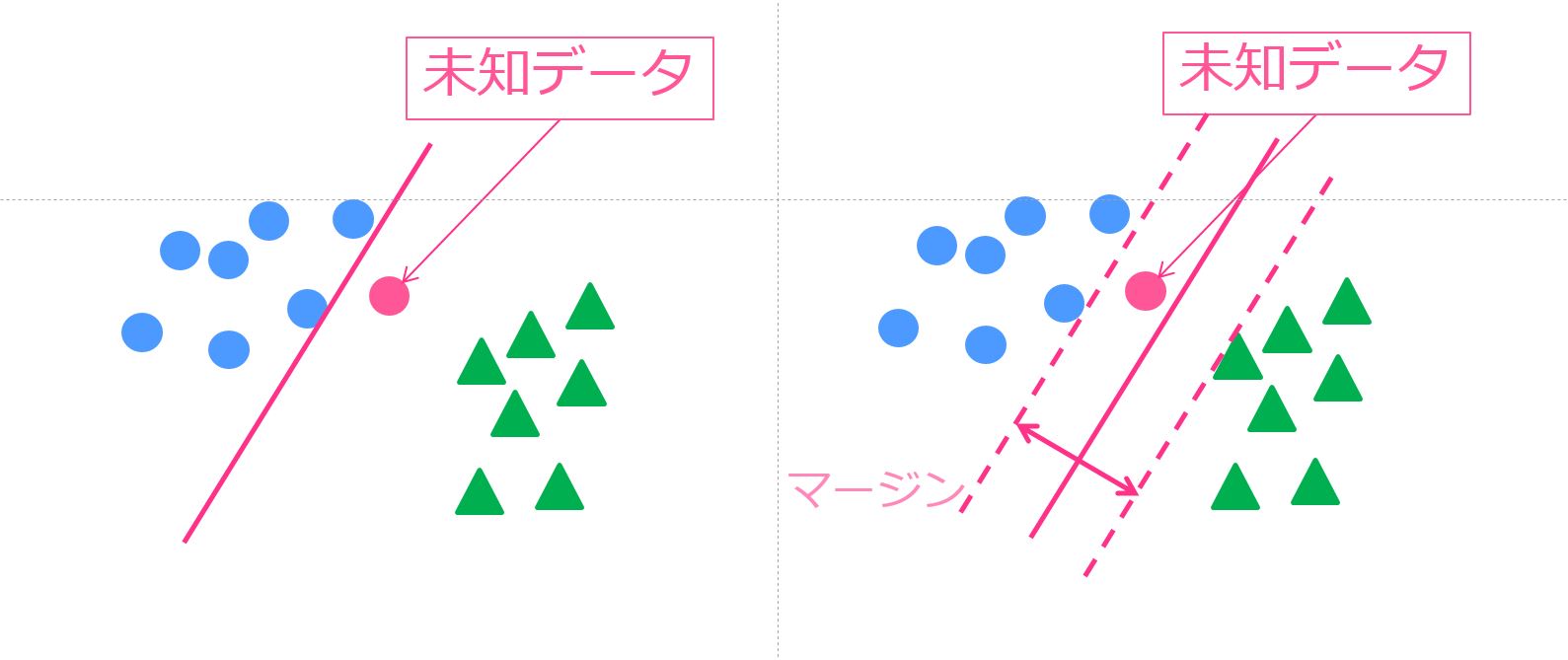
・‘svm’ – Support Vector Regression
サポートベクターと呼ばれる境界付近のデータを使って上手く判別する手法。
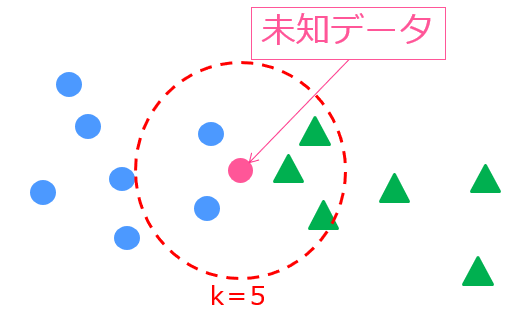
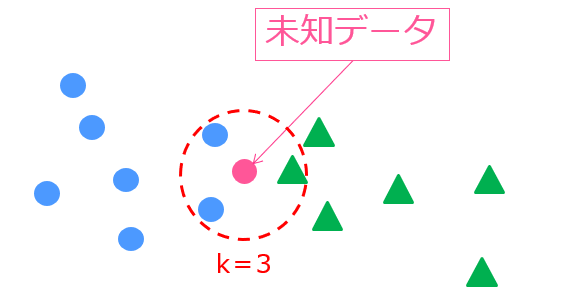
・‘knn’ – K Neighbors Regressor
