
【5分で分かる】「CRISP-DM」の流れをデータサイエンティストが徹底解説!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です。
データ分析において必要な考え方である「CRISP-DM」。
おそらくCRISP-DMという言葉は知らなくても、多くの人がこの「CRISP-DM」を日ごろから無意識的におこなっていることでしょう。
CRISP-DMという言葉自体を覚えることそのものには意味がありませんが、CRISP-DMを理解してこのフレームワークに立ち返ることでデータ分析を効率よく行うことができます。

この記事では、そんなCRISIP-DMというプロセスに関してまとめていきます。
以下のYoutube動画でも解説しているので是非チェックしてみてくださいね!
目次
CRISP-DMとは
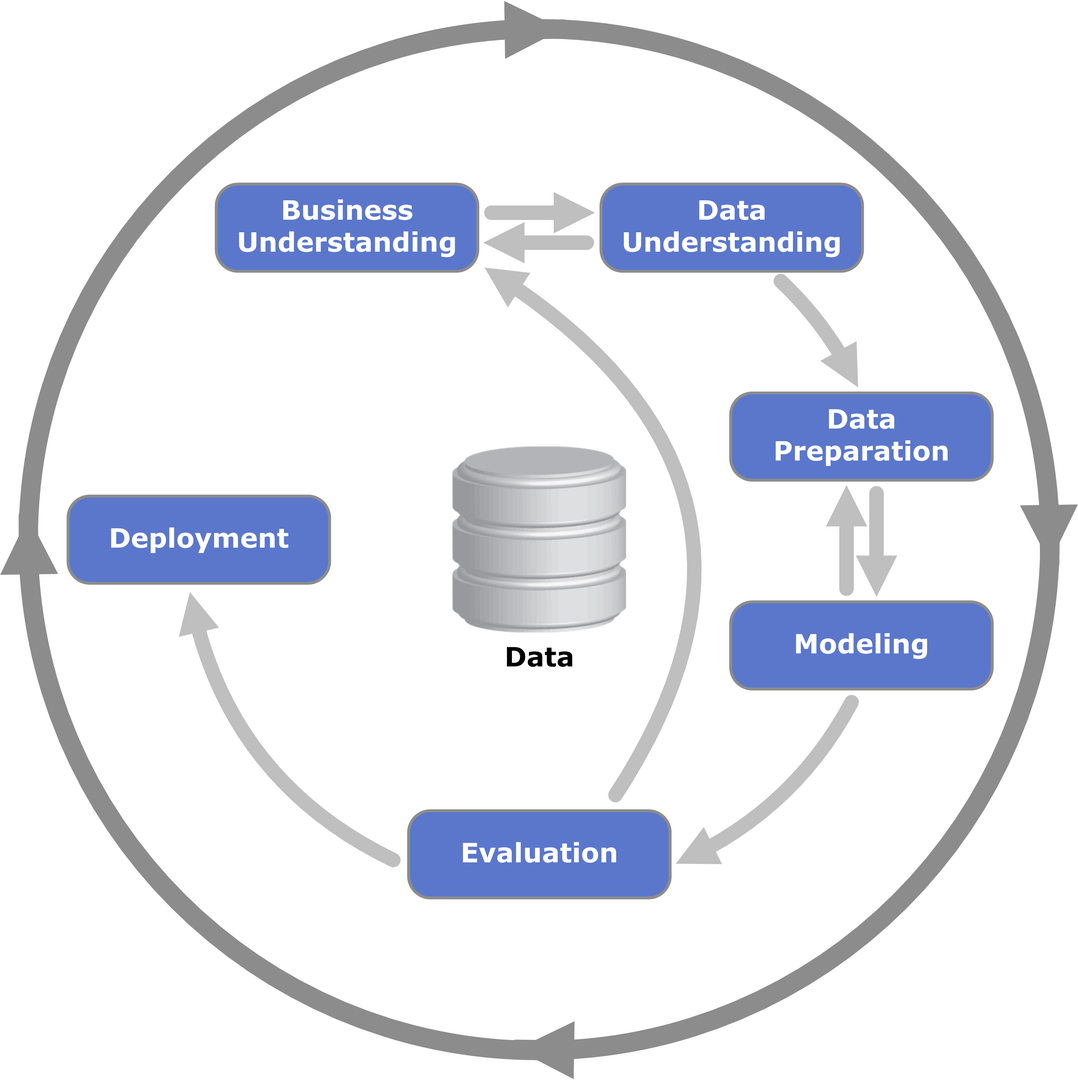
(出典:Wikipedia-‘Cross-industry standard process for data mining’)
CRISP-DMとは、「Cross-industry standard process for data mining」の略であり、データマイニング・データサイエンス・AI開発などにおいて業界横断で標準的に使えるデータ分析プロセスになります。
このCRISP-DMには全部で6つのプロセスがあります。
それぞれについて詳しく見ていきましょう!
Business Understanding