k近傍法。あるデータの近傍k個のデータを基にクラス判別する手法の回帰版。
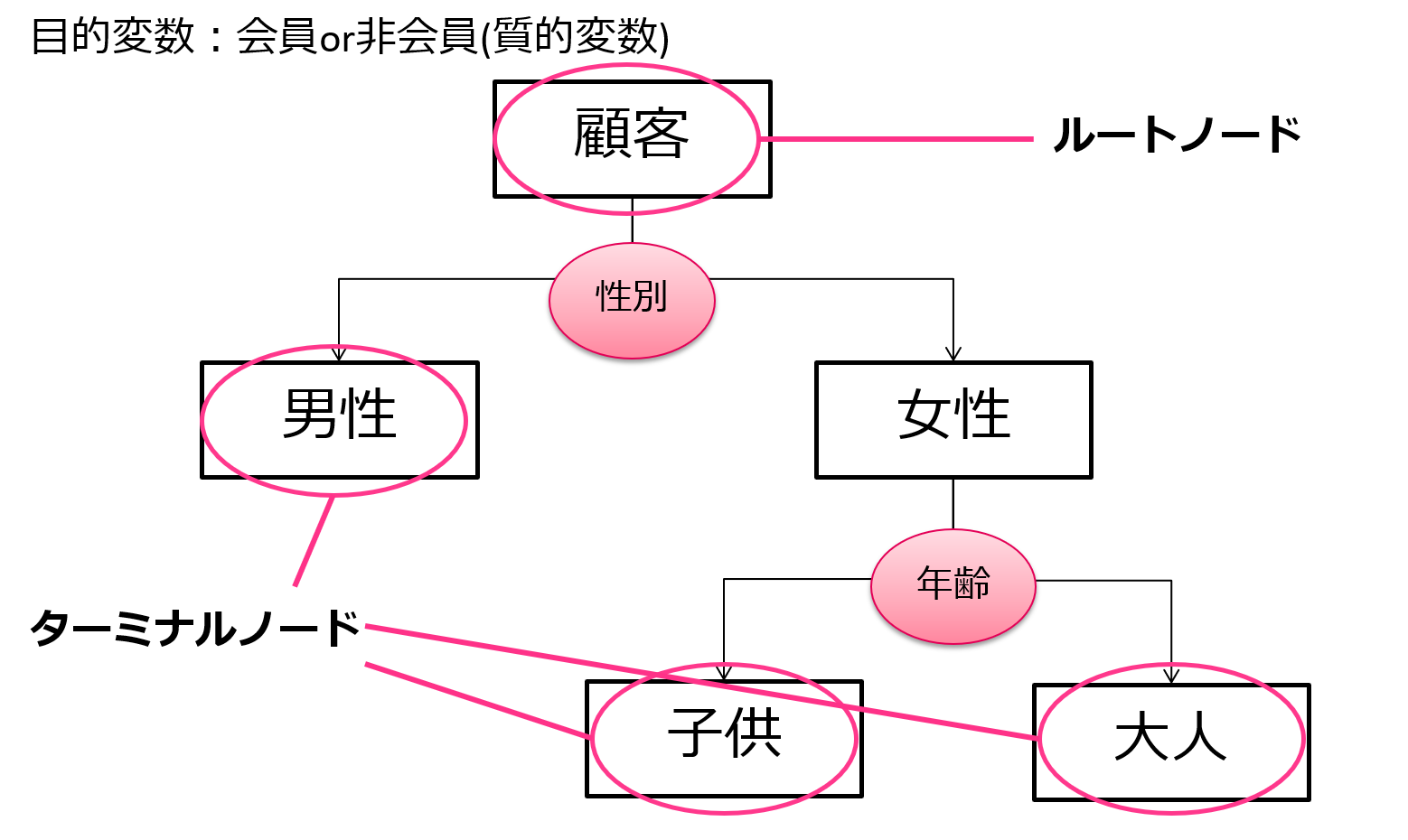
・‘dt’ – Decision Tree Regressor
データの現状把握のためによく用いられる決定木
決定木っていうのはその名の通り木構造でデータ分類していく手法で、そこそこの精度と結果の視認性から実務の場で良く用いられています!
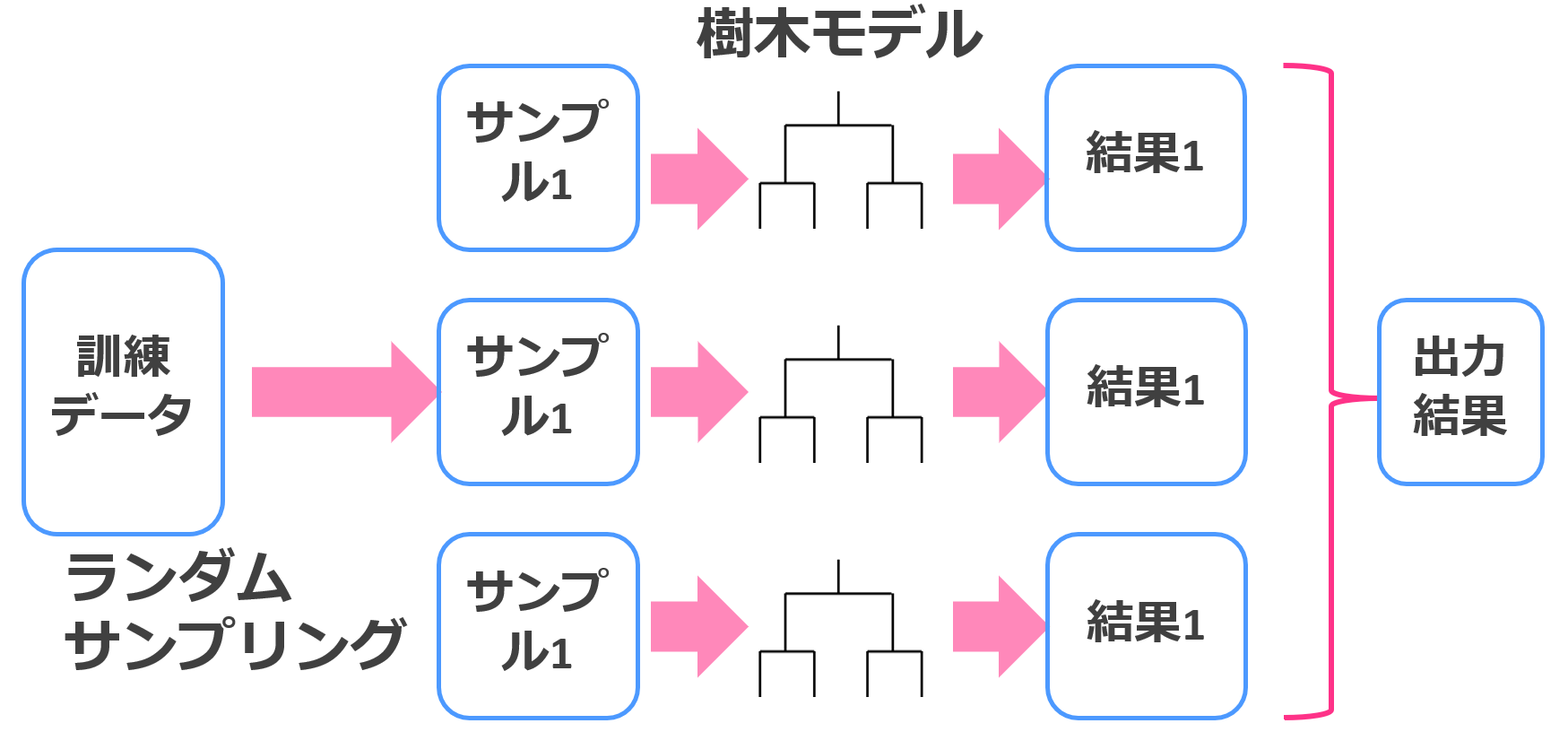
 ・‘rf’ – Random Forest Regressor
・‘rf’ – Random Forest Regressor
・‘et’ – Extra Trees Regressor
その決定木をバギングでアンサンブル学習させたのがランダムフォレスト。
Extra Trees Regressorも決定木にバギングを用いていますが、特徴量選択やバギングにおけるブートストラップサンプリングのアルゴリズムが違います。
・‘ada’ – AdaBoost Regressor
・‘gbr’ – Gradient Boosting Regressor
・‘xgboost’ – Extreme Gradient Boosting
・‘lightgbm’ – Light Gradient Boosting Machine