まず全てのデータ分析は、ビジネス理解から始まります。
データ分析というと、プログラミング言語やツールを使ってデータにアクセスするイメージがあると思いますが、最初は往々にしてビジネスを理解してビジネス課題を特定するところから始まります。
とはいえ、この段階でデータを触ってはいけないわけではありません。
理想はマクロ的な視点でビジネス課題を特定してその課題に対する仮説を基にデータを触ることですが、個人的にはデータをとりあえず触ってみるというところから始まってよいと思っています。
というかそこにあまり理路整然とした順番は必要ありません。
図でもBusiness UnderstandingとData Understandingが行き来しているように、シャープな課題特定と仮説立てにはこのプロセスの行き来が必要なのです。
ここでは、その課題に対してどのような出口設計をするのか、どのように効果検証を行うのかという事前設計も重要です。
このフェーズはコンサルタントの仕事に近く、コンサル本が役に立ちますが、定番は「イシューからはじめよ」といったところでしょうか。

Business understandingの工程に関しては以下の記事で詳しく解説しています。

Data Understanding

Business Understandingと相互的に行うのがData Understanding。
データの構造や中身を分かっていないと、データ分析に移ることはできません。
もしかしたら元々Business Understandingで設計した課題と仮説を検証するデータがそもそも揃っていないかもしれません。
その場合、そのデータを新たに計測もしくは別のDMPから連携するのか、それとも別の検証方法を考えるべきなのか検討しなくてはいけません。
ここでDMPをしっかり作り込めているか否かの差が大きく出てきてしまいます。
また、このフェーズでは探索的データ分析(EDA)と呼ばれるステップをおこなっていきます。
このステップは地味な面も多いですが、これからのモデル構築の精度を決める非常に重要なステップとも言えます。
以下の記事で探索的データ分析(EDA)については詳しく解説していますので是非チェックしてみてください!

データを簡単に集計して可視化を行い、どこに課題があるのか見極めていくことになります。
PythonだとPandasを使い加工集計し、MatplotlibやSeabornと呼ばれるライブラリを使用することで比較的簡易的に可視化を行うことができます。
Data Preparation

続いてData Preparation。
このプロセスは、いわゆるデータ分析における前加工・前処理と言われるところです。
最もデータ分析において時間がかかる工程であり、地味な作業が多いです。
などの工程が必要になります。
Modeling

データ分析という言葉から連想されるイメージはこのモデリングの場合が多いかもしれません。
しかし、実際はこのモデリング自体は便利なライブラリが用意されているためそれほど時間がかからないのです。
※モデル構築のコーディングには時間はかかりませんが、モデル学習自体は時間がかかる場合が多いです。
選択するモデルにはたくさんの種類がありますが、選択する上での基準はいくつかあります。
例えば、
・分類なのか回帰なのか
・画像データか否か
・時系列データか否か
精度だけを求めるのであれば、勾配ブースティングもしくはディープラーニング。
解釈容易性を求めるのであれば、決定木やロジスティック回帰などが好まれます。
またKaggleなどのデータコンペでは、とにかく高い精度を出力することが求められるのでいくつかのモデルを組みあわせて(アンサンブル)、最終結果とすることもあります。
そもそも勾配ブースティングが自体がアンサンブル学習なのですが、それをさらに他の様々な手法とアンサンブルすることは、本質的ではないとは思いますが現にそれで精度が上がるのです。
機械学習の手法は以下で一挙にまとめています!

Evaluation

モデルを構築した後にそれで終わりではありません。
そのモデルを評価しなくてはいけません。
評価指標には、
・MSE(平方平均二乗誤差)
・RMSE(平均二乗誤差)
・正解率
・適合率
・再現率
・F-measure
などがあります。
機械学習領域と統計学領域で同じ指標でも言い方が違ったりややこしいのですが、
✓回帰のタスクであれば、RMSEあたり
✓分類のタスクであれば、再現率・適合率
を使用することが多い気がします。
再現率・適合率に関しては以下の不均衡データの記事で詳しくまとめています!
実は、このEvaluationの段階で、思ったような効果が出ていないと判断された場合「CRISP-DM」でいうBusiness Understandingに戻ってしまっています。
つまりは、そもそも最初に立てた課題設定が間違っていたという大きな手戻りが発生しているわけですね。
CRISP-DMにおける評価のフェーズに関しては以下の記事で詳しく解説しています!