・‘catboost’ – CatBoost Regressor
高精度の機械学習手法といえば、これらのブースティング手法。
ブースティングはバギングと同じくアンサンブル学習手法ですが学習の方法が若干違います。
端的に言うと、バギングが複数の学習器を並列に使って平均を取ろうとする手法なのに対してブースティングは複数の学習器を直列に使って全員で欠点を補おうとする手法なイメージ。
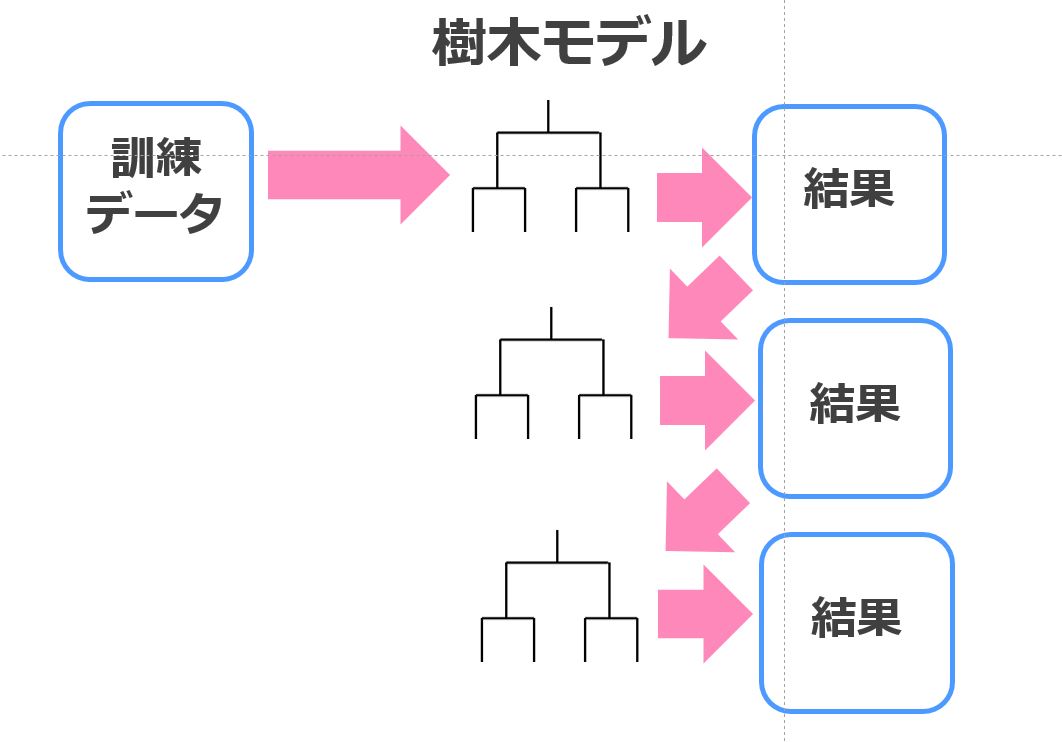
その中でも決定木と勾配ブースティングを組み合わせた勾配ブースティング木が強く、xgboostやLightGBMやCatBoostはその仲間です。
・‘mlp’ – MLP Regressor
これはMulti-layer Perceptron regressorで多層パーセプトロン回帰。
いわゆるニューラルネットワークです!
PyCaretで使われている回帰タスクについて紹介してきましたが、全てを完璧に理解する必要はありませんのでどのような意図でどのような仕組みが実装されているのか簡単に理解しておきましょう!
以下の記事で機械学習入門の内容をまとめています!

PyCaretのモデル選択
複数の機械学習手法の中から実際に使用する手法を選びます。
先程のたくさんの機械学習手法の中から精度の高かったCatBoostを選びましょう!
cb = create_model('catboost')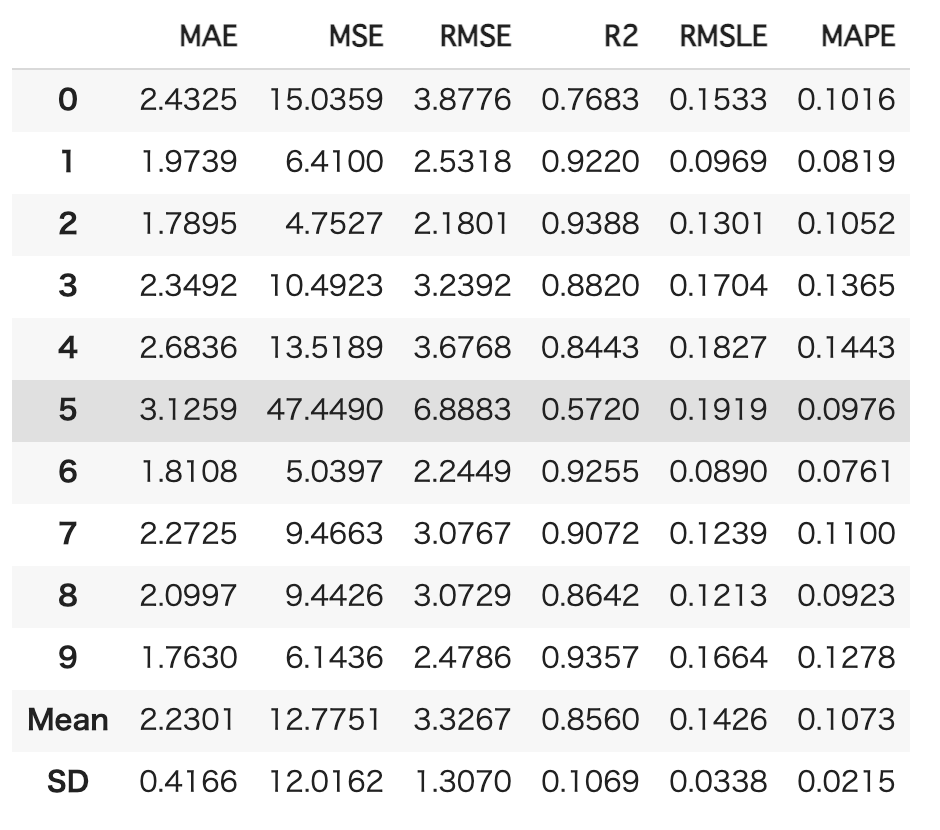
選択したモデルに対して10分割してクロスバリデーションをおこなっています。
ここで使用されている評価指標は、以下です。
MAE・・・Mean Absolute Error(平均絶対誤差)
MSE・・・Mean Square Error(平均二乗誤差)
RMSE・・・Root Mean Square Error(平均二乗平方根誤差)
R2・・・決定係数(寄与率)
RMSLE・・・Root Mean Square Log Error(対数平均二乗平方根誤差)