Deployment

ここまできて、やっとビジネスに落とし込むことができます。
この時、しっかり現場と握れていないとDeploymentが出来ないという結果に陥りかねません。
しっかりDeploymentまで行うことができてデータ分析であり、それを行うことができるのがデータサイエンティストなのです。
そのためには、データホルダーだけで進めるのではなくマーケティングサイド・ビジネスサイドとしっかり業務要件やビジネス設計を明確にして共有しておくことが非常に大事です。
Deploymentについては以下の記事で詳しく解説しています!

CRISP-DMの利用場面

CRISP-DMの利用場面というよりも、データ分析の実例と言った方が早いかもしれませんが例えば顧客の解約率を予測してそれを防ぐことなどがあります。
これをCRISP-DMに当てはめると、非常に簡略化していますが以下のようなイメージです。
・Business Understanding
売上が落ちているのは何が原因なのか→既存顧客の解約率が下がっている→既存顧客の流出を防ぐことが急務である→既存顧客の解約率を予測する
・Data Understanding
どのようなデータがあるか調査、どのようなデータが顧客解約予測に利きそうか基礎分析
・Data Preparation
データの結合、前処理、加工、特徴量生成
・Modeling
機械学習手法でモデル構築
・Evaluation
顧客解約予測における実解約と予測解約の再現率・適合率で評価
・Deployment
解約予測された顧客に対するアプローチ(クーポン付与、メールセグメント、DM、直接アプローチ)
ちなみにデータ分析のプロセスを簡単に分かりやすくまとめているのが以下の書籍になります。
拙著「俺たちひよっこデータサイエンティストが世界を変える」

この小説はCRISP-DMにおけるDeploymentまで出来ていないのですがデータ分析のプロセスがなんとなーく分かるかなと思います。
CRISP-DM まとめ
本記事では、CRISP-DMについて見てきました!
CRISP-DMのステップをより詳しく理解するために以下のUdemyコースを用意しています。是非チェックしてみてください!
【初学者向け】データ分析コンペで楽しみながら学べるPython×データ分析講座
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 4時間 |
| 【レベル】 | 初級~中級 |
僕自身がUdemyの色んなコースを受けてみた中で、他のコースにはないこんなコースあったらいいなみたいなコースを作ってみました。
このコースは、なかなか勉強する時間がないという方に向けてコンパクトに分かりやすく必要最低限の時間で重要なエッセンスを学び取れるように作成しています。
アニメーションを使った概要編とハンズオン形式で進む実践編に分かれており、概要編ではYoutubeの内容をより体系的にデータ分析・機械学習導入の文脈でまとめています。
データサイエンスの基礎について基本のキから学びつつ、なるべく堅苦しい説明は抜きにしてイメージを掴んでいきます。
統計学・機械学習の基本的な内容を学び各手法の詳細についてもなるべく概念的に分かりやすく理解できるように学んでいきます。
そしてデータ分析の流れについてはCRISP-DMに沿って体系的に学んでいきます!
データ分析というと機械学習でモデル構築する部分にスポットがあたりがちですが、それ以外の工程についてもしっかりおさえておきましょう!
続いて実践編ではデータコンペの中古マンションのデータを題材にして、実際に手を動かしながら機械学習手法を実装していきます。
ここでは、探索的にデータを見ていきながらデータを加工し、その上でLight gbm という機械学習手法を使ってモデル構築までおこなっていきます。
是非興味のある方は受講してみてください!
Twitterアカウント(@statistics1012)にメンションいただければ1500円になる講師クーポンを発行いたします!
また、当メディアが運営するAIデータサイエンス特化スクールの「スタアカ(スタビジアカデミー)」でも、CRISP-DMに沿って分析の流れをミッチリ学ぶことが可能です。
 公式サイト:https://toukei-lab.com/achademy/
公式サイト:https://toukei-lab.com/achademy/
| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
24時間以内の質問対応と現役データサイエンティストによる1週間に1回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解などもあわせて学べるボリューム満点のコースになっています!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
冒頭でも述べましたが、CRISP-DMという言葉を知っているかどうかは重要ではありません。
CRISP-DMのフレームワーク
の流れと各プロセスを理解して実践できるようにしましょう!
データ分析に有用なPythonの勉強法については以下の記事でまとめています。

また、データサイエンティストについてロードマップは以下の記事でまとめていますので是非参考にしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