MAPE・・・Mean Absolute Percent Error(平均絶対誤差率)
場合によりますが、よく使われるのはRMSEとR2ですかね。
R2以外は小さい方がモデルの当てはまりがよく、R2は1に近い方がモデルの当てはまりがよくなります。
また、モデルのパラメータチューニングも可能です。
cb_tune = tune_model(cb)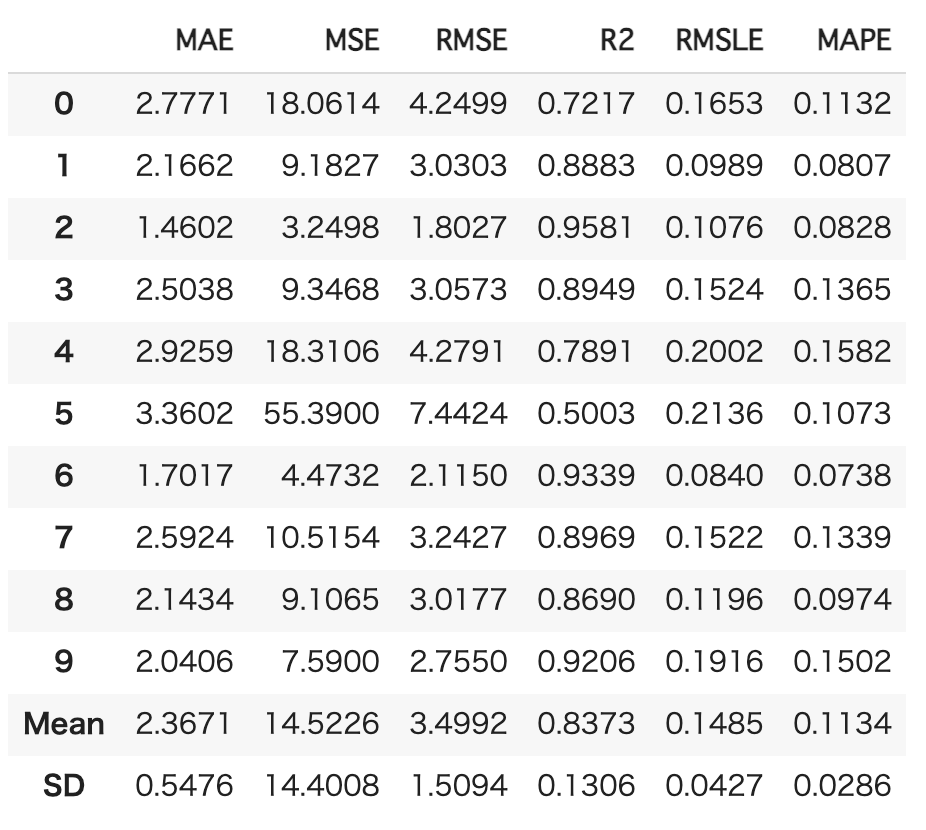
チューニングした結果が返ってきていますが、実はこれ精度若干悪化しているんですよね。
以下の開発者記事の分類タスクではちゃんと精度向上しているので回帰タスクにおけるパラメータチューニングには欠陥がある可能性が・・・
 (引用元:Announcing PyCaret 1.0.0)
(引用元:Announcing PyCaret 1.0.0)
Pycaretで予測を行う
続いて、PyCaretで予測をおこなっていきます!
cb_predict = predict_model(cb)
非常に簡単ですねー!
先ほど前処理で分けたテストデータを当てはめて予測精度を算出してくれています。
Pycaretでデータを描画する
続いて選んだCatBoostによるモデルでPyCaretでデータを描画していきます!
plot_model(cb)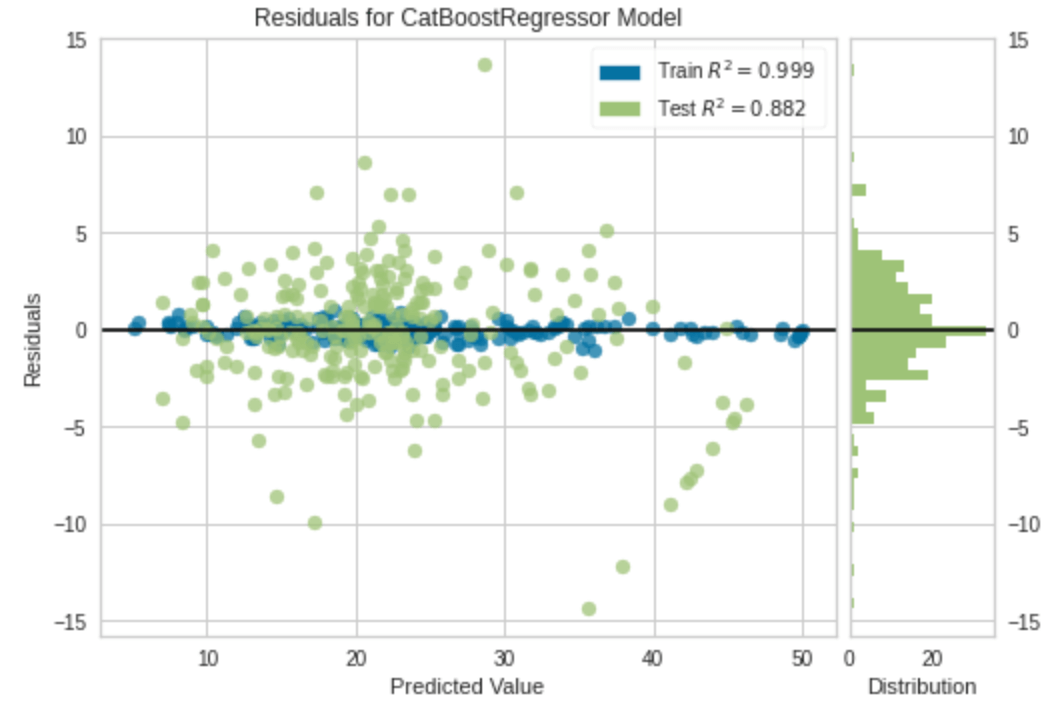
この分布では学習データへのモデルのばらつきと予測データに対するデータのばらつきが示されています!
データの描画も非常に簡単ですねー!
変数重要度を確認する
変数の重要度も簡単に見ることが出来ます。
plot_model(cb, plot='feature')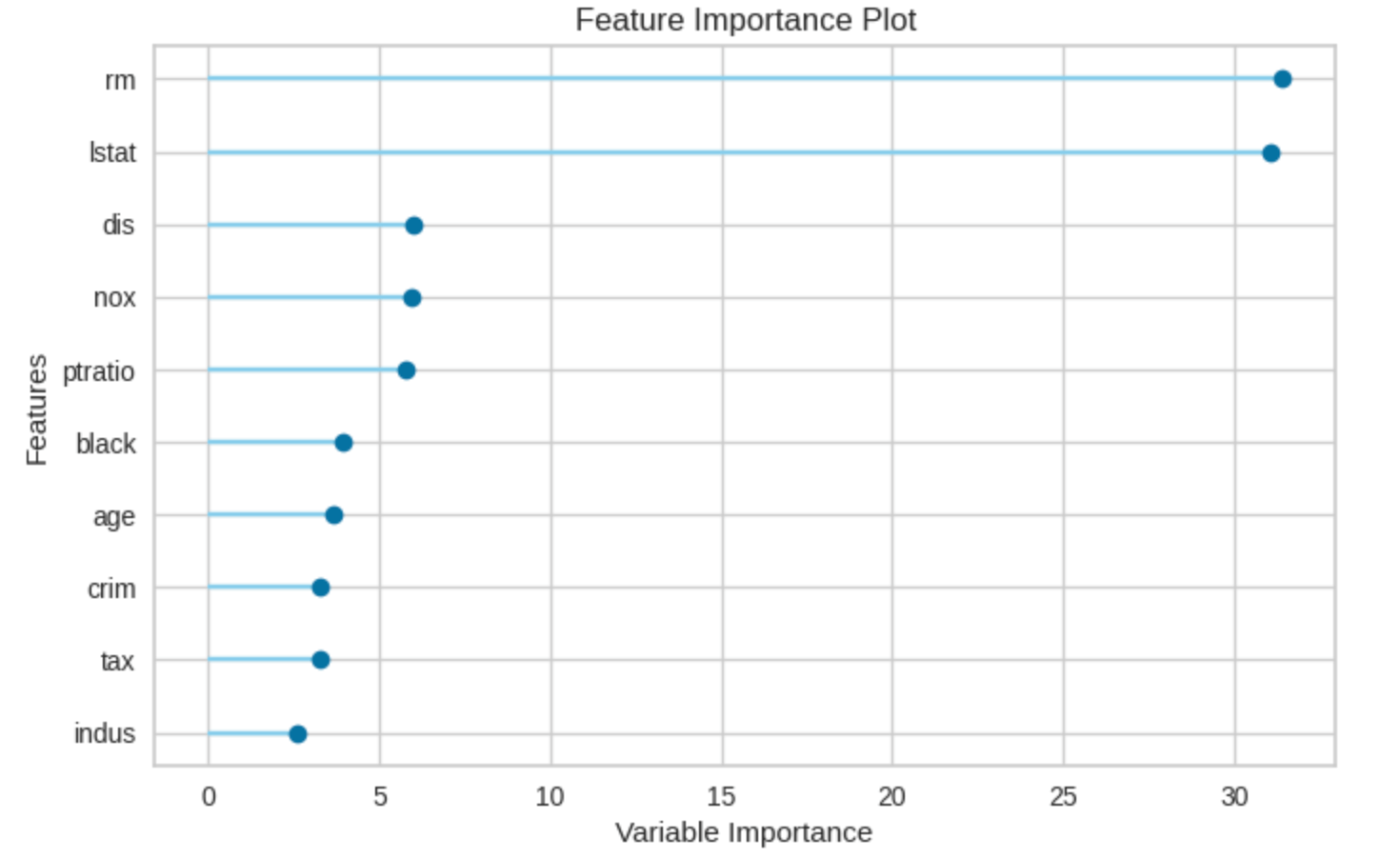
ここまで数行でデータの前処理・モデル選定から予測までをおこなってきました!
Pycaret まとめ

本記事ではPyCaretについてまとめました!
PyCaretの登場はデータサイエンティスト・機械学習エンジニアに衝撃を与えたと言っても過言ではないでしょう。
ただPyCaretがあれば全てができるわけではありません。
データ分析のプロセスであるCRISP-DMでいうところのモデリングの部分が簡易的に出来るようになっただけであり、現状のビジネス課題を分析に落とし込み特徴量を作り出しモデルから得られたアウトプットをビジネスへ導入する一連のプロセスは健在です。
これからもこのような流れは加速していくと考えるべきで、モデリングだけに注力する人材の価値はどんどん薄れていってしまうことでしょう。
手段だけに翻弄されるのではなく、目的を意識したデータ活用を推進していきましょう!
データサイエンティストへのロードマップやPythonの勉強法については以下の記事でまとめていますので是非チェックしてみてください!


 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















